漢語名名組合語義分析的計算研究
2020-09-29 07:44:49王萌符雅茹胡純
現代語文 2020年6期
王萌 符雅茹 胡純
摘 ?要:名名組合語義分析的主要目的是探討修飾語和中心詞之間隱含的語義關系。運用降級述謂結構理論,利用語料庫自動獲取隱含謂詞,將修飾語和中心詞之間的語義關系顯性化。實驗結果表明,該方法不僅可以為名名組合提供多種可能的語義解釋,而且能夠反映組成相似的名名組合之間細微的語義差別。這一研究成果不但能夠服務于信息檢索、問答系統等應用領域,而且可以為概念組合認知機制研究提供語義解釋的依據。
關鍵詞:名名組合;語義分析;隱含謂詞;語料庫
一、引言
名名組合(noun compounds)是一種特定類型的名詞短語,它由相鄰的名詞序列組成,其功能整體上相當于一個名詞,如“電腦 公司”“衣服 價格”和“汽車 質量 問題”等。學界通常把名名組合中的最后一個名詞稱為中心詞(head),前面的名詞稱為修飾詞(modifier)。名名組合廣泛存在于英語、漢語、日語、德語等各種語言,是語言中的第一高頻組合,它主要有以下幾個特點:
第一,通過兩個詞語的組合來實現信息壓縮,并以最少的文本呈現出來,這符合語言學中的“經濟原則”(人們在交際時總是力求用最簡潔的語言來表達復雜完整的意思)。因此,名名組合的使用非常普遍,經常出現在新聞媒體、科技報告及小說等各種文體中。
第二,名名組合的能產性很高。一方面,在日常生活中,人們根據交流的需要,不斷產生新的概念組合來指稱新出現的事物,如“傻瓜 相機”“板凳 隊員”“鳳凰 男”等。另一方面,在快速更新的科技領域中,專業術語通常以名名組合的形式出現,如“數據 總線”“光電 鼠標”等。
第三,雖然名名組合的構成比較簡單(相鄰的名詞序列),但是它們在句法分析和語義解釋上表現出較高的歧義性。特別是在漢語中,名名組合的分析效果對整個句法分析有著很大的影響。
以上特點使得名名組合在語言學和計算語言學領域成為一個熱點研究課題,它所涉及的研究范圍也越來越廣泛,包括名名組合的自動獲取、句法分析、語義解釋、翻譯以及語義焦點分析等。本文主要關注的是漢語名名組合的語義解釋,運用降級述謂結構理論,利用語料庫自動獲取隱含謂詞,探討修飾語和中心詞之間隱含的語義關系。
二、名名組合的語義分析
(一)理論語言學中的名名組合語義類型
在句法結構上,漢語名名組合可以分為主謂、定中、同位與聯合。在語義分析上,名名組合內部隱含著復雜的意義構建過程,其語義關系一直受到學界的
重視,對語義關系的研究在逐步深入和細化,相關成果也頗為豐富。朱德熙從修飾語和中心語的意義聯系出發,歸納出領屬、質料、時間、處所等語義類別[1]。李宇明采用層級性分類方法,將N1與N2組合分為屬性關系與非屬性關系兩大類,每一類下面再分若干小類[2]。袁毓林將名詞定語分為領屬定語和屬性定語兩類[3];文貞惠在這一分類的基礎上提出了一個有層級的語義類別關系網絡[4]。周日安系統研究了名名組合的句法語義,構建出語義匹配的演繹表,推演出名名組合的語義生成模型[5]。方清明以“雙視點”視角對名名語義關系進行了細致的分類,提出了如質料、提取物、處所、部位等20種關系類型[6]。
(二)計算語言學對名名組合的語義分析
在計算語言學領域,很多實際的應用系統都可以利用名名組合的句法語義分析結果。降級述謂結構理論認為,名詞和名詞之間常常隱藏了謂詞,其語義關系可以通過補入隱含謂詞而揭示出來,如“電影 公司”可以是“[制作/發行/拍攝]電影[的]公司”。這種隱含信息的顯性化對信息檢索、問答系統、機器翻譯等諸多自然語言處理任務都有所幫助。例如,在信息檢索系統中,用戶輸入查詢“偏頭疼 療法”,系統可以提供“[減輕]偏頭疼[的]療法”或者“[防止]偏頭疼[的]療法”等不同的語義解釋來幫助用戶改進查詢及結果。
目前,研究漢語名名組合的語義解釋主要有兩大處理策略。第一種是自上而下的策略(top-down strategy),這種方法首先要求有一組已經定義好的、明確的關系集合,然后根據這個關系集合,為每個名名組合分配適當的語義關系。這實際上就是一個分類問題,也有學者將這種方法稱之為“Inventory-based method”。Zhao等實現了具有名物化現象(nominalization)的漢語名名組合的自動語義分類,如“鳥類 遷徙”中的“遷徙”是名動詞(具有名詞功能的動詞)。作者參照動詞的語義角色(semantic roles)界定了四種粗粒度語義關系(Proto-Agent,Proto-Patient,Range和Manner),對300個短語進行了自動分類實驗[7]。
隨著研究的逐步深入,越來越多的研究者意識到,將語義關系歸納為有限的幾個類型的做法是有缺陷的。首先,名名組合的語義關系是不能由一組固定的集合窮盡的,無論根據何種關系進行定義,總存在一些組合不能被正確歸類[6]、[8];其次,固定的關系集合難以反映名名組合的多義性,一個名名組合根據不同的解釋可以屬于多個語義類;最后,各種語義分類體系孰優孰劣無法判斷。因此,研究者開始采用一種非受限的、開放式的方法,不事先定義語義關系集合,而是通過大規模語料去發現詞語組合時隱含的語義關系,并通過某種模式進行釋義(paraphrase)。這就是第二種處理策略:即自下而上的策略(bottom-up strategy)。
在這種思路指導下,很多研究者嘗試用動詞來解釋名名組合的語義關系,他們認為,動詞在表達細粒度的語義關系上更具有表現力。這種研究思路在英文名名組合的語義解釋上,得到了廣泛認可并付諸實踐[9]—[12]。例如,“night flight”的語義關系屬于時間(Temporal)類型,兩個名詞之間更細微的語義關系可以通過加入一系列動詞(如“arrive at,leave at,be at,be conducted at”)表達出來。2010年,國際語義評測會議(Semantic Evaluation,簡稱“SemEval”)提出一項英文評測任務“Noun Compound Interpretation Using Paraphrasing Verbs and Prepositions”,要求參賽者為測試短語提供釋義動詞集合,同時給出動詞的排名;2013年,SemEval延續并擴展了該項評測任務“Free Paraphrases of Noun Compounds”。
漢語名名組合的釋義研究也經歷了從靜態分類到動態演繹的過程,研究成果主要集中在對名名組合語義的靜態分類上,采用動態方式釋義的研究成果較少。王萌等首次采用動態策略,利用語料庫(Chinese Sketch Engine)及Web數據,自動獲取漢語名名組合的釋義短語[13]。魏雪形式化歸納了名名組合的語義模式,對基于規則的漢語名名組合的自動釋義方法進行了探索,利用知網生成釋義短語,對網絡搜索詞進行語義分析[14]。劉鵬遠、劉玉潔基于大規模真實語料,建立了中文基本復合名詞短語語義關系體系及相應句法語義知識庫, 其中包含18281條高頻基本復合名詞短語,每條短語標注了語義關系、短語結構等信息,可作為相關研究的基礎數據資源[15]。
三、隱含謂詞的獲取
(一)降級述謂結構理論
名名組合的表層形式是“名1+名2”。降級述謂結構理論認為,名1和名2之間隱含了動詞,通過補入動詞,大致能將其語義關系揭示出來。不同語義關系隱含著不同的降級謂詞,對應著不同的降級述謂結構。比如,“羊毛 背心”可解釋為“羊毛[編織的]背心”,“英語教師”可解釋為“[教]英語[的]教師”。袁毓林曾對漢語謂詞隱含(implying predicate)進行過詳細論述,從句法和心理實現性等方面對謂詞隱含現象進行了驗證,指出被隱含的謂詞是句子的語義表達中不可或缺的成分[3]。周日安從名詞的語義格(施事、受事、領事等)出發,列舉了18種語義格的匹配情況,他指出研究名名組合的語義類型應持開放態度,可以以語義格為縱橫坐標,構建名名組合語義關系的演繹表[5]。可見,采用降級述謂結構理論對名名組合進行語義分析,關鍵是要獲取隱含謂詞。
(二)隱含謂詞
名詞通常會指涉概念,每一概念都具有自己的特征,當名詞與名詞相組合時,某一方面的特征便會凸顯出來。如“鉆石”作為一種堅硬的材質可以被切割和打磨,也可以作為裝飾物,“鉆石 鋸片”和“鉆石 戒指”分別凸顯了鉆石的兩種不同特征。這些特征可以通過不同的“動詞”進行解釋,即“[切割]鉆石[的]鋸片”和“[鑲嵌]鉆石[的]戒指”。因此,隱含謂詞獲取的主要任務便是找到所有可能的與名詞概念相關的動詞,在兩個名詞組合時,與被凸顯特征相關的“動詞”就是合理的隱含謂詞。
那么,如何獲取與名詞概念相關的動詞呢?在自然語言中,任何形式和結構都是為了表達一定的意義,而任何意義及其關聯都要通過一定的形式和結構表現出來。從句法層次上看,連接動詞與名詞的最為直接的語法關系就是“述賓(verb-object)”和“主謂(subject-verb)”。因此,本研究從較易把握的形式線索——表層的句法結構入手,利用“述賓”和“主謂”兩種語法關系,獲取與名詞概念相關的動詞。這就要求我們所使用的語料是標記了主謂賓等句法結構信息的,而目前可以直接利用的中文句法樹庫資源有限,這會直接影響到動詞的獲取數量。我們的方法是,獲取與名詞在指定語法關系下具有搭配意義的動詞,并不要求語料經過深層次的句法加工和標注。就目前的研究來看,中文詞匯特征素描系統(Chinese Sketch Engine,簡稱“CSE”)便可勝任。
(三)中文詞匯特征素描系統
Sketch Engine是一個大規模語料處理系統,該系統除了提供一般的關鍵詞及語境查詢外,還提供了詞匯特征素描(word sketch)、語法關系(grammatical relation)以及同近義詞分析(thesaurus)等自動產生的語法知識[16]。目前這個系統已經應用于英語、漢語、法語、德語、日本語等多種語言,產生了廣泛的影響。中文詞匯特征素描系統①是Sketch Engine系統與十四億字的Chinese Gigaword語料相結合的產物,它提供了絕大部分中文詞匯實際使用的描述,可以服務于諸多自然語言處理任務[17]。
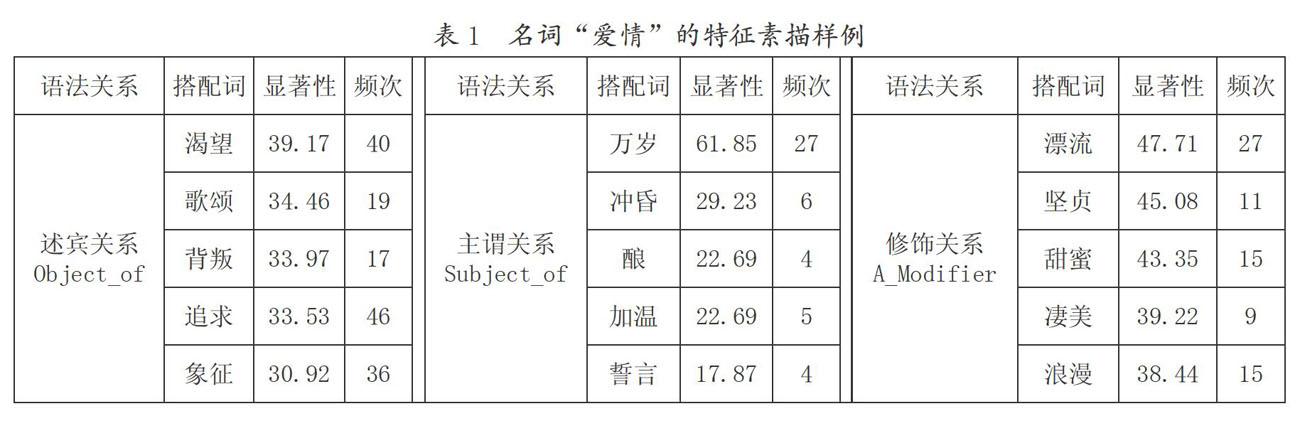
Word Sketch描述了詞語在某些語法關系下與其他詞語的搭配情況。根據詞類的不同,其對應搭配詞的語法關系也不同。例如,CSE中名詞的搭配關系有述賓關系(object_of)、主謂關系(subject_of)、領屬關系(possession/possessor)、修飾關系(A_modifier/N_modifier/modifies)及并列關系(and/or)等9種。所有的搭配關系可以用一個三元組(triple)來表示,即(word1,relation,word2),其中,word1是查詢的關鍵詞,relation是語法關系,word2是在這種語法關系下的搭配詞。我們以“愛情”為例,運用該系統的查詢結果制作了該詞的特征素描,具體如表1所示:
表1列舉了名詞“愛情”在三種語法關系(object_of、subject_of、A_Modifier)下的搭配情況。其中,“頻次”是指在相應的語法關系下搭配詞出現的次數,如“愛情”作為“渴望”的賓語共出現了40次;搭配顯著性的計算方法是互信息;搭配詞語按照顯著性的降序進行排列。
(四)獲取步驟
利用CSE中的Word Sketch功能,可以方便地獲取某個名詞的在各種語法關系下的特征素描,本文只使用“subject_of”和“object_of”兩種關系。以名名組合“n1 n2”為例,經過兩個步驟即可獲取隱含謂詞。
第一步,將n1和n2作為查詢關鍵詞,分別獲取它們在“subject_of”和“object_of”兩種語法關系下的搭配詞,只保留前200個顯著性最高的搭配詞,這樣分別得到名詞n1和n2的相關動詞集合,分別記為VerbSetn1和VerbSetn2。
第二步,求取VerbSetn1和VerbSetn2的交集,得到名詞n1和n2所共有的動詞,作為最終的隱含謂詞獲取結果。
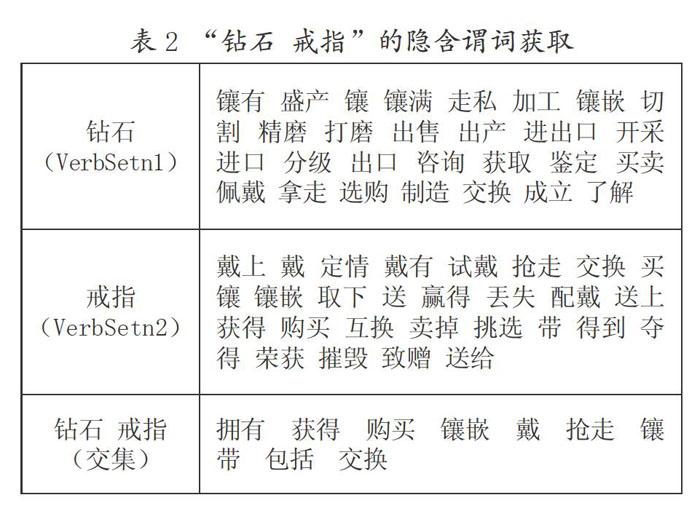
這里以“鉆石 戒指”為例,來探究一下是如何獲取隱含謂詞的,具體如表2所示:
表2給出了“鉆石”“戒指”這兩個名詞在subject_of和object_of語法關系下的搭配動詞樣例,以及它們交集的結果。可以看出,獲取結果中的“鑲嵌、鑲、交換、獲得”等動詞,能夠表達“鉆石”和“戒指”的語義關系。
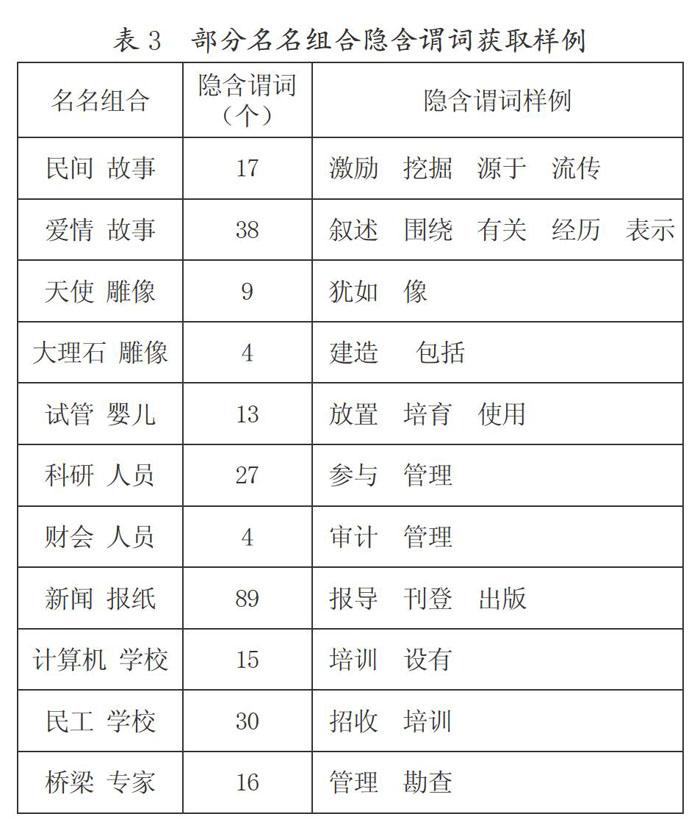
我們按照這一方法,獲取了部分名名組合隱含謂詞的結果,具體如表3所示:
表3給出了部分名名組合隱含謂詞的結果樣例,這里列出的只是顯著性最高的且正確的詞語。對于同一組具有相同中心詞的名名組合,隱含謂詞可以反映它們進行語義關聯的方式,如“民間 故事”主要用“流傳、源于、挖掘”等動詞進行釋義,強調的是故事的來源或發生地;而“愛情 故事”主要用“敘述、圍繞、表示”等動詞進行釋義,強調的是故事的內容。
四、相關結果分析
本研究從《人民日報》語料中抽取了424個高頻名名組合,并列出了部分樣例,具體如表4所示:
經過上述步驟,獲取到400個名名組合的隱含謂詞,有24個名名組合不能獲取隱含謂詞(即兩個集合的交集為空)。
我們為每個名名組合保留10個顯著性最高的謂詞,統計給出的候選中是否有正確的釋義出現,基于此就可以計算整個方法的準確率。我們逐一考察了這400個名名組合獲取的隱含謂詞,其中385個名名組合都有正確的隱含謂詞,只有15個名名組合獲取的謂詞完全不正確,準確率達到96.25%。
與以中心語或修飾語分類的方法相比,筆者所采用的方法具有一定的優越性。這里以名名組合“X公司”隱含謂詞的獲取結果為例,對此加以說明,具體如表5所示:
表5給出了一組具有相同中心詞的名名組合“X公司”,中心語相同時并不表示其構成關系相同,通過隱含謂詞可以有效地揭示其語義關系的差別。例如,“壽險 公司”使用“服務、經營、投資”等謂詞,而“飼料 公司”使用“制造、開發、制作”等謂詞,體現出這兩個公司的不同職能范圍。對于同一個名名組合,不同的隱含謂詞代表了各種可能的語義解釋,對于歧義具有分化作用,如“電影 公司”可以是“[制作/發行/管理]電影[的]公司”等。
本研究還對沒有獲取到隱含謂詞的24個名名組合進行了分析。這些名名組合可以分為兩類:第一類,如“國際 公司”“專業 市場”“外籍 人員”等名名
組合。把它們譯為英文時,一些名詞對應的是形容詞。如“國際 公司”的英文是“international corporation”,名詞“國際”變成了形容詞“international”。在英文名名組合的釋義任務中(參看SemEval2010 Task9),這類形容詞作為修飾語的情況是不包括在內的。而在漢語中,對于這部分名詞實際上充當了形容詞功能的名名組合,是很難找到合適的隱含謂詞的。第二類,如“皮包 公司”“文化 沉渣”“小康 步伐”等名名組合。認知語言學認為,名名組合是一種概念結合的產物,而“皮包 公司”是屬于特征映射型語義關系[18],在這一組合中,“皮包”已失去原來的指稱意義,而是指它所具有的特征。因此,對于這類名名組合,該方法是不能正確獲取隱含謂詞的。而“小康 步伐”其實是隱含了多個謂詞“[邁]步伐[進入]小康”,該方法對此類名名組合也不能獲取到隱含謂詞。
五、余論
漢語名名組合的語義類型復雜多變,難以窮盡,它是開放的,處于不斷的變化中。以基于隱含謂詞的動態策略探討漢語名名組合的語義解釋,是當前研究的趨勢和熱點。本文主要是利用Chinese Word Sketch獲取在指定語法關系下具有搭配意義的動詞,通過這一方法獲取的動詞仍是有限的,今后我們將借鑒英文的相關成果,進一步改進隱含謂詞的獲取方法,通過定義模板利用Web數據進行擴充。同時,在獲取到隱含謂詞后,將利用釋義模板恢復其完整的釋義短語。這一方法不僅可以為名名組合提供多種可能的語義解釋,而且能夠反映組成相似的名名組合之間細微的語義差別。其研究成果不但能夠服務于計算機語言信息處理的需求,而且可以為心理語言學關于概念組合認知機制的研究提供語義解釋的依據。
參考文獻:
[1]朱德熙.語法講義[M].北京:商務印書館,1982.
[2]李宇明.領屬關系與雙賓句分析[J].語言教學與研究, 1996.(3).
[3]袁毓林.謂詞隱含及其句法后果——“的”字結構的稱代規則和“的”的語法、語義功能[J].中國語文, 1995,(4).
[4][韓國]文貞惠.“N1(的)N2”偏正結構中Nl與N2之間語義關系的鑒定[J].語文研究,1999,(3).
[5]周日安.名名組合的句法語義研究[M].北京:中國社會科學出版社,2010.
[6]方清明.現代漢語名名復合形式的認知語義研究[D].廣州:暨南大學博士學位論文,2011.
[7]J.Zhao,H.Liu & R.Lu.Semantic labeling of compound nominalization in Chinese[A].Proceedings of the Workshop on A Broader Perspective on Multiword Expressions[C].2007.
[8]Downing,P.On the creation and use of English compound nouns[J].Language,1977,(4).
[9]Girju,R.,Moldovan,D.,Tatu,M. & Antohe,D.On the semantics of noun compounds[J].Computer Speech and Language,2005,(19).
[10]Diarmuid,? Séaghdha.Learning compound noun semantics[D].Ph.D.thesis,University of Cambridge,2008.
[11]Nakov,P.Noun compound interpretation using paraphrasing verbs:Feasibility Study[A].Proceedings of the 13th international conference on Artificial Intelligence:Methodology,Systems and Applications(AIMSA)[C].2008.
[12]Nakov,P. & Hearst,M.Using verbs to characterize noun-noun relations[A].Proceedings of the 12th international conference on Artificial Intelligence:Methodology,Systems and Applications(AIMSA)[C].2006.
[13]王萌,黃居仁,俞士汶,李斌.基于動詞的漢語復合名詞短語釋義研究[J].中文信息學報,2010,(6).
[14]魏雪.面向語義搜索的漢語名名組合的自動釋義研究[D].北京:北京大學碩士學位論文,2012.
[15]劉鵬遠,劉玉潔.中文基本復合名詞短語語義關系體系及知識庫構建[J].中文信息學報,2019,(4).
[16]Kilgarriff,A.,Rychly,P.,Smrz,P. & Tugwell,D.The sketch engine[A].Proceedings of the Eleventh Euralex Congress[C].2004.
[17]Huang,C.R.,Kilgarriff,A.,Wu,Y.,et al.Chinese sketch engine and the extraction of collocations[A].Proceedings of the Fourth SigHan Workshop on Chinese Language Processing[C].2005.
[18]劉正光.關于N+N概念合成名詞的認知研究[J].外語與外語教學,2003,(11).
Computational Research on the Semantics of Chinese Noun Compounds
Wang Meng1,Fu Yaru2,Hu Chun3
(1.2.School of Humanities, Jiangnan University, Wuxi 214122;
3.School of Foreign Studies, Jiangnan University, Wuxi 214122, China)
Abstract:The semantic analysis of noun compounds is to recover the implicit semantic relations between the head and modifier.In this paper, we adopt the downgraded predication theory to paraphrase Chinese noun compounds. Corpus is used to acquire the implying predicates automatically. The experiment results show that this approach can not only provide the possible interpretations for noun compounds but also reflect the interesting, detailed semantic differences of similar noun compounds.In addition, our research can be applied in some other fields such as question answering, information retrieval and language teaching, and provide semantic interpretation for the study of cognitive mechanisms of concepts combination in psycholinguistics.
Key words:noun compounds;semantic analysis;implying predicates;corpus
