基于BP神經網絡的代碼壞味檢測
2020-10-16 06:31:48王曙燕張一權孫家澤
計算機工程 2020年10期
王曙燕,張一權,孫家澤
(西安郵電大學 計算機學院,西安 710000)
0 概述
FOWLER等人[1]在1999年提出了“代碼壞味”的概念,其指軟件開發過程中可能會出現的代碼問題。代碼壞味檢測是通過重構步驟解決源代碼(或設計)問題的既定方法,其目的是提高軟件質量和維護效果。FOWLER等人一共提出了22種代碼壞味,包括克隆代碼、特征依戀和長方法等。代碼壞味及其檢測方法極大地推動了自動化軟件重構的應用和發展,成為軟件重構領域的研究熱點之一。
目前,研究人員設計出很多代碼壞味檢測工具,具有代表性的包括DECOR、IPlasma、InFusion、JDeodorant、PMD以及Checkstyle,這些工具基于一組度量和規則來檢測特定代碼壞味,如眾所周知的面向對象的度量或者為檢測特定壞味而臨時定義的度量。根據檢測規則,用于通過不同工具檢測代碼壞味的度量可以是不同的,不同的工具對同一種代碼壞味的檢測結果也不同。此外,即使度量標準相同,度量標準的閾值也可能發生變化,從而使得檢測到的壞味數量相應地改變。檢測工具的另外一個問題是檢測準確性普遍較低,會檢測到許多假陽性壞味。上述問題推動了研究人員對代碼壞味檢測方法進行分析并提出了一系列的自動或半自動改進方法,以從代碼中檢測壞味[2]。其中,JDeodorant[3]是由TSANTALIS等人設計的代碼壞味檢測工具,該工具利用杰卡德距離衡量2個代碼實體之間的相似性。文獻[4-6]研究表明,在不同的代碼壞味檢測算法中,特征度量和閾值存在差異,不同的方法選取的度量值和閾值也有所不同,這就導致在代碼壞味檢測中沒有一個具體的標準[2]。學者們為了解決該問題,提出基于各類機器學習算法的代碼壞味檢測方法,但是這些方法也存在一定的局限性。NUCCI等人[7]通過大量實驗,指出在機器學習算法的檢測過程中,代碼壞味數據集普遍僅存在一種類型的壞味,這并不符合實際情況,因為在軟件開發中代碼壞味不可能只存在單一類型,通過實驗可知在數據集中存在不同類型的代碼壞味,機器學習算法在對其檢測時準確率較低,說明了不同類型的代碼壞味分布在數據集中時減弱了機器學習算法對代碼壞味的檢測能力。
本文將BP神經網絡(BPNN)與常見的軟件度量項相結合,以對代碼壞味進行檢測。合并不同類型的代碼壞味,使數據集中存在不同的壞味類型,將常見的軟件度量特征與代碼壞味實例進行相對應的編碼,根據數據集中的標簽信息實現有監督深度學習。利用神經網絡在自動選擇原始數據特征方面的優勢,提取出這些度量項之間的相互關系,使度量特征項與代碼壞味實例完成映射建模,同時模型學習輸入的代碼壞味特征中的復雜關系規則,從而對代碼壞味實例進行分類。由于有監督的深度學習通常需要大量的標記數據作為訓練樣本,因此本文借助2種代碼壞味檢測工具針對4種類型的代碼壞味實例進行提取,檢測程序主要包括Apache中的7個Java開源項目。
1 相關工作
目前的代碼壞味檢測方法主要分為兩大類,一類為基于規則的方法,這些方法主要依賴于度量,在某些情況下還有與代碼結構和命名相關的其他規則;另一類方法使用機器學習技術,這些技術主要基于度量進行代碼壞味檢測。
基于規則的方法較復雜,因為它們使用的信息來源多于基于度量的機器學習方法,如命名規則[8]、結構規則[8]以及軟件版本歷史[9]。章曉芳等人[10]考慮到代碼壞味與軟件演化中的源文件操作關系,探究包含壞味的文件在軟件版本歷史中的不同特征,研究結果表明,有幾種特定的壞味對文件的修改產生了顯著影響。另一方面,基于規則的方法依賴于人為手動創建的規則。例如,DECOR要求規則為特定的語言形式,并且此規范過程必須由領域專家、工程師完成[11]。然而,基于度量的機器學習方法是否比基于規則的方法需要更少的人為干預不得而知,它取決于2個因素:1)基于規則的方法需要什么復雜程度的規則;2)基于度量的機器學習方法需要多少訓練樣本[12]。基于度量的機器學習方法的明顯優勢是減少了開發人員的工作壓力,基于規則的方法要求工程師創建定義每種氣味的特定規則。對于基于度量的機器學習方法,由機器學習算法創建規則,要求工程師僅提供一段代碼是否有氣味的信息。
研究人員提出了基于各類機器學習算法的代碼壞味檢測方法。KREIMER[13]提出了一種自適應檢測方法,該方法將基于度量與學習決策樹的基礎方法相結合,對過大類和長方法的2種代碼壞味類型進行檢測,并且在IYC系統和WEKA工具上完成分析。該方法適用于特定的場景,但在識別不同的代碼壞味時會因為度量規則而存在性能差異。KHOMH等人[14]提出了BDTEX方法,其為一種目標問題度量方法,根據反模式的定義構建貝葉斯信任網絡,并在2個開源程序上使用Blob反模式、功能分解和Spaghetti Code反模式驗證BDTEX方法。MAIGA等人[15]利用一種基于支持向量機的檢測方法在3個開源程序中進行反模式檢測,該方法的F1值達到80%左右,但是準確度較低。YANG等人[16]通過在克隆代碼上應用機器學習算法研究開發人員對代碼壞味的判斷。PALOMBA等人[17]提出一種基于信息檢索技術,利用程序中的文本信息進行壞味檢測。FONTANA等人[12]將幾種常見的機器學習算法應用在各類代碼壞味檢測中,并總結了J48、隨機森林以及貝葉斯網絡等幾種表現較好的機器學習算法。但是,在利用機器學習算法對代碼壞味進行檢測的過程中,數據集包含的有壞味與無壞味實例之間的度量分布不同,實例的選擇可能會導致機器學習算法對壞味的檢測性能下降。劉麗倩等人[18]針對數據不平衡對機器學習算法的影響問題,將決策樹算法與代價敏感學習理論相結合以對長方法進行檢測,研究結果表明,其能提高長方法的檢測查準率和查全率。卜依凡等人[19]將代碼中的文本信息和軟件度量相結合,通過一種基于深度學習技術的方法對上帝類代碼壞味進行檢測,實驗結果表明,該方法對上帝類代碼壞味的檢測性能優于代碼壞味檢測工具JDeodorant,尤其是在查全率上優勢明顯。
上述基于機器學習的方法在進行代碼壞味檢測時取得了較好的檢測效果。但是,此類方法僅考慮數據集中包含受單一類型壞味影響的實例的情景,并不符合軟件開發過程中出現各種類型代碼壞味的實際情況。本文基于BP神經網絡,對同一種數據集中存在不同類型代碼壞味和無壞味的情況進行代碼壞味檢測。
2 相關知識
BP神經網絡具有高效非線性數據函數映射逼近功能,其為一種功能強大的數據建模工具,能夠捕獲和表示復雜的輸入與輸出關系[20]。
2.1 網絡初始化
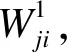
(1)
其中,f(·)為激活函數,在輸出層輸出過程中使用Softmax激活函數,將其設置為3個單元表示輸出代碼壞味特征類型。Softmax激活函數可以將多個神經元的輸出映射到(0,1)區間,選取概率最大的分類作為代碼壞味預測結果。
2.2 輸出值計算
在BP神經網絡模型中,層與層之間存在計算線性關系,在網絡初始化完成之后,需要為每層選擇合適的激活函數,目的是為了盡可能多地得到神經網絡中每層之間學習輸入數據的線性變換集合空間,從而充分利用多層表示的優勢。在網絡中,隱藏層學習輸入層數據的線性變換(網絡中間一層使用ReLU激活函數),ReLU激活函數用于隱藏層神經元輸出,當輸入x<0時,輸出為0,當x>0時,輸出為x,該激活函數使神經網絡更快收斂,計算公式如式(2)所示:
φ(x)=max(0,x)
(2)

(3)
2.3 模型訓練
為了使BP神經網絡對代碼壞味進行可靠的預測,必須對BP神經網絡進行適當訓練。在訓練過程中,BP神經網絡算法利用梯度下降法尋找最優解,在輸出層和隱藏層之間,通過誤差值按權重比例進行分割,計算出每條鏈接相關的特定誤差值,通過重組這些誤差值得到隱藏層神經元節點相關聯的誤差值,再次將這些誤差值按照輸入層和隱藏層之間的權重進行分割,完成誤差的反向傳播。其中,最主要的步驟是更新層與層之間的權重值和閾值,更新規則表達式如式(4)~式(7)所示:
(4)
θ2=θ2+β·(Ypred-Yreal)·Ypred·(1-Ypred)
(5)
(6)
(7)
其中,α和β為學習率,在訓練過程中,需要獲取BP神經網絡的目標輸出,Yreal為代碼壞味真實值,將其作為最終的目標輸出。如果目標輸出Yreal與預測目標Ypred之間的誤差小于當前設定的閾值,或者訓練迭代輪數達到預設的閾值,則完成模型訓練。
3 基于BP神經網絡的代碼壞味檢測方法
機器學習算法在對代碼壞味進行檢測的過程中,數據集中只包含一種類型的代碼壞味,并不能反映軟件設計過程中存在的實際問題。本文提出基于BP神經網絡的代碼壞味檢測方法,針對數據類(Data class)、上帝類(God class)、長方法(Long method)和特征依戀(Feature envy)4種壞味類型進行分類,并將4種類型合并為方法級別和類級別2種類型的數據集,使數據集中包含不同的壞味類型。表1所示為4種類型的代碼壞味描述。

表1 代碼壞味描述Table 1 Description of bad smell in code
利用神經網絡對代碼壞味進行檢測,是將度量特征信息與標簽信息組成的向量形式作為神經網絡輸入層的輸入,通過網絡得到特征并輸入到目標函數的神經網絡分類器中進行訓練,分類器的預期輸出為樣本的標簽,在經過多次迭代訓練后,可以得到最終被訓練好的神經網絡分類器。圖1所示為本文代碼壞味檢測方法的流程。

圖1 基于BP神經網絡的代碼壞味檢測方法流程Fig.1 Procedure of detection method of bad smell in code based on BP neural network
3.1 數據集預處理
在對數據集進行預處理時需要提取代碼壞味實例、度量特征以及標簽,由于不同的研究人員對度量特征提取的結果不同,本文主要按以下度量項來提取代碼壞味度量特征:
1)數據類:耦合強度(CINT)和類耦合類數(CBO)。
2)上帝類:訪問外部數據數(ATFD)、類的圈復雜度(WMC)、類中通過訪問相同屬性而發生連接的方法對個數(TCC)。
3)特征依戀:訪問外部數據數(ATFD)、屬性訪問的位置(LAA)、提供外部數據數(FDP)。
4)長方法:代碼總行數(LOC)、方法數(NOM)、屬性數(NOA)。
提取度量特征、代碼壞味實例與標簽的具體步驟如下:
步驟1針對4種代碼壞味類型,使用代碼壞味自動檢測工具iPlasma和Checkstyle對開源軟件系統進行檢測,提取代碼壞味實例和無壞味實例并對其進行標記,生成標簽。
步驟2計算有代碼壞味實例和無代碼壞味實例的度量特征。使用浮點數序列對有代碼壞味和無代碼壞味實例度量特征進行編碼表示,其中,0代表某度量特征不是代碼壞味影響因素,純小數值代表某度量特征是影響代碼壞味的因素。
步驟3將步驟1和步驟2中的度量特征和標簽進行合并,生成方法級別和類級別的2種數據集,以此構成訓練集。
利用度量特征和標簽構成訓練集的具體實現過程如下:
將得到的度量特征與標簽信息進行合并,并將度量特征與標簽信息轉換為向量表示〈m11,m12,…,p1n〉,m表示度量特征,p表示標簽。合并之后的2種代碼壞味訓練集結構為:每一行代表代碼壞味實例,每一列代表度量特征,最后一列為標簽信息,以此形成一種矩陣數據M。
3.2 神經網絡模型設計
AHSAN等人[21]在肌電圖(EMG)信號的基礎上,利用人工神經網絡檢測不同的預定義手部運動(上、下、左、右),所設計的網絡能夠成功識別手部運動。王毅等人[22]將卷積神經網絡和長短期記憶神經網絡相結合,對用戶偽裝入侵模式的缺陷進行檢測,其檢測效果優于基準系統,從而驗證了該方法的有效性。神經網絡在分類方面具有優勢,利用BP神經網絡模型可以較好地預測代碼壞味。BP神經網絡模型結構如圖2所示。
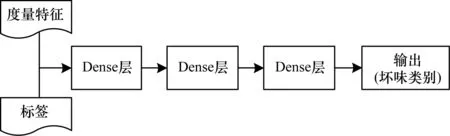
圖2 BP神經網絡分類模型結構Fig.2 Structure of BP neural network classification model
在對數據集進行預處理后,將數據集輸入到神經網絡模型中,代碼壞味檢測的具體步驟如下:
輸入帶有標簽的代碼壞味矩陣數據樣本M
輸出代碼壞味類別
步驟1建立神經網絡分類器模型,構建的神經網絡結構采用全連接形式,第1層為一個輸入層,第2層是隱藏層,網絡的最后一層是輸出層,輸出層采用Softmax函數并輸出代碼壞味的類別。
步驟2將數據集預處理之后的代碼壞味度量特征的矩陣數據M作為輸入層的輸入,將標簽信息作為網絡輸出基準,表示為Yreal,輸出層的輸出值表示為Ypred,如果Yreal與Ypred之間的誤差小于當前設定的閾值或者訓練迭代輪數達到閾值,則完成神經網絡對代碼壞味預測輸出的訓練,否則返回神經網絡輸入層進行模型訓練。
步驟3將FONTANA等人提出的代碼壞味公開數據集作為基準代碼壞味測試集,并且按照數據集預處理過程中所述方式對測試數據進行合并與向量形式轉換。將得到的測試集輸入訓練好的神經網絡模型中,模型自動輸出預測的代碼壞味類別。
3.3 評估模型
在訓練與測試階段需要監控樣本上的損失和精度,并以準確度(Accuracy)、F1值以及AUC值評價指標評估神經網絡模型的分類性能。準確度、F1值具體計算公式如式(8)~式(11)所示:
(8)
(9)
(10)
(11)
其中,TP代表樣本正類,TN代表樣本負類,FP為將錯誤的樣本分類成正確樣本的數量,FN則是將正確樣本分類成錯誤樣本的數量。
F1值可以看作模型精確率和召回率的一種加權平均值,取值范圍為0~1。在分類任務中,期望精確率和召回率都達到很高,但實際上不可能實現。因此,需要獲取兩者之間的平衡點,而F1值可以看作此平衡點,F1值越高說明精確率和召回率同時達到較高且取得了平衡。
AUC值被定義為ROC曲線下的面積,其不受閾值的影響。作為數值類型,AUC值越大的分類器效果越好。
4 實驗驗證
NUCCI等人對FONTANA提出的代碼壞味公開數據集進行合并,使其中擁有不同的壞味類型。本文基于該數據集,在相同的條件下利用Weka工具提供的機器學習算法和本文方法分別進行代碼壞味檢測,以驗證本文代碼壞味檢測方法的性能。
4.1 實驗過程
本文實驗在Ubuntu14.04 LTS環境下進行,模型代碼基于Keras深度學習框架實現,使用Tensorflow作為計算后端引擎。神經網絡模型采用全連接形式,以batch size=10的形式組成小批量對網絡進行梯度更新,網絡的訓練迭代輪數epoch設置為500。
本次實驗通過代碼壞味檢測工具對7個Java開源項目進行檢測,以獲取代碼壞味實例,并將數據類、上帝類、特征依戀以及長方法的4種數據集進行合并,生成類級別和方法級別的2種類型數據集,使代碼壞味數據集中包含不同壞味類型以及度量特征值。利用FONTANA等人[12]提出的公開代碼壞味數據集作為基準測試集,對訓練好的模型進行測試。具體過程如下:
1)對數據集中的度量特征、代碼壞味實例以及標簽進行預處理。本文利用代碼壞味自動檢測工具獲取到代碼壞味實例并進行標記生成標簽,結合度量特征與標簽信息得到代碼壞味訓練集。考慮到基準數據集為Arff格式,不利于輸入BP神經網絡,本文利用Python實現CSV數據集格式與Arff數據集格式的相互轉換。為了驗證代碼壞味預測模型的實際能力,將上帝類和數據類的數據集合并為類級別的數據集,將特征依戀和長方法的數據集合并為方法級別的數據集。合并之后的2種數據集分別包含840種代碼壞味實例。
2)神經網絡模型訓練。將預處理后的代碼壞味數據集作為網絡輸入層的輸入,標簽值作為網絡的預期輸出,實現網絡對代碼壞味分類輸出的訓練,從而得到BP神經網絡分類模型。
3)模型優化。在模型優化階段,利用十折交叉驗證法驗證模型對代碼壞味的預測精度,以避免在訓練過程中出現過擬合現象。模型以分類交叉熵作為損失函數,降低BP神經網絡對代碼壞味的預測錯誤率,選擇自適應學習率的Adam進行模型參數學習。
4.2 結果分析
實驗從以下3個方面分析本文基于BP神經網絡的代碼壞味檢測方法與NUCCI等人使用的機器學習算法在相同數據集上的代碼壞味檢測結果:
1)數據集中包含不同類型的代碼壞味對于神經網絡分類器的效果影響。為了探究數據集中存在不同類型的代碼壞味對神經網絡分類器檢測效果的影響,將方法級別和類級別的代碼壞味數據集分別作為神經網絡的分類輸入。各檢測方法在不同數據集中的準確度、F1值和AUC值結果分別如表2~表5所示。
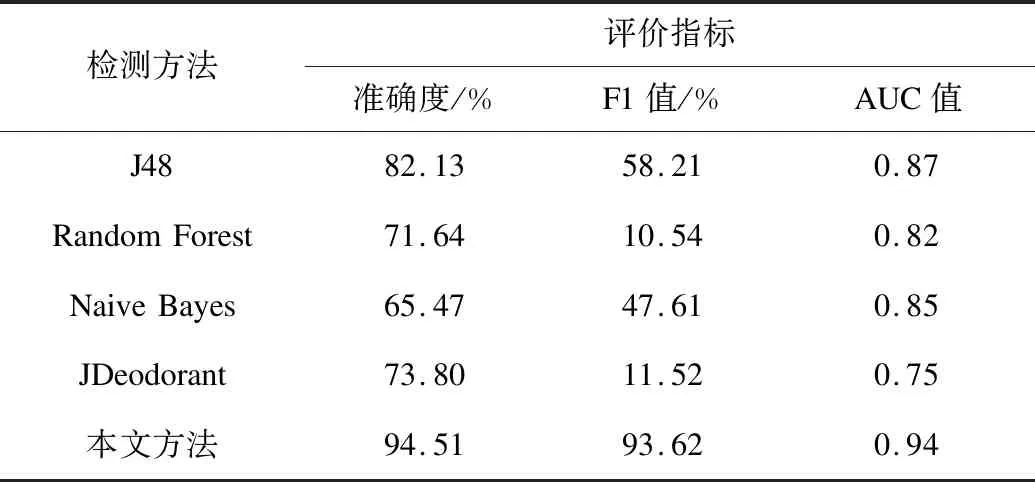
表2 數據類數據集的測試結果Table 2 Test results of Data class dataset
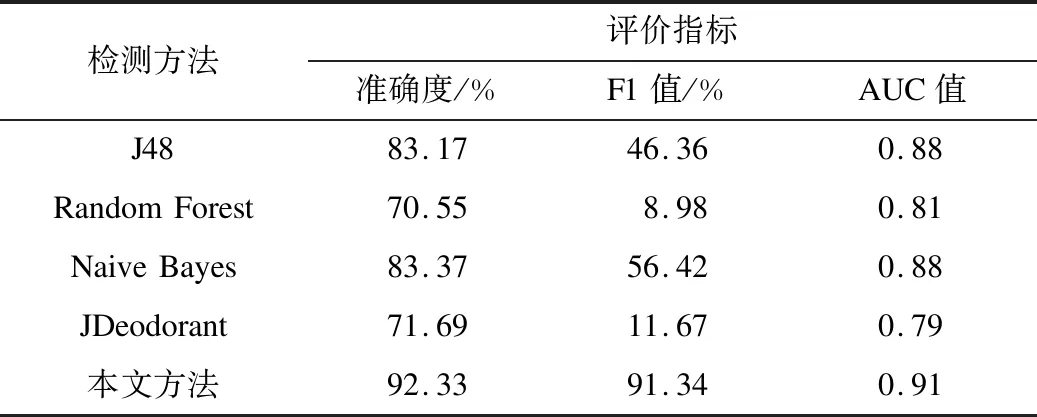
表3 上帝類數據集的測試結果Table 3 Test results of God class dataset

表4 特征依戀數據集的測試結果Table 4 Test results of Feature envy dataset
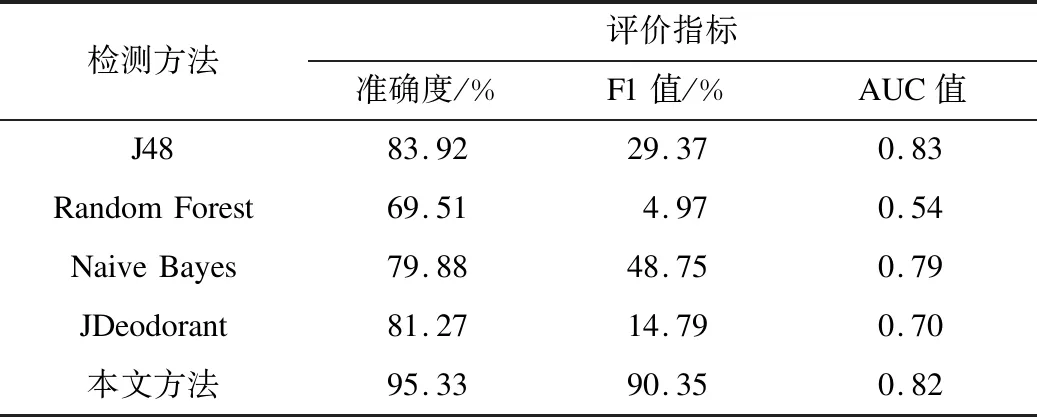
表5 長方法數據集的測試結果Table 5 Test results of Long method dataset
實驗結果表明,本文方法在數據集存在不同壞味類型的情況下,平均準確度達到91.63%,平均F1值達到87.63%,在AUC值上與其他檢測方法相比沒有明顯差別,但在分類整體效果上優于其他檢測方法。以J48方法為例,本文方法在平均準確度上提高了9.26%,平均F1值提高了41.75%。對比基于度量和規則的代碼壞味檢測工具JDeodorant,本文方法在平均準確度上提高了16.03%,平均F1值提高了74.33%。綜合基于機器學習的代碼壞味檢測方法和基于度量的代碼壞味檢測工具JDeodorant,本文方法在總體平均準確度上提升了15.19%,平均F1值提升了58.39%。
2)神經網絡模型構建過程中的參數設置。在利用BP神經網絡模型檢測代碼壞味的過程中,網絡隱藏層神經元的數量選擇尤為重要。根據2種數據集含有不同的代碼壞味特征,本文對類級別數據集和方法級別數據集的模型神經元個數設置如表6所示。

表6 神經元數量設置Table 6 Number setting of neurons
在網絡中,隱藏層采用ReLU激活函數,輸出層采用Softmax激活函數。
3)代碼壞味分類的準確度。為了能夠形象描述本文模型在訓練階段與測試階段的代碼壞味分類準確度,記錄樣本在分類過程中的準確度,結果如圖3~圖6所示。從中可以看出,神經網絡分類器在迭代輪數為400~500時能達到最佳整體分類性能。
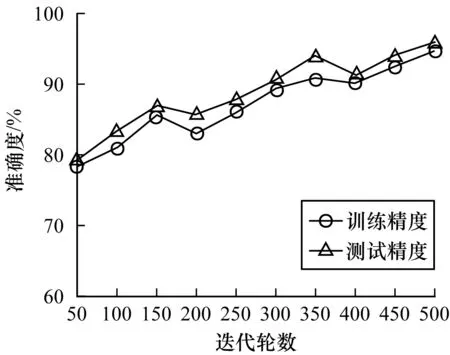
圖3 數據類數據集的準確度Fig.3 Accuracy of Data class dataset
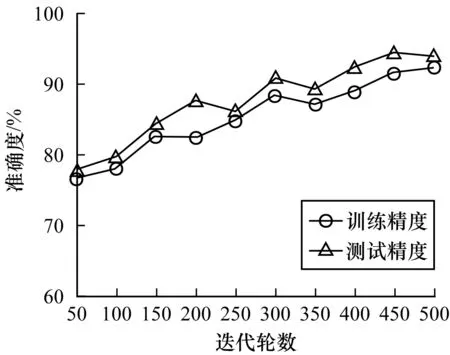
圖4 上帝類數據集的準確度Fig.4 Accuracy of God class dataset
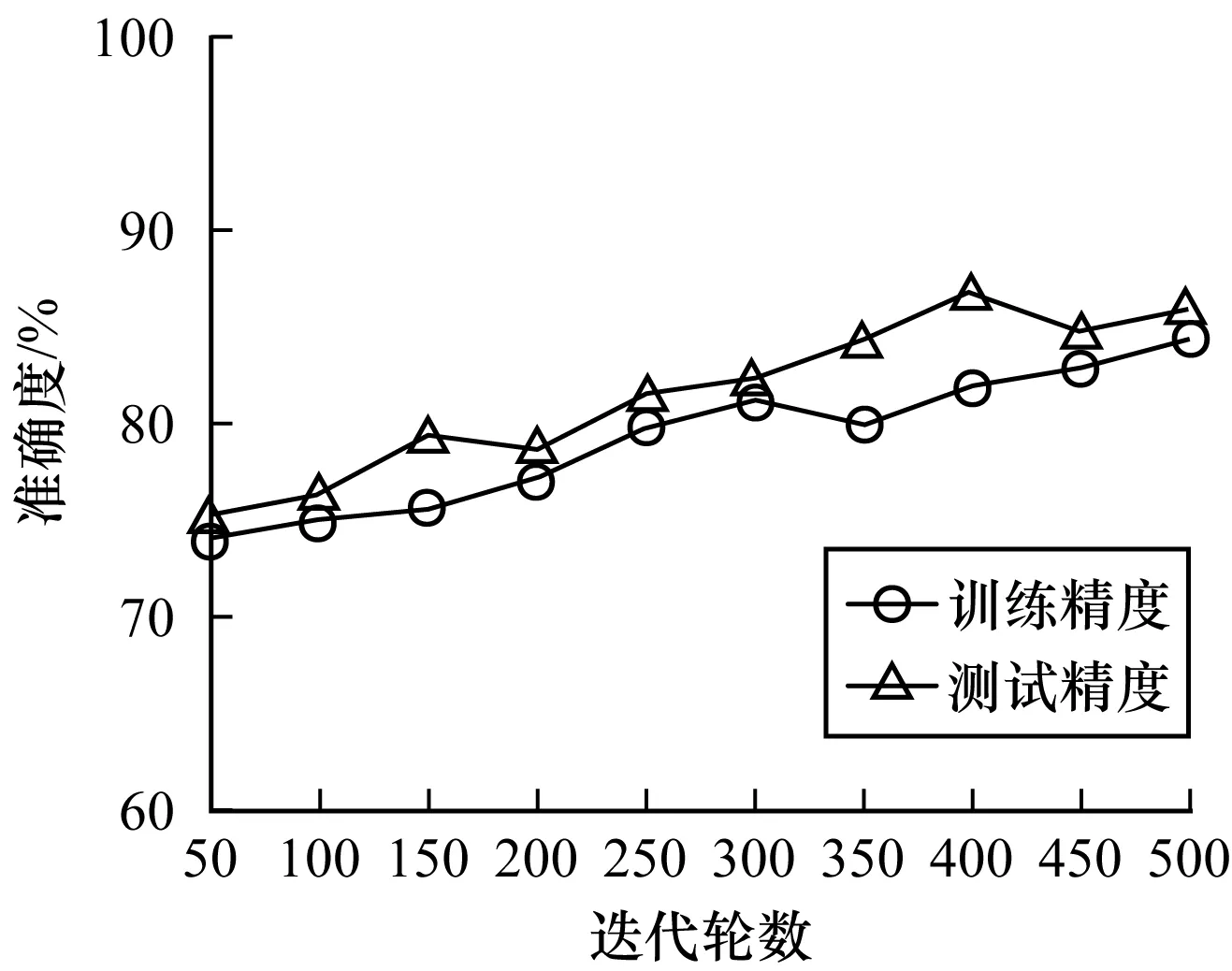
圖5 特征依戀數據集的準確度Fig.5 Accuracy of Feature envy dataset

圖6 長方法數據集的準確度Fig.6 Accuracy of Long method dataset
5 結束語
代碼壞味檢測對程序質量具有重要影響,本文提出一種基于BP神經網絡的代碼壞味檢測方法,將常見的軟件度量特征項與代碼壞味實例信息相結合,并將收集到的代碼壞味類別合并成類級別和方法級別的2種類型數據集,以此作為神經網絡模型的輸入,模型輸出代碼壞味的分類類別。實驗結果表明,與J48、Random Forest等代碼壞味檢測方法相比,該方法在測試集上的整體效果更優。
在實際的代碼壞味檢測中,收集到的相關數據集中正樣本數量與負樣本數量存在很大的不平衡性,影響了預測結果的準確度,為解決該問題,研究人員通常手動選取數據集的正負樣本數量,以達到數據集的正負樣本平衡,該方式會耗費大量的人力且難以保證檢測結果的正確性。因此,下一步將基于生成式對抗神經網絡對代碼壞味進行檢測,以解決數據集正負樣本不平衡的問題。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
