改進YOLOv3網絡在圖像中評價空氣質量
2020-10-19 04:41:14鄧益儂羅健欣金鳳林畢鵬程
計算機工程與應用 2020年20期
鄧益儂,羅健欣,張 琦,劉 禎,胡 琪,金鳳林,畢鵬程
1.陸軍工程大學 指揮控制工程學院,南京 210007
2.南京小吉狗網絡科技有限公司,南京 210000
1 引言
空氣質量指數(AQI)是定量描述空氣質量狀況的無量綱指數。空氣質量按照AQI的大小分為六級,一到六級分別為優,良,輕度、中度、重度和嚴重污染。同時針對單項污染物還規定了六項空氣質量分指數,分別描述細顆粒物、可吸入顆粒物、二氧化硫、二氧化氮、臭氧、一氧化碳的含量。其中可吸入顆粒物與其他污染物相比,能夠直接進入肺泡,對人類健康的危害最大。世界各國普遍使用PM2.5濃度值作為可吸入顆粒物污染指數的衡量指標,近十年人們進行了大量研究旨在評價各種環境下的空氣質量指數,特別是PM2.5濃度值的估計。目前對于PM2.5的精確測量主要依托傳感器實現,例如中國環境監測總站利用動態加熱系統檢測PM2.5的β 射線吸收[1],然而,現有的高質量PM2.5監控傳感器花費在數萬美元以上,而且維護成本高,導致其大范圍部署不切實際。以北京為例,16 411平方公里的城市面積僅部署了35 個固定傳感器來收集PM2.5數據(見圖1(a)),即使是居住密集區也只有22個空氣質量監測站點(見圖1(b))。因此稀疏分布的PM2.5監控系統無法在城域范圍內提供細粒度的測量。由于部分特殊區域例如工廠,交通樞紐附近的PM2.5濃度值可能會遠高于城市平均水平,所以人們更關注于實時的空氣質量檢測結果,以避免接觸到空氣中的致癌物。雖然設計低質量便攜式傳感器是一種解決思路,但是由于技術問題在沒有被集成到智能手機之前,人們不會隨身配備專門的空氣質量檢測器。與此同時如圖2 所示[2],隨著圖像識別技術的發展,利用城市空氣質量視覺日志并基于圖像檢測的環境空氣質量評價方法得到了廣泛研究。相比于傳感器采集局部空氣物理數據的方式,基于圖像檢測的方法只需使用攝像頭就可以采集到各種尺度(最大數公里級別)區域的環境圖片信息,然后通過視覺分析或者深度學習算法提取和分析圖片中的數據特征,即可便捷和高效地完成對環境空氣質量的評價,這也促進了使用智能手機實時估計周圍空氣質量的模式成為可能。
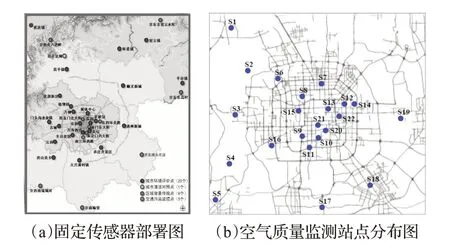
圖1 北京市空氣質量監測站分布圖
本文在圖像檢測算法的框架下,提出了一種基于卷積投票模型的空氣質量評價方法,對傳統直接套用深度學習模型進行空氣質量檢測的算法做出了改進。卷積投票網包含多錨點檢測機制和卷積投票網兩個模塊,適用于非固定場景下的空氣質量指數評估,以及固定場景下的PM2.5濃度預測,旨在得到當前周圍環境下空氣質量的實時評價。應用場景如圖3 所示[3],其中空氣質量指數分為優、良、輕度污染、中度污染、重度污染以及嚴重污染六個級別,而PM2.5濃度單位為μg/m3。
2 相關工作
目前,基于圖像檢測的空氣質量指數和PM2.5濃度預測方法有三種[4],分別基于視覺特征[5-6]、能見度特征[7-9]以及深度特征[10-11],其評價示例如圖4所示[12]。
Yang 等人[5]利用相對濕度校正從預處理圖像中提取的傳輸特征,并提出了一種基于學習(LB)的方法來估計PM2.5濃度。Spyromitros-Xioufis 等人[6]結合深度學習的方法對視覺特征進行處理,首先利用GoogLeNet[13]自動提取圖像的天空部分,然后對檢測區域的像素顏色值的統計量進行操作估計。但是由于視覺特征主要是人工設定的HOG[14]和SIFT[15]等特征,以及顏色直方圖這類原始的圖像參數信息,很難通過處理這些與空氣質量的相關性較低的特征得到滿意的檢測結果。

圖2 北京空氣質量視覺日記

圖3 兩種空氣質量評價問題
圖4 基于圖像檢測技術的空氣質量指數評價
相比于視覺特征,能見度特征更加適用于表征空氣受污染的程度,大多數方法基于光學物理模型和亮度對比度進行分析。例如Kim 等人[7]基于HIS 模型,利用顏色差估計場景的可見性。Liu 等人[8]則提出一種霧度模型,通過環境傳輸圖的混濁度來反映空氣質量。此外Poduri等人[9]將截取的局部天空區域的光強特征與天空亮度模型進行比較進而得到評價結果。然而由于能見度特征的表現受光圈、快門等相機參數的影響較大,在手機上使用攝像頭進行能見度評估的可行性仍有待進一步探討。
相比之下近年來基于深度學習挖掘環境圖像深度特征的方法成為了研究熱點,利用LeNet[16]、AlexNet[17]、VGG[18]、GoogLeNet 以及 ResNet[19]等卷積神經網絡模型結構可以提取到語義信息更為豐富的深度特征。例如Wang 等人[10]基于AlexNet 構建了一個雙通道卷積神經網絡,利用每個通道訓練環境圖像的不同部分進行特征提取,同時提出一種特征權重自學習方法,對提取的特征向量進行加權和連接,并使用融合的深度特征向量來測量空氣質量。還有的方法[11]嘗試結合空氣質量變化的規律特征信息,基于長期短期記憶網絡(LSTM)[20]構建模型,對城市空氣質量指數進行檢測甚至是預測。
但是由于無法直接解釋深度特征與空氣質量的相關性,任何模型對深度特征的理解都需要基于大量訓練數據的統計特性,因此在得到表征能力更強的深度特征時,也會伴隨產生較多的噪聲特征,干擾模型的評價結果。總體上,基于圖像檢測的空氣質量評價方法的對比舉例如表1所示。

表1 基于圖像檢測的空氣質量評價方法對比
3 本文的研究內容和主要貢獻
總體上,將基于深度學習的方法應用到空氣質量評價中有以下兩點問題:一方面,如前文所述,由于空氣質量特征本身抽象度較高,經過卷積操作往往與其他噪聲特征糅雜在一起,因此需要將噪聲特征進行過濾;另一方面,相比于其他物體檢測任務,反映空氣質量的特征并不集中于圖像的某一塊區域,而是散布于整幅圖像,因此需要加強網絡模型針對細節提取小尺度特征的能力。目前很多方法借鑒了目標檢測領域比較成熟的檢測方法,并在此基礎上,圍繞上述問題對現有的網絡模型進行了針對性的改進。例如張富凱等人[22]對傳統的YOLOv3[23]算法進行了改進,首先增強深度殘差網絡,而后通過多尺度特征提取以及特征圖融合機制,提升網絡模型對復雜環境下小目標的檢測能力。徐誠極等人[24]則將一種注意力機制引入YOLOv3算法,將通道注意力及空間注意力機制加入特征提取網絡之中,使用經過篩選加權的特征向量來替換原有的特征向量,達到過濾特征噪聲的目的。另外陳幻杰等人[25]提出了一種改進的多尺度卷積特征目標檢測方法,用以提高SSD[26]模型對中目標和小目標的檢測精確度。該方法對SSD 模型低層特征層采用區域放大提取的方法以提高對小目標的檢測能力。還有的方法直接對圖像質量進行評估,例如Li等人[27]將顯著性檢測與人類視覺系統(HSV)相結合,使用HSV空間中的灰色和顏色特征訓練模型對圖像進行去噪。類似于上述方法的研究思路,本文在現有網絡模型的基礎上,設計了專門的機制來提取圖像細節特征并過濾掉深度特征中噪聲的干擾。首先在訓練網絡模型之前對數據集進行了預處理,將空氣質量的檢測轉換為一個多錨點(anchor)的回歸和分類過程,有效地監督了網絡對圖像各個區域的細節特征進行學習,然后使用卷積投票模塊對所有錨點的檢測結果進行分析和過濾,剔除掉不合理錨點位置上卷積產生的噪聲影響,形成最終的空氣質量指數和PM2.5濃度評價。
鑒于YOLOv3在圖像檢測上的優越性能,本文利用該網絡模型提取和分析空氣質量深度特征,并基于darknet[28]框架以方便算法在不同平臺間進行移植。一方面,YOLOv3 使用darknet-53 作為主要的特征提取網絡,其結構是從各主流網絡選取性能比較好的卷積層進行整合得到,同時由于各層使用了3×3和1×1的小尺寸卷積核,減少了各層的卷積操作數目,保證了較高的檢測效率。除此之外,小卷積核也有利于網絡模型對小尺度的目標進行檢測。由于空氣質量信息反映于圖像的像素細節,因此基于小卷積核進行特征提取有利于捕獲與空氣質量相關的細節特征;YOLOv3的具體網絡結構如圖5 所示。另一方面darknet 框架本身完全由C 語言實現,沒有任何依賴項,雖然最初構建于Linux環境,但darknet 作為輕型的深度學習框架便于移植。由于評估空氣質量的工作需要在不同的手持設備上進行,因此選擇darknet 框架,有利于在不同平臺終端進行檢測模型的本地端部署。本文在進行空氣質量的檢測研究時,使用的是darknet在Windows上的移植版本。
本文的主要貢獻在于:
(1)本文針對非固定場景下的空氣質量指數評估,以及固定場景下的PM2.5濃度預測兩個問題,提出了基于卷積投票模型的空氣質量評價方法,該模型包含多錨點檢測算法和卷積投票算法兩個模塊,是對圖像檢測算法在空氣質量評價任務中的擴展和改良。
(2)在卷積投票模型中,設計了多錨點檢測機制用于提取和分析空氣質量深度特征。通過在一幅圖像上設置多個錨點檢測位置,以及相對應的錨點檢測框(anchor box),可以監督網絡同時得到不同圖像區域特征的檢測結果,包括小尺度錨點檢測框對圖像局部域特征的檢測結果,大尺度錨點檢測框對圖像全域特征的檢測結果,以及中心位置錨點檢測框對圖像中心域特征的檢測結果。
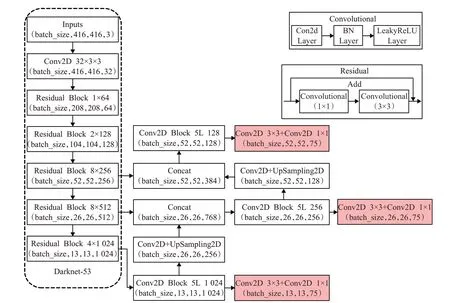
圖5 YOLOv3網絡結構圖
(3)在卷積投票模型中,構建了卷積投票網對多錨點檢測算法得到的結果進行進一步分析。基于所有錨點給出結果的置信度高低,過濾掉不合理卷積操作產生的噪聲影響,修正多錨點檢測機制的評價結果。同時對比了不同卷積投票策略下,算法估計精度的變化。最后通過競賽印證了本文所述方法的有效性。
4 多錨點檢測
目前效果較好的基于深度學習的圖像檢測算法,例如Faster-RCNN[29]、SSD、YOLO系列[23,30-31]都使用了錨點(anchor)作為基本的檢測機制。本文所借鑒的算法YOLOv3,其做法是將圖像平均劃分為多個單元(cell),然后在每個cell里面放置一個錨點,每個錨點負責預測若干個子框(box)。YOLOv3 的錨點檢測框(anchor box)機制相當于在圖像上均勻散布密集的檢測錨點,提取以錨點為中心,檢測框大小的圖像域進行分析。YOLOv3在每張圖片上共產生10 647個錨點檢測框,相當于對圖像上以錨點為標記的各個區域特征進行窮舉分析。
錨點檢測框在回歸邊界盒大小時只參照圖片有效區域的大小,即真實值(Ground truth),這種機制適用于目標檢測任務,即圖像上只有少量有效的目標區域特征,其余均為無效的背景特征。但是在空氣質量檢測問題中整幅圖像都是有效目標區域,這使得一些直接套用目標檢測網絡模型的方法只能基于圖像的全局域特征進行空氣質量指數等級的大致分類。而本文的方法旨在發揮錨點檢測框機制在分析和提取局部圖像特征的優勢,將傳統方法的單一分類轉化為基于錨點檢測框機制的數值回歸,使模型在估測具體的PM2.5濃度數值時也有較好的精度。但是本文所采用的多錨點檢測有別于YOLOv3原始的錨點檢測框機制,并不關心于錨點檢測框的生成實現,這項工作由YOLOv3的原始算法完成。本文的方法是基于錨點檢測框構建數據標簽(label),顯式指定錨點檢測框標簽(anchor box label)的錨點位置以及邊長數據,并設置不同比例的錨點檢測框標簽監督訓練網絡,使模型能夠同時給出對圖像的全域特征和局部域特征的評價結果。為構建錨點檢測框標簽本文首先進行數據轉換,將空氣質量數據集的標簽轉換為訓練YOLOv3模型所需的VOC[32]格式,然后通過數據增廣完成多錨點檢測機制的設置。本文使用的訓練和測試數據集由2018年全球人工智能應用大賽賽事主辦方提供。
4.1 錨點標簽轉換
本文基于錨點機制,針對兩種不同的檢測任務分別轉換制作了用于非固定場景下空氣質量指數分級評定的錨點分類標簽(anchor Classification label),以及用于固定場景下PM2.5濃度預測的錨點回歸標簽(anchor Regression label)。數據標簽格式參照VOC 數據集的標簽,包括一個類別標簽和一個檢測框,其中檢測框用中心點坐標(x,y)以及長w和寬h描述。具體格式形式化表示為class,x,y,w,h,其中x、y、w、h均用圖像的尺寸進行歸一化。
4.1.1 錨點分類標簽
在預測非固定場景下的空氣質量指數的具體問題中,官方給定數據集中空氣質量指數標簽分為6 個級別,標簽從0 至5 依次代表優、良、輕度污染、中度污染、重度污染以及嚴重污染。因此視等級為類別來構建錨點分類標簽。
如圖6所示,基于class,x,y,w,h的格式,每幅圖像的錨點分類標簽包含一個class∈[0,5] 的類別標簽和兩種錨點檢測框的中心位置記憶長寬比例Ground truth x,y,w,h。其中,第一種錨點檢測框Ground truth(GT)的中心點坐標x,y為圖像中心,邊框長度w,h為圖像長寬W,H,用以學習圖像的全域空氣質量特征并給出總體評價。第二種錨點檢測框Ground truth的中心點坐標x,y為圖像上的隨機位置,然后本文基于YOLOv3最后一個輸出特征圖的尺度13×13,將邊框長度w,h設置為圖像尺寸的1/13,用以學習圖像的局部域空氣質量特征,并通過局部評價修正總體評價。最終錨點分類標簽形式化表示為:

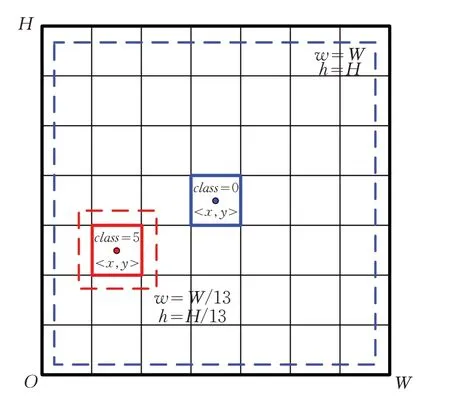
圖6 錨點分類標簽示意圖
4.1.2 基于2D坐標的變換
在預測固定場景下的PM2.5濃度的具體問題中,官方給出了四個固定單一視角下的空氣質量圖片數據集。每幅圖像的標簽信息包括該場景對應的PM2.5濃度,拍攝時相對濕度大小(百分比形式),以及拍攝時間(精確到小時),形式化表示為 PM2.5,濕度,時間 。其中濕度和時間兩個影響因子可以為PM2.5濃度的預測提供輔助作用。但是由于預測連續型數據值的難度較大,即使基于單一視角的固定場景并使用影響因子進行校正,依然無法利用分類模型直接檢測精確的PM2.5濃度。本文摒棄了單純的分類檢測模式,通過構建錨點回歸標簽引入了回歸過程處理此問題。如圖7所示,標簽的轉化形式可以表示為:
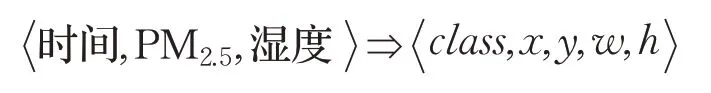
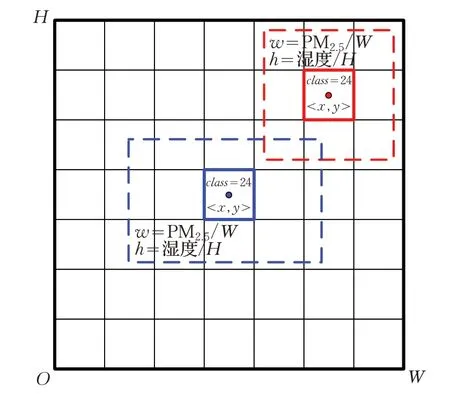
圖7 錨點回歸標簽示意圖
本文將錨點檢測框的Ground truth 設定成一個長寬分別為PM2.5濃度和濕度的矩形框,然后通過回歸算法對錨點檢測框的邊界盒進行預測,由此將對PM2.5濃度的檢測轉化為了一個回歸過程,回歸得到的錨點檢測框的邊界盒的長度即是PM2.5濃度。在具體的錨點回歸標簽構建中,由于Ground truth 的w,h取值不再依據圖像邊長的比例,而是被賦予了 PM2.5,濕度 的實際意義,為了不使Ground truth 超出圖像范圍,本文使用圖像尺寸(W大于最大PM2.5濃度數值,H大于最大濕度值)進行歸一化。錨點檢測框Ground truth的中心點坐標x,y同樣分為兩種:第一種為圖像中心點;第二種為其他圖像隨機位置,具體取值將依據4.2 節中的增廣算法給出。除此之外,由于數據集中的時間因子以小時劃分為離散數據,本文基于YOLOv3的分類算法對時間因子進行分類預測,其中類別class∈[1,24] ,模擬一天之中不同時刻光照強度帶來的影響,校正PM2.5濃度的回歸結果。最終錨點回歸標簽表示為:
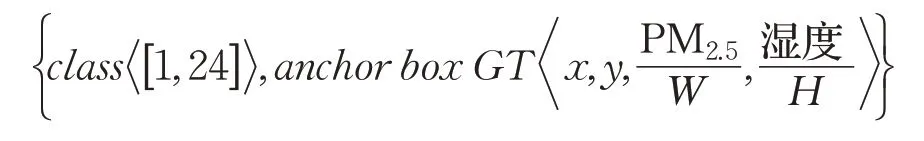
4.2 錨點數據增廣
由于錨點檢測框標簽的優勢在于監督網絡模型提取和分析局部圖像特征,使用單一的錨點檢測框標簽進行分類回歸顯然無法對整幅圖像表征的空氣質量情況進行全面的評價。因此需要對錨點檢測框標簽進行數據增廣,通過錨點增廣算法對錨點檢測框Ground truth的中心位置x,y進行設定,將大量錨點檢測框均勻地散布于圖像上的有效區域,構建多錨點檢測機制,促進網絡模型學習并分析圖像上所有的有效空氣質量深度特征,進而給出完整合理的評價結果。
基于前文所述的YOLOv3區域提議方法,將圖像劃分為13×13 個單元(cell)區域,然后將錨點數量增廣后散布于各個單元里面,為了得到均勻的散布,本文規定每個單元里面至多放置一個錨點檢測框標簽,負責監督該單元周圍的空氣質量深度特征的學習和評價。同時鑒于天空圖像域的深度特征比地面圖像域的深度特征更能表征環境空氣質量,因此本文側重對天空圖像域中數據的分析,將圖像上半部分(天空部分)與下半部分(地面部分)的增廣比例設置為5∶1。基于本文對圖像劃分為13行13列,假設<i,j>是圖像上某一個像素所處位置的行列號,則上半部劃分為:i∈[0,12],j∈[0,6],用以大致包含圖像的天空部分。下半部劃分為:i∈[0,12],j∈[7,12] ,用以大致包含圖像的地面部分。本文規定圖像上半部分包含的錨點檢測框標簽個數為60,圖像下半部分為12。下面分別介紹針對非固定和固定場景下兩種空氣質量檢測任務的錨點增廣算法,通過對錨點檢測框標簽的增廣構建最終用于空氣質量指數檢測的非固定場景圖像標簽,以及用于PM2.5濃度檢測的固定場景圖像標簽。
4.2.1 非固定場景圖像標簽
非固定場景圖像標簽的構建是基于對錨點分類標簽的增廣,如圖8 所示,主要通過計算72 個錨點檢測框Ground truth的中心點坐標x,y實現。
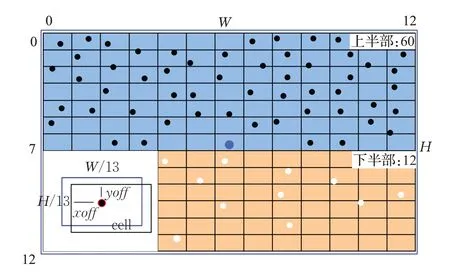
圖8 非固定場景圖像標簽
首先指定一個大尺度的錨點檢測框Ground truth,其中心點x,y為圖像的中心點,尺寸w,h為圖像尺寸,用于分析圖像的全域特征并給出空氣質量指數的總體評價。然后本文通過隨機算法在圖像上增廣72個尺寸w,h為圖像尺寸的1/13 的錨點檢測框Ground truth,其中在圖像的上半部分生成60 個anchor 位置,下半部分生成12 個anchor 位置。所有錨點檢測框Ground truth 中心點坐標的計算過程基于所屬單元在圖像上的位置,以及x,y在單元內部的偏置給出:基于長寬分別為W、H的圖像被等分為13×13個單元,每個單元的長寬分別為W/13、H/13,便有位于圖像第i行第j列的單元,其左上角坐標為:(W/13 )×i,(H/13) ×j。于是中心點坐標可由如下公式得出:
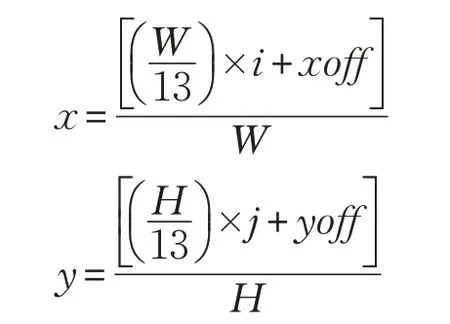
其中,xoff∈[0,W/13] 和yoff∈ [0,H/13] 是錨點檢測框Ground truth 中心點相對于所屬單元左上角的偏置坐標,該值在相應單元區域內由隨機算法生成。另外如前文所述i∈[0,12],j∈[0,6] 說明錨點檢測框Ground truth的中心點位于圖像上半部,i∈[0,12],j∈[7,12] 說明位于下半部。最后用W,H對x,y進行了歸一化。
4.2.2 固定場景圖像標簽
固定場景圖像標簽的構建是基于對錨點回歸標簽的增廣,如圖9 所示,核心算法同樣是計算72 個錨點檢測框Ground truth的中心點坐標x,y。為加速和簡化計算,本文將不同尺寸的圖片縮放到650×650的同一尺寸下,并使用這個尺度對錨點檢測框Ground truth的值進行歸一化。
首先類似于非固定場景圖像標簽指定一個x,y為圖像中心位置的錨點檢測框Ground truth,這是由于考慮到卷積操作的原理,中心錨點的感受野(ReceptiveField)要大于其他位置的錨點,并且圖像中心的特征會被多次提取,因此有必要設計一個的中心錨點檢測框Ground truth,專門針對圖像中心域的PM2.5濃度值進行評價。但是Static label中并沒有使用圖像尺寸設計錨點檢測框Ground truth,這是因為基于整幅圖像的全域特征信息(最大數公里級別),直接給出PM2.5的總體評價難以保證精度。因此在固定場景圖像標簽中,所有增廣得到的72 個錨點檢測框Ground truth的都被賦予唯一的尺寸。
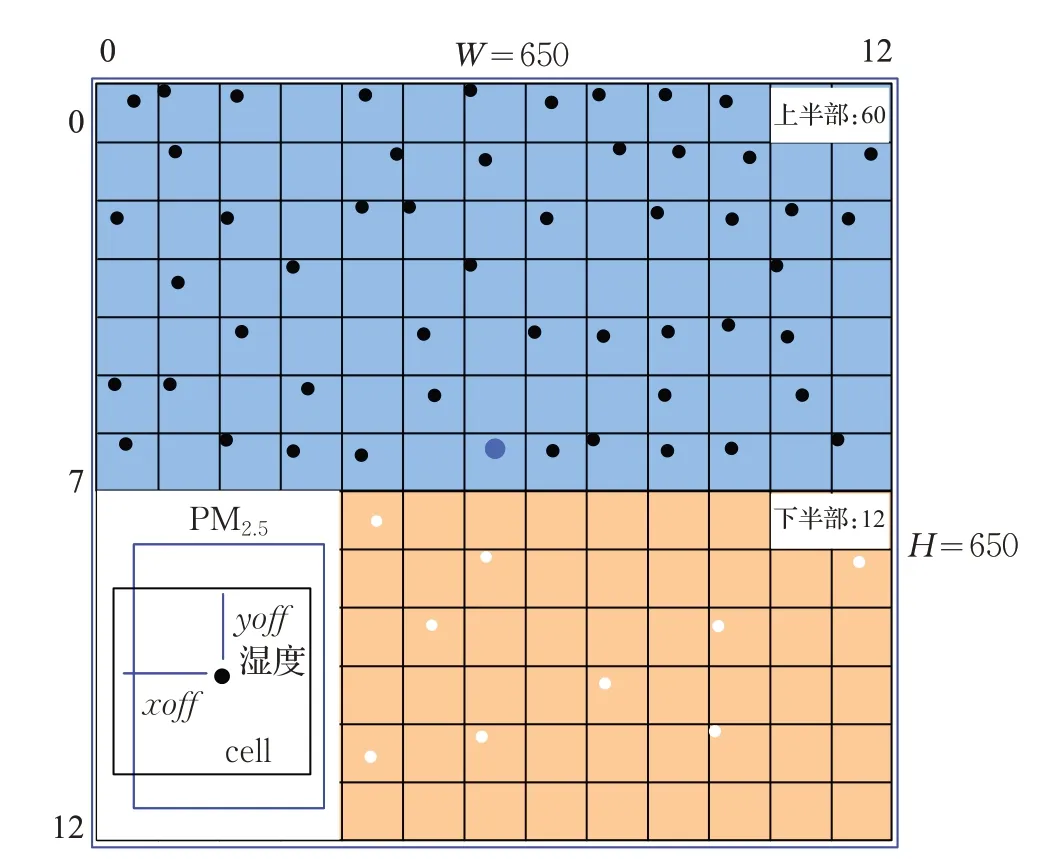
圖9 固定場景圖像標簽
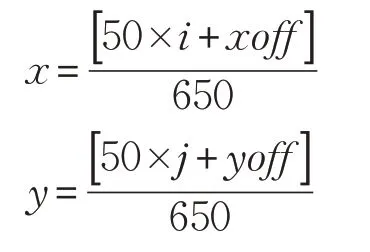
其中,xoff∈[0,50] 和yoff∈ [0,50] 是錨點檢測框Ground truth中心點相對于所屬單元左上角的偏置坐標,該值在相應單元區域內由隨機算法生成。同樣的,i∈[0,12] ,j∈[0,6] 說明錨點檢測框Ground truth的中心點位于圖像上半部,i∈[0,12] ,j∈ [7,12] 說明位于下半部。最后用 650,650 對x,y進行了歸一化。
使用固定場景圖像標簽完成訓練之后,網絡在測試階段首先通過darknet-53模塊提取錨點位置周圍區域圖像特征,在此區域回歸出一個與錨點檢測框Ground truth具有較高IOU的錨點檢測框,其邊界盒的長度即是PM2.5濃度。
基于錨點增廣機制,非固定場景圖像標簽或者是固定場景圖像標簽都有72 個錨點檢測框的標注,圖10 給出了非固定場景圖片中錨點數據的增廣效果。利用錨點增廣機制訓練完成的網絡模型會根據輸入的圖片產生72個輸出值。為得到反映整幅圖像空氣質量的統一評價,本文提出了卷積投票網,對來自于圖像各個區域的72個卷積結果進行分析、篩選和綜合。

圖10 非固定場景圖片中錨點數據增廣效果
5 卷積投票網
實際上,卷積投票網是網絡輸出層的擴展,這種卷積投票的思想將本文的方法與其他基于深度特征的算法區別開來。卷積投票網總體上基于兩個模塊構建,分別是卷積置信度機制和投票算法。其中,卷積置信度機制可以過濾掉圖像不同區域內無效的卷積操作,即噪聲深度特征帶來的影響。而投票算法則進一步基于卷積結果的置信度大小進行打分和加權計算,最終得出對整幅圖像的唯一評價。圖11分別將卷積置信度的估計值(a)和相應的類別評價(b),以及基于置信度閾值過濾的PM2.5濃度估計結果(c)進行了可視化表示。
5.1 卷積置信度機制
如上文所述,并不是所有圖像域的卷積深度特征都可以表征空氣質量,因此基于部分噪聲特征產生的結果并不可信。為描述結果的可信程度,在YOLOv3的錨點檢測機制中,每個錨點檢測框在得到輸出結果的同時會給出該結果的置信度得分,這些置信度分數反映了錨點檢測框所在圖像域包含空氣質量有效特征的信心程度,以及錨點檢測框中相關檢測值的準確性。具體的,置信度被定義為:
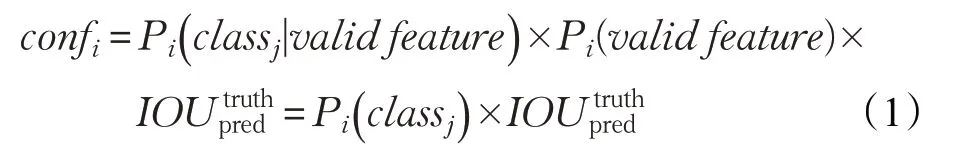

圖11 (a)基于錨點的置信度估計效果

圖11 (b)基于錨點的類別估計效果

圖11 (c)基于置信度閾值過濾的PM2.5濃度估計效果
5.2 投票算法
投票算法的核心是將卷積網絡的輸出結果進行均值池化(meanpooling)或者最大池化(maxpooling),相當于綜合考慮了全部有效深度特征對空氣質量評價的投票結果。另外基于評價任務的難度不同,相比較于在非固定場景下評估空氣質量指數等級,在固定場景下預測PM2.5濃度時,卷積投票網使用的投票算法種類更多。
為方便表達,做如下簡稱:
在非固定場景下評估空氣質量指數等級問題為NotStatic Level問題;在固定場景下預測PM2.5濃度問題為Static PM2.5問題。
NoStatic Level最大投票算法:
在NotStatic Level 問題中,投票算法對所有N=72個輸出值進行maxpooling,取置信度最大的第i個錨點檢測框中的類別值classj作為空氣質量等級檢測值:
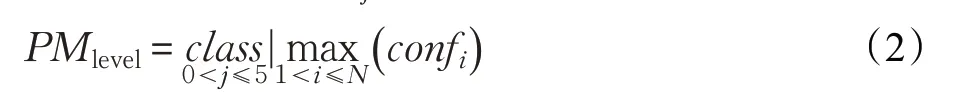
相比于 NoStatic Level 投票算法,Static PM2.5問題中的求解目標是錨點檢測框回歸得到的PM2.5濃度值,因此Static PM2.5問題并不基于類別進行投票,而是對錨點檢測框的長度值應用投票算法。
Static PM2.5最大投票算法:
該投票算法基于maxpooling,在所有N=72 個檢測結果中,取置信度最大的錨點檢測框的長度值作為檢測結果,則有:

其中boxi.right是網絡輸出的第i個錨點檢測框右側坐標值,其與左側坐標值boxi.lef差值即為代表PM2.5濃度的檢測框邊長。于是表示第i個錨點檢測框輸出的PM2.5濃度。
Static PM2.5平均投票算法:
Static PM2.5問題中,考慮到PM2.5濃度值的非離散屬性,如果采用maxpooling 會丟失較多有價值的信息,因此對所有N=72 個輸出結果進行meanpooling,以綜合圖像上不同區域檢測結果對總體結果的影響:
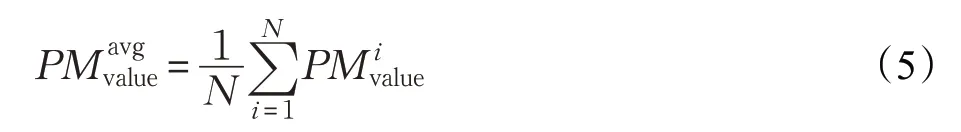
對所有結果meanpooling 存在一定問題,不希望那些conf不高的輸出結果影響最終的檢測值,因此本文設計了一種基于置信度門限(threshold)的投票算法,只對置信度大于門限的輸出結果進行meanpooling,這里門限值μ取0.95。
Static PM2.5基于置信度門限的投票算法:
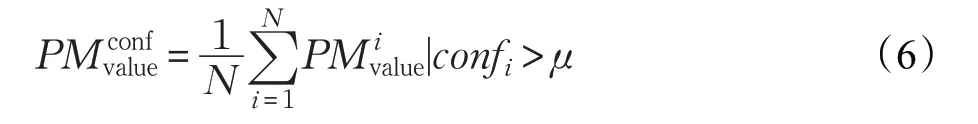
其中,n為置信度大于門限的輸出結果個數。應該注意到,即使取置信度在0.95 以上的輸出,仍不能保證單個樣本錨點檢測框的檢測結果沒有誤差,甚至個別錨點檢測框的檢測結果會與其他樣本框的結果偏差較大,以至于成為噪聲樣本。為消除這些噪聲結果,本文設計了一種基于置信度門限的排序投票算法。
Static PM2.5排序投票算法:
由于本文選取的置信度門限較高,因此可以認為所有高于門限的輸出值都具備最高置信度,即confi≈1。在理想情況下,對于相同的檢測內容,所有最高置信度的PM2.5檢測值應該相近,因此,如果某個檢測框輸出結果的置信度在門限以上,但是與其他最高置信度結果的平均值相差較大,那么該檢測框的輸出值就可以被判定為噪聲。于是本算法旨在過濾掉那些異常的輸出結果,挑選出置信度和相似度都比較高的輸出值來擬合最終的PM2.5檢測值:
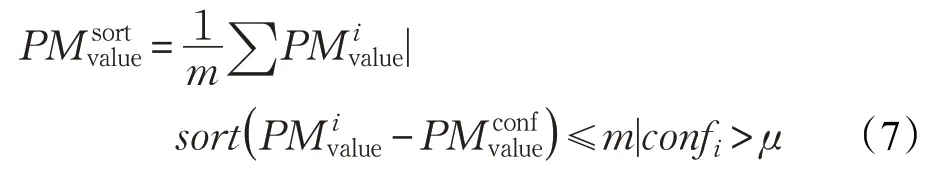
6 結果分析
本文詳細分析了不同權重的網絡模型基于不同檢測策略時,在官方測試數據集上的結果。相比于NotStatic Level 問題,Static PM2.5問題更為復雜且改進的空間更大。在兩個問題取得一定得分后,改變策略對Nostatic Level 問題分數的提升較小,相比之下Static PM2.5問題的分數提升更多。總體上雖然分數的提升并不是跨越式的,但是對于空氣質量評價準確率的提升可以充分印證本文提出的多錨點檢測機制和卷積投票算法的有效性。表2 分別列出了解決兩個問題所采用的方案,以及各個方案在每個問題上取得的成績和總成績。其中10Kweights代表網絡權重經過1萬次epoch迭代的訓練;MAX代表NoStatic Level最大投票算法或者Static PM2.5最大投票算法;Aug 代表錨點增廣算法;Conf_0.95 代表基于置信度門限為0.95 的投票算法;Sort_top5代表取置信度前五個值的排序投票算法;Total為兩個問題的總成績。下面本文基于NotStatic Level問題和Static PM2.5問題的評分結果,對多錨點檢測機制和卷積投票網的作用進行評價。
6.1 多錨點檢測機制的評價
在NotStatic Level 問題中,由于只有6 個空氣質量等級類參與分類,因此卷積投票網可以認為置信度較大的類別輸出值是準確的,進而只采用最大投票算法給出評價。基于卷積投票網在此處的算法固定,通過分析評測結果主要驗證了錨點增廣算法的有效性。第一次測試時,采用權重經過1 萬次epoch 訓練的網絡模型進行檢測,然后結合最大投票算法得到34.41 分的評價結果。接下來本文對錨點增廣算法進行了驗證。在下一次測試前,基于錨點增廣訓練網絡模型迭代2 萬次epoch,這一策略的使用在第二次測試中將評分提高到38.22,表明采用錨點增廣算法和增加的訓練次數帶來了3.81 分的改良。第三次測試前沒有進行策略上的改進,繼續增加的1 萬個epoch 訓練帶來了1.19 分的提升。從結果來看模型訓練到3 萬個epoch 已基本收斂,總體上,增加訓練倫次帶來了一定程度的改進,但是錨點增廣算法的使用才是檢測效果提升的關鍵,如圖12所示。
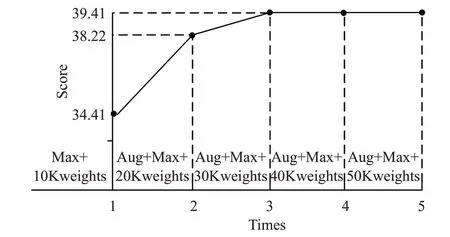
圖12 NotStatic Level問題對多錨點檢測機制的驗證
在Static PM2.5問題中,多錨點檢測機制同樣幫助網絡提升了檢測準確度。該問題的第一次評價,基于訓練次數為2 萬個epoch 的權重和最大投票算法,得到3.07分,之后同樣進行了錨點增廣。這一策略與增加的1萬個epoch 訓練將評分提高到5.70 分。同時,通過與Not-Static Level問題結果的對比發現,2萬個到3萬個epoch訓練次數的提升只能帶來39.41-38.22=1.19 分的改進,這說明在Static PM2.5 問題中,第二次評價產生的5.70-3.07=2.63 分的提高主要源于錨點增廣算法的應用,這也印證了多錨點檢測機制在空氣質量評價中的核心作用。
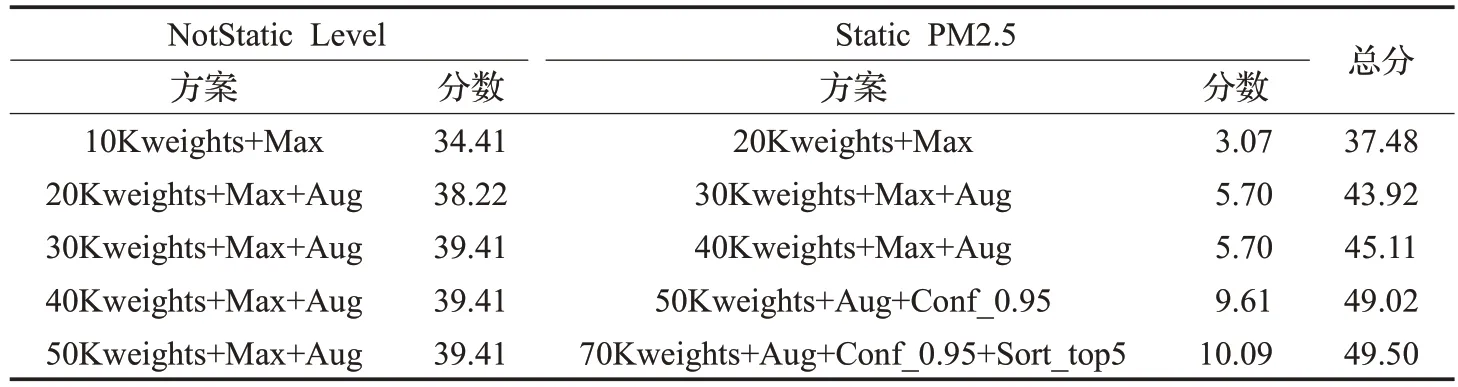
表2 不同檢測策略下的得分結果
總體上,不論是針對NotStatic Level 問題或者是Static PM2.5問題,只依賴于檢測算法本身得到的評價結果精度都比較低,并且單純地增加訓練迭代次數并不能帶來檢測效果的提升。但是采用多錨點檢測機制可以打破YOLOv3 模型的檢測瓶頸,大幅度地提高檢測精度。其中對于NotStatic Level 問題的提升基本來自于多錨點檢測機制的作用。而在Static PM2.5問題中,多錨點檢測機制也可以在少量的訓練次數之內帶來較大的精度提升。
6.2 卷積投票網的評價
鑒于在NotStatic Level 問題中只采用了最大投票算法,因此卷積投票網對于檢測能力的改進主要反映在Static PM2.5問題的評價結果上。基于前文所述,在Static PM2.5問題的第二次測試中,錨點增廣算法將得分提高到5.70分。由于第三次測試前沒有進行策略上的改進,而且增加的1 萬個epoch 訓練并沒有帶來成績的提升,這說明網絡模型的訓練已達到泛化能力的瓶頸,后面評價結果的提升完全來自于卷積投票網中投票算法的作用。在第四次測試中,由于使用了Static PM2.5基于置信度門限的投票算法,幫助模型取得9.61 分的評價結果,相比前一次實現了3.91 分的較大提升。最后一次測試中,基于卷積投票網對策略做出進一步改進,利用Static PM2.5排序投票算法剔除了高置信度數值中離散程度較大的噪聲項,同時結合經過7 萬次epoch 訓練的網絡權重,得到了目前為止Static PM2.5問題上的最高分10.09,如圖13所示。
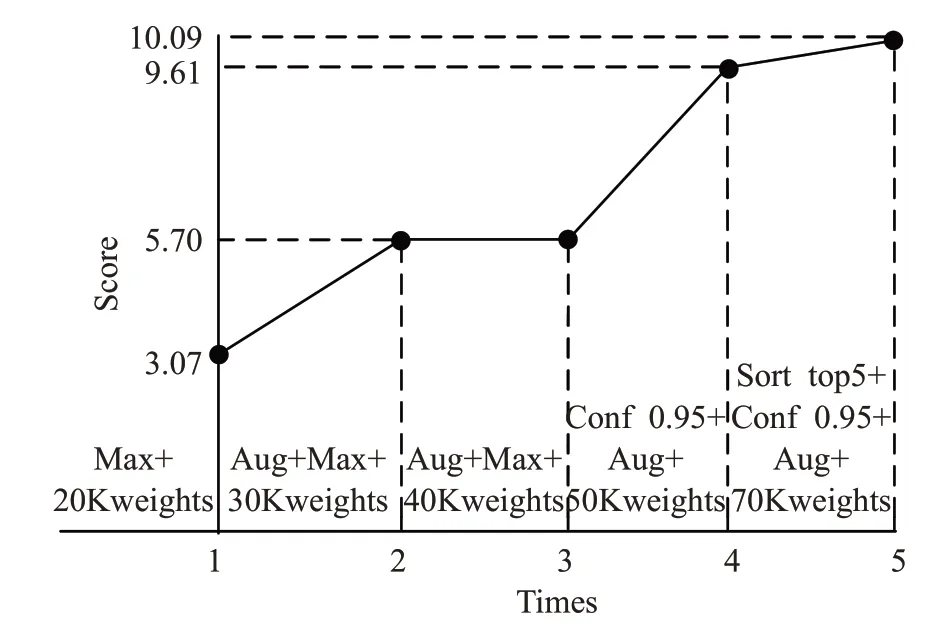
圖13 Static PM2.5問題對卷積投票網的驗證
可以看出,對PM2.5濃度值這種連續型數值進行檢測的難度要遠遠大于對空氣質量等級等離散數據的估計。YOLOv3 作為目前深度學習中效果較好的圖像檢測算法,其對于離散數據的分類能力同樣要強于對邊界框坐標值的回歸,YOLOv3只能給出目標邊界框的粗略坐標,難以將其回歸機制直接移植到PM2.5濃度的估計任務上。雖然多錨點檢測機制突破了YOLOv3 的檢測瓶頸,但是由于檢測連續型數值本身固有的難點,多錨點檢測機制難以保證所有錨點的檢測結果都可信,實驗結果表明,算法直接對所有錨點檢測結果進行meanpooling得到的分數僅為最高分數的56%,這說明由于多錨點檢測在此問題中帶來了多噪聲,極大地干擾了最終結果的輸出,因此本文進一步采用基于門限的卷積投票策略過濾置信度較低的檢測噪聲,這使得檢測效果得到了69%的提升。但是考慮到實際情況中高置信度的檢測結果也有可能為噪聲,算法最后基于排序投票策略,將與平均值相差較大的輸出結果視為噪聲,并且通過過濾掉這部分噪聲,將檢測精度進一步提升了5%。
總體上,卷積投票網主要用于Static PM2.5等連續型數值的預測問題,相比于最初直接使用YOLOv3進行濃度值回歸的做法,卷積投票網帶來了229%的提升,相比于受噪聲影響較大的多錨點檢測機制,投票策略得到了77%的提升。同時由于卷積投票網是針對YOLOv3 模型的輸出端進行進一步處理,因此并沒有增加太多的運算量。具體實驗中,算法基于檢測精度最高的Static PM2.5排序投票算法,對官方給出的Static PM2.5問題測試數據集進行結果輸出,處理67 張圖片的檢測結果僅需要0.01 s左右的時間。
7 結語
本文在基于深度特征的圖像檢測算法基礎上,提出了一種使用多錨點檢測和卷積投票網進行空氣質量評價的方法,分別適用于不固定場景非靜態環境下的空氣質量指數評估(NotStatic Level 問題),以及固定場景靜態環境下的PM2.5濃度預測(Static PM2.5問題)。與傳統的借鑒深度學習網絡,對空氣質量深度特征進行無差別分析的方法不同,本文提出的多錨點檢測機制和卷積投票網,不僅可以給出對全域特征的分析結果,還能夠實現對局部域特征的具體評價,并且可以在一定程度上過濾掉噪聲深度特征帶來的干擾。本文所述方法在2018年全球人工智能應用大賽中得到了總分第3 名的成績。為減少時間耗費,本文在darknet 框架下基于單模型網絡進行端到端的訓練,以達到實時的需求。下一步的工作包括:(1)進一步提升多錨點機制對于深度特征提取的準確度。本文的多錨點機制是基于固定的上下圖比例,隨機地設置各個區域的錨點。為得到更為合理的錨點,可以預先分析出圖像上大致的有效區域。例如文獻[6]利用深度學習模型自動檢測和提取圖像的天空部分,雖然只分析天空部分的做法有待商榷,但是其思路可以被借鑒。(2)進一步探索基于時序模型的卷積投票網。目前有一些工作[33]利用時序卷積網絡模型(例如LSTM、RNN等),對時間維度上的長程深度特征進行分析。可以基于卷積投票網對相同環境屬性的深度特征進行跟蹤分析,綜合它們在不同時刻的投票結果,進而將卷積投票網應用于多錨點和多時間點兩個維度上。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
