深度學(xué)習(xí)中的對抗攻擊與防御
2020-10-21 17:58:30劉西蒙謝樂輝王耀鵬李旭如
網(wǎng)絡(luò)與信息安全學(xué)報 2020年5期
劉西蒙,謝樂輝,王耀鵬,李旭如
(1.福州大學(xué)數(shù)學(xué)與計算機科學(xué)學(xué)院,福建 福州 350108;2.廣東省數(shù)據(jù)安全與隱私保護(hù)重點實驗室,廣東 廣州 510632;3.華東師范大學(xué)計算機與科學(xué)學(xué)院,上海 200241)
1 引言
隨著計算機運算能力的提升和社會數(shù)據(jù)量爆發(fā)式增長,深度學(xué)習(xí)在數(shù)據(jù)特征提取上表現(xiàn)出獨特的優(yōu)勢。如今,深度學(xué)習(xí)已經(jīng)被廣泛應(yīng)用于各個領(lǐng)域,在諸如計算機視覺[1]、語音識別[2-3]、文字處理[4]、惡意軟件檢測[5]等場景下均有不俗的表現(xiàn)。其在圍棋[6]、游戲[7]等領(lǐng)域已經(jīng)達(dá)到人類頂尖的水平。以計算機視覺領(lǐng)域為例,在2012年的一個大規(guī)模圖像[8]識別任務(wù)中,Krizhevsky等[1]利用卷積神經(jīng)網(wǎng)絡(luò)[9]將識別率提高至84.7%,達(dá)到前所未有的高度。
盡管深度學(xué)習(xí)在許多領(lǐng)域中取得了令人矚目的成績,但Szegedy等[10]在其針對圖像分類的研究成果中指出,盡管深度神經(jīng)網(wǎng)絡(luò)有著極高的準(zhǔn)確率,但卻非常脆弱,容易受到一種往圖像中添加人眼無法察覺的微小擾動攻擊。這類攻擊不僅能夠以極高的置信度誤導(dǎo)深度神經(jīng)網(wǎng)絡(luò)輸出錯誤的分類結(jié)果,并具有可遷移性,即同一張擾動圖像可能攻擊多個網(wǎng)絡(luò)模型。這類攻擊被稱為對抗攻擊,這個擾動圖像即為對抗樣本。如圖1所示,假設(shè)圖像分類模型能夠以57.7%的置信度正確識別出圖片中的熊貓,但在圖片中有針對性地添加一些人眼不可察覺的微小擾動后,雖然肉眼看上去圖片并沒有變化,但該圖像分類模型卻以99.3%的置信度錯誤地把將圖片分類成了長臂猿[11]。
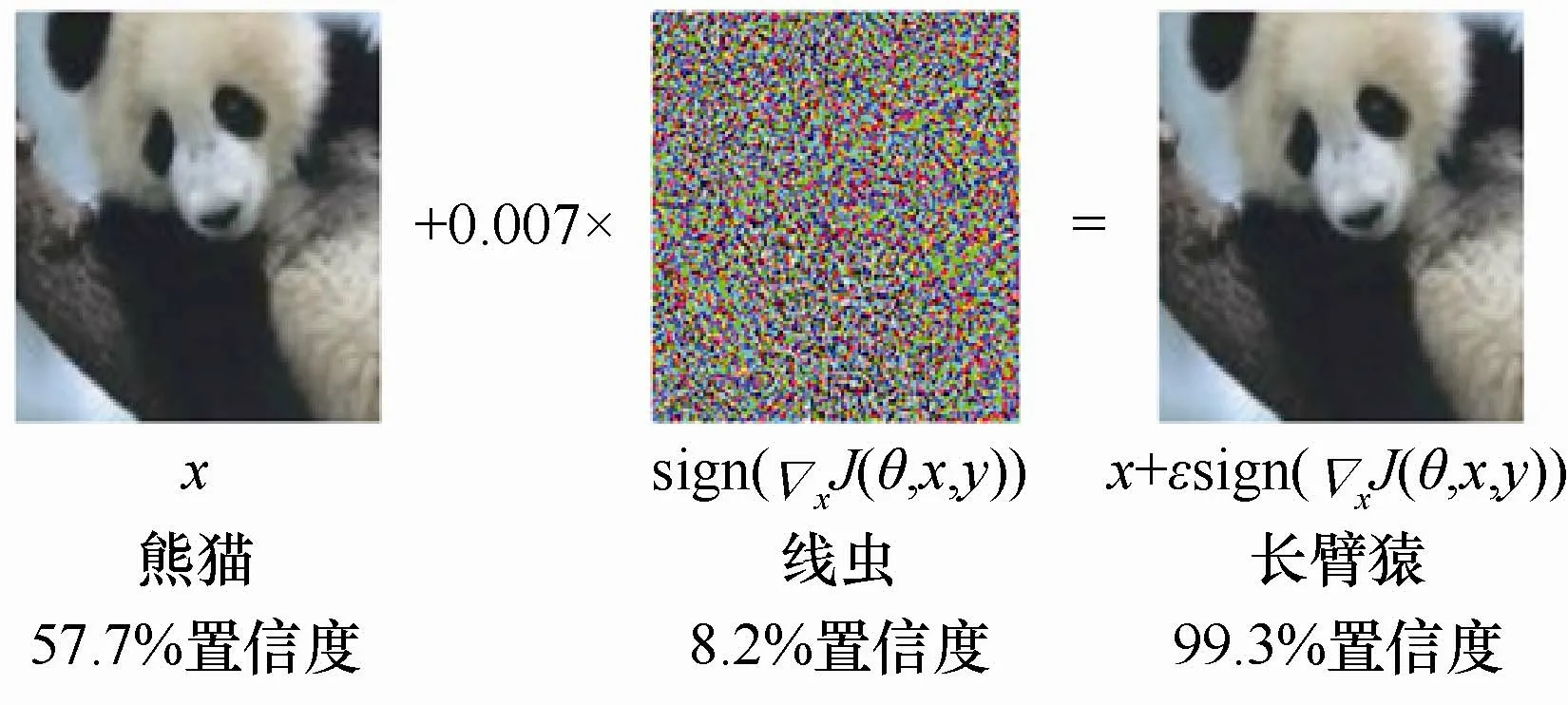
圖1 對抗樣本實例Figure 1 Adversarial example
自Szegedy等[10]提出針對深度神經(jīng)網(wǎng)絡(luò)的對抗攻擊之后,針對計算機視覺中深度學(xué)習(xí)的對抗攻擊及其防御逐漸成為研究熱點,由此產(chǎn)生了許多對抗攻擊和防御方法。既有白盒攻擊中Moosavi-Dezfooli等[12]提出對于多個圖像適用的通用擾動,也有黑盒攻擊中Su等[13]提出只針對圖像中的一個像素點進(jìn)行擾動并誤導(dǎo)分類器的極端攻擊方法。而防御方法主要分為3類,即輸入預(yù)處理、提高模型魯棒性以及惡意檢測。涉及的具體方法多種多樣,包括預(yù)處理修正網(wǎng)絡(luò)、像素偏移、圖像變換、對抗生成網(wǎng)絡(luò)防御、特征去噪、防御蒸餾、對抗性訓(xùn)練和隨機化等。雖然目前提出了大量防御方法,但卻無法完全防御對抗攻擊,許多防御方法并不完善、存在片面性,其有效性也遭到了質(zhì)疑[14-16]。
本文總結(jié)了目前主流的對抗攻擊和防御方法,并從這兩個角度出發(fā),進(jìn)行相關(guān)的介紹和總結(jié)。
2 相關(guān)概念
本節(jié)主要介紹一些相關(guān)的基本概念、對抗攻擊威脅模型和攻擊類型。
2.1 基本概念
Szegedy等[10]首次發(fā)現(xiàn)在原始圖像上添加人眼無法察覺的噪聲,添加噪聲后的圖像能夠誤導(dǎo)神經(jīng)網(wǎng)絡(luò)模型以高置信度錯誤分類該圖像,這類通過添加噪聲導(dǎo)致網(wǎng)絡(luò)分類錯誤的圖像被稱為對抗樣本,其所添加的噪聲稱為對抗擾動。Moosavi-Dezfooli等[12]發(fā)現(xiàn)一種通用型對抗擾動,這種擾動添加到特定數(shù)據(jù)集的所有圖像構(gòu)成對抗樣本,具體細(xì)節(jié)在第3節(jié)中介紹。此外,對抗樣本具有遷移性,即對抗樣本能夠攻擊特定目標(biāo)模型以外的神經(jīng)網(wǎng)絡(luò)模型。攻擊者為了使生成的對抗樣本與原始圖像肉眼無法區(qū)分,對抗樣本x′與原始樣本x的相似程度使用?p范數(shù)衡量,即的定義如式(1)所示。
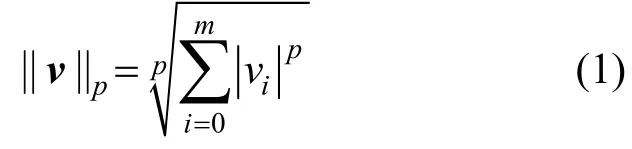
其中,v是m維向量;p是實數(shù)。
針對對抗樣本問題,Goodfellow等[11]首次提出通過對抗訓(xùn)練來提高模型魯棒性,即在原有的模型訓(xùn)練過程中加入對抗樣本的訓(xùn)練方法,旨在提升模型對于微小擾動的魯棒性,具體的方法將在第5節(jié)中介紹。
2.2 威脅模型
根據(jù)攻擊者對攻擊目標(biāo)模型所掌握信息的程度,可以把威脅模型分為黑盒模型、灰盒模型、白盒模型。①黑盒攻擊:攻擊者只能夠通過神經(jīng)網(wǎng)絡(luò)輸入,獲得相應(yīng)的輸出,根據(jù)輸出的反饋構(gòu)造對抗樣本。②灰盒攻擊:相比黑盒攻擊,灰盒攻擊的攻擊者所擁有的信息更加豐富。攻擊者能夠獲得攻擊目標(biāo)模型結(jié)構(gòu)、參數(shù),但不了解目標(biāo)模型防御機制相關(guān)的任何信息,灰盒模型通常用于評測防御方法。③白盒模型:攻擊者掌握目標(biāo)模型結(jié)構(gòu)、參數(shù)、防御機制等全部信息,有時候還包括訓(xùn)練集,在這種情況下,攻擊者的能力最強。
2.3 攻擊類型
自Szegedy等[10]提出對抗樣本的概念之后,便產(chǎn)生了許多對抗樣本生成算法。攻擊算法可根據(jù)有無針對性目標(biāo)分為定向攻擊和非定向攻擊。定向攻擊指攻擊者產(chǎn)生的對抗樣本能夠讓神經(jīng)網(wǎng)絡(luò)把對抗樣本分類成攻擊者指定類別。非定向攻擊指神經(jīng)網(wǎng)絡(luò)將對抗樣本分類為除正確類別以外的任意類別。非定向攻擊相比定向攻擊更加容易實現(xiàn)。而根據(jù)攻擊威脅模型,攻擊算法可分為白盒攻擊和黑盒攻擊。白盒攻擊者能夠獲得網(wǎng)絡(luò)模型結(jié)構(gòu)、參數(shù)、防御機制,有時候甚至還包括訓(xùn)練集。黑盒攻擊者只能夠根據(jù)神經(jīng)網(wǎng)絡(luò)輸入,獲得相應(yīng)輸出,并不知道網(wǎng)絡(luò)模型的結(jié)構(gòu)和參數(shù)。在攻擊威脅模型的基礎(chǔ)上,可根據(jù)攻擊者所能掌握目標(biāo)模型信息程度細(xì)分成4個類別:梯度攻擊、置信度攻擊、決策攻擊、遷移攻擊,如圖2所示。梯度攻擊建立在攻擊者能夠獲取目標(biāo)模型結(jié)構(gòu)和參數(shù)的基礎(chǔ)上,利用反向傳播的梯度構(gòu)造對抗樣本,屬于白盒攻擊。置信度攻擊、決策攻擊、遷移攻擊是黑盒攻擊模型中的子類別。置信度攻擊通過網(wǎng)絡(luò)模型輸出的置信度構(gòu)造對抗樣本。相比置信度攻擊,決策攻擊只需根據(jù)最終的輸出類別,不需要各類別的置信度。遷移攻擊則在代理模型上生成對抗樣本,利用對抗樣本的遷移性對目標(biāo)模型發(fā)起攻擊。遷移攻擊所需要的信息量最少,不需要目標(biāo)模型的任何信息,就可以實現(xiàn)對目標(biāo)模型的攻擊。

圖2 攻擊類型Figure 2 Attack type
3 對抗攻擊
自對抗樣本被發(fā)現(xiàn)以來,出現(xiàn)了許多不同的對抗樣本生成算法及其相應(yīng)的改進(jìn)版本。本文根據(jù)威脅模型的不同,將對抗攻擊算法分為白盒攻擊與黑盒攻擊兩類。
3.1 白盒攻擊
3.1.1 L-BFGS攻擊
Szegedy等[10]發(fā)現(xiàn)了兩點深度神經(jīng)網(wǎng)絡(luò)的反直覺特性。①神經(jīng)網(wǎng)絡(luò)中深層次的語義信息由整個單元空間構(gòu)成,而不是單個神經(jīng)元。②深度神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)到的輸入輸出之間的映射關(guān)系具有不連續(xù)的特性,并由此提出一種在原始圖像上添加肉眼難以觀察到的微小擾動就能夠誤導(dǎo)分類器的圖片,即對抗樣本。文獻(xiàn)[10]首次提出對抗樣本概念,并將對抗樣本生成方法建立成模型,采用L-BFGS算法[17]簡化成如式(2)、式(3)所示。
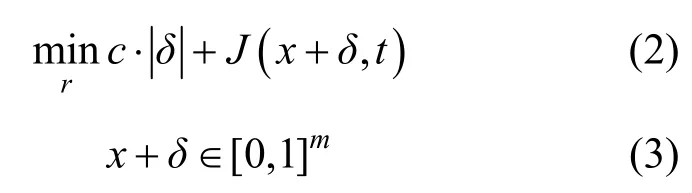
其中,x表示原始圖像,這里將RGB圖像轉(zhuǎn)換成m維向量表示;c是超參數(shù),該算法利用線性搜索找到一個可以產(chǎn)生最小距離對抗樣本的常數(shù);式(2)中最小化擾動δ和攻擊目標(biāo)類別t的損失函數(shù)J(通常是交叉熵)來誤導(dǎo)深度學(xué)習(xí)網(wǎng)絡(luò)模型;式(3)保證添加擾動后的圖像取值x+δ∈[0,1]m穩(wěn)定在正常范圍。
3.1.2 快速梯度符號算法攻擊
Szegedy等[10]認(rèn)為對抗樣本的存在是由神經(jīng)網(wǎng)絡(luò)模型的非線性和過擬合造成的。而Goodfellow等[11]認(rèn)為,即使是簡單的線性模型也會存在對抗樣本,并且將線性特征應(yīng)用于非線性模型,提出了第一個基于梯度的快速梯度符號算法(FGSM,fast gradient sign method),該算法與L-BFGS有兩點不同:①采用L∞優(yōu)化方式;②重點在于計算效率,對抗性能不足。核心公式如式(4)所示。
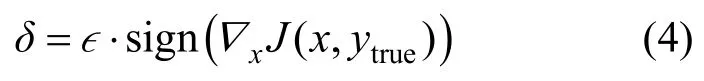
3.1.3 基礎(chǔ)迭代法攻擊
Kurakin等[18]提出基礎(chǔ)迭代法(BIM,basic iterative method)。它是對FGSM[11]的擴(kuò)展:不再利用單一步長?,而是分成多次小步α進(jìn)行迭代,采用?裁剪對應(yīng)結(jié)果,如式(5)、式(6)所示。

其中,x′i表示對抗樣本的第i次迭代;clip為裁剪函數(shù),定義如式(7)所示。
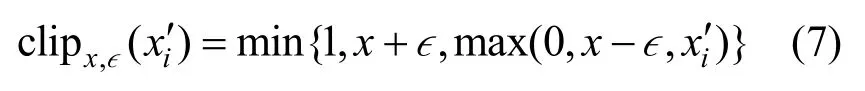
裁剪函數(shù)對圖像x′的每個像素進(jìn)行裁剪,保證ix′維持在原始圖像x的?鄰域。實驗表明,BIM比FGSM更有效,但計算效率有所降低。
3.1.4 基于雅可比矩陣的顯著圖攻擊
Papernot等[19]提出攻擊算法:基于雅克比的顯著圖(JSMA,Jacobian based saliency map attack)算法。該文獻(xiàn)利用L0范數(shù)將擾動控制在圖像中的幾個像素點上,保證對抗樣本的真實性。該方法首先利用雅克比矩陣計算深度神經(jīng)網(wǎng)絡(luò)的前向?qū)?shù),如式(8)所示。
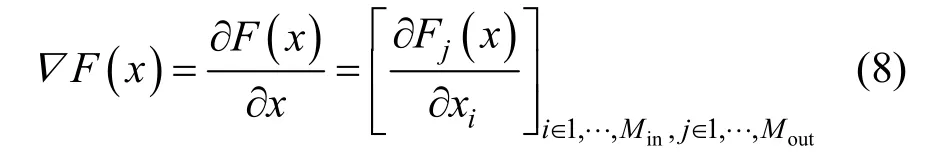
其中,F(xiàn)表示Softmax層輸出函數(shù),Min表示輸入層數(shù)量,Mout表示輸出層數(shù)量。然后通過前向?qū)?shù)計算對應(yīng)的對抗性顯著圖(adversarial saliency map),并利用貪心算法選擇對抗性顯著圖中數(shù)值最大的一個像素點進(jìn)行擾動。算法迭代以上步驟直到達(dá)到最大擾動像素數(shù)量或者成功誤導(dǎo)模型,最終得到對抗樣本。
3.1.5 Carlini&Wagner(C&W)攻擊
防御蒸餾可以為目標(biāo)網(wǎng)絡(luò)模型提供很強的魯棒性,能夠?qū)?dāng)時已經(jīng)出現(xiàn)的攻擊算法成功率由95%銳減到0.5%。Carlini和Wagner[20]提出、種優(yōu)化方式的C&W攻擊算法,能夠?qū)φ麴s或未蒸餾的神經(jīng)網(wǎng)絡(luò)達(dá)到100%的攻擊效果,計算如式(9)所示。
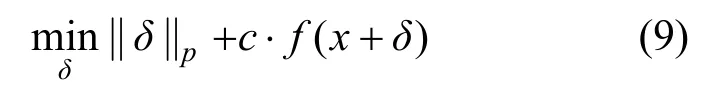
其中,δ即對抗性擾動,對應(yīng)原始圖像和對抗樣本的差值,該部分越小,意味著越不容易被察覺。而f()·表示目標(biāo)函數(shù)。文獻(xiàn)[20]提供了7種候選目標(biāo)函數(shù),該文獻(xiàn)在實驗中實際應(yīng)用的函數(shù)之一如式(10)所示。
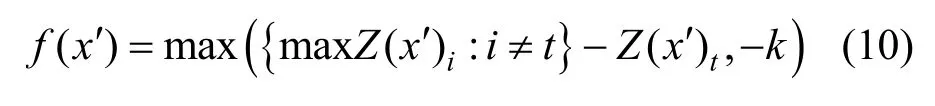
其中,Z(x′)i表示類別i的邏輯值,將最大邏輯值(對應(yīng)類別不同于t)記為,并通過優(yōu)化降低max{Z(x′)i來提高攻擊有效性。利用k控制錯誤分類的置信度,參數(shù)k與對抗樣本x′攻擊的成功率呈正相關(guān),k越大,x′分類為t的可能性越大。超參數(shù)c用來權(quán)衡兩個部分之間關(guān)系,C&W算法中使用二分查找來確定c值。
3.1.6 Deepfool攻擊
Moosavi-Dezfooli等[21]提出了基于分類問題的Deepfool對抗樣本生成方法。在二分類問題中,原始圖像與決策邊界的最短距離為垂直距離,為了生成最小擾動,使原始圖像朝著垂直于決策邊界的方向前進(jìn)最短距離,到達(dá)決策邊界,生成對抗樣本使其誤導(dǎo)分類模型。但大多數(shù)神經(jīng)網(wǎng)絡(luò)是高度非線性的,問題由二分類延伸至多分類。多分類問題可以看作多個二分類問題的集合,即尋找原始樣本與其所在凸區(qū)域的邊界之間的最小距離,并通過多次迭代到達(dá)分類邊界,使攻擊成功。
3.1.7 通用型擾動攻擊
Moosavi-Dezfooli等[12]首次證明了存在一種非定向的通用型擾動攻擊,將其添加到給定圖像集中的大部分圖片上能夠?qū)崿F(xiàn)以高置信度誤導(dǎo)網(wǎng)絡(luò)模型,并給出了通用型擾動生成算法。算法將目標(biāo)數(shù)據(jù)集X記為數(shù)據(jù)集X={x1,x2,… ,xm},并對數(shù)據(jù)集X中的所有圖像添加通用型擾動δ,使數(shù)據(jù)集X中大部分圖像能夠誤導(dǎo)分類模型。算法尋找的擾動δ滿足式(11)。
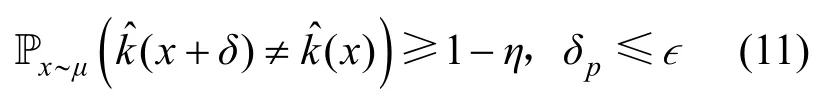
假設(shè)原始樣本從圖像分布μ中采樣得到,表示對圖像x的預(yù)測類別,η表示欺騙率。算法利用DeepFool攻擊方法[21]依次將數(shù)據(jù)集X中的圖像逐漸推到各自的決策邊界,并依次將圖像投影在半徑為?的p球面上,迭代生成通用型擾動δ。
3.2 黑盒攻擊
3.2.1 單像素攻擊
Su等[13]提出一種基于差分進(jìn)化算法的極少像素攻擊。這是一種極端的對抗攻擊方法,僅改變一個像素就能夠使網(wǎng)絡(luò)模型分類錯誤。該算法通過迭代地修改單個像素并生成子圖像,將其與母圖像對比,根據(jù)選擇標(biāo)準(zhǔn)保留攻擊效果最好的子圖像以實現(xiàn)對抗攻擊。單像素攻擊可以通過修改少數(shù)不同像素來達(dá)到攻擊的目的,如修改1、3或5個像素點,成功率分別為73.8%、82.0%、87.3%。與以往的攻擊方法不同,該算法僅需要黑盒反饋(概率標(biāo)簽),不需要目標(biāo)網(wǎng)絡(luò)的內(nèi)部信息,如梯度和網(wǎng)絡(luò)結(jié)構(gòu)。
3.2.2 期望變換攻擊
噪聲、扭曲、仿射變換等圖像變換操作會導(dǎo)致對抗樣本失效。針對這個問題,Athalye等[22]提出變換期望(EOT,Expection OverTransformation)攻擊算法。其核心如式(12)所示。
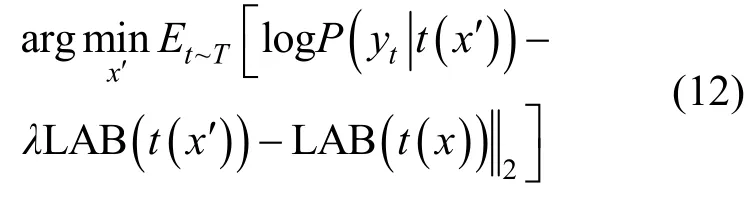
其中,x′是對抗樣本;x為原始圖像;LAB為圖像顏色對立空間[23];T是圖像變換分布。
算法基本思想是變換分布T可以對感知扭曲進(jìn)行建模,如隨機旋轉(zhuǎn)、平移或添加噪聲。該算法不僅能夠模擬簡單變換,也可執(zhí)行諸如紋理的三維渲染之類的操作。
3.2.3 零階優(yōu)化攻擊
受到C&W算法[20]的啟發(fā),Chen等[24]提出了基于置信度的零階優(yōu)化(ZOO,zeroth order optimization)方法。其通過輸入樣本和輸出類別置信度,針對深度神經(jīng)網(wǎng)絡(luò)模型進(jìn)行黑盒攻擊。ZOO不需要訓(xùn)練替代模型,它利用零階優(yōu)化近似估計網(wǎng)絡(luò)梯度,同時使用降維、分層攻擊、重要抽樣技術(shù)提高計算效率。該算法的優(yōu)化方案與C&W算法[20]一致,但其區(qū)別在于該算法為黑盒攻擊,無法獲取模型梯度,ZOO使用近似梯度替代模型梯度,利用對稱差商計算近似梯度和黑塞矩陣。在得到梯度和黑塞矩陣的前提下,通過隨機坐標(biāo)下降方法生成最優(yōu)擾動,并利用ADAM方法[25]提高收斂效率。
3.2.4 邊界攻擊
Brendel等[26]指出當(dāng)前的主流攻擊方式為基于梯度的攻擊和基于置信度的攻擊。但在現(xiàn)實場景中無法獲取攻擊所需的網(wǎng)絡(luò)模型信息,這兩種方式都不適用于現(xiàn)實場景。因此,文獻(xiàn)[26]提出了僅需輸出類型的決策邊界攻擊,其基本思想是在保證得到對抗樣本的情況下,不斷地迭代靠近原始圖像,最終得到與原始圖像相近的對抗樣本。這種攻擊能夠有效地應(yīng)用于現(xiàn)實場景,并且與遷移攻擊相比,邊界攻擊所需的模型信息量更少、魯棒性更強、更容易應(yīng)用于現(xiàn)實場景。
3.2.5 有偏邊界攻擊
邊界攻擊是從多維正態(tài)分布中提取擾動候選項,這意味著算法使用的是無偏采樣的攻擊方式。雖然這種方法靈活性較高,但對于魯棒性較強的模型效率不高。Brunner等[27]則提出有偏的邊界攻擊,大大提高了攻擊的效率,主要從3方面進(jìn)行改進(jìn)。
1)低頻擾動:由于經(jīng)典的對抗樣本生成算法產(chǎn)生的對抗擾動是高頻噪聲,所以Brunner等[27]采用了低頻的Perlin噪聲[28]繞過檢測機制。
2)區(qū)域掩碼:利用區(qū)域掩碼,在對抗樣本和原始圖像差異較大的區(qū)域進(jìn)行更新,在極度相似部分則不進(jìn)行更新,有效減少了搜索空間。
在學(xué)習(xí)課件后對說服又有了更深刻的認(rèn)識,說服的要點是建立信譽,找到共同點,提供支持信息和展示同理心。信譽可以在工作接觸當(dāng)中慢慢建立,只要你是一個坦誠的人,這不是一個難題。而找出共同點比較難,很多人說服對方的時候,直接站在對方的對立面,針鋒相對,而不是在了解受眾的基礎(chǔ)上找到共同點。同理心和感情認(rèn)同真的非常重要,上面我的實例就是在同理心和感情認(rèn)同的基礎(chǔ)上說服了對方。平等基礎(chǔ)上的說服不是出于地位和大義上的指責(zé)與審判,是一種心理共鳴。
3)替代模型梯度:對抗樣本具有遷移性,即替代模型的梯度對于攻擊目標(biāo)模型是有幫助的。因此,Brunner等[27]利用替代模型的梯度指引邊界攻擊的更新方向,使其提高攻擊效率。
雖然上述改進(jìn)提高了算法效率,但替代模型梯度依賴于模型的可移植性。為了解決這個問題,Chen等[29]提出不依賴可移植性假設(shè),利用蒙特卡洛估計評估梯度的方向,進(jìn)一步改善了攻擊效率。
3.3 攻擊方法總結(jié)
攻擊的主要目標(biāo)是以人眼無法察覺的擾動,使深度學(xué)習(xí)模型對輸入圖像分類錯誤。因此,本文根據(jù)攻擊目標(biāo)有無、擾動范數(shù)、攻擊類型3個特點對這些經(jīng)典的方法加以對比,如表1所示。從表1可以看出,攻擊算法非定向的居多,擾動范數(shù)主要是?0、?2、?∞3類。早期提出的攻擊算法類型中,梯度攻擊最為常見,但現(xiàn)實應(yīng)用中遷移攻擊、置信度攻擊、決策攻擊更符合實際。
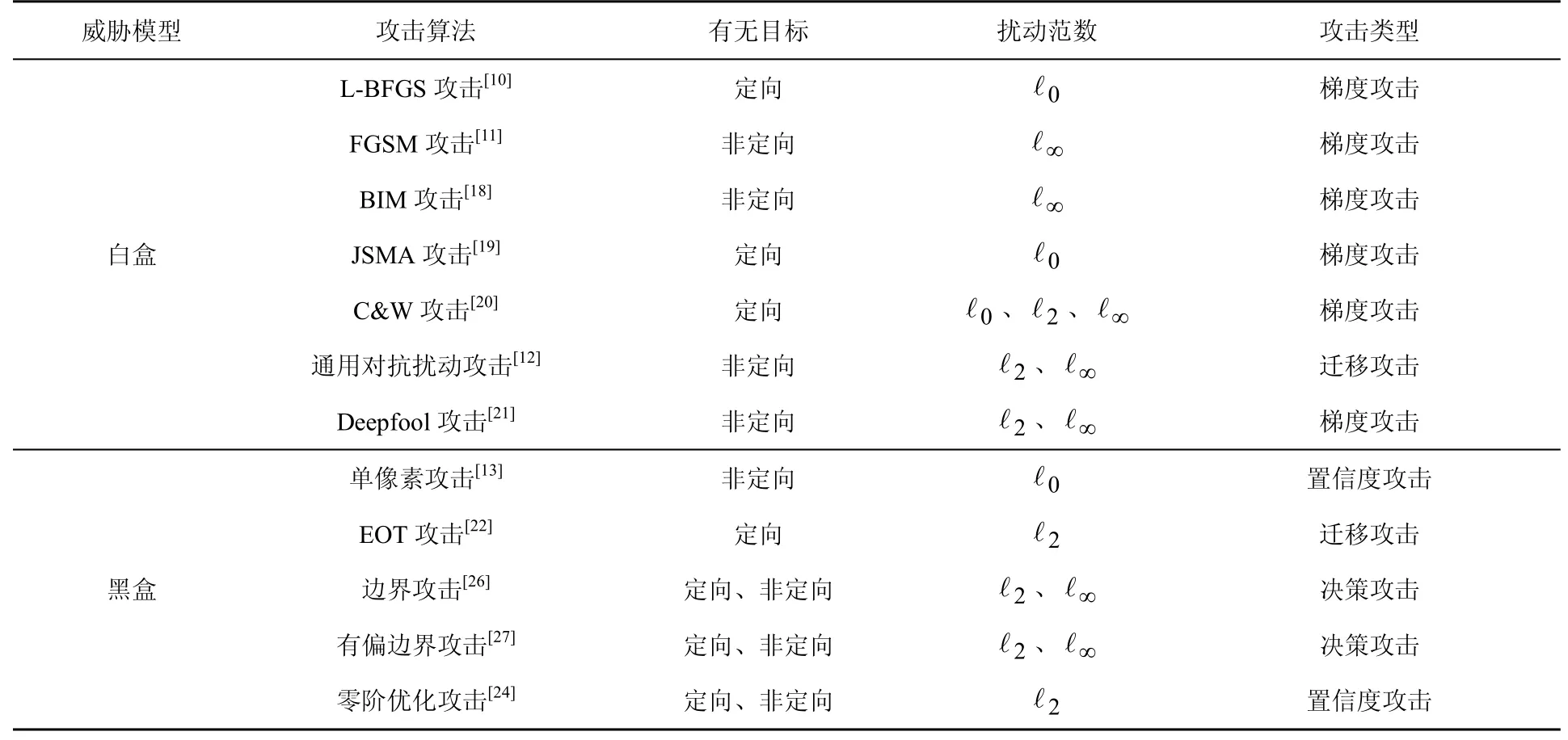
表1 對抗攻擊方法總結(jié)Table 1 Summary of adversarial attacks
4 對抗攻擊的實例
第3節(jié)介紹了圖像分類領(lǐng)域內(nèi)的對抗樣本生成算法,但存在一定的條件限制,如標(biāo)準(zhǔn)數(shù)據(jù)集、白盒模型等約束。這些條件的約束可能不足以讓人為深度學(xué)習(xí)模型安全擔(dān)憂。然而,已有針對網(wǎng)絡(luò)空間攻擊、目標(biāo)檢測、停車牌識別、語義分割、人臉識別等現(xiàn)實應(yīng)用場景的攻擊實例,本節(jié)對這些領(lǐng)域內(nèi)的對抗攻擊實例進(jìn)行介紹。
4.1 圖像分類
Kurakin等[30]首次證明了對抗攻擊的威脅存在于物理世界。他們使用Inception-v3模型[31]生成對抗樣本,然后打印出對抗樣本的圖像,并用手機攝像頭拍攝,把拍攝的圖像輸入TensorFlow Camera Demo應(yīng)用程序。結(jié)果表明,即使是用相機拍攝,這些圖像仍能夠?qū)е履P头诸愬e誤。簡單利用對抗樣本的可移植性的攻擊方式容易受到圖像變換的影響,效果不夠穩(wěn)定。因此,Athalye等[22]提出一種構(gòu)造3D對抗樣本的方法,通過EOT技術(shù)首次合成了現(xiàn)實3D對抗樣本,該方法模擬多種圖像變換的影響,即使在圖像變換的干擾下,仍然保持對抗樣本的特性,使對抗樣本在現(xiàn)實場景中更加魯棒。
4.2 網(wǎng)絡(luò)空間攻擊
Papernot等[32]提出了網(wǎng)絡(luò)空間上的現(xiàn)實對抗樣本攻擊,在合成數(shù)據(jù)集上訓(xùn)練了一個代理模型,用于產(chǎn)生對抗樣本,并對MetaMind、亞馬遜和谷歌的遠(yuǎn)程托管神經(jīng)網(wǎng)絡(luò)發(fā)起攻擊。結(jié)果表明,模型錯誤分類率分別是84.24%、96.19%和88.94%。同樣地,Liu等[33]利用對抗樣本的遷移性實施攻擊,其基本思想是生成一個能夠同時讓多個模型分類出錯的對抗樣本,用來實施遷移攻擊。這一方法實現(xiàn)了在大數(shù)據(jù)集ImageNet[8]上的黑盒攻擊,并且成功攻擊了當(dāng)時提供最先進(jìn)圖像分類服務(wù)的商業(yè)公司Clarifai。
與遷移攻擊不同,Li等[34]分別對單像素攻擊和邊界攻擊進(jìn)行改進(jìn)。在單像素攻擊[13]基礎(chǔ)上,通過逐步增加像素修改的數(shù)量,并融入語義分割的思想提高效率。而在邊界攻擊[26]中則引入語義分割和貪心的思想提高效率。Li等[34]還對亞馬遜、微軟、谷歌、百度和阿里巴巴五大云服務(wù)提供商提供的與計算機視覺相關(guān)的服務(wù)(如圖像分類、對象識別、非法圖像檢測)分別進(jìn)行了黑盒攻擊,成功率幾乎達(dá)100%。
4.3 目標(biāo)檢測
Wei等[35]提出了一種基于生成對抗網(wǎng)絡(luò)[36]框架的對抗樣本生成方法,為了增加對抗樣本的可移植性,引入網(wǎng)絡(luò)的特征損失作為損失函數(shù)的一部分。通過結(jié)合高級別的類別損失和低級別的特征損失訓(xùn)練的生成器,生成的對抗樣本具備很好的可遷移性,可以同時攻擊兩個具有代表性的目標(biāo)檢測器快速區(qū)域卷積神經(jīng)網(wǎng)絡(luò)[37](Faster-RCNN,faster regions with convolutional neural networks)和單發(fā)多框檢測器[38](SSD,single shot multibox detector)。
Thys等[39]提出了基于“你只需看一次”(YOLO,you only look once)[40]模型的動態(tài)人物目標(biāo)檢測攻擊方法。他們通過優(yōu)化圖像的方式生成一個對抗補丁,將其放置在人體中心,成功繞過檢測模型檢測。他們把優(yōu)化目標(biāo)損失函數(shù)分為3個部分,即Lnps、Ltv和Lobj。Lnps表示當(dāng)前補丁的顏色能否應(yīng)用于現(xiàn)實生活;Ltv體現(xiàn)了圖像的平滑度;Lobj為圖像中最大的目標(biāo)檢測置信度。在優(yōu)化過程中,神經(jīng)網(wǎng)絡(luò)模型參數(shù)不變,僅改變對抗性補丁,并將每次修改過的補丁進(jìn)行旋轉(zhuǎn)、縮放等基本變換之后,再次應(yīng)用到數(shù)據(jù)集圖像中,以提高對抗性補丁魯棒性,使其能夠成功誤導(dǎo)檢測模型。
4.4 停車牌識別
Evtimov等[41]基于先前攻擊算法[20,33],提出了一種通用的攻擊算法(魯棒物理擾動),用于在不同的物理條件下(如距離、角度、扭曲)產(chǎn)生具有魯棒性的視覺對抗性擾動。在實際駕駛環(huán)境中,魯棒性物理擾動成功欺騙路標(biāo)識別系統(tǒng)。為了證實魯棒性物理擾動具有通用性,他們將用魯棒性物理擾動生成的涂鴉貼在微波爐上,成功誤導(dǎo)Inception-v3分類器[31]將微波爐識別成手機。Lu等[42]對道路標(biāo)志圖像與檢測器的物理對抗樣本進(jìn)行了實驗,實驗表明YOLO[40]和Faster-RCNN[37]等檢測器目前沒有被Evtimov等[41]提出的攻擊所欺騙。然而Eykholt等[43]聲稱能夠產(chǎn)生一個小的貼紙來欺騙YOLO檢測器[40],也可以欺騙Faster-RCNN[37]。Chen等[44]進(jìn)一步使用了EOT技術(shù)[22,45]技術(shù),使攻擊更具有魯棒性,成功誤導(dǎo)Faster-RCNN檢測器[37]。
4.5 語義分割
Hendrik等[46]給出了針對語義分割和目標(biāo)檢測的通用對抗樣本。隨后,Xie等[47]首先提出了一種系統(tǒng)的算法(稠密對抗生成器),生成用于對象檢測和分割任務(wù)的對抗樣本。如圖3所示,在添加擾動后,語義分割和目標(biāo)檢測同時預(yù)測出錯。稠密對抗性生成器的基本思想是同時考慮檢測和分割任務(wù)中的所有目標(biāo),優(yōu)化總體損失。此外,為了解決目標(biāo)檢測任務(wù)中建議數(shù)量較多的問題,引入交并比來保持增加但合理的建議數(shù)量。文獻(xiàn)[48]發(fā)現(xiàn),在分割任務(wù)中,廣泛使用的對抗損失與準(zhǔn)確性之間的關(guān)系沒有在分類任務(wù)中那么明確,因此,提出了使用Houdini損失來近似真實的對抗損失,使對抗擾動更不易被人眼察覺。

圖3 語義分割對抗樣本實例Figure 3 Adversarial example of semantic segmentation
4.6 人臉識別
Sharif等[49]開發(fā)了一種針對人臉識別系統(tǒng)進(jìn)行攻擊的系統(tǒng)性方法,只需要通過添加一副眼鏡框就能夠讓人臉識別系統(tǒng)識別錯誤。Zhou等[50]研究了一個現(xiàn)實中對抗攻擊的有趣例子,發(fā)現(xiàn)紅外光也可以用來干擾人臉識別系統(tǒng)。攻擊者可以在一頂帽子的帽檐安裝LED燈,利用LED燈照射到臉部產(chǎn)生人眼無法察覺但能被相機傳感器捕捉到的紫色光線,躲避人臉識別系統(tǒng)檢測。
5 防御策略
近年來,研究人員提出了許多針對對抗樣本問題的防御策略。本文將防御策略分為預(yù)處理、提高模型魯棒性、惡意檢測3類,如圖4所示。
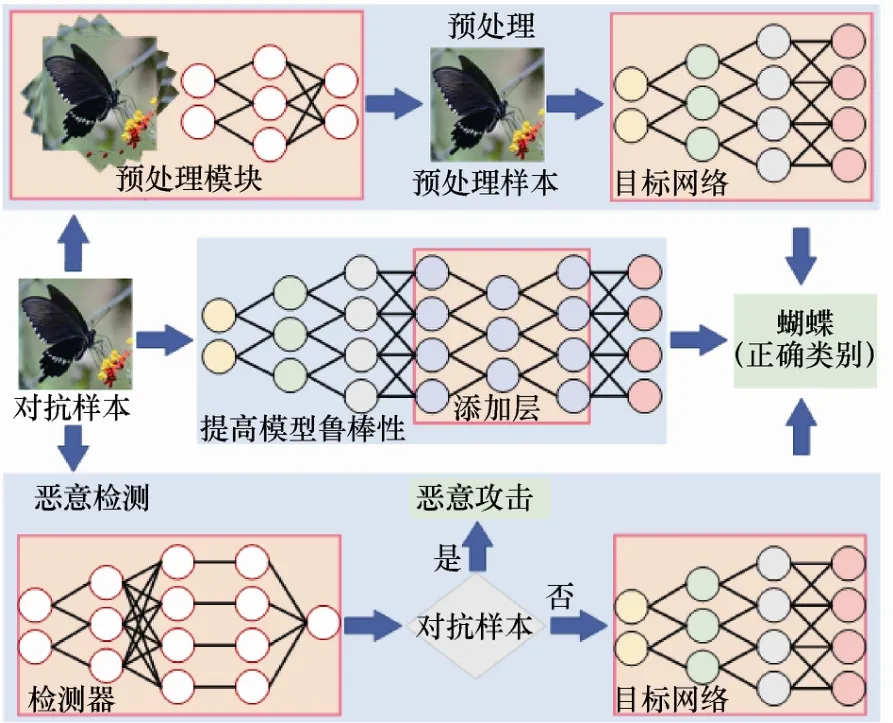
圖4 對抗防御框架Figure 4 A framework of adversarial defense
預(yù)處理是在圖像輸入網(wǎng)絡(luò)之前對圖像進(jìn)行去噪、隨機化、重構(gòu)、縮放、變換、增強等操作,減輕對抗擾動對模型分類的影響,通常無須對模型進(jìn)行任何的修改,可以直接應(yīng)用于已經(jīng)訓(xùn)練好的模型,計算開銷較低。提高模型魯棒性則通過修改模型架構(gòu)、訓(xùn)練方式、正則化、特征去噪等方式實現(xiàn),增強模型抵抗對抗樣本的能力,但需對模型進(jìn)行重新訓(xùn)練,計算開銷較大。惡意檢測防御方法檢測用戶輸入的圖像是否是惡意圖像,從而阻止對抗攻擊。預(yù)處理與惡意檢測方法無須修改預(yù)訓(xùn)練模型,但惡意檢測的防御方法不能夠恢復(fù)對抗樣本的正確類別。提高模型魯棒則著重對模型自身入手,不借助附加機制進(jìn)行預(yù)處理和檢測。
5.1 預(yù)處理
5.1.1 隨機化
Wang等[51]通過在樣本中隨機消除特征(類似dropout[52]的方式)來阻止攻擊者構(gòu)建有效的對抗樣本,雖然dropout[52]訓(xùn)練時隨機讓神經(jīng)元失效,但測試階段的防御效果不顯著。而隨機消除特征在測試階段能夠隨機讓神經(jīng)元失效。Prakash等[53]提出一種像素偏移的方法,包括重新分配像素值和小波去噪兩個部分。重新分配像素值利用了卷積神經(jīng)網(wǎng)絡(luò)對自然圖像中噪聲的魯棒性,隨機將一些像素替換為一個小鄰域中隨機選擇的像素。小波去噪修復(fù)重新分配像素值和對抗性擾動帶來的圖像破壞,使圖像變得更加自然。然而,Athalye等[15]利用反向近似梯度技術(shù)繞過像素偏移過程的不可微問題,成功繞過防御方法。相似地,Ho等[54]提出用像素重繪來防御對抗樣本。首先訓(xùn)練一個預(yù)測模型用于生成預(yù)測圖像,并對圖像像素值的取值范圍進(jìn)行區(qū)間劃分。原始圖像經(jīng)預(yù)測模型生成預(yù)測圖像,獲得預(yù)測圖像的每個像素值所在區(qū)間,再用區(qū)間內(nèi)的隨機值替換原始圖像的像素值。
5.1.2 圖像變換
Dziugaite等[55]研究發(fā)現(xiàn)對于FGSM算法[11]產(chǎn)生微小擾動的對抗樣本,JPEG壓縮能夠減輕對抗樣本導(dǎo)致的分類錯誤,但隨著擾動程度的增大,JPEG壓縮的防御效果會降低。Das等[56]進(jìn)一步研究發(fā)現(xiàn)JPEG壓縮的一個重要能力就是它能夠去除圖像內(nèi)部的高頻信號分量,相當(dāng)于有選擇性地模糊圖像,可以消除圖像上的對抗性擾動。由此Das等[56]提出一種能夠快速搭建在已訓(xùn)練好的網(wǎng)絡(luò)模型上的JPEG壓縮預(yù)處理模塊。然而,Guo等[57]發(fā)現(xiàn)總方差最小化[58]和圖像縫合[59]比固定性的去噪過程(如JPEG壓縮[55]、位深度縮減[60]、非局部均值濾波[61]等)具有更強的防御能力。在眾多簡單防御的基礎(chǔ)上,Raff等[62]提出集合一系列簡單的防御(如位深度縮減[60]、JPEG壓縮[55]、小波去噪[63]、均值濾波[64]、非局部均值濾波[61]等)來構(gòu)建一個強的防御機制來抵抗對抗樣本,并且深入考慮了模糊梯度的問題[16]。其基本思想是從大量的隨機變換中隨機選擇幾個變換,并在圖像輸入網(wǎng)絡(luò)之前按隨機順序應(yīng)用每個變換。該方法在大規(guī)模數(shù)據(jù)集[8]中也具有魯棒性。
然而,這些基本的變換大多數(shù)已經(jīng)被證明不能夠有效防御對抗樣本[53,55,60],而且He等[65]曾聲稱簡單防御方法的組合并不能有效防御對抗樣本。
5.1.3 去噪網(wǎng)絡(luò)
Akhtar等[66]針對通用型擾動攻擊算法[12],提出防御框架。該框架包含擾動校正網(wǎng)絡(luò)和擾動檢驗器兩部分。該框架將擾動校正網(wǎng)絡(luò)作為額外的預(yù)輸入層附加到目標(biāo)網(wǎng)絡(luò)中,在不更新目標(biāo)模型參數(shù)的情況下訓(xùn)練它們對被擾動后的圖像進(jìn)行校正,使分類器對對抗樣本和其原始圖像預(yù)測結(jié)果相一致。擾動檢驗器是將擾動修正網(wǎng)絡(luò)輸入輸出的特征差異作為輸入,通過支持向量機[67]學(xué)習(xí)得到二元分類器。輸入圖像首先經(jīng)過擾動修正網(wǎng)絡(luò),然后使用擾動檢驗器進(jìn)行檢測是否存在擾動。如果檢測到擾動,就用經(jīng)過擾動修正網(wǎng)絡(luò)修正后的圖像代替原始圖像作為分類器輸入。
傳統(tǒng)的去噪自編碼器[68]是流行的去噪模型。但傳統(tǒng)的去噪自編碼器在編碼器和解碼器之間節(jié)點數(shù)太少會限制重建高分辨率圖像所需的精細(xì)尺度信息。為了解決這個問題,Liao等[69]使用U-net[70]作為去噪網(wǎng)絡(luò)模型。U-net[70]網(wǎng)絡(luò)模型與傳統(tǒng)的自編碼器有兩點區(qū)別:第一,去噪網(wǎng)絡(luò)使用的不是像素層面的損失函數(shù),而是使用特征圖作為損失函數(shù);第二,U-net去噪網(wǎng)絡(luò)學(xué)習(xí)的是對抗擾動,而不是構(gòu)造整個圖像。利用去噪網(wǎng)絡(luò)得到對抗性擾動,并結(jié)合原圖像得到去噪后的圖像。但Athalye等[15]指出這個方法不能有效防御白盒攻擊。
5.1.4 對抗生成網(wǎng)絡(luò)
Samangouei等[71]提出一個基于對抗生成網(wǎng)絡(luò)[36]的防御框架,主要思想是采用原始數(shù)據(jù)集訓(xùn)練一個對抗生成網(wǎng)絡(luò),利用生成器的表達(dá)能力重構(gòu)一個與原始圖像相似但不含對抗擾動的重構(gòu)圖像。整個防御框架如圖5所示。輸入圖像經(jīng)過對抗性生成網(wǎng)絡(luò)進(jìn)行重構(gòu)后,得到一個與原始圖像相似的重構(gòu)圖像,再將重構(gòu)的圖像輸入目標(biāo)網(wǎng)絡(luò)模型進(jìn)行分類。其中引入了隨機種子,使整個網(wǎng)絡(luò)模型難以攻擊。但這個方法在CIFAR-10數(shù)據(jù)集[72]上不能夠有效防御白盒攻擊。并且Athalye等[16]在MNIST數(shù)據(jù)集[73]上采用反向傳播近似梯度技術(shù)對這種防御機制進(jìn)行攻擊,但成功率只有48%。
相似地,Bao等[74]提出基于雙向生成對抗網(wǎng)絡(luò)[75-76]的特征雙向?qū)股删W(wǎng)絡(luò),它描述了高維數(shù)據(jù)空間和低維語義潛在空間之間的雙向映射。輸入圖像經(jīng)過特征雙向生成網(wǎng)絡(luò)映射,提取語義特征,這些特征不隨擾動而變化,并根據(jù)語義特征把輸入圖像重構(gòu)成無擾動圖像。輸入圖像經(jīng)過雙向?qū)股删W(wǎng)絡(luò)的重構(gòu)后輸入目標(biāo)模型進(jìn)行分類。實驗表明,在白盒和灰盒攻擊下,這種防御方法對于預(yù)先訓(xùn)練好的任意分類器都有效。

圖5 對抗生成網(wǎng)絡(luò)防御框架Figure 5 Defense framework of generative adversarial network
5.1.5 超分辨率
Mustafa等[77]提出一種基于超分辨率[78]和小波去噪[79]的防御方法。其基本思想是使用超分辨率網(wǎng)絡(luò)將流形外的對抗樣本引入自然圖像流形中,從而將分類恢復(fù)到正確的類別。算法采用小波去噪減少惡意對抗擾動,然后使用超分辨率網(wǎng)絡(luò)加強圖像視覺質(zhì)量。該方法在無須重新訓(xùn)練模型的前提下,可以補充到現(xiàn)有的防御機制,同時提升分類準(zhǔn)確率。
5.2 提高模型魯棒性
5.2.1 對抗性訓(xùn)練
對抗性訓(xùn)練作為目前能夠有效提高模型魯棒性的防御方式,其缺點是訓(xùn)練模型的開銷太大且無法對所有攻擊類型的對抗樣本進(jìn)行對抗訓(xùn)練。
Goodfellow等首次[11]提出對抗訓(xùn)練來提高模型魯棒性,Kurakin等[18]利用批量歸一化[80]方法,成功將其擴(kuò)展到Inception-v3模型[31]和ImageNet數(shù)據(jù)集[8]。但其缺點是只能防御單步的攻擊[11],不能防御迭代的攻擊[81]。而Chang等[82]提出了一種基于雙對抗樣本的訓(xùn)練方式,既能夠抵抗單步的對抗樣本,也可以防御迭代的對抗樣本。許多對抗訓(xùn)練只能防御特定的對抗攻擊[11,83-84],在Athalye等[16]的評測中,Madry等[81]利用梯度投影下降攻擊算法進(jìn)行對抗訓(xùn)練的防御方法是唯一沒有被完全攻破的防御方法。但Madry等[81]只在MNIST[73]和CIFAR-10[72]數(shù)據(jù)集上進(jìn)行對抗訓(xùn)練。隨后,Kannan等[85]成功將其擴(kuò)展到ImageNet數(shù)據(jù)集[8],將相似的樣本構(gòu)成一對,配對樣本的模型輸出相似程度作為損失函數(shù)的一部分。該方法在ImageNet數(shù)據(jù)集[8]上具有魯棒性,而且超過了當(dāng)時表現(xiàn)最好的集成對抗訓(xùn)練方法[86]。
此外,Li等[87]利用距離度量學(xué)習(xí)中常見的三重?fù)p失函數(shù)來構(gòu)建對抗訓(xùn)練模型。三重?fù)p失函數(shù)可以優(yōu)化嵌入空間,即具有相同標(biāo)簽的樣本在空間中盡可能地接近,不同標(biāo)簽的樣本盡可能地遠(yuǎn)離。由于很難找到一個能夠代表對抗樣本域的樣本,因此對抗訓(xùn)練泛化能力較弱。Song等[88]提出了一種具有領(lǐng)域適應(yīng)能力的對抗訓(xùn)練方法,旨在學(xué)習(xí)樣本有意義的表示,這種表示在對抗樣本和原始數(shù)據(jù)集上是不變的。
5.2.2 批量調(diào)整網(wǎng)絡(luò)梯度
Rozsa等[89]認(rèn)為在一批訓(xùn)練樣本中,正確分類的樣本往往對模型權(quán)重更新貢獻(xiàn)較小,在正常樣本周圍難以形成更加平坦、不變的區(qū)域,這導(dǎo)致很小的擾動就能夠使分類器分類錯誤。因此,他們提出了一種簡單、高效、可以提高模型魯棒性的訓(xùn)練方法(批量調(diào)整網(wǎng)絡(luò)梯度)對梯度進(jìn)行調(diào)整,用于提高分類正確樣本對模型參數(shù)更新的貢獻(xiàn)值。該方法的優(yōu)點在于不依賴任何形式的數(shù)據(jù)擴(kuò)充和使用對抗樣本進(jìn)行對抗性訓(xùn)練,同時能夠保持甚至增強整體分類性能并抵抗對抗攻擊。
5.2.3 正則化
Tomar等[90]提出了一種深度學(xué)習(xí)和流形學(xué)習(xí)相結(jié)合的方法(流形正則化網(wǎng)絡(luò))。在模型損失上附加一個盲點特性的流形損失項。結(jié)果表明,該方法能夠抵抗對抗樣本,并且能夠使模型在流形上泛化。此外在MNIST[73]、CIFAR-10[72]、SVHN[91]數(shù)據(jù)集上結(jié)合dropout[52]能夠獲得較好的表現(xiàn)。而缺點在于梯度正則化是二階的,這導(dǎo)致模型的訓(xùn)練時間翻了一倍。Sankaranarayanan等[92]觀察到隱藏層激活的對抗性擾動在不同的樣本中普遍存在,提出通過中間激活函數(shù)層的對抗擾動來提供更強的正則化。該方法不僅比dropout[52]有更強的正則化,而且比傳統(tǒng)對抗性訓(xùn)練方法的魯棒性更強。
神經(jīng)網(wǎng)絡(luò)模型不能夠?qū)W習(xí)到關(guān)鍵特征,圖像輕微的變化就導(dǎo)致分類器分類錯誤。針對這個問題,Liu等[93]提出通過基于非線性注意力模塊和L2特征正則化的特征優(yōu)先模型,使模型分類依賴于關(guān)鍵特征。其中,注意力模塊通過給關(guān)鍵特征分配更大的權(quán)重,促使模型學(xué)習(xí)到關(guān)鍵特征。對模型進(jìn)行L2正則化促使提取原始圖像和對抗樣本相似的本質(zhì)特征,有效忽略了添加的擾動。
5.2.4 防御蒸餾
Papernot等[94]基于網(wǎng)絡(luò)蒸餾[95]思想提出一種防御方法(防御蒸餾)。網(wǎng)絡(luò)蒸餾技術(shù)原本是為了把網(wǎng)絡(luò)模型部署到移動端而設(shè)計的一種網(wǎng)絡(luò)壓縮技術(shù),它能夠把大的網(wǎng)絡(luò)壓縮成小的網(wǎng)絡(luò),而且能夠保持網(wǎng)絡(luò)的性能。在蒸餾的過程中通過調(diào)整溫度(softmax函數(shù)中的參數(shù)T),產(chǎn)生更加平滑、對擾動更加不敏感的模型,從而提升模型對對抗性性樣本的魯棒性。文獻(xiàn)[94]聲稱防御蒸餾能夠抵抗90%的對抗樣本。隨后,Carlini等[96]指出蒸餾并不能防御對抗攻擊,只要對C&W[20]進(jìn)行微調(diào)便能攻擊成功。
5.2.5 特征去噪
微小的對抗性擾動在網(wǎng)絡(luò)中被逐層放大,導(dǎo)致網(wǎng)絡(luò)的特征圖中出現(xiàn)大量的噪聲。原始圖像的特征主要集中在圖像中的語義特征,而對抗樣本的特征在語義不相關(guān)的區(qū)域被激活。因此,Xie等[97]開發(fā)了新的卷積網(wǎng)絡(luò)架構(gòu),這個架構(gòu)包含了用于特征圖去噪的去噪模塊。雖然去噪模塊并不能提高在原始數(shù)據(jù)集下的分類準(zhǔn)確率,但去噪模塊和對抗性訓(xùn)練結(jié)合在一起,在白盒攻擊和黑盒攻擊中能夠顯著提高模型的魯棒性。在2018年CAAD(對抗樣本攻防賽)中,該方法在48種未知攻擊下獲得50.6%的分類準(zhǔn)確率。
5.2.6 隨機消除特征
由于深度學(xué)習(xí)模型不能夠很好的學(xué)習(xí)到關(guān)鍵特征,攻擊者通過向不相關(guān)的非關(guān)鍵特征維度添加微小的擾動,就可以導(dǎo)致模型分類錯誤。因此,Gao等[98]提出了一種DeepCloak機制,具體過程如圖6所示。利用掩碼的方式刪除網(wǎng)絡(luò)模型中不必要的特征,限制了攻擊者生成對抗樣本的能力,從而提升模型的魯棒性。與其他的防御機制相比,DeepCloak機制更易于實現(xiàn)且計算效率較高。

圖6 隨機消除特征框架Figure 6 A framework of random feature nullification
5.2.7 卷積稀疏編碼
Sun等[99]基于卷積稀疏編碼[100],構(gòu)造了一個分層的低維準(zhǔn)自然圖像空間。文獻(xiàn)[99]通過將原始圖像和對抗樣本映射到一個低維準(zhǔn)自然圖像空間來實現(xiàn)高水平的魯棒性。這個準(zhǔn)自然圖像空間近似于自然圖像空間。同時該方法消除了對抗性擾動,使對抗樣本接近其在特征空間中的原始輸入。在訓(xùn)練階段,作者在輸入圖像和神經(jīng)網(wǎng)絡(luò)的第一層之間引入一個稀疏變換層來有效地將圖像映射到準(zhǔn)自然圖像空間中,用映射到準(zhǔn)自然空間的圖像對分類模型進(jìn)行訓(xùn)練。在測試階段,把原始輸入映射到準(zhǔn)自然空間的圖像作為分類模型的輸入。與其他不可知攻擊的對抗性防御方法相比,該方法在對抗性擾動的大小、各種不同的圖像分辨率和數(shù)據(jù)集規(guī)模方面,都有具有更強的魯棒性。
5.2.8 深度收縮網(wǎng)絡(luò)
研究發(fā)現(xiàn)去噪自編碼器[101]可以消除大量的對抗性噪聲,但當(dāng)去噪自編碼器與原始神經(jīng)網(wǎng)絡(luò)疊加時,會再次受到失真程度更小的對抗樣本攻擊。Rifai等[102]認(rèn)為這是自動編碼機訓(xùn)練上的問題,并提出了深度收縮網(wǎng)絡(luò)模型。模型采用了一種全新的端到端的訓(xùn)練過程,該過程采用伸縮自編碼器相似的平滑損失、逐層懲罰,近似地使網(wǎng)絡(luò)輸出的方差相對于輸入的擾動最小,使模型在訓(xùn)練數(shù)據(jù)點周圍更加平滑。這增強了模型對對抗樣本的魯棒性,并且沒有明顯的性能損失。
5.2.9 阻止可移植性
對抗樣本具有可遷移性的特點,由特定網(wǎng)絡(luò)模型生成的對抗樣本可能誤導(dǎo)其他網(wǎng)絡(luò)模型結(jié)構(gòu)不同或者不同訓(xùn)練集上的分類器。針對這個問題,Hosseini等[103]提出了空標(biāo)簽的方法來防御黑盒下的對抗樣本可移植性攻擊。其主要的思想是通過對數(shù)據(jù)集的標(biāo)簽增加一個空類別,并進(jìn)行對抗性訓(xùn)練。該方法的優(yōu)勢在于能夠?qū)箻颖镜腻e誤標(biāo)簽分類到空類別中,而不是其他的錯誤類別,有效阻止對抗樣本的可移植性,同時圖像能夠保持模型的精度。
5.3 惡意檢測
5.3.1 圖像變換
Tian等[104]認(rèn)為對抗性的樣本通常對某些圖像變換操作敏感,如旋轉(zhuǎn)和移位,但原始圖像通常是免疫這種操作的,因此,提出一種基于圖像變換的對抗樣本檢測方法。首先,對一幅圖像進(jìn)行一組的變換操作,生成多幅變換后的圖像。然后,使用這些變換后的圖像的分類結(jié)果作為特征訓(xùn)練一個神經(jīng)網(wǎng)絡(luò)來預(yù)測原始圖像是否受到了攻擊者的干擾。為了防御更復(fù)雜的白盒攻擊,在轉(zhuǎn)換過程中引入隨機性。對多個圖像數(shù)據(jù)集的實驗結(jié)果表明,C&W[20]算法產(chǎn)生的對抗樣本的檢測率達(dá)到99%。其中,對于白盒攻擊,該方法的檢測率達(dá)到70%以上。
5.3.2 有狀態(tài)檢測
針對白盒對抗樣本的防御已被證明是難以實現(xiàn)的。白盒攻擊在實際場景中不太現(xiàn)實,云平臺提供的服務(wù)一般是基于詢問的方式。因此,Chen等[105]首次提出基于有狀態(tài)檢測的黑盒防御方法,相比目前研究的無狀態(tài)防御,該方法增強了防御方的能力。有狀態(tài)檢測方法思想是記錄一定量的用戶詢問記錄,并且在用戶下次詢問時,將用戶詢問與以往的記錄進(jìn)行對比,如果相似程度在規(guī)定的一定閾值內(nèi)則認(rèn)為是惡意攻擊,具體流程如圖7所示。首先,為了能夠壓縮用戶詢問記錄的存儲,使用了相似編碼進(jìn)行壓縮編碼。然后,將用戶詢問輸入和以往記錄比較,利用k近鄰算法計算距離d,如果d小于閾值δ則認(rèn)為用戶是在進(jìn)行惡意攻擊。利用黑盒攻擊NES[106]和邊界攻擊[26]進(jìn)行評估,實驗分析表明,基于詢問的黑盒攻擊通常需要幾十萬到上百萬的詢問,這非常容易觸發(fā)用戶的防御機制。即使不觸發(fā)防御機制,攻擊所需的存儲服務(wù)也需消耗大量資源。有狀態(tài)的檢測方法缺點是無法防御不需要詢問的遷移攻擊。但是,該方法能夠與防御遷移攻擊的集成對抗性訓(xùn)練方法進(jìn)行結(jié)合,可以彌補有狀態(tài)檢測的不足,使其在黑盒攻擊情況下有較好的表現(xiàn)。
5.3.3 隱藏層特征
Metzen等[107]提出增加一個小的檢測子網(wǎng)絡(luò)來擴(kuò)充深度神經(jīng)網(wǎng)絡(luò),這個子網(wǎng)絡(luò)是用于檢測對抗樣本的二分類器。文獻(xiàn)[101]將子網(wǎng)絡(luò)嵌入網(wǎng)絡(luò)內(nèi)部,結(jié)合對抗性訓(xùn)練,成功檢測由FGSM[11]、BIM[18]、Deepfool[21]攻擊算法產(chǎn)生的對抗樣本。Li等[108]則通過分析對抗樣本與正常的樣本是否來自相同分布的方式來進(jìn)行對抗樣本的檢測。該檢測方法使用中間層的特征,即基于卷積層的輸出,而不是直接使用原始圖像和對抗樣本進(jìn)行統(tǒng)計分布。文獻(xiàn)[108]用這些中間特征訓(xùn)練了一個級聯(lián)(層疊)分類器,有效地檢測對抗樣本。此外,從一個特定的對抗算法[10]生成數(shù)據(jù)并進(jìn)行訓(xùn)練,得到的分類器可以成功地檢測從完全不同機制[109]生成的對抗樣本。Feinman等[110]認(rèn)為對抗樣本與原始圖像屬于不同的分布,因此使用高斯混合模型對神經(jīng)網(wǎng)絡(luò)最后一層的輸出進(jìn)行建模,用來檢測對抗樣本。由于神經(jīng)網(wǎng)絡(luò)尾部的隱藏層可以捕獲到輸入的高級語義信息,在最后一層上使用一個簡單的分類器將比其應(yīng)用于原始輸入圖像更加準(zhǔn)確可靠。相似地,Zheng等[111]通過分析深度神經(jīng)網(wǎng)絡(luò)中隱藏神經(jīng)元的輸出分布,使用高斯混合模型來近似深度神經(jīng)網(wǎng)絡(luò)分類器的隱藏狀態(tài)分布,然后通過判斷輸入樣本狀態(tài)分布是否異常來檢測對抗樣本。該方法能夠應(yīng)用于任何深度神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)上,并可以與其他防御策略相結(jié)合,以此提高模型的魯棒性。實驗表明,該方法能夠防御黑盒和灰盒攻擊。
Carlini等[14]通過構(gòu)造新的損失函數(shù),成功繞過了10種檢測方法,其中包括上面所提到的前3種方法[107-108,110]。

圖7 有狀態(tài)檢測流程Figure 7 The pipeline of stateful detection
5.3.4 流形學(xué)習(xí)
Meng等[112]提出一種防御對抗樣本的方法,由若干個檢測器和一個修正器組成。檢測器在訓(xùn)練期間學(xué)習(xí)對抗樣本的流行分布,對于遠(yuǎn)離流形邊界的樣本判定為對抗樣本。而修正器在流形區(qū)域中尋找一個與輸入x相近的x′替換x并輸入分類器進(jìn)行分類。然而,Carlini等[113]指出這個方法只能抵抗輕微對抗擾動。Huang等[114]觀察到對抗樣本子空間在方向上與原始數(shù)據(jù)子流形非常接近,因此通過添加隨機擾動來擴(kuò)展對抗子空間能夠使對抗樣本被重新分類正確。而且由于神經(jīng)網(wǎng)絡(luò)模型的魯棒性,添加微弱的隨機擾動并不會影響分類結(jié)果。Huang等[114]提出了一種模型無關(guān)方法來解決檢測對抗樣本。該方法通過分析模型對于隨機擾動輸入的反應(yīng),以相對變化的置信度作為檢測對抗樣本的鑒別標(biāo)準(zhǔn),在理論框架中學(xué)習(xí)范數(shù)有界對抗性擾動的魯棒性,可以輕易地部署到現(xiàn)成的深度學(xué)習(xí)模型中。
5.3.5 自適應(yīng)去噪
傳統(tǒng)的去噪對擾動較大的情況效果顯著,但在擾動較小的情況,去噪會使圖像模糊,導(dǎo)致分類準(zhǔn)確率低。針對這個問題,Liang等[115]利用交叉熵的大小作為標(biāo)準(zhǔn)實現(xiàn)自適應(yīng)去噪。其中包含兩種圖像降噪方式:標(biāo)量量化和空間平滑濾波。先使用交叉熵自適應(yīng)量化區(qū)間大小,然后判斷是否需要進(jìn)行空間平滑濾波。降噪后的圖像和原始輸入分別用分類器進(jìn)行分類,如果分類結(jié)果一致,則認(rèn)為原始輸入是正常樣本,否則認(rèn)為是對抗樣本。
5.4 防御方法總結(jié)
各類防御方法都有其相應(yīng)的優(yōu)點和缺點,本文將具有代表性的防御方法加以比較,如表2所示。預(yù)處理和惡意檢測類的方法著重對輸入數(shù)據(jù)進(jìn)行去噪,然而這些方法不能夠有效過濾對抗擾動,存在一些問題。例如,只能針對特定數(shù)據(jù)集或者算法有效,不能夠很好泛化,但其優(yōu)點是開銷較小,往往無須對模型進(jìn)行修改和重新訓(xùn)練原有模型,容易補充到已有的防御系統(tǒng)。提高模型魯棒性的方法針對模型自身進(jìn)行改進(jìn),往往需要對模型架構(gòu)和訓(xùn)練方式進(jìn)行修改,并進(jìn)行重新訓(xùn)練。目前公認(rèn)的有效防御對抗樣本的方法是對抗訓(xùn)練,其主要的缺點是往往需要改變原有模型的架構(gòu)、訓(xùn)練策略進(jìn)行對抗訓(xùn)練,這就導(dǎo)致模型訓(xùn)練開銷較大。

表2 防御方法總結(jié)Table 2 A summary of adversarial defenses
6 未來展望
6.1 對抗樣本
對抗樣本最早只針對圖像分類任務(wù)[10]提出,然而根據(jù)本文第4節(jié)中的描述,針對圖像分類[30]、網(wǎng)絡(luò)空間攻擊[32,34]、停車牌識別[41]、目標(biāo)檢測[35,39]、語義分割[46-47]、人臉識別[49]等任務(wù)的對抗樣本被發(fā)現(xiàn)。盡管已經(jīng)有針對不同應(yīng)用場景的對抗樣本,但與現(xiàn)實世界中的應(yīng)用場景還有較大差距。未來針對現(xiàn)實物理環(huán)境具有魯棒性的對抗樣本將是研究的熱點。
6.2 對抗攻擊
對抗攻擊從梯度攻擊[11,18,81]發(fā)展到置信度攻擊[24],再到?jīng)Q策攻擊[106,116]的攻擊,其攻擊所需的信息量逐漸減少,而且已經(jīng)成功應(yīng)用于現(xiàn)實場景。盡管近年來對抗樣本的生成算法取得了較大的進(jìn)步,但仍然有許多不足和限制,如詢問的次數(shù)過多、攻擊不夠穩(wěn)定等。未來針對更高效、更微小擾動、穩(wěn)定的黑盒攻擊算法仍是研究的熱點。
6.3 對抗性防御
正如本文中所提到的大部分防御方法只針對特定的已知攻擊算法有效,在未知攻擊算法中并不能夠很好地泛化。迄今為止,仍然沒有一個對抗樣本的防御方法能夠完全抵抗白盒攻擊。因此,研究人員開始著重于針對灰盒、黑盒攻擊[77]以及對抗樣本檢測機制[105]方向的研究。相比于強大的白盒攻擊,灰盒和黑盒攻擊者所擁有的信息更少,相對更容易防御,而且在實現(xiàn)環(huán)境中更加符合實際情況。如何訓(xùn)練一個魯棒性模型以及有惡意檢測機制的模型是未來的研究熱點。
7 結(jié)束語
本文針對深度學(xué)習(xí)領(lǐng)域存在的對抗攻擊問題,首先給出了對抗樣本和對抗攻擊的基本概念,構(gòu)建了威脅模型;介紹了近年來深度學(xué)習(xí)領(lǐng)域具有代表性的對抗攻擊手段及現(xiàn)實中的對抗攻擊實例;研究了典型的防御方法,并根據(jù)最新研究進(jìn)展分析了方法的有效性;針對深度學(xué)習(xí)的對抗攻擊能夠直接影響到系統(tǒng)的可用性,誘導(dǎo)系統(tǒng)輸出錯誤的結(jié)果。目前該領(lǐng)域內(nèi)仍然沒有一個能夠有效防御對抗樣本的防御機制,但訓(xùn)練一個魯棒性模型是可能的。最后,根據(jù)對研究現(xiàn)狀的分析,本文討論了這一領(lǐng)域未來研究方向。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
