基于大數據驅動的智慧圖書館推送系統設計
2020-10-22 02:11:33胡勇祥
現代電子技術 2020年20期
胡勇祥
摘? 要: 傳統的智慧圖書館推送系統由于圖書館信息資源量過大,導致所需推送時間過長,為此設計一種基于大數據驅動的智慧圖書館推送系統。通過應用表示層、業務邏輯層和數據存儲層完成系統總體架構設計。根據系統架構,通過用戶終端、交換機、服務器和數據存儲器等完成系統硬件設計;通過設計系統的功能模塊,利用MapReduce分析計算用戶信息、爬蟲技術爬取與用戶需求相關的圖書館信息,完成系統軟件設計。至此,完成基于大數據驅動的智慧圖書館推送系統設計。實驗結果表明,與傳統的智慧圖書館推送系統相比,提出的基于大數據驅動的智慧圖書館推送系統能夠更快速地為用戶推送信息。
關鍵詞: 智慧圖書館; 推送系統; 系統設計; 大數據驅動; 信息提取; 對比驗證
中圖分類號: TN919?34; TP39? ? ? ? ? ? ? ? ? ? ?文獻標識碼: A? ? ? ? ? ? ? ? ? ? ?文章編號: 1004?373X(2020)20?0102?03
Design of smart library push system based on big data driver
HU Yongxiang
(Huanggang Normal University, Huanggang 438000, China)
Abstract: As the traditional smart library push system takes too much push time due to the excessive amount of library information resources, a smart library push system based on big data driver is designed. The overall system architecture design is completed by the application of presentation layer, business logic layer and data storage layer. According to the system architecture, the system hardware design is completed by means of the user terminal, switch, server, data storage, etc. By designing the functional modules of the system, MapReduce is used to analyze and calculate user information, and crawler technology is used to crawl library information related to user needs, so as to complete the software design of system. Thus the design of smart library push system based on big data driver is completed. The experimental results show that, in comparison with the traditional smart library push system, the proposed smart library push system based on big data driver can push information for users more quickly.
Keywords: smart library; push system; system design; big data driver; information extraction; comparison validation
0? 引? 言
智慧圖書館是將智能技術運用到圖書館建設中而形成的智能化圖書館[1?2]。在智慧圖書館的建設中,智慧圖書館推送系統是其中的核心系統之一,該系統通過感知和預測讀者的需求,為讀者提供智慧化的、高精準度的資源和服務[3?4]。隨著互聯網技術的發展,信息資源的數量也隨之呈指數增長。面對海量的信息資源,圖書館讀者需要快速、精準地獲取自己需要的信息。要想為讀者提供更為快速、精準的信息,就要感知和預測讀者的需求,為讀者提供智能化的推送服務。然而,現有的智慧圖書館推送系統在感知讀者需求的方面,還存在推送精準度差、所需推送時間長等問題[5]。
近年來,在大數據環境下,物聯網、云計算、人工智能等技術得到了廣泛的應用[6?7]。根據上述分析,基于大數據驅動設計智慧圖書館推送系統,使智慧圖書館更加高效、智能地為讀者提供智能化服務。
1? 基于大數據驅動的智慧圖書館推送系統設計
采用大數據技術中的爬蟲技術和MapReduce,基于大數據驅動,設計智慧圖書館推送系統。首先,設計智慧圖書館系統的總體架構,根據總體架構,通過用戶終端、交換機、服務器和數據存儲器等硬件完成系統的硬件設計,利用MapReduce對用戶信息作分析計算,再利用爬蟲技術爬取與用戶需求相關的圖書館信息,完成系統的軟件設計。
1.1? 基于大數據驅動的智慧圖書館推送系統總體架構
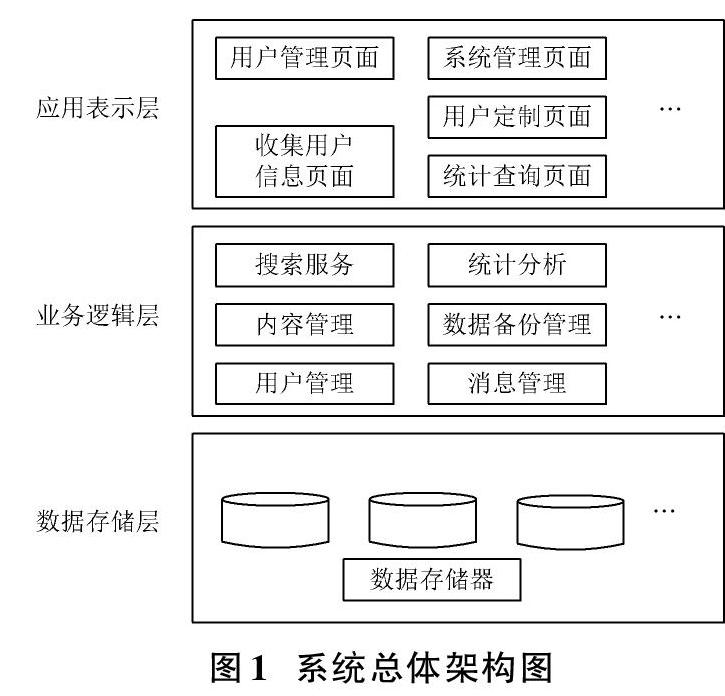
智慧圖書館推送系統的總體架構由應用表示層、業務邏輯層、數據存儲層3個層次組成。系統總體架構圖如圖1所示。
應用表示層為圖書館用戶提供一個可視化的用戶界面,是智慧圖書館推送系統的門戶和功能接入口。用戶通過訪問Web登錄智慧圖書館推送系統,實現與圖書館推送系統中應用程序的對話。在該層設有用戶管理模塊、用戶定制管理模塊、信息收集模塊。在用戶管理模塊,用戶可以執行注冊登錄、信息管理、權限管理等操作。在信息收集模塊,可以收集用戶操作記錄等用戶信息,并作出預處理設置。在用戶定制管理模塊,可以執行用戶定制數據的錄入、修改、保存、刪除等操作。
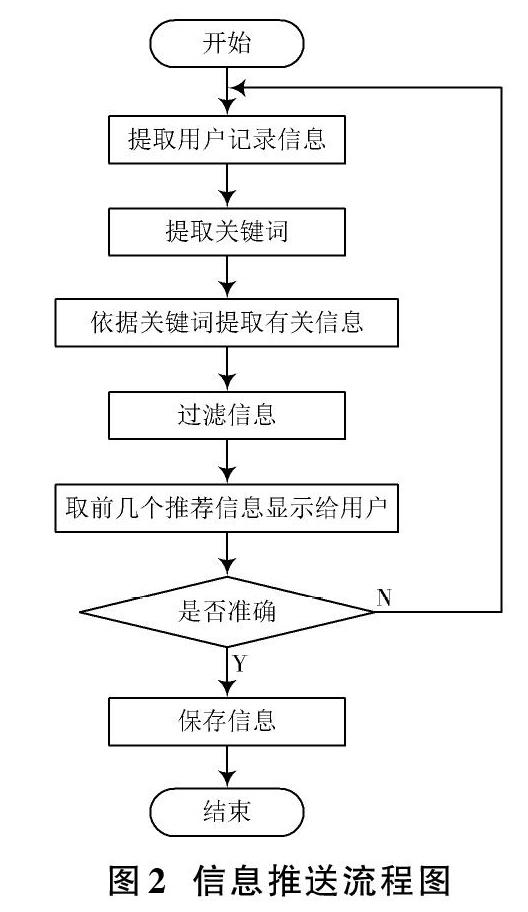
業務邏輯層在應用表示層和數據存儲層之間,是圖書館推送系統對用戶的需求、系統的數據業務處理的部分,此層將應用表示層和數據存儲層連接起來。在該層設有信息推送模塊、綜合查詢管理模塊。在綜合查詢管理模塊,將其分為3個子模塊,分別為綜合查詢、統計報表、打印輸出。在信息推送模塊,當用戶在瀏覽圖書館網頁時,該模塊會提取用戶操作記錄的關鍵詞等信息發送到后臺,后臺服務程序在接收到客戶端提供的信息后,向用戶推送與用戶操作記錄相關的信息。信息推送的流程如圖2所示。
數據存儲層用于存儲用戶的操作記錄、瀏覽歷史、圖書館圖書等信息數據,同時,也是數據頁和圖書館推送系統的緩沖區,是將圖書館推送系統中的各類數據統一實行管理的層面,所使用的數據庫是SQL Server? 2005。在該層設有數據庫維護模塊。
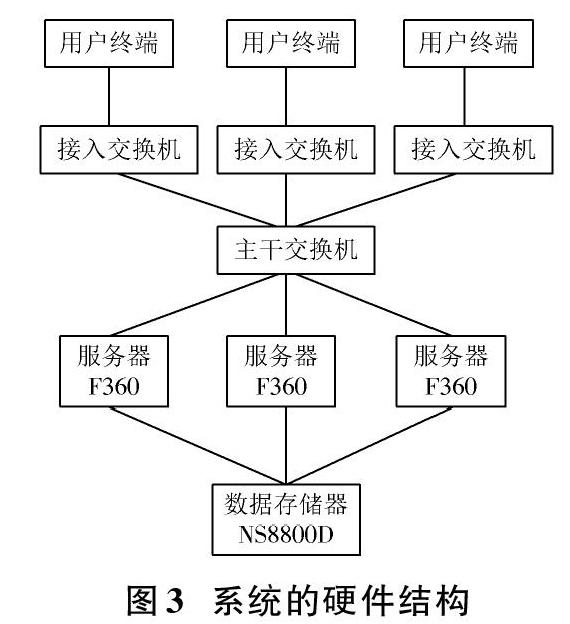
1.2? 基于大數據驅動的智慧圖書館推送系統硬件設計
根據基于大數據驅動的智慧圖書館推送系統的總體架構,設計系統的硬件結構。在智慧圖書館系統中,圖書館存儲器為NS8800D,其中的HDFS具有可擴展和容錯存儲性能,將存儲的文件拆分為多個塊(每個塊的大小為64 MB或128 MB),復制在智慧圖書館推送系統中的多個節點上,因而具有非常大的容錯性。此智慧圖書館推送系統中的HDFS,通過持續監視各個節點,以及各個節點所管理的塊,以確保智慧圖書館推送系統中數據的可用性。各個塊都受到HDFS的檢查和控制,在對系統中的數據以塊的形式讀取后,確定系統中數據的正確性。MapReduce提供了并行計算功能,針對智慧圖書館推送系統中海量的數據,將其通過主節點分配給各個節點,再收集計算結果,以便快速、精確地為用戶提供推送服務[8?9]。
1.3? 基于大數據驅動的智慧圖書館推送系統軟件設計
在硬件設計的基礎上,設計智慧圖書館推送系統的軟件。系統中主要功能模塊如圖4所示。智慧圖書館推送系統的開源軟件選用Apache Hadoop,其支持分布式數據密集型應用程序和MapReduce計算,允許智慧圖書館推送系統對大量數據并行處理。
智慧圖書館數據推送系統的主要目的是在給定時間內,根據用戶的操作記錄等信息,將圖書館信息快速、高效地推送給用戶,以滿足用戶需求。
在為用戶推送相關信息時,先要采集用戶操作記錄的相關信息,要對關鍵詞等文本信息進行統計和分析。利用統計量的大小比較,精準地獲取用戶操作記錄的主要信息。統計量的計算公式如下:
[x2ti,Cj=NAD-CBA+CB+DA+BC+D] (1)
式中:[x2]為統計量;[N]為提取用戶操作記錄的文本個數;[ti]為用戶操作記錄特征;[Cj]為一個類別;[A]為[Cj]中具有特征[ti]的文本個數;[C]是[Cj]中不存在特征[ti]的文本個數;[B]是[Cj]外具有特征[ti]的文本個數;而[D]是[Cj]外不存在特征[ti]的文本個數[10?11]。根據式(1)確定提取的關鍵詞信息。將一條操作記錄看作是一個空間向量[Dt1,w1;t2,w2;…;tn,wn],利用向量之間的夾角[cos θ]值,獲取與用戶操作記錄相似的文本信息,即計算文本相似度[SimD1,D2]:
[SimD1,D2=cos θ]? ? ? ? ?(2)
[cos θ=k=1nw1k·w2kk=1nw21kk=1nw22k]? ? ? ? ? (3)
式中:[D1]和[D2]為相比較的兩個文本信息;[wi]為每個特征對文本內容表示的重要程度;[n]為比較次數[12?14]。通過式(2)和式(3),計算出文本相似度。智慧圖書館推送系統會根據文本相似度,利用MapReduce分析計算用戶信息,再利用爬蟲技術爬取與用戶操作記錄相關的信息,針對用戶需求,為用戶提供智能化推送服務。
綜上,通過硬件和軟件設計,完成基于大數據驅動的智慧圖書館推送系統設計。
2? 實? 驗
為了驗證提出的基于大數據驅動的智能圖書館推送系統能否更快速地為用戶推送信息,將其與傳統的智慧圖書館推送系統進行了對比實驗。
2.1? 實驗過程
利用智慧圖書館推送系統,將推送文章數據量設為100篇、300篇、600篇、1 000篇和1 500篇,針對不同的智慧圖書館推送系統,測試其推送不同數量的文章所需推送時間的多少。
2.2? 實驗結果分析
本文提出的基于大數據驅動的智慧圖書館推送系統與傳統推送系統所需推送時間對比結果如圖5所示。
由圖5可知,在3個智慧圖書館推送系統中,隨著推送文章數量的增加,推送時間都隨之變長。然而,在兩個傳統推送系統中,隨著推送文章數量的增加,推送所需時間增長較多;而本文設計系統隨著推送文章數量的增加,所需推送時間增長的并不多。
通過分析發現,采用大數據驅動的系統隨著數據量的增多,對數據的分析、計算速度越快。因此,與傳統的智慧圖書館推送系統相比,推送同樣數量的文章,本文設計系統所需時間更少,表明其能夠更高效地為用戶提供推送服務。
3? 結? 語
針對傳統智慧圖書館推送系統存在的推送時間長的問題,本文設計基于大數據驅動的智慧圖書館推送系統。采用MapReduce、爬蟲技術等完成硬件和軟件設計,并將所設計系統與傳統的智慧圖書館推送系統進行了對比實驗。實驗結果表明,提出的基于大數據驅動的智慧圖書館推送系統能夠更為高效地為用戶服務。
參考文獻
[1] 陳臣.基于大數據挖掘與知識發現的智慧圖書館構建[J].現代情報,2017,37(8):85?91.
[2] 李欣.強關聯規則挖掘在智慧圖書館個性化推送服務中的應用研究[J].情報科學,2018,36(4):95?99.
[3] 曹樹金,劉慧云,王連喜.大數據驅動的圖書館精準服務研究[J].大學圖書館學報,2019,37(4):54?60.
[4] 常青,楊武健,龔景興.智慧圖書館建設誤區與建設策略[J].圖書情報工作,2018,62(19):13?18.
[5] 張潔,袁輝.智慧圖書館系統支撐下的學科服務實踐[J].圖書館論壇,2017,37(7):27?32.
[6] 許新龍,楊永霞.新一代智慧圖書館信息系統研究[J].國家圖書館學刊,2018,27(6):48?53.
[7] 楊妮.基于“互聯網+”的高校智慧圖書館系統建設的思考[J].湖北函授大學學報,2017,30(9):49?50.
[8] 羅寰.論人工智能時代新一代智慧圖書館系統構建[J].中國中醫藥圖書情報雜志,2019,43(1):1?3.
[9] 胡泰然,曹鵬彬,陳緒兵.基于RFID與XBEE的CIRCLE智慧圖書館的設計與開發[J].微型機與應用,2017,36(14):98?101.
[10] 于成龍.基于移動增強現實技術的圖書館文獻推送系統的設計與實現[J].農業圖書情報學刊,2017,29(2):65?68.
[11] 朱寧.構建智慧圖書館智能服務系統[J].辦公自動化,2017,22(24):51?52.
[12] 高艷麗.大數據驅動的SOC設計平臺IC?ONE[J].中國集成電路,2017,26(9):43?48.
[13] 張潔,汪俊亮,呂佑龍,等.大數據驅動的智能制造[J].中國機械工程,2019,30(2):127?133.
[14] 孫遠芳,段翠華,張培穎.大數據驅動的未來網絡:體系架構與應用場景[J].中國電子科學研究院學報,2017(5):25?30.
