
基于PubMed數據庫的數字圖書館文獻查檢系統設計
2020-10-22 02:11:33曲婧
現代電子技術 2020年20期
曲婧


摘? 要: 現有文獻查檢系統存在準確率低、系統運行能耗高以及耗時長等問題,為此,提出并設計基于PubMed數據庫的數字圖書館文獻查檢系統。采用三層體系結構模式,將系統分為數據層、業務層與應用層。數據層存放從PubMed數據庫中選取的數據,通過PCIe接口支持的通信技術與業務層交互;業務層設置SoC芯片HI3510作為處理器,對用戶需求輸入后形成的查檢條件進行查詢索引處理,通過輸入文獻題目、文獻號、文獻作者等關鍵詞獲取文獻文本,結合Web Service服務查詢本地PubMed數據庫;最終通過應用層的用戶界面顯示文獻查檢結果,完成系統設計。實驗結果表明,該系統的文獻查檢準確率高達到90%,系統運行能耗少,且查檢耗時低。
關鍵詞: 文獻查檢; 數字圖書館; PubMed數據庫; 三層體系結構; 業務層設置; 文獻獲取
中圖分類號: TN919?34; G254.9? ? ? ? ? ? ? ? ? 文獻標識碼: A? ? ? ? ? ? ? ? ? ? ? 文章編號: 1004?373X(2020)20?0112?03
Design of digital library literature search system based on PubMed database
QU Jing
(College of Optical and Electronical Information, Changchun University of Science and Technology, Changchun 130000, China)
Abstract: The existing literature search system has some defects, such as low accuracy, high energy consumption, long time consuming, etc. Therefore, a digital library literature search system based on PubMed database is proposed and designed. The system is divided into data layer, service layer and application layer. The data layer stores the data selected from PubMed database. The communication technology supported by PCIe interface interacts with the service layer. The SOC chip HI3510 taken as processor is adopted in the service layer to query and process the search conditions formed according to user input. The literature text is obtained by inputting literature title, document number, literature author and other keywords, and the local PubMed database is queried in combination with Web Service. The result of the literature query is displayed on the user interface of the application layer. The experimental results show that the accuracy of the literature search system is as high as 90%, its energy consumption is low, and its time consuming is short.
Keywords: document query; digital library; PubMed database; three?tier architecture; business tier setup; document acquisition
0? 引? 言
網絡信息技術的飛速發展為很多傳統領域帶來了新的變革,數字圖書館是建立在信息技術上,利用現代化數字手段以高效有序的信息資源為核心,設計的一種分布式超大規模數字化信息系統[1?2]。文獻是知識內容信息化的集合體,記錄并展示了人類的進步和發展,尤其隨著科學技術的進步,文獻數量大幅度增加,成為數字化圖書館的重要檢索內容之一[3?4]。原始文獻的排列是無序的,要想快速找到用戶需求的信息,就必須尋找到一種非常有效的檢索方式,信息檢索成為數字化圖書館應用的核心技術之一。建立信息檢索平臺能夠為用戶提供高效的檢索手段,幫助用戶快速、準確地實現文獻查檢,滿足用戶需求。由此可以看出,尋找一種高效數字圖書館文獻查檢手段,具有實際應用價值[5]。
黃容等人通過對數值知識元的深入分析,進行數字圖書館數值知識元識別、抽取、索引與檢索,由此建立數字圖書館檢索系統,該系統的數值知識利用效率較高,但運行耗時長[6];李默為尋找一種有效的數字圖書館檢索方法,對移動視覺搜索技術進行了深入分析,融合個性化推薦服務,分析檢索關鍵問題,能夠提供較好的用戶視覺體驗,但該系統運行能耗高[7];李月琳針對游戲化信息檢索系統中用戶的偏好、態度及使用意愿進行分析,采用原型法設計GIRS紙面原型系統,發現用戶最感興趣的元素,最大程度滿足客戶、吸引客戶,但該方法的準確率不足[8];李潔采用文獻計量學分析,為埃博拉病毒研究提供文獻尋找數據依據,采用PubMed檢索文獻,分析埃博拉病毒發展趨勢,檢索效果整體較好,但系統運行準確率還有待提高[9]。
為解決上述研究方法存在的問題,本文提出并設計基于PubMed數據庫的數字圖書館文獻查檢系統。實驗結果表明,該系統的文獻查檢準確率較高,系統運行能耗低,且運行耗時少。
1? 系統整體架構
PubMed數據庫是美國國家醫學圖書館下屬信息中開發的醫學文本數據庫,是公共數據查檢平臺,被廣泛應用于研究中[10]。PubMed數據庫包含2種記錄模式:一是MEDLINE記錄,使用主題詞作為關鍵詞進行信息查檢;二是PREMEDLINE記錄,用于臨時存儲未進行標記的文本數據,當操作者標記文本后,文本資料自動轉移至MEDLINE數據庫,靈活性較好。
本文從PubMed數據庫中選取文獻數據集作為研究對象,采用三層體系結構模式設計數字圖書館文獻查檢系統。三層體系結構模式層次明了,方便程序移動,具有較好的實際應用價值,能很好地滿足系統設計需求。本文設計的系統架構如圖1所示。
在圖1所示的數字圖書館文獻查檢系統架構中,應用層與數據層不直接聯系,通常將業務規則、數據處理等步驟設置在業務層,應用層與業務層通過通信技術連接,再由業務層與數據層通信、交互。這樣能夠有效緩解數據量或者用戶訪問量激增情況下系統的負載,較好地保護服務器[11]。
系統設計中,應用層設置用戶界面,負責用戶信息的輸入和接收系統反饋信息。業務層負責訪問數據庫,設計文獻查檢步驟,計算、更新數據等,并反饋計算結果至用戶界面端。數據層主要存放從PubMed數據庫中選取的對象數據集。
2? 系統硬件設計
2.1? PCIe接口設計
根據系統設計架構可知,應用層與業務層、業務層與數據層之間的連接均需依據通信技術開展,那么通信中必定需要使用計算機接口。因PCIe接口適用于較高數據量的計算機通信,因此本系統采用PCIe接口進行通信設計[12]。給出PCIe卡板電路框圖如圖2所示。
2.2? 處理器設計
處理器是決定系統運行性能好壞的關鍵,根據本系統的實際查檢需求,選取SoC芯片HI3510作為處理器。HI3510是一款集成圖像處理器、編碼器,能夠在滿足系統性能要求的條件下,最大程度降低系統硬件設計的復雜度,且在600 mW基礎功耗的前提下,配置多級節能模式,降低系統能量消耗。
HI3510芯片主要負責完成系統控制,數據壓縮編碼以及網絡數據傳輸等。通過設置HI3510芯片的對應通信接口,可以完成芯片內各模塊的初始化工作,幫助后續系統準確運行。
3? 系統軟件設計
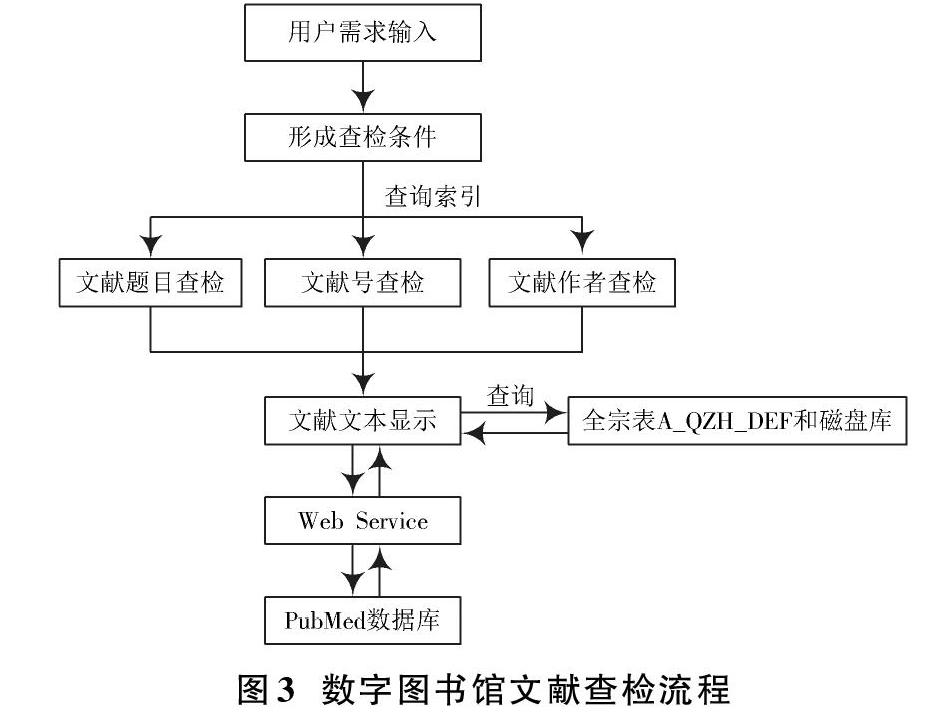
在硬件條件的支持下,按照三層體系結構模式設計系統軟件流程,按照用戶需求輸入、形成查檢條件,通過查檢條件分類及計算機處理進行數字圖書館文獻檢查,實現查檢結果。數字圖書館文獻查檢流程如圖3所示。
由圖3可知,用戶發送文獻查檢需求命令后,系統應用層發送通信信息至業務層,形成查檢條件,利用HI3510芯片,通過輸入文獻題目、文獻號、文獻作者等關鍵詞,查詢得到相關文獻,顯示文獻文本。這時根據顯示得到的文件查詢全宗表A_QZH_DEF和磁盤庫,獲取文本文件的服務路徑和存儲地址,再通過調用Web Service服務,依據服務路徑和存儲地址查詢本地PubMed數據庫,返回用戶界面顯示文獻,結束數字圖書館文獻查檢。
4? 實驗結果與分析
為驗證本文設計系統的性能,進行實驗分析,本實驗采用.NET框架建立并運行Web Service服務,并運行多種語言環境。.NET框架中,所有編程語言都可以“一次編程,隨處運行”,創建各種語言應用程序,同時容納不同語言存在。本實驗開展實驗環境如表1所示。
實驗數據選用PubMed數據庫中10萬個數據,其中5萬個數據用于訓練樣本,另外5萬個數據用作測試數據。在上述實驗環境和數據設置下,給出以下指標:查檢準確率、系統運行能耗、查檢耗時。通過與傳統系統對比,驗證本文系統的有效性。
將本文系統與文獻[6]、文獻[7]系統的查檢準確率進行對比,結果如圖4所示。
由圖4得,在剛開始測試時,本文系統的查檢準確率為75%,隨著測試數據量的增加,準確率逐漸增加到90%且趨于平穩。文獻[6]和文獻[7]系統的查檢準確率先上升后下降,文獻[6]最高達到60%,文獻[7]最高達到80%。由此可見,本文系統的查檢準確率明顯高于文獻[6]、文獻[7]系統,且系統測試過程平穩,穩定性較強。
以系統運行能耗為指標,對比本文系統與文獻[6]、文獻[7]系統,結果如圖5所示。
分析圖5可知,本文系統的運行能耗在30 J以下,文獻[6]系統運行能耗可達到60 J,文獻[7]系統運行能耗可達到75 J。從圖中可看出,本文系統,能具有明顯的優勢,這是因為本文系統設計中,硬件部分選取SoC芯片HI3510作為處理器,采用多級節能模式運行,大大降低了系統運行能耗。
將本文系統與文獻[6]、文獻[7]系統的查檢耗時進行對比,結果如表2所示。
分析表2可以看出,本文系統的查檢耗時在10~15 s之間,平均耗時為12.6 s;文獻[6]系統的查檢耗時在20~26 s之間,平均耗時為24.0 s;文獻[7]系統的查檢耗時在23~35 s之間,平均耗時為28.4 s。根據數據分析可以看出,本文系統查檢耗時最低,優于其他文獻,主要是因為本文系統設計中,采用三層體系架構,層次明了,靈活性較好,可最大程度滿足用戶需求,避免無效運行,節省系統運行耗時。
5? 結? 論
數字圖書館文獻查檢是目前被廣泛使用的一種技術,查檢系統的好壞直接影響圖書館電子用戶體驗。本文提出并設計基于PubMed數據庫的數字圖書館文獻查檢系統,采用3層體系結構模式將系統分為數據層、業務層和應用層。硬件部分主要對PCIe接口處理器HI3510進行了分析,軟件部分給出了數字圖書館文獻查檢系統流程。實驗結果表明,本文設計系統具有較好的查檢性能,優于傳統方法。
參考文獻
[1] 孫雨生,李萬蓉,郝麗靜.國內數字圖書館信息可視化應用進展[J].計算機與數字工程,2019,47(1):140?145.
[2] 盛先鋒.基于聚類優化的數字圖書館協同過濾個性化推薦服務研究[J].中國中醫藥圖書情報雜志,2019,43(3):37?40.
[3] 藍燕,曾樹洪.數字圖書館網絡及服務方案設計[J].現代計算機(專業版),2017(16):88?91.
[4] 高興輝.數字圖書館分類文獻數據關聯規則提醒系統設計[J].電子設計工程,2019,27(13):66?69.
[5] 谷參.基于分布式結構的圖書館信息檢索服務系統研究[J].現代電子技術,2017,40(1):83?85.
[6] 黃容,何楊煜琪,王忠義,等.數字圖書館數值知識元檢索系統設計[J].圖書情報工作,2018,62(14):125?132.
[7] 李默.數字圖書館個性化移動視覺搜索機制研究[J].圖書館理論與實踐,2019(2):107?112.
[8] 李月琳,何鵬飛.游戲化信息檢索系統用戶研究:游戲元素偏好、態度及使用意愿[J].中國圖書館學報,2019,45(3):62?78.
[9] 李潔,武桂珍.基于GoPubMed對埃博拉病毒研究文獻的數據分析[J].病毒學報,2018,34(4):565?569.
[10] 李彩,杜冰,徐虹,等.我國中文醫學期刊在PubMed數據庫中的收錄及數據展示分析[J].中國科技期刊研究,2018,29(7):728?732.
[11] 賈賀,艾中良,賈高峰,等.基于Solr的司法大數據檢索模型研究與實現[J].計算機工程與應用,2017,53(20):249?253.
[12] 馬佳立.面向大數據的數字圖書館移動視覺搜索機制及應用[J].自動化技術與應用,2019,38(5):179?182.
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
小太陽畫報(2018年1期)2018-05-14 17:19:25
家庭影院技術(2017年9期)2017-09-26 03:41:45
財經(2017年2期)2017-03-10 14:35:35
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
