面向多部門多屬性的群決策應急方案調整方法
2020-10-24 02:15:18王應明
運籌與管理 2020年2期
鄭 晶, 王應明
(1.福建江夏學院 電子信息科學學院,福建 福州 350108; 2.福州大學 決策科學研究所,福建 福州 350116)
0 引言
近年來,各式各樣的突發事件頻頻發生,對生命安全和經濟方面造成了很大的損失,給社會帶來了嚴重的負面影響,例如,地震、馬航事件、臺風、恐怖襲擊等事件。當突發事件發生時,決策者面臨著時間緊迫和信息有限的壓力,如何快速生成應急方案來降低經濟損失,減少人員傷亡,是應急管理部門亟待解決的難題之一[1]。
目前,有關應急方案生成方法的研究已經引起了國內外學者的關注[2~4]。例如,Fan等[2]應用案例推理(Case-based Reasoning, CBR)對S城市的地鐵項目做出應急響應;封超等[3]提出一種基于CBR考慮屬性權重影響的應急方案生成方法,并應用于臺風應對中;Yu等[4]提出應用CBR解決面對自然災害時城市供水網絡的應急響應問題。可以看出,已有這些研究大多是基于CBR的應急決策方法,通過檢索方法搜索與當前突發事件相似的歷史案例來生成解決方案。但是,直接運用相似歷史案例的應急方案有可能存在應急效果不佳的情形,往往需要對應急方案進行調整來適應當前突發事件[5],因此如何對方案進行調整是一個具有實際意義的研究課題。方案調整主要有兩種,一是通過統計方法進行調整,例如,基于距離[6]或者相似度[7]的方案調整方法;另一種是通過機器學習方法進行調整,例如,Zhang等[8]通過遺傳算法對方案進行調整;Qi等[9]應用支持向量機對方案進行調整;Butdee等[10]采用神經網絡來進行方案調整。統計調整方法對于數據量的要求低于機器學習方法,但是機器學習方法的精確度相對較高,同時也需要付出一定的計算代價。在機器學習方法中,支持向量機方法、神經網絡方法和遺傳算法均是黑箱學習過程且需要制定參數[5]。特別需要指出的是,目前的方案調整方法都是只針對單個個體進行調整。
已有的研究為方案調整提供了理論與方法的支持,但突發事件具有突發性、危害性等特征,數據具有模糊性,且需要多個部門共同決策生成合適的應急方案,目前的方案調整方法無法解決群決策環境下的問題。鑒于此,本文將群決策和置信規則庫引入到方案調整中,解決突發事件下多部門多屬性的群決策應急方案調整問題。
1 置信規則庫推理方法
Yang等[11]在2006年提出的置信規則庫推理算法(rule-base inference methodology using the evidential reasoning, RIMER),以擴展的IF-THEN規則作為知識庫,以證據推理(Evidence Reasoning, ER)作為推理機,因此,能在不確定信息情形下,用簡單的推理機制得到理想的結果,并已成功應用于不確定推理等領域[12,13]。RIMER主要包括兩個方面:一是通過置信規則庫(belief rule base, BRB)的知識表示;二是基于BRB的推理機制。下面給出簡單的介紹。
1.1 BRB的知識表示
BRB是由一系列的置信規則構成的,其中第k條規則Rk的描述如下:
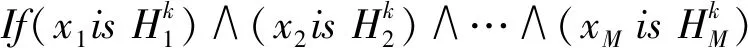
then{(D1,β1,k),(D2,β2,k),…,(Dn,βn,k)}
(1)
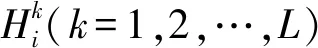
此外,第k條規則的權重為θk,表示該規則相對于其他規則的重要性;第k條規則中前置屬性xi的權重為δi,k。
1.2 BRB的推理機制
BRB的推理機制包含兩個步驟,先計算激活權重,再應用ER進行合成。BRB的推理步驟如下:
首先,根據屬性權重δi,k和規則權重θk計算第k條規則的激活權重,計算公式如下:
(2)
(3)
然后,應用ER對所有激活的規則進行合成。下面給出ER的合成過程。
在ER算法中,通過屬性的置信度βj,k和屬性權重wk得到基本信度分布,計算公式為:
mj,k=wkβj,k
(4)
(5)
(6)
(7)
接下來,應用Wang等[14]提出的解析方法進行合成,合成公式為:
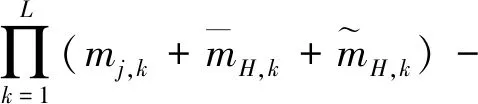
(8)
(9)
(10)

(11)
(12)
(13)
其中,βj表示在結論的評價等級Dj上的置信度,βH表示不確定甚至無知信息的置信度。
2 面向多部門多屬性的基于置信規則庫的群決策應急方案調整方法
2.1 問題描述
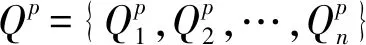
本文要解決的問題是,根據各部門根據自身關注的指標集合Gq,目標案例信息(P0,S0),歷史案例庫(Pa,Sa)及各部門對生成的所有應急方案的評價信息R,如何運用一個可行的決策分析方法調整各部門生成的應急方案并集結為最終的應急方案,為當前的突發事件提供有力的支持。
2.2 部門中應急方案調整方法
為了解決部門中應急方案調整問題,這里提出一種基于BRB的應急方案調整方法。如圖1所示,該方法主要包括計算部門中目標案例與歷史案例的相似度,通過BRB中的參數訓練學習確定規則庫,以及部門中應急方案生成等步驟。
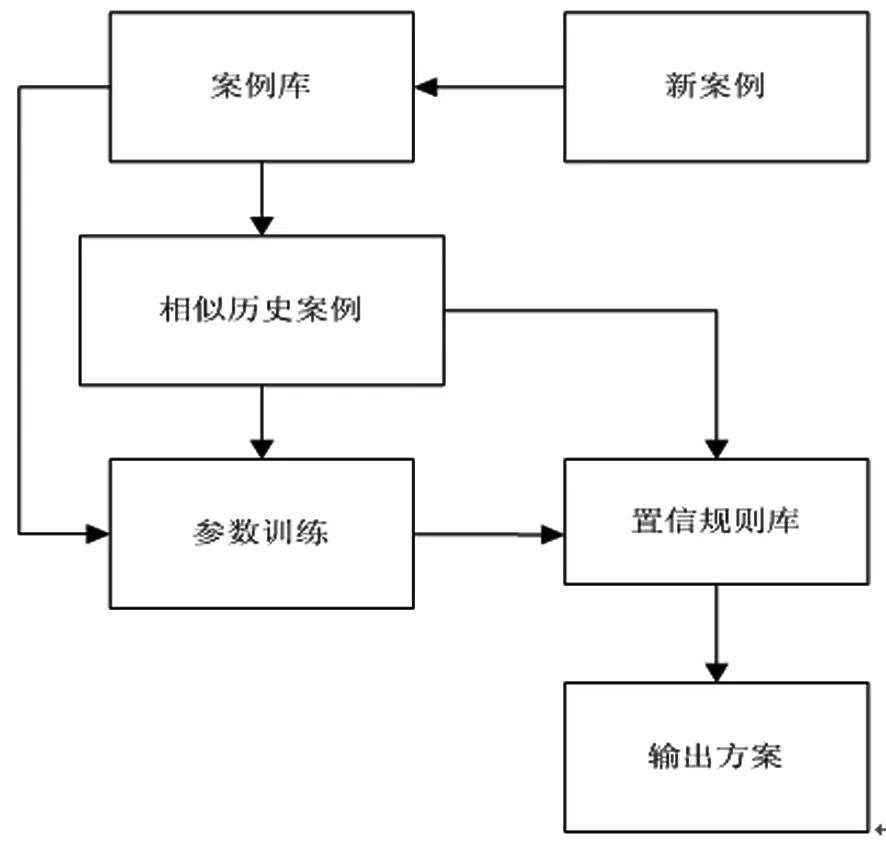
圖1 基于置信規則庫的部門中應急方案調整框架
下面分別闡述所提方法的每個部分的計算過程。
2.2.1 計算部門中目標案例與歷史案例的相似度
突發事件具有不確定性、突發性等特點,案例屬性的表示往往包括定性和定量多種形式,文獻[15]對此做出了較為詳細的研究,并給出了有效的相似度計算方法。本文只考慮問題屬性為數值型的情形,其它數據類型可參考文獻[15]。首先,計算目標案例與歷史案例間的距離d(xab,x0b),計算公式如下:
(14)
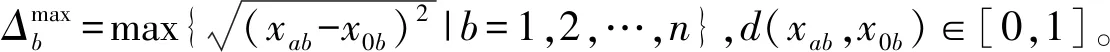
進一步地,計算目標案例與歷史案例的屬性相似度s(xab,x0b),計算公式如下
s(xab,x0b)=exp[-d(xab,x0b)]
(15)
(16)
(17)
最后,計算目標案例與歷史案例的相似度sa,計算公式如下:
(18)
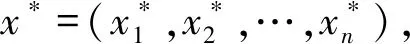
2.2.2 部門中BRB的學習
在案例調整過程中,通過BRB表示問題Pa和解決方案Sa之間的因果關系,因此,將門中最相似歷史案例與案例庫中其他歷史案例的屬性差異值作為前置條件,將其他歷史案例的解決方案作為問題的解。在此基礎上,運用案例庫的信息學習BRB系統中的參數(θk,δi,k,βj,k)以此來改善系統的推理能力[20]。下面給出BRB參數學習的步驟。
Step1計算部門中最相似歷史案例與案例庫中其他歷史案例的屬性差異值Δxab,并作為BRB的前置條件,計算公式如下:
(19)
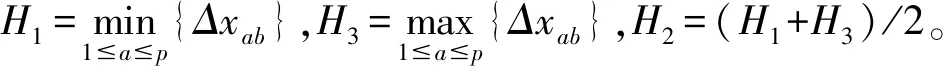
Step3根據文獻[21]的信息轉換技術,將屬性相似度的差異值Δxab轉換為置信度形式{(Ht,b,αt,b)|t=1,2,3},轉換公式如下:
(20)
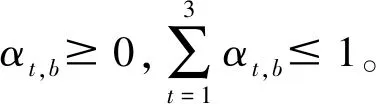
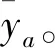
(21)
(22)
(23)
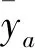
(24)
(29)
其中,式(24)為目標函數,其含義是最小化推理輸出值與實際值之間的差異;式(25)和式(26)是每條置信規則結論的限制;式(27)和式(28)是屬性權重的限制;式(29)是規則權重的限制。
2.2.3 部門中應急方案的生成
在確定BRB基礎上,通過BRB的推理機制來獲取目標案例的方案,其具體步驟如下:
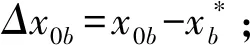
Step2根據式(20)將Δx0b轉換為置信度形式;
Step3根據式(2)和(3)計算激活權重wk;
Step4根據式(4)~(13)對激活的規則進行融合,得到解決方案的置信度{β1,β2,…,βN}。如果解決方案的值為區間數,則根據式(21)和(22)將置信度轉換為區間數;再根據式(23)轉換為精確數。
2.3 最終應急方案的生成
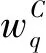
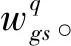
(30)
(31)
(32)
Step2對多部門多屬性的評價進行集結,集結公式如下:
(33)
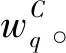
(34)
(35)
(36)
在此基礎上,通過線性加權法對各部門生成的應急方案進行集結得到最終的應急方案,集結公式如下:
(37)
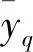
3 算例分析
3.1 液體泄漏應急案例分析
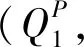
Step1根據3個部門所關注的問題屬性及其案例庫信息,依據式(14)~(18)計算得到最相似的歷史案例分別為(P28,S28)、(P29,S29)和(P21,S21)。
Step2根據式(19)計算各部門歷史案例(Pa,Sa)與最相似歷史案例(P*,S*)之間的屬性差異值Δxab;
Step3設置問題屬性差異值與方案屬性的評價等級,即{H1,H2,H3}和{D1,D2,D3};再根據式(20),將屬性差異值與方案屬性轉換為置信度分布形式;
Step4根據式(24)~(29)來學習各部門BRB的參數(θk,δi,k,βj,k),以此來確定各部門學習后的BRB;
Step5依據式(20)計算各部門目標案例(P30,S30)與最相似歷史案例(P*,S*)之間的屬性差異值Δx30b,并依據式(20)轉換為置信度分布形式;再依據式(2)~(13)進行推理得到各部門應急方案的置信度形式;在此基礎上,依據式(21)~(22)得到3個部門的解決方案,分別為[73,74.7],[73,74.4],[70.1,73.2]。
Step6三個部門對3個應急方案針對救援時間、救援花費和傷亡降低率進行評價,評價信息如下:

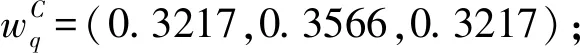
3.2 結果分析
為了說明本文方法的有效性,下面給出本文方法與其他方法的性能比較。
首先,為驗證通過應急方案的調整,將會提高應急方案的有效性,將3個部門通過相似度計算方法得到最相似歷史案例的應急方案與通過BRB調整后得到的結果進行比較,其結果如表1所示。
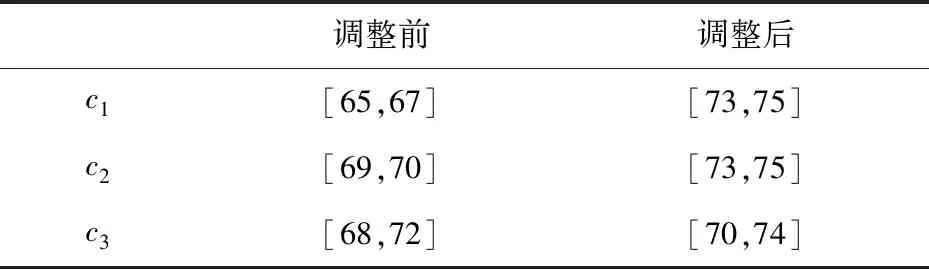
表1 應急方案調整前后結果對比
從案例庫信息可知,目標案例(P30,S30)所采用的實際應急方案為[70,75]。從表1可知,沒有進行應急方案調整前的方案與實際采用的應急方案的偏差大于調整后的方案。為了說明調整前后的偏差,引入均方差(mean squared error, MSE)的概念來比較計算方案值與實際值的偏差,其計算公式如下:
(38)
其中,yq為各個部門得到的應急方案,y0為目標案例的應急方案。
根據式(38),計算得到應急方案調整前得到的MSE為22.333%,而調整后的MSE為2%,相對縮小了20.333%,因此,通過基于BRB的應急方案調整,使生成的方案更加有效。
接著,將基于BRB調整的結果和基于BRB的群決策調整結果。從文獻[5]可知,由BRB調整的結果為[72,76],而通過本文提出的基于群決策的調整方法的結果為[72,75]。為了更好地定量分析兩個結果的準確性,根據區間數的歐式距離,得到基于BRB調整的目標案例的方案與實際方案之間的距離為2.2361,而由文本方法得到的方案值與實際值之間的距離為2,因此本文提出的方法的準確度更高一些。
進一步地,將基于平均權重得到的應急方案及其根據文獻[24]的方法融合多部門應急方案的結果與本文的結果進行比較。由平均權重得到的應急方案為[73,75],由文獻[24]得到的融合結果為[73,75],通過本文方法得到的結果為[72,75]。根據區間數的歐式距離,三種方法得到的結果與實際值之間的距離分別為3,3,2,因此本文提出的多部門應急方案集結的方法準確度更高。
最后,將每個部分調整后的結果與群決策的結果進行比較。部門c3得到的應急方案與實際方案的差距較大,存在無法很好控制突發事件的可能性。部門c1和c2調整得到的應急方案值為[73,75],其下界略大于實際情況[70,75],可以控制突發事件,但是存在一定的浪費,而通過群決策將得到的結果為[72,75],與實際情況更接近,因此,群決策下的應急方案調整不僅符合實際應急決策的情形,也使得結果更加精確。
4 結束語
針對應急決策過程需要多部門參與及關注屬性不同的問題,本文提出一種面向多部門多屬性的群決策應急方案調整方法。本文首先運用CBR的檢索方法搜索到各部門與目標案例最相似的歷史案例,然后運用BRB對各部門最相似的歷史案例進行調整,最后通過基于距離的權重賦權法對各部門的應急方案進行集結得到最終的應急方案。該方法具有以下特點:①通過BRB對應急方案進行調整,不僅可以提高應急方案的準確度,而且可以處理模糊情形下的案例信息;②在應急決策過程中,考慮到多部門參與及關注屬性不同的特點,使得決策更加符合實際情形;③通過基于距離/相似度的權重對部門意見進行集結,不需要部門之間進行過多地討論與協商,使得群體意見可以在短時間內達成一致,提高應急響應時間。
本文所提方法不僅適用于突發事件,也適用于經濟管理、工業生產等應用領域中多部門參與的方案生成問題,當然也存在一些問題有待于研究,比如各部門在決策過程中存在心理行為。
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
少先隊活動(2021年2期)2021-03-29 05:40:48
中學生數理化(高中版.高二數學)(2019年6期)2019-06-24 03:37:50
Coco薇(2017年11期)2018-01-03 20:59:57
中國公路(2017年7期)2017-07-24 13:56:38
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
Coco薇(2016年2期)2016-03-22 02:42:52
中國衛生(2015年4期)2015-11-08 11:16:06
Coco薇(2015年1期)2015-08-13 02:47:34
