數據處理技術在互聯網推薦場景中的應用
2020-11-05 09:51:46董雪鵬
科學技術創新 2020年32期
董雪鵬
(南京電子器件研究所,江蘇 南京210016)
在互聯網社會,每個人的線上生活都在不斷產生相應的數據,這些數據就是互聯網社會最寶貴的資源。當前互聯網公司的許多商業模式都是基于這些數據實現的。通過對互聯網用戶行為數據的處理,可以分析用戶的使用習慣,不同類別用戶的興趣特征,從而為不同用戶推送不同的內容,提升用戶使用體驗,提升應用日活用戶數量,進而提升應用商業化指標。數據處理技術在內容推薦場景的應用隨著業務場景的需求,處理技術的發展以及沉淀數據質量的提升可以分為三個方面:離線批處理,分布式流計算和深度數據挖掘。
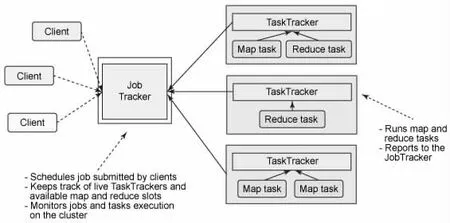
圖1 MapReduce 結構圖

圖2 流式計算過程示意圖
1 離線批處理技術
互聯網上每天都在產生很多的數據,為了將最新的數據及時準確地送到每個用戶的眼前,需要每天對這些數據進行分析計算。比如某個線上商店新上架了一批新的熱門商品,那么電商平臺需要及時將這批商品推薦到潛在客戶的應用程序上。這里就需要進行推薦算法的計算,而且需要定期根據最新的數據進行推薦結果更新。這里存著一個核心計算問題,計算成本。
在數據量達到一定規模后,所有的計算成本都會呈指數級增長,包括內存、CPU 和時間。為了在有限的時間內盡可能快地完成計算任務(保證上架商品盡可能快地呈現到用戶面前),需要將更多的算力聯合成集群使用。同樣是由谷歌公司發表的論文“MapReduce”提供了一種解決分布式計算問題的思路,對應的開源解決方案是Hadoop 中的MapReduce 模塊(見圖1)。
MapReduce 幫助數據分析人員將存儲在分布式存儲上的海量數據分散到不同的服務器上進行并行計算,最終再將分散的計算結果進行合并得到最新的數據分析結果[1]。因為這種計算往往是面向一定規模的存量數據的,即先將數據存儲到硬盤上,當數據累積到一定的規模后再進行批量分析,因此也稱為離線批處理計算。
但是有些場景下這種計算模式是不能夠滿足我們的業務需求的。比如在導航地圖中,用戶痛點是希望知道當前道路的實時路況,如果間隔一段時間才能得到分析結果,這種體驗將會是非常糟糕的。此時數據分析的主要矛盾是計算的實效性問題,需要有一種快速的數據分析技術來支撐這種業務場景[2]。
2 分布式流計算
為了能夠提高數據分析的效率,降低數據分析時延,發展出了流計算模式[3]。流計算相比較批處理技術的核心優化點有兩個:
(1)純內存操作,節約了數據存入磁盤再進行讀取的成本。
(2)將計算分為很多小的鏈式操作,充分利用計算的流水線效應提高了計算吞吐能力。
流式計算開源的解決方案有很多,當前業界最流行的解決方案是Apache 基金會開源的Flink 實現(如圖2)。
流計算過程中,數據像流水線一樣闖過由Operator 組成的處理鏈條,整個數據集的平均吞吐延時約等于Operator 中耗時最長節點的延時[4]。
3 深度數據挖掘
隨著批處理和流處理場景的落地,這些大數據處理技術滿足了各種用戶最基本的需求,但是互聯網沉淀的數據資源的價值還遠遠沒有被挖掘出來。為了滿足不同用戶個性化的需求,實現千人千面的業務價值,需要引入一些更高階的計算模式,這就是深度學習技術[5]。
深度學習技術的應用是工程、算法和商業模式在一個合適的時間點發生碰撞的結果,通過前面的工程積累,生產上基本解決了大規模復雜計算的問題。此外,2010 年之后深度學習算法的飛速發展也為商業應用提供了強有力的理論支撐,還有多年來各個應用場景沉淀下來的海量的優質標定數據,也為技術的商業化應用提供了保障。在這樣一個特定的時間點,數據,算法和工程碰撞在一起成就了數據挖掘的成功應用。
4 結論
大數據技術在互聯網領域的成功應用有著清晰的發展脈絡。本質上由于互聯網的普及造成了海量數據噴發,而實際生產的需要推動了工程和算法各個方面協同發展,最終達到完美的融合,實現了商業上的成功。這一發展過程,在其他行業引入大數據技術進行生產時,值得充分借鑒。
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
電力與能源(2017年6期)2017-05-14 06:19:37
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
信息通信技術(2015年6期)2015-12-26 01:16:46
