一種立體視覺的障礙物檢測的細化方法
2020-11-06 14:46:58林堅王力虎潘福東劉奎郁凡
現代信息科技 2020年12期
林堅 王力虎 潘福東 劉奎 郁凡


摘 ?要:在立體視覺的障礙物檢測過程中,由于室內地面的紋理特征較弱,使得檢測的障礙物區域包含了較大的地面干擾,獲得障礙物目標位置并不理想,該文使用了一種新的細化方法,改善了目標檢測精度。該算法基于雙目視覺獲得深度信息,采用深度圖像分割法提取出目標的粗略區域;然后結合其Canny邊緣坐標信息對障礙物區域進行細化,進而得到準確的障礙物位置信息。實驗結果表明了該方法具有較強的自適應性。
關鍵詞:障礙物檢測;立體視覺;圖像分割;Canny邊緣;細化
中圖分類號:TP23;TP391.41 ? ? ?文獻標識碼:A 文章編號:2096-4706(2020)12-0070-03
Abstract:In the obstacle detection process of stereo vision,due to the low texture of the indoor ground,the detected obstacle area contains a large ground interference,and obtaining the target position of the obstacle is not ideal. This paper uses a new refinement method,improved target detection accuracy. The algorithm obtains depth information based on binocular vision,and uses the depth image segmentation method to extract the rough area of the target;then combines the Canny edge coordinate information to refine the obstacle area to obtain accurate obstacle position information. Experimental results show that this method has strong adaptability.
Keywords:obstacle detection;stereo vision;image segmentation;Canny edge;refine
0 ?引 ?言
隨著智能機器人技術的興起,越來越多的移動機器人被應用于環境檢測、自主導航、安防等領域[1]。意味著機器人需要具有更強的感知能力能來應對不同環境,因此如何提高機器人對障礙物檢測的精度成了一個重要研究方向。由于立體視覺具有信息豐富、準確度高、效率高、使用方便等特點,被廣泛應用于機器人的障礙物目標實時檢測[2]。為了獲得更加精確的障礙物空間位置和尺寸信息,本文提出了一種改進的立體視覺的障礙物檢測方法。
近幾年來,在基于視覺的障礙物檢測方法中,基于深度學習的目標檢測方法得到較為廣泛的應用,張舜[3]等利用深度學習實現場景中目標的檢測,該方法依賴先驗的訓練數據,不適用于要求實時性的場合。王軍華[4]等采用基于改進RANSAC的雙目障礙物檢測算法,通過提取的地平面模型對障礙物進行分割。吳宗勝[5]等利用立體視覺并結合超像素技術對道路上的障礙物進行概率檢測,主要是通過建立地面模型并評估三維空間點到地面的距離,得到障礙物的概率信息,進而實現障礙物和地面分離。這兩位學者通過建立地面模型對障礙物進行分割,取得了較好的結果。但是對于一些特殊情況,如一些室內弱紋理的地面,立體視覺獲取的深度信息存在較大誤差,其所建立的地面模型并不準確,無法很好地得出障礙物檢測結果。針對這一問題,本文通過結合立體視覺和邊緣信息的障礙物檢測方法,實現障礙物輪廓區域的精細化,克服誤匹配的影響。
1 ?相關工作
針對上述問題,利用障礙物具有較強的紋理特征,而地面的紋理特征較弱這一特性,可通過結合圖像的邊緣坐標點信息,從而得到更加準確的障礙物信息。本文的主要工作為;首先采用雙目相機采集并校正左右兩幅圖像,然后通過立體匹配計算得到場景中物體的視差圖;最后根據深度信息進行圖像分割,并在使用輪廓檢測法提取障礙物大致輪廓區域基礎上,結合Canny邊緣檢測算法計算其邊緣的坐標信息,實現障礙物輪廓由粗到精的檢測。下文對障礙物檢測所涉及的基本原理進行介紹。
1.1 ?雙目立體視覺測量原理
雙目視覺成像模型如圖1所示,根據空間點在左右相機的視差原理可測量出雙目相機到被測物體的距離信息[6],以及更加精確的障礙物空間位置和尺寸信息,從而得到準確的障礙物位置信息。
若世界坐標空間中的任意點A(X,Y,Z)過光軸在左右相機成像平面的像點坐標分別為(ul,vl)和(ur,vr),當兩像點對應的極線el和er處于一條直線上時,記d=ul-ur,根據三角形相似性,可求左相機成像平面像素點與空間點A的關系:
其中,f為焦距,b為基線,d表示空間點在左右相機平面上像點的視差。若給定左相機平面上的一點和與之對應有且只有一個的對應點,則容易得出該點在相機成像平面的坐標,進而可以確定該點在三維世界坐標系上的坐標。在雙目立體視覺視差測量過程中,需要得到左右相機中像素點的匹配關系,本文采用的立體匹配算法為半全局塊匹配算法(Semi-Global Block Matching,SGBM),該算法結合了局部立體匹配算法和全局立體匹配算法的優點,具有視差效果好并且速度快的特點,在計算機視覺中得到廣泛應用。為了提高匹配算法的效率,需要對采集的圖像進行校正,該方法實現左右兩幅圖像中待匹配的像素點在極線方向上對齊,將兩幅圖像的立體匹配時從二維搜索降為一維搜索,有效地降低匹配算法搜索的復雜度。
1.2 ?邊緣檢測
在計算機視覺中,圖像邊緣特征包含了圖像的重要信息,廣泛應用于目標檢測、特征提取、圖像增強等計算機圖像處理,常用邊緣檢測方法有Sobel、Prewitt、LOG、Canny等方法。不同的邊緣檢測方法各具特點,在這些邊緣檢測方法中,Canny[7]邊緣檢測算法表現更為出色,是一種簡單、準確、高效的邊緣檢測方法,所以本文主要使用Canny邊緣檢測算法實現場景物體的邊緣檢測。其步驟主要分成四步。
(1)通過構建一個高斯核對圖像進行卷積操作,實現圖像模糊處理,降低圖像噪聲。
(2)圖像像素點的梯度強度和方向計算,梯度強度越大,邊緣越明顯。設水平梯度為Gx,垂直梯度為Gy,則每個像素點的梯度強度G和方向θ表達為:
(3)非極大值抑制。這一步主要是保留梯度強度局部最大值的邊緣像素點,剔除大部分非邊緣像素點,得到細化后的邊緣。
(4)滯后閾值法求解圖像邊緣。通過設定Canny邊緣檢測算法高閾值和低閾值兩個閾值,將大于高閾值的邊緣定義為強邊緣,屬于有效邊緣,將兩閾值之間的邊緣定義為弱邊緣,當弱邊緣連接了強邊緣才屬于有效邊緣,小于低閾值則被排除。
1.3 ?障礙物檢測
在障礙物檢測過程中,我們通常認為距離相機較近的物體為障礙物,所以可以通過自適應閾值方法對視差圖進行二值化處理,則通過選取視差圖的均值作為閾值,進而得到二值圖像。
為了降低由于噪聲、遮擋等因素的影響,這里通過形態學方法對二值圖像進行開運算處理,消除面積較小的連通區域。經過形態學處理后的圖像進行輪廓檢測法可獲得障礙物所在的區域。
由于輪廓檢測法獲得的障礙物區域包含大量干擾成分,所以需要對其進行細化,以便得到更加準確的障礙物輪廓矩形區域信息。于是,在此基礎上,通過求取障礙物區域邊緣像素坐標點的外輪廓矩形,則可擬合出障礙物最小邊框。障礙物區域的細化過程如圖2所示,其中,星型物體表示障礙物,圓點表示障礙物的邊緣坐標點。
2 ?實驗與討論
實驗中計算機平臺為i5-7500處理器,8 GB內存,軟件平臺為Python3與OpenCV,雙目攝像機平臺采用全瑞視訊200萬像素的USB高清雙目攝像頭模塊。通過相機標定和圖像校正得到圖像分辨率為598×322 pixel。相機標定的參數有基線為60 mm,焦距為640 mm,測量深度范圍為500~3 000 mm。
圖3是采用雙目視覺方式實現的障礙物檢測的細化結果,其中圖3(a)為拍攝的室內真實場景中的左視圖,圖3(b)為立體匹配計算得到的視差圖,并經過上色處理的偽彩色圖,圖3(c)為自適應閾值處理后的二值圖像,圖3(d)為細化后進行擬合的輪廓圖。可以看出,根據視差圖通過閾值法分割提取得到障礙物區域存在較大誤差,而經過細化后的障礙物區域,只保留了障礙物輪廓特征,大大降低了地面對障礙物檢測的干擾。
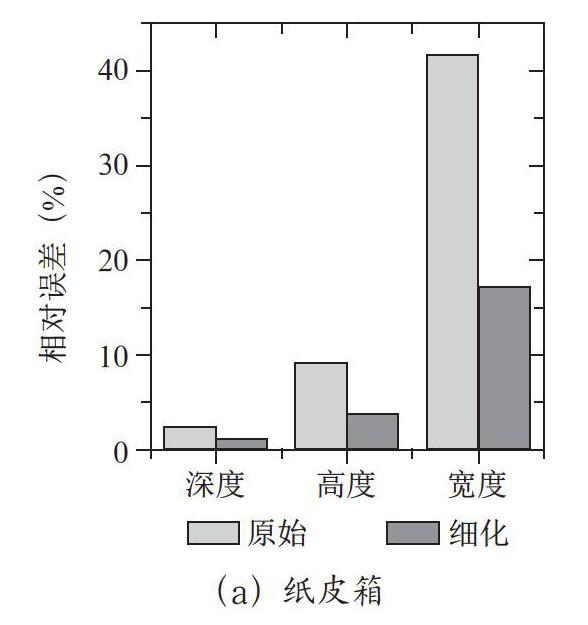
以真實場景中的紙皮箱和木凳作為障礙物,對比原始和細化后的相對誤差,其結果如圖4所示,其縱坐標分別表示深度、高度和寬度的測量相對誤差值。可以看出經過細化后相對誤差有較大幅度的下降,以寬度的最為明顯,最大降幅可達75%,并且深度和高度的測量在細化后相對誤差均在5%以下。
在時間復雜度方面,通過反復多次測量統計,算法平均總耗時為65 ms,基本上達到15幀每秒,滿足系統的實時性,實驗結果表明了該方法具有較強的自適應性。
3 ?結 ?論
本文是基于校內某項目的研究成果,結合立體視覺和邊緣信息的實現障礙物檢測,為機器人的避障提供較好的障礙物數據支撐。通過對室內地面的障礙物深度圖的分割,提取出障礙物區域,然后利用Canny邊緣檢測算法計算得到該區域的邊緣坐標信息,實現了障礙物識別的精細化,有效提高了障礙檢測的精度,降低弱紋理地面因素的影響。在實際應用中,由于陰影和光照等因素干擾,大大增加了障礙物的檢測難度,系統仍需針對這些干擾因素進行進一步的改良。
參考文獻:
[1] 張耀威,卞春江,周海,等.基于圖像與點云的三維障礙物檢測 [J].計算機工程與設計,2020,41(4):1169-1173.
[2] LAN J H,JIANG Y L,FAN G L,et al. Real-Time Automatic Obstacle Detection method for Traffic Surveillance in Urban Traffic [J].Journal of Signal Processing Systems,2016,82(3):357-371.
[3] 張舜,郝泳濤.基于深度學習的障礙物檢測研究 [J].電腦知識與技術,2019,15(34):185-187+193.
[4] 王軍華,李丁,劉盛鵬.基于改進RANSAC的消防機器人雙目障礙檢測 [J].計算機工程與應用,2017,53(2):236-240.
[5] 吳宗勝,李紅,韓改寧.結合立體視覺與超像素技術的道路障礙物概率檢測 [J].機械科學與技術,2019,38(2):277-282.
[6] 張易,項志宇,陳舒雅,等.弱紋理環境下視覺里程計優化算法研究 [J].光學學報,2018,38(6):226-233.
[7] HAN Y,CHU Z N,ZHAO K. Target positioning method in binocular vision manipulator control based on improved canny operator [J].Multimedia Tools and Applications,2019(5):1-16.
作者簡介:林堅(1992—),男,漢族,廣東吳川人,碩士,研究方向:系統集成;通訊作者:王力虎(1962—),男,漢族,山西文水人,教授,碩士生導師,博士,研究方向:工業自動化、計算機程序設計。
