基于TLSTM的醫療保險欺詐檢測
2020-11-10 07:10:52曹魯慧秦豐林閆中敏
計算機工程與應用 2020年21期
曹魯慧,秦豐林,閆中敏
1.山東大學 信息化工作辦公室,濟南 250100
2.山東大學 軟件學院,濟南 250100
1 背景
醫療保險欺詐每年對許多國家造成的經濟損失高達數千億美元,嚴重威脅醫保基金的合法使用,妨礙政府醫保政策的有效實施。隨著信息化的發展,越來越多的用戶屬性信息和行為信息被積累下來,醫療保險欺詐識別成為學者們的研究熱點。醫保欺詐識別旨在醫療保險大數據中抽繭剝絲,從絕大部分正常合理的醫療數據中區分出極少量的欺詐記錄,由于數據量大、數據分布不均、違規行為相對隱蔽,使得醫療保險大數據中的欺詐檢測成為一項具有挑戰性的工作。
目前國內醫保領域的醫療服務反欺詐應用系統主要通過專家定義的欺詐檢測規則來圈定疑似欺詐行為,規則中閾值、權重的選擇非常困難,而且現實中大部分欺詐行為比較隱蔽,按照規則一刀切計算代價非常大但準確率卻極低。
已有的欺詐識別算法大多將其看作二分類問題,將記錄分成合法/欺詐兩個類別。但在醫療保險背景下,由于供需雙方存在嚴重的信息不對稱現象,欺詐者會努力模仿合法用戶的行為,而且欺詐者的比例很小,傳統的基于分類的欺詐識別算法不再適用。
近年來,隨著深度學習的發展,學者們廣泛使用遞歸神經網絡(RNN)利用患者就醫行為序列構建預測模型,預測患者接下來的就醫行為。但是,RNN無法有效解決長期依賴關系。當患者的就醫行為序列過長時,RNN模型的預測性能會隨之下降。
不同就醫之間具有依賴關系。將時序信息結合到算法中能夠提高欺詐識別的準確率。區別于傳統的事件序列數據(如股票價格等),病人的住院數據時間間隔是不均勻分布的。兩次住院記錄間的時間間隔可能是幾天、幾月甚至幾年。時間間隔的長短對后續事件的影響程度是不同的,間隔時間越長,對后續的影響程度越小。圖1 顯示了一個病人在某個時間段內的就醫行為序列,可以看出從時間分布上看,就醫行為由于偶發性等原因分布并不均勻。此外,疾病和藥品/診療項目種類繁多,醫療保險數據是異構的。若能夠根據患者的就醫行為序列歷史預測其下一次就醫行為,能夠有效幫助進行醫療保險欺詐的預防工作。

圖1 患者就醫序列
針對上述問題和挑戰,本文旨在解決以下關鍵問題:如何考慮時間間隔對醫療行為的影響以提高預測的準確程度;如何通過預測結果與現實就醫行為的對比來篩選出可疑的欺詐記錄。為了解決這些問題,提出了一個基于TLSTM的醫療保險欺詐識別模型。該模型使用過去五年中患者的醫療保險數據作為樣本。改進LSTM 提出TLSTM 算法,引入注意機制和時間調整因子來共同加權不同時刻的隱藏狀態,顯著提高了預測性能并獲得較高的欺詐識別準確率。
總之,本文的主要貢獻如下:
(1)在LSTM 的基礎上,引入注意機制和時間調整因子來共同加權不同時刻的隱藏狀態,顯著提高了預測性能。
(2)將患者的就醫行為與預測的就醫行為結果進行對比,通過其相似程度確定患者存在欺詐的概率,無需花費很大精力獲得大量有標簽數據作為訓練集。
2 相關研究
基于深度學習的醫療欺詐檢測能夠根據歷史記錄識別出各種復雜類型的醫療保險欺詐。
Choi[1]提出基于graph的注意力模型GRAM補充電子健康記錄醫學本體所固有的分層信息,代表一個醫學概念作為本體通過注意力機制的組合模型。Kermany[2]建立了一個基于深度學習框架的篩查普通可治療致盲性視網膜疾病的診斷工具。該框架利用轉移學習,使用傳統方法的一小部分數據來訓練神經網絡。將這種方法應用于光學相干斷層掃描圖像數據集,證明其性能與人類專家在分類年齡相關性黃斑變性和糖尿病性黃斑水腫方面的性能相當。Litjens[3]將“深度學習”作為一種提高組織病理學幻燈片分析的客觀性和效率的技術。Golden[4]比較了幾種機器學習方法來檢測醫療保險欺詐。采用監督式、無監督式和混合式機器學習方法進行比較研究,使用四種性能指標和通過過采樣和80-20 欠采樣方法減少類失衡。
Baytas[5]提出了一種患者亞型模型,該模型利用TLSTM來學習患者順序記錄的強大單一表示,然后用它將患者分組為臨床亞型。Pham[6]介紹Deepcare,一種端到端深度動態神經網絡,可讀取醫療記錄,存儲以前的病史,推斷當前的疾病狀態并預測未來的醫療結果。Ma[7]提出了Dipole,是一種端到端,簡單且健壯的預測患者未來健康信息的模型,用雙向遞歸神經網絡來記憶過去入院記錄和未來入院記錄的所有信息,并引入三種注意機制來測量不同入院記錄對于預測的關系。Liu[8]提出了一個深度加強學習框架,以通過觀察醫學數據估計最佳動態治療方案。該框架比現有的強化學習方法更靈活,更適應高維空間,以模擬現實生活中異質疾病進展和治療選擇的復雜性,其目標是為醫生和患者提供數據驅動的個性化決策建議。Lasaga[9]展示如何有效地利用RBMs 來找出不嚴格遵循給定診斷對應治療方案的異常處方。Guo[10]對連續行為產生的屬性行為序列進行建模,以捕獲序列模式,將那些偏離序列的行為視為欺詐行為。Zheng[11]提出了一種基于生存分析的欺詐早期檢測模型SAFE,該模型將動態用戶活動映射到生存概率,并保證生存概率隨時間單調遞減。Yan[12]提出了一種新的混合離群點檢測方法,即基于剪枝的k近鄰(PB-KNN),它將基于密度、基于簇的方法與KNN 算法相結合,進行有效的離群點檢測。
上述相關研究都獲得了令人滿意的欺詐識別效果,然而,它們大都針對于特定疾病類型進行欺詐識別,此外,沒有考慮就醫行為序列中的長時依賴問題。因此本文考慮不同時間間隔對于就醫行為預測的影響,并提出針對于全部疾病類型而非單一疾病類型的欺詐識別算法。
3 基于LSTM的醫療保險欺詐檢測
本章中,首先介紹了醫療保險數據的結構一些基本的符號。然后描述了基于LSTM 的醫療保險欺詐識別算法細節。
3.1 符號表示
醫療保險數據包含三部分信息:(1)患者的基本信息;(2)患者的就醫記錄信息;(3)欺詐標識狀態。
患者的基本信息指患者的年齡、性別、住址等屬性信息。形式化表示為pi=(agei,sexi,addressi,…)。
患者的就醫記錄信息可以表示為就醫序列,由按時間遞增順序產生的一系列就診行為組成。每次就診行為由疾病診斷和采用的藥品/診療項目組成。患者pi的就醫記錄信息形式化表示為pv=(v1,v2,…,vt),每次就診行為可表示為vj=(hj,dj,cj1,cj2,…,cjn),hj表示該次就診的醫院,dj代表患者該次就診的疾病診斷,cj1,cj2,…,cjn指的是該次就診中所使用的藥品/診療項目代碼。每個診斷代碼都可以映射到國際疾病分類(ICD-9)的節點,以及每個藥品/診療項目代碼可以映射到當前過程術語中的節點(CPT)。
輸入為患者在時間段T內的就醫記錄,旨在通過預測t+1 時刻的用戶就醫行為,然后與其實際行為進行對比,相似度越小,存在欺詐的可能性越大。
3.2 LSTM介紹
遞歸神經網絡(RNN)是一種深層網絡結構,其中隱藏單元之間的連接形成一個定向循環。這個反饋循環使網絡能夠將隱藏狀態的前一個信息作為內部存儲器。因此,對于系統需要存儲和更新上下文信息的問題,RNN 是首選的。基于隱馬爾科夫的模型也具有類似的功能,但區別于傳統的隱馬爾科夫模型,RNN不做馬爾可夫特性的假設,可以處理可變長度序列。此外,原則上,過去輸入的信息在內存中不受時間限制。然而,長期依賴性的優化在實際中是不可能實現的,因為在這種情況下,梯度值將分別變得過大或者過小。為了能夠在不違反優化過程的情況下合并長期依賴關系,會產生差異。其中一個流行的變種是長短期記憶網絡(LSTM),它能夠處理具有集成結構的長時間依賴關系。一個標準的模塊對忘記、輸入、輸出門和存儲器單元進行了計算,但是結構要求在元素之間的間隔時間內均勻地分布。因此,在縱向醫療數據中存在的時間不均勻性不適用于該邏輯結構。例如,患者的就醫行為日期的分布是高度不均勻的,這樣記錄之間的時間間隔可以從一天到幾年不等。由于連續兩次醫院就診之間的時間間隔是醫療領域決策的重要來源之一,LSTM體系結構會將正常的時間間隔納入到時間數據所需的審計數據中。為此,提出了TLSTM算法,能夠處理就醫行為間隔分布的不均勻性。
3.3 基于TLSTM的就醫行為預測
首先,算法利用改進的LSTM算法預測患者在t+1時刻的行為預測。
圖2顯示了算法的主要步驟。給定患者從1到t時刻的就醫行為記錄,i時刻的就診行為可以映射為一個向量veci。將其作為TLSTM 的輸入,獲得隱藏狀態Hi。通過attention機制,可以計算當前i狀態的相對重要權重。最終,算法輸出t+1時刻的就醫行為預測結果。

圖2 算法結構
Embedding Layer嵌入層用于將輸入的患者從1到t時刻的就醫記錄映射為向量vec。若使用該藥品/診療項目,則向量中對應值為1,否則置為0。對于輸入x=pv=(v1,v2,…,vt),其映射向量vec可以表示為:

A表示藥品/診療項目的權重矩陣。
RNN 為建模患者就醫時序數據提供了可能,但RNN 的預測性能會隨著時序序列的長度增加而下降。LSTM可以克服該缺點,但它沒有考慮不同時間間隔對預測結果的不同權重。為了解決以上挑戰,提出引入時間間隔的TLSTM,它考慮時間序列間不同時間間隔對預測的不同影響程度。圖3為TLSTM的示意圖。
注意力機制模擬人腦注意力的特征。該核心思想是更多地關注重要內容,而不是關注其他內容。在住院行為預測的過程中,傳統的神經網絡模型忽略了訪問時間間隔長度的影響關于建模的序列,因為每次訪問對當前時刻的貢獻不一定是一樣的。因此,考慮到并非所有特征都有助于預測,將注意力分數和時間調整因子添加到LSTM框架,在患者就醫序列的建模過程中用于確定隱藏狀態的強度。
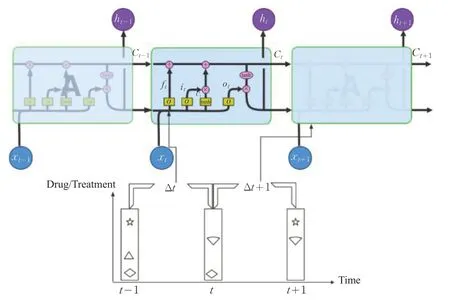
圖3 引入時間間隔
TLSTM能夠根據疾病類型和時間間隔控制前面信息的通過程度。算法實現過程如下:
首先,通過忘記門的Sigmoid 層決定要從細胞狀態中丟棄什么信息。它查看ht-1(前一個輸出)和xt(當前輸入),并為單元格狀態Ct-1(上一個狀態)中的每個數字輸出0和1之間的數字。1代表完全保留,而0代表徹底刪除。Δt表示行為間的時間間隔,不同的時間間隔對信息的保留程度產生影響。時間間隔越久,信息保留程度越小。
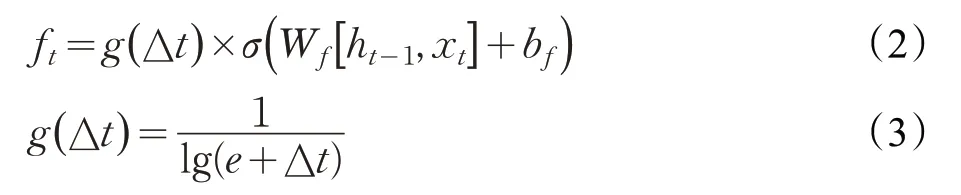
然后決定要在細胞狀態中存儲什么信息。這部分分為兩步。首先,稱為“輸入門層”的Sigmoid層決定了將更新哪些值。接下來一個tanh 層創建候選向量Ct,該向量將會被加到細胞的狀態中。在下一步中,結合這兩個向量來創建更新值。
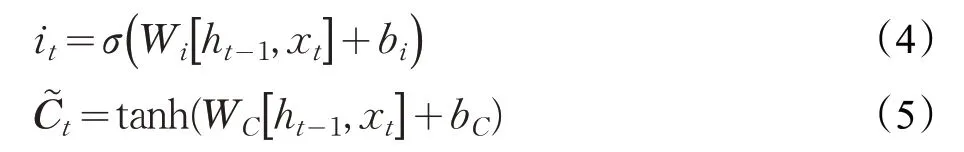
更新上一個狀態值Ct-1,將其更新為Ct。將上一個狀態值乘以ft,以此表達期待忘記的部分。
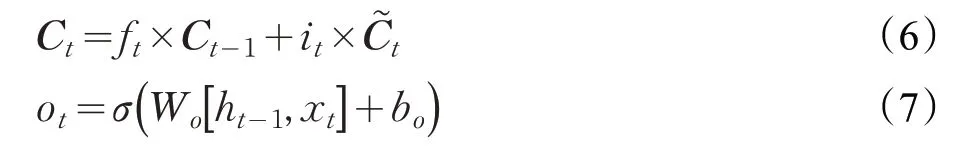
輸出將基于細胞狀態,但將是一個過濾版本。首先,運行一個Sigmoid層,它決定了要輸出的細胞狀態的哪些部分。然后,將單元格狀態通過tanh(將值規范化到-1 和1 之間),并將其乘以Sigmoid 門的輸出,至此輸出了決定的那些部分。

獲得輸出的預測就醫行為之后,計算該患者在t+1時刻的實際就醫行為與預測的就醫行為之間的相似度。若相似度較高,說明該次就醫行為存在欺詐的可能性較低,反之,存在欺詐的可能性較高。
4 實驗評估
在真實數據集上評估提出的模型。為了保護隱私和安全,對相應的患者和醫院的實驗數據進行匿名化,如使用Hospital-A、Hospital-B來代表醫院的名稱。
中國山東省某地區的健康保險數據用于實驗,主要選擇了患者2014 年至2018 年總費用最高的四大疾病。四種疾病包括腫瘤、冠心病疾病、糖尿病和肺炎。這些就醫數據包括診斷,醫院和藥品/診療項目。為方便起見,使用TD來表示腫瘤數據集,CHDD代表冠心病數據集,DD 代表糖尿病數據集,PD 代表發送肺炎數據集。表1描述了有關數據集的統計信息。
與已有醫療保險欺詐識別方法進行比較,以便評估TLSTM模型的性能,方法描述如下。
樸素貝葉斯(NB)[13]:將欺詐識別看作二分類問題。
梯度提升樹(GBDT)[14]:基于迭代所構造的決策樹算法。
RNN[15]:這是傳統的單向遞歸神經網絡,在不使用任何注意機制的情況下輸出未來的就醫行為。
TLSTM:本文提出的模型,考慮時間間隔對醫療的影響。
表2展示了利用TLSTM預測就醫行為所在醫院的結果實例。

表2 醫院預測
將患者的就醫行為與預測的就醫行為結果進行對比,通過其相似程度確定患者存在欺詐的概率。若相似度較高,說明該次就醫行為存在欺詐的可能性較低,反之,存在欺詐的可能性較高。采用準確率、召回率和F-meausre作為評價標準來評估算法的性能。對于所有帶參數的方法,通過進一步將訓練集劃分為80%用于模型擬合和20%用于參數驗證來優化參數10 次交叉驗證。圖4 顯示TLSTM 算法與對比算法的性能比較結果。從圖中可以看出,本文的算法較已有算法顯著提高了欺詐識別的準確程度。

圖4 性能對比
5 結論
近年來,隨著中國人口數量的迅速擴大,醫療保險的參保患者人數也不斷增加。如何通過患者的就醫行為分析發現疑似欺詐記錄已成為醫療保險的重要研究熱點。當患者就診序列的長度很大時,RNN 的預測能力會顯著下降。此外,該方法忽略了訪問序列中時間間隔對其的影響。基于TLSTM的醫療保險識別模型解決了這些問題。將用戶的歷史就醫行為序列作為TLSTM模型的輸入,預測患者再入院原因及診療方案,通過比較模型輸出與用戶當前就醫行為的差異程度,來判斷用戶存在欺詐的可能性。實驗表明,該算法在欺詐識別準確度上明顯優于已有算法。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中外會展(2014年4期)2014-11-27 07:46:46
中學數學雜志(初中版)(2006年1期)2006-12-29 00:00:00
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
