基于機器學習對公司未來ROE預測的研究
2020-11-16 06:55:49翟玉奇
市場周刊·市場版 2020年2期
關鍵詞:機器學習


摘 要:ROE作為評價公司盈利能力的重要指標,可衡量公司對股東投入資本的利用效率。它彌補了每股稅后利潤指標的不足,因此,每一次的ROE都是影響上市公司的股價、未來業績以及投資者期望進而營銷的其投資者的投資決策。本文根據杜邦分析法中的若干因素,結合其他分析因子,運用R軟件,通過機器學習,構建模型,有效彌補了簡單的多元回歸擬合不精確的情況,為預測公司ROE提供了一個新的方法,也為投資人進行投資決策提供了一個重要依據。
關鍵詞:ROE;杜邦分析;多元回歸;機器學習
一、 引言
凈資產報酬率(ROE),是企業一定時期的凈利潤與平均凈資產之比,該指標反映了企業所有者所獲投資報酬的大小。該指標越好,則表示企業的經營給股東的回報越高,越容易吸引市場投資者的關注。如果企業對其財務管理的意識缺乏,就會盲目樂觀,意識不到潛在的危機,可能會導致企業遭到巨大的損失。所以,只有用科學的方法進行綜合性的財務預測才能對于企業的日常和未來的發展提供有效的建議,從而不斷促進企業自身的發展。
傳統的財務預測只能從單一的盈利能力、營運能力、償債能力和發展能力進行簡單分析,另外杜邦財務分析體系可以全面概括以上四個能力的分析結果。能夠幫助企業的管理決策者對企業財務狀況有更加全面、更具全局性的了解,但由于其內在因素可能會產生共線性或相關性較大的因素,應在杜邦分析的基礎上,加入其保函因素之外的變量加以預測,進而及時調整企業的發展策略以及管理結構,使企業向正確的方向發展和進步。
機器學習是研究怎樣使用計算機模擬或實現人類學習活動的科學,是人工智能中最具智能特征,最前沿的研究領域之一。本文運用的機器學習方法為隨機森林和XGBOOST分析方法,從準確性和模型規范性上,對預測公司未來ROE有著質的提高。
二、 數據處理與模型介紹
(一)數據選擇
根據杜邦分析我們可以知:資產凈利率是影響權益凈利率的最重要的指標,具有很強的綜合性,而資產凈利率又取決于銷售凈利率和總資產周轉率的高低。總資產周轉率是反映總資產的周轉速度。對資產周轉率的分析,需要對影響資產周轉的各因素進行分析,以判明影響公司資產周轉的主要問題在哪里。銷售凈利率反映銷售收入的收益水平。擴大銷售收入,降低成本費用是提高企業銷售利潤率的根本途徑,而擴大銷售,同時也是提高資產周轉率的必要條件和途徑。
因此,在選擇杜邦因素數據方面,我們選擇資產周轉率、利潤率、債務資本比率;杜邦因素之外的因素通過分析企業數據相關程度選擇了成長速度、市倍率、收入質量、資產規模、當年凈資產收益率作為指標。
(二)數據處理
根據choice金融客戶端,通過比率分析,由抽取決策好的數據,并由下一年度ROE作為預測標準,本文選取了2432條觀測數據如表1,以此提高機器學習的準確性,通過與線性回歸的對比,驗證其回歸的準確性與優越性。
(三)數據描述
1. 數據統計性描述
為驗證其選擇數據準確性,應檢測模型因素的準確性:
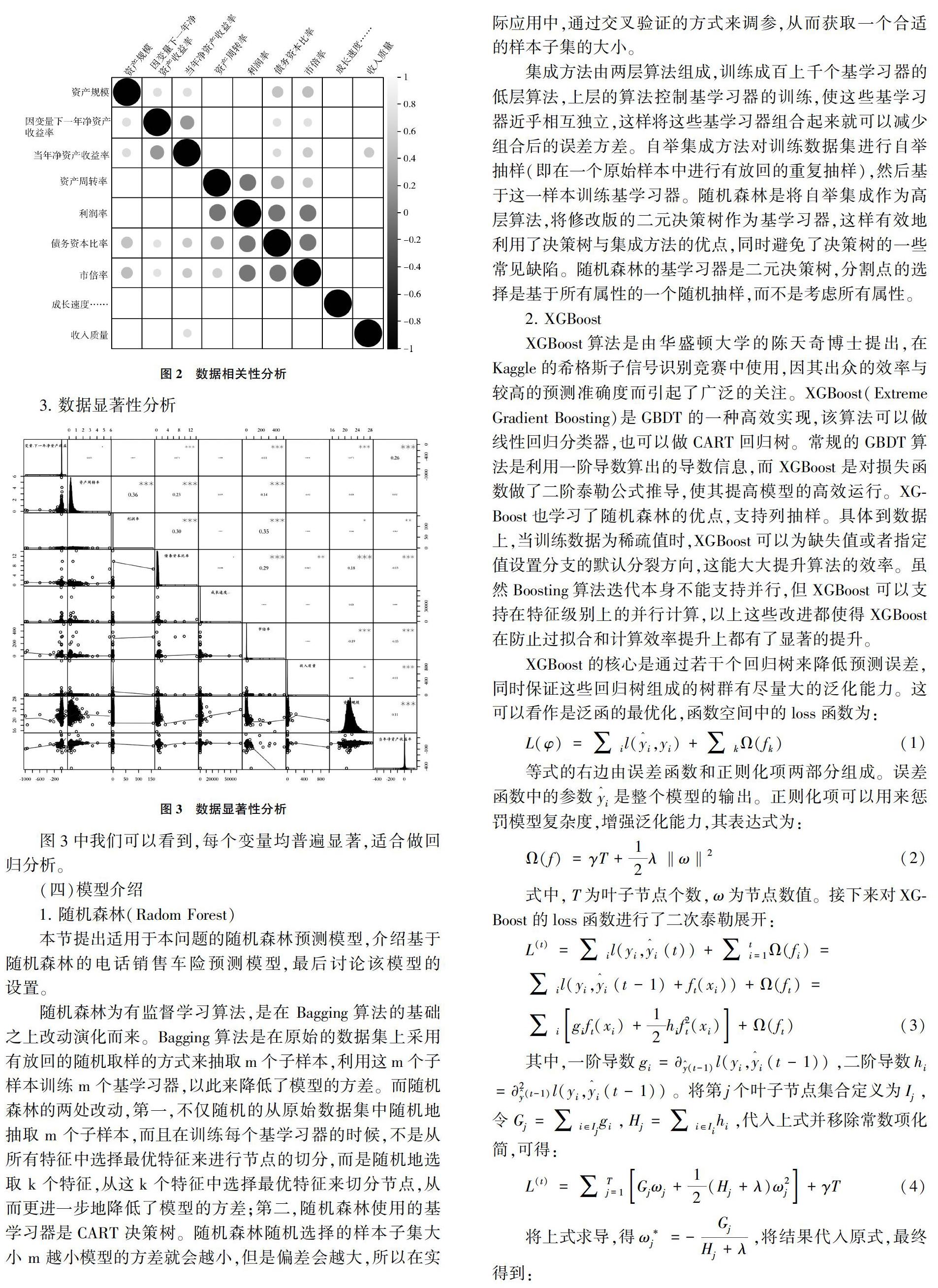
2. 數據相關性分析(圖2)
3. 數據顯著性分析
圖3中我們可以看到,每個變量均普遍顯著,適合做回歸分析。
(四)模型介紹
1. 隨機森林(Radom Forest)
本節提出適用于本問題的隨機森林預測模型,介紹基于隨機森林的電話銷售車險預測模型,最后討論該模型的設置。
隨機森林為有監督學習算法,是在 Bagging算法的基礎之上改動演化而來。Bagging算法是在原始的數據集上采用有放回的隨機取樣的方式來抽取m個子樣本,利用這m個子樣本訓練 m 個基學習器,以此來降低了模型的方差。而隨機森林的兩處改動,第一,不僅隨機的從原始數據集中隨機地抽取 m 個子樣本,而且在訓練每個基學習器的時候,不是從所有特征中選擇最優特征來進行節點的切分,而是隨機地選取 k 個特征,從這k 個特征中選擇最優特征來切分節點,從而更進一步地降低了模型的方差;第二,隨機森林使用的基學習器是CART 決策樹。隨機森林隨機選擇的樣本子集大小 m 越小模型的方差就會越小,但是偏差會越大,所以在實際應用中,通過交叉驗證的方式來調參,從而獲取一個合適的樣本子集的大小。
集成方法由兩層算法組成,訓練成百上千個基學習器的低層算法,上層的算法控制基學習器的訓練,使這些基學習器近乎相互獨立,這樣將這些基學習器組合起來就可以減少組合后的誤差方差。自舉集成方法對訓練數據集進行自舉抽樣(即在一個原始樣本中進行有放回的重復抽樣),然后基于這一樣本訓練基學習器。隨機森林是將自舉集成作為高層算法,將修改版的二元決策樹作為基學習器,這樣有效地利用了決策樹與集成方法的優點,同時避免了決策樹的一些常見缺陷。隨機森林的基學習器是二元決策樹,分割點的選擇是基于所有屬性的一個隨機抽樣,而不是考慮所有屬性。
2. ?XGBoost
XGBoost算法是由華盛頓大學的陳天奇博士提出,在Kaggle的希格斯子信號識別競賽中使用,因其出眾的效率與較高的預測準確度而引起了廣泛的關注。XGBoost(Extreme Gradient Boosting)是GBDT的一種高效實現,該算法可以做線性回歸分類器,也可以做CART回歸樹。常規的GBDT算法是利用一階導數算出的導數信息,而XGBoost是對損失函數做了二階泰勒公式推導,使其提高模型的高效運行。XGBoost也學習了隨機森林的優點,支持列抽樣。具體到數據上,當訓練數據為稀疏值時,XGBoost可以為缺失值或者指定值設置分支的默認分裂方向,這能大大提升算法的效率。雖然Boosting算法迭代本身不能支持并行,但XGBoost可以支持在特征級別上的并行計算,以上這些改進都使得XGBoost在防止過擬合和計算效率提升上都有了顯著的提升。
三、 模型驗證
(一)線性回歸
根據線性回歸的結果來看,可列出回歸方程:
下一年ROE=3.354×資產周轉率+0.485×利潤率-4.106×債務資本比率-0.0002成長速度-0.122×市倍率+0.057×收入質量+1.106×資產規模+0.581×當年凈資產收益率-23.781
但R2僅僅只達到了8%,是一個相當低的值,考慮到多元回歸方程的原理僅僅為最小二乘法,但由于數據較為分散,控制回歸會造成準確度偏低的情況,因此,此時僅僅運用多元回歸是行不通的。
(二)RadomForest
1. RadomForest重要性分析
從Radom Forst給出的重要性權重中,可以看到當年ROE的對于預測下一年ROE有著重大的影響。
2. 模型精確度
[1]0.9919333
過歷史數據檢驗,我們可以將準確度控制在99.19333%,這是一個相當大的準確度,但是模型的難度也相當龐大,建立模型的時間消耗巨大。
(三)XGBoost
1. 因素重要性分析(圖6)
與隨機森林的學習模型相同,當年ROE與下一年ROE有著密不可分的關系,這也是提高精確度必備可少的因素。
2. 模型精確度
通過XGBoost模型,可以迅速高效率地得到較為準確的預測模型,精確度達到了98.35419%。可以看到,雖然XGBoost精確度不如Radom Forest,但是從其速度來說,更勝Radom Forest一籌。
四、 結論
對比原始的多元回歸分析,Radom Forest和XGBoost都有不同程度優勢,在準確度方面,Radom Forest要比XGBoost模型有著更準確的優點,但其缺點也更加明顯:隨著數據的增多,其訓練模型耗費的時間也越多,XGBoost在提升了速度之后,缺失了一部分準確度,由于數據過少,或者數據變量不夠充分等因素或許是造成缺失準確度的原因。
五、 結束語
本文對傳統的預測下一年度ROE問題進行了創新與改進,基于XGBoost和Radom Forest模型的預測結果往往更具有代表性,準確性和快速性,并經過數據對其模型的準確性進行驗證,在今后金融市場投資者選擇被投資公司的實踐中,可以加入更多的有關變量提供模型的準確程度,這對調整對投資者投資行為指導有著巨大的意義,如果簡單做一次預測ROE分析的話,根據現有的ROE數據進行判斷,往往有著不俗的預測表現。
作者簡介:
翟玉奇,山西大學。
猜你喜歡
電子技術與軟件工程(2016年22期)2016-12-26 21:36:42
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
活力(2016年8期)2016-11-12 17:30:08
科學與財富(2016年28期)2016-10-14 21:19:17
電腦知識與技術(2016年20期)2016-08-19 18:49:49
電腦知識與技術(2016年12期)2016-06-14 00:45:31
科教導刊·電子版(2016年10期)2016-06-02 19:17:03
科教導刊·電子版(2016年10期)2016-06-02 18:04:11
電腦知識與技術(2016年3期)2016-04-07 16:12:55
