基于word2vec的語音識別后文本糾錯
2020-11-17 06:55:56張佳寧嚴(yán)冬梅
計算機(jī)工程與設(shè)計 2020年11期
張佳寧,嚴(yán)冬梅,王 勇
(天津財經(jīng)大學(xué) 理工學(xué)院,天津 300222)
0 引 言
隨著在線會議、慕課及自媒體視頻等的興起,離線長音頻生成字幕的需求呈現(xiàn)爆炸式增長,傳統(tǒng)的以人為主的技術(shù)已經(jīng)不能滿足需求,將語音識別技術(shù)(automatic speech recognition,ASR)運用于字幕制作是大勢所趨。然而實際應(yīng)用中,由于環(huán)境噪音、語音質(zhì)量、方言和說話方式以及ASR系統(tǒng)詞匯量等多因素的影響,會不可避免地導(dǎo)致ASR的錯誤[1]。
許多研究人員為降低語音識別錯誤率做了大量研究。Graves A[2]通過增加詞與詞之間的停頓提高正確率;Fujiwara K[3]通過提出一種更適于人發(fā)音的語音字母表改進(jìn)了語音輸入;Che J等通過分析語音識別錯誤的案例,提出一種特有的基于漢語語音、語言特征的文本校正和意圖識別方法[4]。但這些研究[2-4]都聚焦在短句實時識別,與長音頻的ASR結(jié)果有很大不同。
Ogawa A等[5,6]提出一種使用深度雙向回歸神經(jīng)網(wǎng)絡(luò)進(jìn)行ASR誤差檢測和識別率估計的方法;Rahhal Errattahi等[7]利用變量神經(jīng)網(wǎng)絡(luò)(V-RNN)模型進(jìn)行錯誤檢測和錯誤類型分類。但這些研究[5-7]都是針對分類任務(wù)的,用有限的規(guī)則去約束復(fù)雜多變的語言顯然不合理。
Geonwoo Park等[8]提出一種用于常規(guī)ASR系統(tǒng)的拼寫錯誤校正后處理模型,但由于誤識別詞的候選集僅由語音識別產(chǎn)生的備選詞構(gòu)成,導(dǎo)致該方法嚴(yán)重依賴ASR的識別結(jié)果。
針對上述研究中存在的問題,本文提出一種基于word2vec的糾錯方法,即利用word2vec建立語義和語境詞典,使用百度公開的深度語言模型,解決語音識別后得到的文本與原始音頻不符的問題。
1 基于word2vec的語音識別后文本糾錯
1.1 基于word2vec的語義相似度
計算機(jī)在處理詞語時會用一種數(shù)學(xué)化的形式表示詞語,稱為詞語的向量化。word2vec與獨熱編碼(One-Hot Encoder)的目的都是把詞映射到n維空間。但不同于One-Hot Encoder,為了防止因為數(shù)據(jù)稀疏帶來的維數(shù)災(zāi)難問題,word2vec將詞轉(zhuǎn)化成了稠密向量。
word2vec由Tomas Mikolov等提出[9,10],它是在神經(jīng)網(wǎng)絡(luò)語言模型(neural network language model,NNLM)基礎(chǔ)上建立的。word2vec用Huffman樹作為最后一層輸出層,僅考慮“局部上下文”來學(xué)習(xí)有意義的詞向量。
詞在轉(zhuǎn)化為向量時,意思相近的詞會被映射到空間中相近的位置。word2vec根據(jù)這一特性,使用夾角余弦[11]來反映詞語間的關(guān)聯(lián)程度。夾角余弦的計算方法如式(1)所示,空間中的兩個詞的語義越相似,它們的夾角余弦值也就越接近于1
(1)
式中:W1,W2為詞向量,W1i,W2i分別表示W(wǎng)1,W2的各分量。
在語義上越接近的詞,出現(xiàn)在同一語境的可能性越大,因此本文在進(jìn)行語境檢測時使用了基于word2vec的語義相似度計算方法。
1.2 語境關(guān)鍵詞的提取
情景語境指說話人說話當(dāng)時當(dāng)?shù)厮幍沫h(huán)境。無論在何種環(huán)境中,某一時刻的說話內(nèi)容總是圍繞一個特定主題展開的,本文稱之為語境核心詞(簡稱核心詞)。如“指針”是C語言的代表,若再提到“繼承”、“友元”、“類”就會聯(lián)想到C++語言。關(guān)鍵詞是指在特定語境含有特定意義的詞,范圍大于核心詞。
考慮到算法的擴(kuò)展性、用戶友好性,本文參考李躍鵬等[12]的方法,使用預(yù)訓(xùn)練好的word2vec模型結(jié)合少量語境核心詞構(gòu)建關(guān)鍵詞集。
語義相似度表明了詞與詞在語義上的相關(guān)程度,與核心詞在語義上距離比較近的詞,也是對于整個語境比較重要的詞。因此,關(guān)鍵詞集由與核心詞語義相似度相近的詞組成。具體計算方法如式(2)和式(3)
(2)
n_c表示cores中詞的總數(shù),corei表示核心詞集cores中的第i個核心詞,wordj表示語料庫中第j個詞,tmp_KeyScorej表示wordj與核心詞集cores語義相似度的均值
retention_factorsj=tmp_KeyScorej-β
(3)
retention_factorsj表示wordj的保留因子;β是一個可調(diào)閾值參數(shù),它限制著retention_factorsj。當(dāng)β值比較大時,retention_factorsj相應(yīng)就比較小,所對應(yīng)的wordj被保留在關(guān)鍵詞集的概率也就比較小;反之,則wordj被保留在關(guān)鍵詞集的概率就比較大。
求得詞集后,對詞集tmp_keys進(jìn)行排序,并將結(jié)果保存到最終的關(guān)鍵詞詞集keyword_set。關(guān)鍵詞詞集keyword_set可以分成兩部分,第一部分由出現(xiàn)在當(dāng)前語境的詞組成,第二部分由未出現(xiàn)在當(dāng)前語境的詞組成。第一部分按照對糾錯的貢獻(xiàn)性又可以劃分成兩組,第一組為對糾錯有貢獻(xiàn)的,第二組為對糾錯沒有貢獻(xiàn)的。關(guān)鍵詞詞集keyword_set中最后真正有用的,只有第一部分中的第一組中所含的詞。在每次查找時,如果不對關(guān)鍵詞詞集keyword_set加以約束,詞集中所有詞就都會被遍歷。這不僅沒有提高糾錯正確率,還產(chǎn)生了較高時間代價。為了提高查詢關(guān)鍵詞集的效率,參考Salihefendic A等[13]的方法,本文對關(guān)鍵詞進(jìn)行了排名,在糾錯時對keyword_set中的詞投票,具體計算方法如式(4)和式(5)
(4)
其中,wi表示待修改文本中第i個詞,w_pyi表示wi的拼音,keyword_seti表示keyword_set中與w_pyi對應(yīng)的詞,xi表示待修改文本中第i個詞的拼音的貢獻(xiàn)度
(5)
其中,word_frei表示keyword_set中的第i個詞wordi的詞頻;α1、α2是可調(diào)的參數(shù),表示隨著連續(xù)語音的識別,word_frei隨著時間的變化。
更新keyword_set中詞的詞頻后,對keyword_set中詞進(jìn)行約束,規(guī)定將小于某一閾值的詞停用。
1.3 最終混淆集的生成
1.3.1 深度語言模型
語言模型描述的是在語言學(xué)中詞與詞在數(shù)學(xué)上的關(guān)系,它在文本糾錯中起著至關(guān)重要的作用。在過去的自然語言處理中,N-Gram模型因其簡單、易用、有效的特點,一直發(fā)揮著重要的作用[14]。但是隨著N元文法的增加,模型參數(shù)會變得很大,對于長距離的語境信息不能很好地利用。此外,數(shù)據(jù)稀疏也一直是N-Gram不可避免的問題。DNNLM則是在深度學(xué)習(xí)的基礎(chǔ)上建立的,它不僅比 N-Gram 能利用更多的上下文信息,而且在訓(xùn)練中采用了詞向量,減少了數(shù)據(jù)稀疏性對于模型的影響。
訓(xùn)練一個好的語言模型需要十分龐大的正確語料以及一定軟硬件支持。過去這項工作在國內(nèi)一直由研究者或者相關(guān)領(lǐng)域的企業(yè)所有,市場上很難獲得一個訓(xùn)練好的模型的接口。2017年百度免費開放了依托海量優(yōu)質(zhì)數(shù)據(jù)和最新技術(shù)訓(xùn)練的DNNLM,為研究者提供了一個實用便捷的工具。本文在模型中使用DNNLM對輸入文本中的詞進(jìn)行判斷,從而得出該詞出現(xiàn)在當(dāng)前文本中的概率。
1.3.2 混淆集的縮減
考慮到語音識別時一些字的音會發(fā)生變化,混淆集中的替換詞不能只包含同音詞,初始混淆集需要采用PYCN生成。在采用PYCN生成混淆集時,由于原始詞拼音的不確定性,使得生成的初始混淆集tmp_con中詞的數(shù)量眾多。例如:使用“雞蛋”生成混淆集時,最終會得到“幾單”、“忌憚”等100多個搜索結(jié)果。而DNNLM為了覆蓋范圍更全面、結(jié)果更合理,模型一般都很大,如果將這些結(jié)果都輸入到模型中進(jìn)行查詢,時間開銷將會非常大。為了解決這一問題,本文利用語境知識縮減混淆集中詞的數(shù)量。本文先從測試集中選取了85個測試實例,然后又從3個領(lǐng)域中選取了85個詞進(jìn)行了實驗。實驗結(jié)果如圖1和圖2所示。

圖1 使用NNLM計算句子得分時間開銷

圖2 使用word2vec計算詞語間相似度時間開銷
圖1是使用DNNLM計算句子得分的時間開銷,橫坐標(biāo)表示輸入句子的數(shù)量,縱坐標(biāo)表示使用的時間,單位為s。圖2是使用word2vec計算詞語間相似度的時間開銷,橫坐標(biāo)表示輸入詞的數(shù)量,縱坐標(biāo)表示使用的時間,單位為ms。
由圖1、圖2可知,使用word2vec計算80個詞與詞的語義相似度花費的時間僅為0.0020 s,使用DNNLM查詢80句話的時間開銷已經(jīng)達(dá)到25 s,計算語義相似度的時間開銷要遠(yuǎn)遠(yuǎn)小于計算語句語言模型得分的。核心詞表示了當(dāng)前語境的主要內(nèi)容,語境中出現(xiàn)的其它詞在理論上不應(yīng)該與核心詞在語義上相距太遠(yuǎn)。可見,利用語義詞典查詢詞與詞的語義相似度,將混淆集中與語境相距太遠(yuǎn)的詞篩除,來縮小混淆集中詞的數(shù)量,不僅不影響糾錯結(jié)果,還減少了查詢語言模型的次數(shù),提高了糾錯效率。因此,為了減小模糊集的數(shù)量,可以對tmp_con中的詞與核心詞進(jìn)行語義相似度計算,從而排除一些不合語境的詞。計算語境得分的計算方法如式(6)所示
(6)
tmp_conj表示文本詞集tmp_con中的第j個元素,con_scorej表示tmp_conj的在當(dāng)前語境的得分。
只要con_scorej的得分小于閾值ε,就認(rèn)為tmp_conj出現(xiàn)在當(dāng)前文本不合理,將tmp_conj從混淆集tmp_con中移除。重復(fù)這一過程,得到最終的混淆集confusion_set,將候選詞依次帶入DNNLM中計算文本得分,重排序,選出最合適的文本。
1.4 整體流程
整體流程如下。
步驟1 對輸入的音頻進(jìn)行預(yù)處理,將處理后的音頻輸入語音識別系統(tǒng)中,將音頻轉(zhuǎn)化成文字。
步驟2 將語音識別后待處理的文本輸入到糾錯檢錯系統(tǒng),對文本進(jìn)行第一次處理,去除無意義的語氣詞、口頭禪和一些使用語音識別工具常見的錯誤。
步驟3 對第一次處理后的文本進(jìn)行第二次處理,利用關(guān)鍵詞進(jìn)行檢錯糾錯,并且更新關(guān)鍵詞詞表。
步驟4 對第二次處理的結(jié)果進(jìn)行處理,然后利用NNLM對句子中的每個詞進(jìn)行打分,將分?jǐn)?shù)明顯區(qū)別于其它詞語的詞添加到“誤識別”的列表中,對誤識別的詞進(jìn)行糾錯。
2 實驗與結(jié)果分析
2.1 語義相似度詞庫
訓(xùn)練基于word2vec的語義相似度模型,需要大量語義上正確的文本。語義的基礎(chǔ)詞庫方面,本文使用了維基百科提供的中文語料和網(wǎng)上爬取的新聞?wù)Z料,共有3 G。對語料進(jìn)行預(yù)處理,使用NLPIR漢語分詞系統(tǒng)進(jìn)行分詞。調(diào)用了Gensim的word2vec模型[15]進(jìn)行訓(xùn)練,得到語義的基礎(chǔ)詞庫。
2.2 評價指標(biāo)
在對算法性能的評價中,采用了召回率(Recall,又稱查全率),準(zhǔn)確率[16](Precision,又稱查準(zhǔn)率)和F1值作為評價標(biāo)準(zhǔn),來判斷模型中算法的有效性。計算公式見式(7)、式(8)和式(9)
(7)
(8)
(9)
2.3 實 驗
2.3.1 語音識別
實驗中語音識別的音頻包括有3個來源:①現(xiàn)場教學(xué)錄音,《管理學(xué)原理》中“控制”一章的教學(xué)視頻,時長為1個小時;②遠(yuǎn)程錄播課,“學(xué)習(xí)強(qiáng)國”和“馬克思主義大講堂”中關(guān)于馬克思主義原理的內(nèi)容,時長為50 min;③有聲圖書,《錢不要存在銀行》中的第一、二章內(nèi)容,時長為1 h 10 min。語音識別工具調(diào)用了百度語音的SDK。
如表1語音識別結(jié)果所示:實驗中把誤識別詞分成3類:第一類,識別后詞語拼音沒有發(fā)現(xiàn)變化;第二類,識別后詞語長度發(fā)生變化;第三類,識別后詞語長度不變,但拼音發(fā)生變化。所選的音頻一是教師在課堂上直接錄制的,雖然語音聽上去吐字清晰,語速也適當(dāng),但從視頻中分離的音頻仍然含有各種雜音,比如老師的翻書聲、話筒的嘶嘶聲、學(xué)生的竊竊私語聲。語音識別的最終結(jié)果吞音、吐音現(xiàn)象很明顯,在誤識別的詞集中,僅有26.24%是替換錯誤,例如“就是所有的活動、所有的工作都是需要受到控制的,所有的人都需要受到控制,不是說你是領(lǐng)導(dǎo)就不受控制,你是部門主管就不受控制,那不行。”被識別成了“活動,所有的工作是需要適當(dāng)控制的,所有的人都說你是領(lǐng)導(dǎo)就不受控制,你是部門主管就不行。”。所選的第二個和第三個音頻則雖然是在安靜環(huán)境下錄制的,但也存在一定雜音。

表1 語音識別結(jié)果
2.3.2 檢錯糾錯
實驗中,為了使用核心詞擴(kuò)展關(guān)鍵詞,每個音頻都選取了5個對于它所處語境具有代表意義的詞來構(gòu)建核心詞庫,將每個核心詞代入word2vec模型中,選擇與核心詞語義最相近的詞,排序去重后構(gòu)建出關(guān)鍵詞集。例如,音頻②的核心詞與部分關(guān)鍵詞見表2。

表2 核心詞與關(guān)鍵詞
為了驗證本文所提出方法的有效性,實驗中采用了3種方法進(jìn)行對比。方法一,傳統(tǒng)2_Gram+3_Gram糾錯方法;方法二,沒有使用語境的DNNLM方法;方法三,本文提出的使用語境的DNNLM方法。實驗結(jié)果見表3。
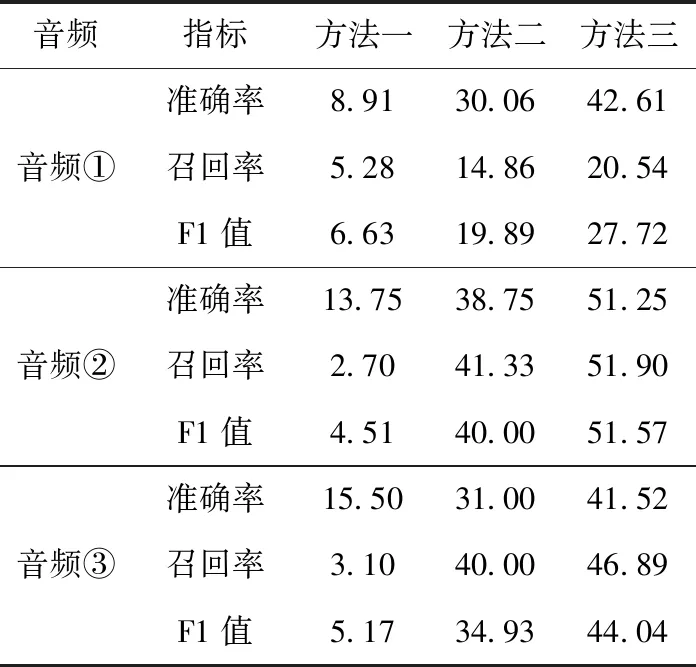
表3 3種方法的準(zhǔn)確率、召回率以及F1值/%
由表3中3種方法的準(zhǔn)確率、召回率以及F1值可知,本文提出的方法在3個測試集上的準(zhǔn)確率、召回率和F1值都要明顯優(yōu)于傳統(tǒng)N-Gram和未使用語境知識的DNNLM方法。
通過對比傳統(tǒng)N-Gram、未使用語境的DNNLM和使用語境的DNNLM得到的實驗數(shù)據(jù),驗證了本文中使用的深度語言模型在檢錯糾錯方法的明顯有效性,在此不再分析。對比使用語境與未使用語境的DNNLM方法,可以驗證語境詞對檢錯糾錯效果。對表3的實驗結(jié)果進(jìn)行計算,(方法三數(shù)據(jù)-方法二數(shù)據(jù))/方法二數(shù)據(jù),得到見表4。
使用語境的糾錯方法對比未使用語境的,其準(zhǔn)確率、召回率、F1值都有了較大提高。由表4結(jié)果可得:在使用語境知識后,測試集中語句的原始結(jié)構(gòu)被打亂,進(jìn)一步定位了句子的范圍,為后續(xù)使用深度語言模型進(jìn)行檢錯奠定了基礎(chǔ),從而提高了算法檢錯糾錯能力。
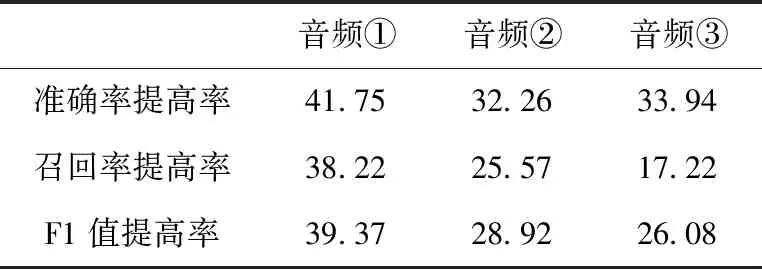
表4 使用語境與未使用語境的DNNLM實驗結(jié)果對比/%
為了驗證利用語境詞典可以提高糾錯效率,分別對使用了語境詞典和沒有使用語境詞典兩種情況的時間進(jìn)行了差值計算,時間提高的計算方法見式(10)
Time_difference=no_use_time-use_time
(10)
no_use_time表示沒有使用語境詞典查錯糾錯花費的時間,use_time表示使用了語義詞典查錯糾錯花費的時間。
實驗中隨機(jī)從測試集中選取了86個例子。圖3為有、無語境知識進(jìn)行文本糾錯的時間差,橫坐標(biāo)表示輸入句子的數(shù)量,縱坐標(biāo)表示沒有使用語境知識和使用語境知識進(jìn)行文本糾錯的時間差,單位是s。從圖3中可知,在利用DNNLM檢錯糾錯時,利用語境知識比沒有利用語境知識快了600 s。對3個測試集進(jìn)行計算效率的測試,音頻①、音頻②和音頻③的時間差分別為721 s,367 s,541 s。語境知識可以有效地提高檢錯糾錯效率,尤其在語句比較長的情況下,語境知識可以很好地縮減混淆集的規(guī)模,從而將文本糾錯的速度大幅提高。

圖3 有無語境知識的時間差
2.4 實驗結(jié)果分析
在2.3的實驗中,使用了最新的ASR技術(shù)對長音頻文件進(jìn)行語音識別后文本糾錯。實驗結(jié)果表明:對于上文中現(xiàn)場教學(xué)、遠(yuǎn)程錄播和有聲圖書音頻在ASR下產(chǎn)生的文本,本文提出的基于word2vec的糾錯方法,相比于使用傳統(tǒng)語言模型的方法和不使用語境信息的糾錯方法,不僅能夠提高糾錯的準(zhǔn)確率、召回率和F1值,還能通過縮減混淆集中詞的數(shù)量,提高計算的效率。
在實驗中,還發(fā)現(xiàn)以下3種情況。第一,說話人在講課、演講、發(fā)言時的說話方式與朗讀新聞或者文學(xué)著作時是有差別的。在識別這些偏口語化的長音頻時,在查錯階段,語言模型會查出許多本身不是錯誤,但不是很書面的詞的“錯”。第二,說話人在說話時,其語速、音調(diào)在不同時刻可能是不一樣的,致使語音識別時會因為音頻信號的突然改變而出現(xiàn)吞音、吐音的現(xiàn)象,從而使識別后的詞與原始詞存在較大差別,使得測試集中很多錯誤實驗方法檢測不出來。這為后期文本糾錯帶來了一定的挑戰(zhàn)。第三,不同地域語言發(fā)音存在差異,相同詞語在不同地域的讀音也會略有差異。
由于存在以上3種情況,即使使用最新的ASR技術(shù),識別后的文本也已經(jīng)和原始文本有了很大出入,而本文的實驗分析是采用原始文本作為正確文本的對比樣本,所以,雖然與其它方法相比,準(zhǔn)確率與召回率都有了較大提高,但其絕對值仍然比較低,需要繼續(xù)提高ASR水平。
3 結(jié)束語
本文從現(xiàn)有ASR技術(shù)出發(fā),提出一種基于word2vec的語音識別后文本糾錯方法。主要貢獻(xiàn)點:①提出使用公開深度語言模型進(jìn)行檢錯;②提出結(jié)合少量語境核心詞利用word2vec生成關(guān)鍵詞集;③提出使用word2vec縮減混淆詞集數(shù)量。實驗結(jié)果表明:本文提出的方法,對不同類型、不同領(lǐng)域的長音頻語音識別后文本糾錯是有效的,對實際應(yīng)用中長語音的語音識別有一定現(xiàn)實意義。
盡管如此,長音頻的語音識別后文本糾錯仍然有很大提升空間,今后的研究可以將個人化發(fā)音特色加入PYCN方法中,考慮個性化的混淆集生成方法。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
電子制作(2018年18期)2018-11-14 01:48:06
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
大連民族大學(xué)學(xué)報(2015年2期)2015-02-27 08:28:11
