多分支卷積塊的目標檢測算法
2020-11-23 07:34:16劉翔羽楊超宇
赤峰學院學報·自然科學版 2020年10期
劉翔羽 楊超宇

摘 要:為解決現有目標檢測算法中尺度變化帶來的檢測問題,為此設計了基于多尺度感受野特征塊,即一種并行的多分支卷積塊,共享參數但有著不同的卷積擴張率,并將其特征塊集成到SSD框架中,從而增強網絡的感受野以提高檢測精度,之后再添加通道注意力模塊,融合多個尺度相同的特征,由此得到最終的特征進入檢測層檢測。在COCO和Pascal VOC 2007數據集上測試表明,該方法在滿足一定檢測精度的同時可以達到實時的檢測效果。
關鍵詞:目標檢測;尺度變化;感受野
中圖分類號:TP391? 文獻標識碼:A? 文章編號:1673-260X(2020)10-0017-06
1 引言
近年來,深度卷積神經網絡(CNNs)[1-3]在目標檢測上取得了巨大的成功。通常,這些基于CNN的方法可以大致分為兩種類型:One-stage方法如YOLO[3]或SSD[2],直接利用前饋CNN去預測感興趣區的邊界框,而Two-stage的方法,如FasterR-CNN[1]或R-FCN[4]方法則是先生成提案,然后再加以利用提取區域特征從而利用CNN進一步細化。但是,這兩種方法的一個中心問題是如何處理尺度變化。對象實例的尺度大小可能會有不同的范圍,這阻礙了檢測,特別是那些尺度非常小或者非常大的情況。
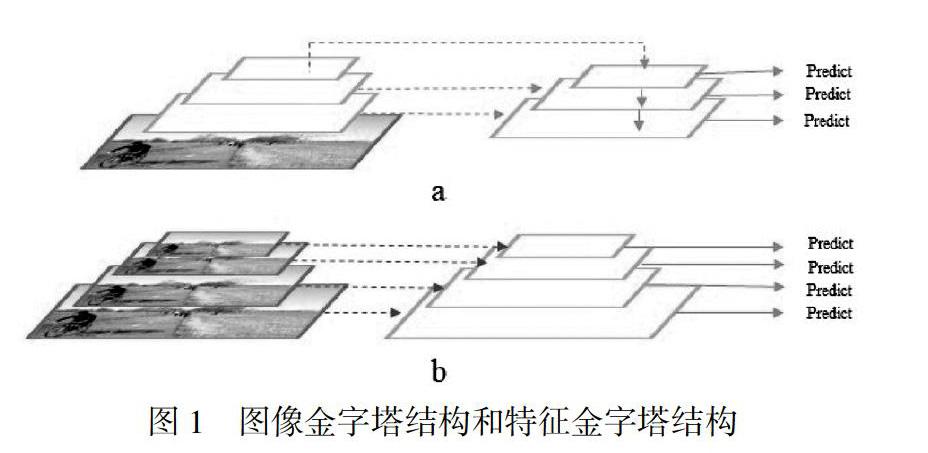
為了彌補大尺度變化,一種直觀的方法是利用多尺度圖像金字塔[5],這在基于手工制作的特征的方法[6,7]和基于深度CNN的方法中都很流行。強有力的證據[1,4]表明,深度檢測器可以受益于多尺度的訓練和測試。為了避免出現極端尺度的訓練對象,SNIP[8,9]提出了一種尺度歸一化方法,在每個圖像尺度中有選擇地訓練適當大小的對象,圖1a為圖像金字塔結構。然而,測試時間的增加使得圖像金字塔方法不太適合實際場合應用。另一個努力的方向是利用網絡內的特征金字塔來近似模擬圖像金字塔以減少計算代價,圖1b為特征金字塔結構。這個方法首先在[10]中實現,通過在特征通道層插值快速構造特征金字塔來用于目標檢測。SSD[2]利用來自不同層的多尺度特征映射,并在每個特征層檢測不同尺度的對象。為了彌補低級特征中語義的缺失,FPN[11]進一步擴展了自頂向下的通路和橫向的連接,以在高層特征中包含強語義信息。然而,不同尺度的目標區域特征是從不同層次的FPN骨干網中提取出來的,而FPN骨干網又是用不同的參數集生成的。這使得特征金字塔成為圖像金字塔的一個不令人滿意的替代品。圖像金字塔和特征金字塔方法都有著同樣的動機,即檢測模型對不同尺度對象應該有不同的感受野。盡管效率不高,但圖像金字塔充分利用了模型的表征能力,對所有對象進行變換尺度一視同仁。與之相反,特征金字塔產生了多層次的特征,從而犧牲了不同尺度上的特征一致性,這導致有效的訓練數據減少,每個尺度的過度擬合風險更高。
為解決尺度變化對目標檢測的影響,本文提出Multi-BranchReceptive-field Network(MBRnet)即多分支感受野網絡模型,通過設計多分支卷積塊生成不同尺度感受野的特征圖,并將其集成到SSD網絡結構中,以此來降低尺度變化對檢測精度的影響,提高識別率,同時添加通道注意力模塊學習不同尺度特征圖。
2 相關研究
2.1 深度學習目標檢測
基于深度學習的目標檢測方法在精度和速度上都有了很大的提高。Two-stage檢測方法[1,12,4,13,14]是主要的檢測方法之一,它首先生成一組區域建議,然后通過CNN網絡對其進行細化。在[1]中,R-CNN通過選擇性搜索生成區域建議,然后由CNN獨立地、順序地從原始圖像中對裁剪的建議區域進行分類和細化。為了減少R-CNN中特征提取的冗余計算,SPPNet[15]和Fast R-CNN[1]一次性提取整幅圖像的特征,然后分別通過空間金字塔池RoI池化層生成區域特征,RoIAlign layer進一步改進了RoI層,解決了粗糙空間量化問題。Faster R-CNN首先提出了一個統一的端到端目標檢測框架,介紹了一種與檢測網絡共享骨干網的區域建議網絡(RPN),用以取代原有的獨立的、耗時的區域建議方法。為了進一步提高FasterR-CNN的效率,R-FCN通過全卷積網絡構造位置敏感的分數圖,以避免RoI-wise頭部網絡。為了避免R-FCN中額外的大分數圖,Light-Head R-CNN使用了一個維度更小的特征圖和一個輕便的R-CNN子網來更有效地構建一個兩階段檢測器。
另一方面,One-stage檢測方法從YOLO開始被推廣,最具代表性的方法就是YOLO和SSD。它們基于整個特征圖預測多個對象的置信度和位置,這兩種檢測器都采用了輕量級的網絡架構來加速,而它們的檢測精度明顯落后于頂級的Two-stage 方法。最近更為先進的One-stage檢測器如DSSD和RetinaNet通過更深層的ResNet-101和應用一些技術,例如反卷積和Focalloss來更新它們的輕便網絡架構,這些方法在檢測效果的精度上甚至超過了一些頂級two-stage方法。然而,這種性能的提高在很大程度上犧牲了它們的速度優勢。
2.2 Receptivefield
現有一些深度學習模型為了提高檢測精度都是在以犧牲計算力為代價,增加網絡深度。在這項研究中,我們的目標是在不引起太多計算負擔的情況下提高高速單級探測器的性能。因此,人為修改網絡以加強網絡特征表征能力是替代增加網絡深度最好的方法。感受野是卷積神經網絡中重要的概念,感受野被定義為神經網絡特征所能看到的輸入圖像區域,對于感受野在CNN的相關研究在早期已經出現,最相關的是Inception[16]家族,ASPP[17]和Deformable CNN[18]。Inception塊采用具有不同內核大小的多個分支來捕獲多尺度信息。但是,所有的內核都是在同一個中心采樣的,這就需要更大的內核來達到相同的采樣覆蓋率,從而丟失了一些關鍵的細節。對于ASPP,擴展卷積改變了從中心到中心的采樣距離,但是這些特征和以前相同核大小的卷積層有著相同的分辨率,這使得在所有位置的線索都被同等對待,可能導致對象和上下文之間的混淆。Deformable CNN學習單個物體的不同分辨率,但不幸的是有著和ASPP一樣的缺點。Trident Networks[19]為了探討感受野對檢測結果的影響,對于不同尺度的物體,使用不同擴張率的空洞卷積來控制網絡的感受野,其結果表明不同尺度對象的性能受網絡接受域的影響,最適宜的感受野與物體的尺度有很強的相關性。可以得出的結論是,通過調大物體的有效感受野,從而影響小物體的表現。
2.3 Dilated convolution
空洞卷積通過在稀疏采樣位置進行卷積,以原始權重放大卷積核,從而在不增加額外成本的情況下增大了感受野的大小,因此,針對感受野的改善,我們統一采取的方法是使用空洞卷積(Dilated convolution)。空洞卷積在語義分割中得到了廣泛的應用,它可以整合大量的上下文信息。DetNet[22]設計了一個特定的檢測骨干網絡來保持空間分辨率,并使用空洞卷積放大感受野。在本文的工作中,我們使用多分支并行的架構,在分支中使用不同擴張率的空洞卷積來適應不同尺度的對象感受野。
2.4 SSD(Single shot multibox detector)結構
SSD是一種One-stage目標檢測方法,One-stage算法就是目標檢測和分類是同時完成的,其主要思路是利用CNN提取特征后,均勻地在圖片的不同位置進行密集抽樣,抽樣時可以采用不同尺度和長寬比,物體分類與預測框的回歸同時進行,整個過程只需要一步,所以其優勢是速度快。SSD采用的主干網絡是VGG網絡,但與VGG的區別是,將VGG的全連接層去除替換成卷積層并去掉所有的Dropout層和FC8層并新增了四個卷積層。整體結構如圖2所示。
盡管SSD在保持檢測性能的同時還基本達到了和深層網絡檢測器相媲美的精度,但是仍然有著尺度變化帶來的問題,在對多尺度檢測時性能并不是很好,為此,本文提出的MBRnet模型在此基礎上改進,通過設計并行的多分支卷積塊,增強網絡特征表征能力提高對尺度變化的檢測性能。
3 MBRnet模型
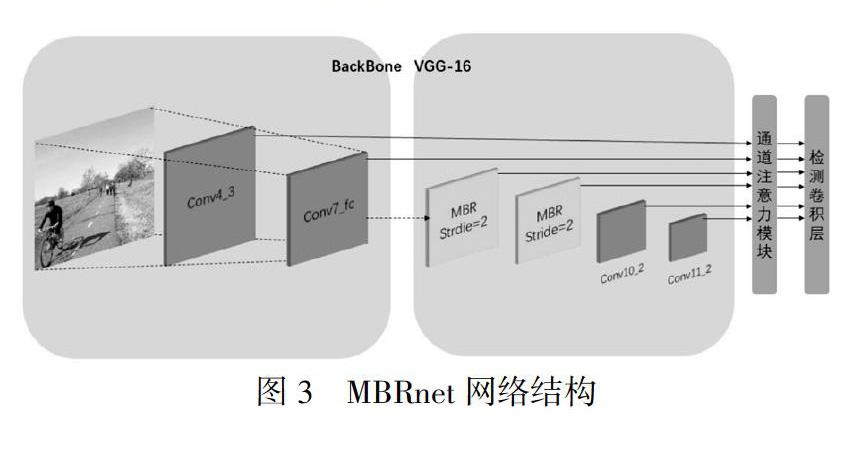
MBRnet模型是以SSD模型為基礎進行改進,融合本文所設計的多分支卷積塊,改進了從輕量級骨干網中提取的特征,并且這個多分支卷積塊是共享權重的,因此檢測速率仍舊很快。因為高層語義特征表征能力更強,因此僅在SSD網絡中的高層卷積層加入所設計的多分支卷積塊,從而得到更好特征表現的特征圖。再將得到的多尺度的特征,再添加通道注意力模塊進行融合,使融合后的特征中既包含高層特征,又有足夠的底層語義。為了使有效特征通道表現得更好,利用注意力機制為每個通道學習一個權值從而增強有效通道權重。圖3給出了模型中較為主要的層。
3.1 多分支卷積塊
本文所提出的MBRnet模型是以SSD網絡為基礎,VGG網絡為主骨干網絡,將其中的一些卷積層替換為本文所設計的多分支卷積塊,并且這些分支卷積塊與原先的卷積塊有著相同的結構但擴張率不同。以一個單獨的多分支卷積塊為例,我們在結構中應用瓶頸結構,包含三個卷積層分別由一個1×1,3×3和1×1三個卷積核,將對應的多分支卷積塊構造為3×3convs的具有不同擴張率的平行卷積塊。卷積塊的首尾采用1×1的卷積核來過濾特征圖的通道數,中間的卷積核設計為3×3步長為2的卷積塊。具有擴張率ds的擴張卷積在其連續卷積核中插入ds-1個0,從而在不增加參數和計算次數的情況下增大核的大小,具體來說,就是擴張的3×3卷積可以與核大小為3+2(ds-1)的卷積有著相同的感受野,假設當前特征圖的總步幅為s,則速率ds的擴張卷積可使網絡的感受野增加2(ds-1)s,因此,如果我們用擴張率ds修改n個conv層,則感受野可增加2(ds-1)sn。所以我們設置的三個卷積塊的擴張率大小分別為1、2、3來控制感受野大小以適應不同尺度特征圖,結構如圖4所示。并行的三個分支卷積塊可以使我們控制不同分支的感受野,得到具有適應性的感受野可以降低尺度變化帶來的負面影響。本文選擇在conv6和conv7替換為多分支塊,因為頂層特征所產生的更大的跨步會導致感受野的更大差異,而不在后面的conv8和conv9層繼續使用替換的卷積塊原因是后兩層的特征尺度過小而不再適用于卷積塊處理。
使用多分支卷積塊替代原始網絡卷積層的一個重要問題是會多出幾倍的參數,潛在的會產生過擬合問題,幸運的是我們會在不同的分支上共享相同的結構但卷積膨脹率不停,因此權重共享變得更簡單,在多分支中應用權重共享使得訓練參數的減少,并且緩解了一定程度的過擬合問題,使得檢測精度會有所定提高。共享權值的好處可以分為三點,首先,它與我們的目的保持統一,即不同尺度的物體應該以相同的表征力進行統一轉換,其次,這使得與原來的檢測相比不會產生額外的參數,最后,可以對所有來自分支的更多對象樣本訓練轉換參數,換句話說,就是在不同感受野下,對不同尺度范圍進行相同的參數訓練。
3.2 通道注意力模塊
加入多分支卷積塊之后的整個網絡,在進行特征提取之后會產生10個有效特征圖,這些特征圖即包含底層信息的特征圖,又有高層特征的特征圖,為了使最后用作檢測的特征信息更加分豐富,我們選擇引入通道注意力模塊融合多個金字塔相同尺度的特征,避免了主干網中的特征對檢測任務而言特征表示不夠充足的問題,同時特征包含了高低層語義和細節信息,這樣既利于檢測框的準確生成也利于網絡分辨目標和背景。融合的特征通道不同作用不同,為了加強通道特征表示,這里使用SEnet[20]所提出的Squeeze-and-Excitation模型,通過學習的方式自動獲取每個通道特征的重要程度融合不同通道的特征。
通道注意力模塊結構如圖5所示。這里給出具體的處理方法,多個特征金字塔中寬高為10通道數為256的特征經過concat操作融合成寬高為10通道數為256的融合特征,之后經過Attention機制增強不同通道的效果,最終用作檢測層。Attention的實現方式,將需要融合特征作為輸入進行Squeeze操作即全局平均池化使之成為寬高為1通道數保持為2560,之后進行Excitation操作,經過兩個全連接層和一個ReLU函數激活層,其中,經過第一個FC層之后的輸出維數變為原來的1/16,最后一個FC層再將其維數恢復一次來進行編碼和解碼操作同時不會產生太多計算量,最后再經過一個Sigmoid函數求得融合特征的每個通道的注意力權值。
4 實驗結果及分析
我們主要在Pascal VOC 2007和MS COCO數據集上進行了實驗,兩個數據集分別有20和80個對象類別。在VOC 2007中,如果IoU與GT(Ground Truth)的交點大于0.5,則預測邊界框為正;而在COCO中,則使用不同的閾值進行更全面的計算,評價檢測性能的指標是平均精度(mAP)。我們以Pytorch深度學習框架實現MRBnet,并利用SSD提供的開源基本設施,我們的訓練策略也主要遵循SSD包括數據擴充、難分樣本挖掘(hard negative mining)、尺度和默認框的寬高比例以及Loss函數。
模型batch-size設置為32。為了防止loss爆炸,學習率采用分布策略,初始學習率根原始SSD設置一樣10-3,此后在10、150和200個epoch時學習率每次衰減為原來的十分之一,前5個epoch的學習率從10-6逐漸升至4×10-3。參數衰減值(weight-decay)為0.0005,動量因子(momentum)為0.9。
4.1 多分支卷積塊和通道注意力模塊有效性驗證
為驗證所提出的方法有效性,我們在Pascal voc 2007數據集上分別做了多組實驗驗證了各模塊的有效性,結果如表1所示。為了更好地理解多分支卷積塊,我們以原始SSD作為對比,帶有新數據擴充的SSD300*在數據集上達到77.2%mAP,通過簡單的加入多分支卷積塊后,結果改進到79.1%mAP,獲得1.9%的提升,這說明多分支卷積塊在檢測方面是有效地。加入通道注意力模塊后,檢測結果有著0.9%的提升,同樣說明通道注意力模塊可以有效提升檢測率。當同時引入提出的這兩種模塊之后,我們的MRBnet在數據集上達到了80.1%mAP。充分證明,提出的這兩種模塊都有效提升了檢測精度。
4.2 Pascal VOC 2007實驗結果對比
表1展示了現階段各主流檢測器在Pascal VOC 2007測試集與我們的結果之間的比較。SSD300*為更新后的SSD結果,增加了[2]的數據擴充,縮小了圖像以創建更多的小示例。為了公平的比較,我們使用Pytorch-0.3.0和CUDNN V6重新實現了SSD,環境與MBRnet相同。通過整合卷積層,我們的基本模型,以80.1%的地圖性能優于SSD和YOLO,同時保持SSD300的實時速度。它甚至達到了與R-FCN相同的精度,R-FCN是兩階段框架下的高級模型。結果表明MRBnet比大多數一階段和兩階段的目標檢測系統要好,同時并以高速運行。
4.3 Microsoft COCO實驗結果對比
為了進一步驗證所提出的MRBnet模型有效性,我們在MS COCO數據集上進行了實驗。我們使用trainval35k set (train set +val35k set)進行訓練,同樣的將batch-size設置為32,我們保持原來的SSD策略,減少默認框的大小,因為COCO中的對象比PASCAL VOC中的對象小。
從下表可以看出,MRBnet在test-dev集上達到了30.8%/51.2%,基準已經大大超越了SSD 300*,甚至與擁有深度骨干網絡的R-FCN相比都有一定優勢,而檢測速率上與R-FCN相比有著優越的提升。與大模型相比MRBnet的結果略低于模型RetinaNet500(31.4%vs30.6%),但值得注意的是,RetinaNet500使用了較深的殘差網絡ResNet-101+FPN結構和新的loss使得學習的重點在困難樣本(hard example),而我們的網絡只是輕量級的VGG模型。另一方面,MRBnet檢測平均消耗只有30ms,而RetinaNet500則需要90ms。同時,可以觀察到所提出的MRBnet模型對不同尺度下的檢測精度與原SSD和Two-stage方法相比都有所提升。通過以上各方法之間結果對比,MRBnet使用的多分支卷積塊和通道注意力模塊有效提升了各類檢測精度,并在面對多尺度任務時可以出色完成檢測任務。
5 結語
目標檢測中多尺度問題一直影響檢測器的檢測精度,本文所提出的多分支卷積塊和通道注意力模塊在數據集上表現出良好的檢測效果,在VOC 2007和Microsoft COCO數據集上檢測精度較One-stage許多方法相比都有明顯提升效果,檢測精度可以與Two-stage相媲美,在實時性和準確度上成績都非常優秀。現階段卷積神經網絡仍然因網絡層數過深、訓練參數過多導致模型實用性差,需依賴高性能設備做推理,如何通過剪枝壓縮模型計算量是下一步的研究方向。
——————————
參考文獻:
〔1〕Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun.Faster R-CNN: Towards real-time object detection with regionproposal networks. In NIPS, 2015.
〔2〕Wei Liu, Dragomir Anguelov, Dumitru Erhan, ChristianSzegedy, Scott Reed, Cheng-Yang Fu, and Alexander CBerg. SSD: Single shot multibox detector. In ECCV, 2016.
〔3〕J. Redmon, S. Divvala, R. Girshick, and A. Farhadi. Youonly look once: Unified, real-time object detection. arXivpreprint arXiv:1506.02640 v4, 2015.
〔4〕Jifeng Dai, Yi Li, Kaiming He, and Jian Sun. R-FCN: Objectdetection via region-based fully convolutional networks. InNIPS, 2016.
〔5〕Edward H Adelson, Charles H Anderson, James R Bergen,Peter J Burt, and Joan M Ogden. Pyramid methods in imageprocessing. RCA engineer, 29(06):33–41, 1984.
〔6〕Navneet Dalal and Bill Triggs. Histograms of oriented gradientsfor human detection. In CVPR, 2005.
〔7〕David G Lowe. Distinctive image features from scaleinvariantkeypoints. International Journal of Computer Vision,60(02):91–110, 2004.
〔8〕Bharat Singh and Larry S Davis. An analysis of scale invariancein object detection–SNIP. In CVPR, 2018.
〔9〕Bharat Singh, Mahyar Najibi, and Larry S Davis. SNIPER:Efficient multi-scale training. In NIPS, 2018.
〔10〕Piotr Doll′ar, Ron Appel, Serge Belongie, and Pietro Perona.Fast feature pyramids for object detection. IEEETransactions on Pattern Analysis and Machine Intelligence, 36(08):1532–1545, 2014.
〔11〕Tsung-Yi Lin, Piotr Doll′ar, Ross B Girshick, Kaiming He,Bharath Hariharan, and Serge J Belongie. Feature pyramidnetworks for object detection. In CVPR, 2017.
〔12〕Ross Girshick. Fast R-CNN. In ICCV, 2015.
〔13〕Zhaowei Cai and Nuno Vasconcelos. Cascade R-CNN: Delvinginto high quality object detection. In CVPR, 2018.
〔14〕Zeming Li, Chao Peng, Gang Yu, Xiangyu Zhang, YangdongDeng, and Jian Sun. Light-head R-CNN: In defense of twostageobject detector. arXiv:1711.07264, 2017.
〔15〕Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Transactions on Pattern Analysisand Machine Intelligence, 37(09):1904–1916, 2015.
〔16〕Szegedy, C., Io_e, S., Vanhoucke, V., Alemi, A.A.: Inception-v4, inception-resnet and the impact of residual connections on learning. In: AAAI (2017).
〔17〕Chen, L.C., Papandreou, G., Schro_, F., Adam, H.: Rethinking atrous convolution for semantic image segmentation. arXiv preprint arXiv:1706.05587 (2017).
〔18〕Dai, J., et al.: Deformable convolutional networks. In: ICCV (2017).
〔19〕Li Y, Chen Y, Wang N, et al. Scale-Aware Trident Networks for Object Detection[J]. 2019.
〔20〕Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE conference on computervision and pattern recognition. 2018: 7132-7141.
〔21〕J Redmon, A Farhadi. YOLOv3: An Incremental Improvement. 2018.
〔22〕Zeming Li, Chao Peng, Gang Yu, Xiangyu Zhang, YangdongDeng, and Jian Sun. DetNet: Design backbone for object detection. In ECCV, 2018.
