基于SAC算法的機械臂控制方法與分析
2020-11-23 07:34:16王駿超
赤峰學院學報·自然科學版 2020年10期
王駿超

摘 要:機械臂作為一種常見的自動化設備,關于其控制算法的研究,一直是相關領域的熱點。本文結合目前比較熱門的人工智能理論,將強化學習方法引入到機械臂控制中,提出一種基于Soft Actor-Critic Algorithms算法的控制策略,以更好地解決三維空間下多軸機械臂的軌跡規劃問題。利于CoppeliaSim平臺,搭建仿真環境,選擇UR5機械臂作為實驗對象,進行了多組對比實驗。結果表明:基于策略熵最大化的SAC算法,提高了訓練樣本利用率,保證了學習結果的最優。在用于三維空間中多軸機械臂控制任務時,不僅可以克服傳統控制算法存在的模型依賴性高,規劃精度低的不足,并且相比一般強化學習算法,具有更快的學習效率和更高的穩定性,軌跡也更為平滑,具有很好的實用價值。
關鍵詞:機械臂控制;SAC算法;軌跡規劃;強化學習
中圖分類號:TP242? 文獻標識碼:A? 文章編號:1673-260X(2020)10-0033-07
1 引言
機械臂是一種最常見的也是最早出現的自動化設備,關于其控制算法的研究一直是業內關注的焦點[1,2]。目前比較常見的機械臂軌跡規劃方法主要包括A*算法、人工勢場法、快速擴展隨機樹算法等。A*算法是一種典型的啟發式搜索(Heuristically Search),一直受到廣泛的研究[3],但是A*算法的估價函數構造往往需要人工經驗嘗試,影響了規劃的穩定性和精度。人工勢場法具有良好的實時性[4],但會出現局部最優或振蕩不收斂的情況,在環境比較復雜或者機械臂自由度較高時,不能保證規劃的穩定性和可靠性。快速擴展隨機樹法理論簡單且容易實現[5],當參數設置合理時,可有效避免出現局部最小值的情況。但是所得到的軌跡曲線比較粗糙,往往并不是最優[6],算法的效率較低,并且重復性較差,控制效果不穩定[7]。因此,傳統的軌跡規劃算法在解決機械臂控制問題時均存在著效率低、穩定性差、模型依賴性高的缺陷。
將強化學習算法理論與機械臂運動軌跡規劃控制問題相結合,可以有效彌補和改善傳統算法存在的不足。并且,隨著研究的深入也出現了一些成功的案例,例如:Peters J等人在2006年利用強化學習方法使7自由度的SARCOS Master機械臂完成揮棒擊球的任務[8];2011年,Durrant-Whyte H利用一個桌面級機械臂和深度攝像頭[9],通過強化學習的方法使其完成了空間積木塊的堆疊任務;Mulling K和Kober J等人在2013年以學習打乒乓球為例,介紹了一種機器人通過與人的物理交互來學習的新框架[10];Gu S等人在2017年提出一種基于深度Q函數離線訓練策略的深度強化學習算法,通過多臺機器人并行學習來訓練真實的物理機器人執行復雜的三維操作任務[11]。雖然強化學習算法比較適合應用于機械臂的運動控制,但是,不同類型的強化學習算法在實際使用時還存在著一些問題:
(1)On-policy類強化學習算法的樣本效率低下。例如,目前主流的用于連續控制的深度強化學習(DRL):TRPO算法,PPO算法和A3C算法在每執行一步都需要收集新的樣本[12],因此所需的步驟數和樣本量會隨著任務復雜性增加而增加,即使是相對簡單的任務也可能需要數百萬個數據收集步驟,而具有高維度的復雜任務可能需要訓練一天甚至幾天的才能收斂,成本高昂。
(2)對于基于Q-learning(QL)類的強化學習算法來說,提高樣本效率,復用先前經驗是相對容易的[13]。但是,其離散的狀態空間在處理連續控制問題時可能會導致維數災難(Curse of Dimensionality)。通過連續狀態離散化的方式進行機械臂的動作控制,往往穩定性和收斂性都無法保證。
(3)另一類Off-policy算法,如深度確定性策略梯度算法(deep policy gradient, DDPG)[14],相比QL算法更適合解決連續控制問題,相比PPO等算法也有更高效的樣本學習。但是,DDPG算法在面對高維任務時,Actor網絡與Q網絡的相互影響造成了算法的脆弱性和超參數敏感,這嚴重限制了在現實任務中的適用性,甚至需要依靠精確的建模,才能實現對真實機械臂的有效控制[15]。
針對目前常用算法在用于多軸機械臂控制時存在的一些不足和問題,本文提出了一種基于柔性角色行為評價算法(Soft Actor-Critic Algorithms,SAC)[16]的機械臂控制方法,并且在CoppeliaSim平臺上搭建了UR5多軸機械臂的仿真環境,進行多組對比實驗予以驗證。
2 SAC算法
Soft Actor-Critic Algorithms是一種基于最大化熵理論的無模型深度學習算法,同時具備了Actor-Critic算法框架。不同于確定性策略(Deterministic Policy)算法,SAC算法的主要特征是策略隨機化(Stochastic Policy)。經過訓練,盡可能地在收益和熵(即策略的隨機性)之間取得最大化平衡。這就是使探索與決策的關系非常密切:熵的增加會使智能體傾向于探索更多的情況,從而可以加快后續的學習速度。同時策略的隨機性還可以避免出現過早收斂到某個局部最優值。
2.1 熵最大策略
最大熵原理最早是在信息論中提出的[17],目的是為了讓獲取的數據足夠隨機分散。這樣的思想同樣可以用在強化學習中。使用最大熵原理的強化學習,除了要實現價值最大的目標,還要求策略?仔選擇的每一次動作的熵(Entropy)最大,如式(1),其中st,at為t時刻的狀態和動作,R為得到的獎勵,H為熵函數,?琢為溫度參數,用于控制優化目標更關注獎勵還是熵。
3 實驗部分
3.1 實驗仿真平臺
選用CoppeliaSim進行實驗仿真。CoppeliaSim具有完善的集成開發環境,是非常理想的機器人仿真建模的工具。用于實驗的機械臂為Universal Robots公司的優傲機械臂UR5。UR5是一種高自由度的機械臂,更能驗證本文算法在多軸復雜的真實機械臂中的性能表現。其機械臂坐標系如圖3,D-H參數如表1。
根據UR5的數據,在仿真平臺CoppeliaSim中配置出UR5的3D可視模型,如圖4。
3.2 實驗設計
選用UR5的第一關節Joint 1到第四關節Joint 4的角度作為控制變量,關節Joint 5和Joint 6是控制末端執行控制器精細位姿,在實驗過程中固定角度,通過其他四個關節角度改變來實現控制。SAC算法狀態輸入量為機械臂UR5的四個關節角度以及目標點坐標,即:
3.3 對比實驗一
在上述仿真環境中,驗證SAC算法用于機械臂控制的性能表現,并用深度確定性策略梯度算法(DDPG)作為對比實驗。
DDPG算法是常見的用于解決連續空間規劃問題的強化學習算法。與SAC算法最大的不同,是其策略的更新梯度是固定的。并且由于結合了DQN算法的思想,DDPG算法中具有四個網絡(現實策略網絡、目標策略網絡、現實Q網絡、目標Q網絡)。為了確保實驗結果的可靠性,DDPG算法的參數設置與SAC算法基本保持相同。
最大訓練回合數設置為3000,每回合最大步數為100,當超過100步仍未到達目標點,則結束此次訓練回合,訓練流程圖如圖6:
選擇平均獎勵變化和成功率變化兩個指標作為對比標準。
圖7是機械臂UR5在有障礙物的環境中,分別使用SAC算法和DDPG算法得到平均獎勵曲線。圖中綠色點線圖代表SAC算法,黃色點線圖代表DDPG算法。圖7可以反映出UR5經過兩種強化學習算法訓練后,執行每步動作得到的平均獎勵的變化情況。
從圖7可以看出,SAC算法和DDPG算法訓練后期均穩定在-10左右,說明兩個算法在機械臂避障實驗中均可以有效地控制UR5機械臂到達目標點,但是DDPG算法直到14000步左右平均獎勵值的變化才趨于穩定,慢于SAC算法,說明在三維空間的規劃任務中,DDPG算法的樣本效率和速度是低于SAC算法的。同時,DDPG的平均獎勵曲線變化的幅度是大于SAC算法的,為了保證對比實驗的客觀可靠,DDPG直接采用了與SAC算法基本一致的參數設置,而沒有進行專門的調參,可見在算法穩定性方面,DDPG低于SAC算法。
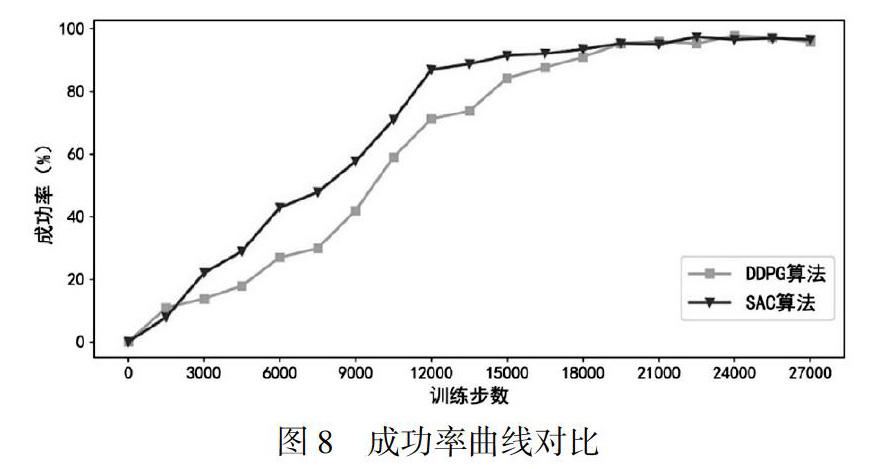
按照閾值條件:||Parm-Ptarget||≤2.5時機械臂規劃成功,統計出基于SAC算法和DDPG算法的機械臂UR5的避障控制成功率曲線。圖8中,綠色帶倒三角曲線是SAC算法的成功率,黃色帶正方形曲線是DDPG算法的成功率。
圖8中SAC算法和DDPG算法的成功率曲線與平均獎勵曲線的趨勢基本相同。SAC算法在18000步左右達到了96%以上的成功率,相比較之下,DDPG算法在20000步之后成功率才穩定在相同水平。從成功率變化曲線的對比中,也可以說明SAC算法的速度是快于DDPG算法的。
3.4 對比實驗二
在相同的仿真環境中,選擇傳統算法中的RRTstar算法,比較在相同環境下兩種算法的規劃效果。RRTstar算法是一種應用比較廣泛的避障算法。相比較一般的RRT算法,具有漸進最優性,而且規劃速度也比較快。RRTstar作為一種基于隨機樹策略的算法,與SAC算法原理上是不同的。因此,不同于第一組對比實驗,在本組實驗對比中,分別選擇機械臂軌跡規劃路徑代價(長度/用時)和關節角度變化曲線作為兩個對比標準。
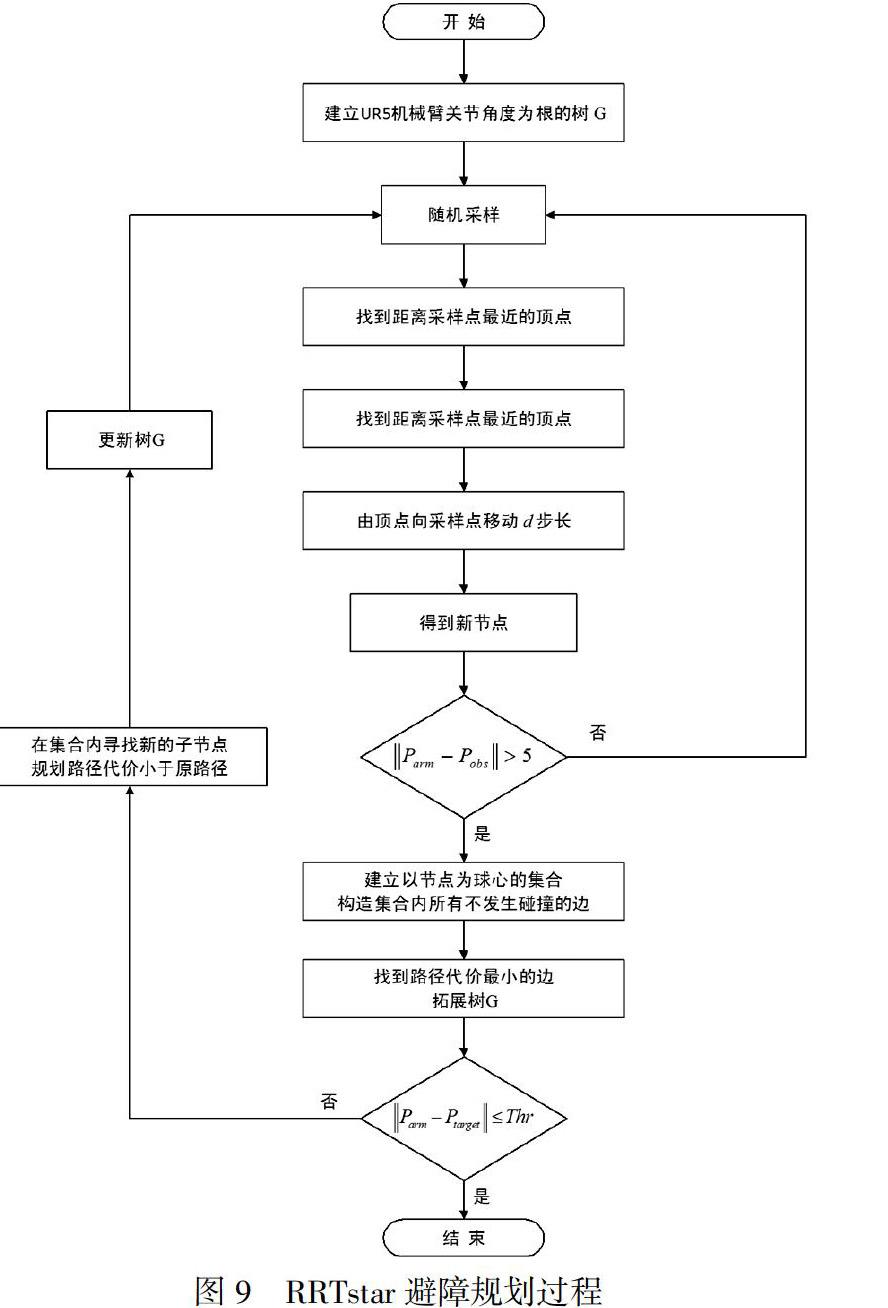
RRTstar避障算法的規劃流程示意圖如圖9。
表4是RRTstar算法的參數設置,迭代次數超過1000次則此次規劃任務失敗;γ是常量系數,影響每次取球狀節點集合的半徑大小;d是規劃空間維度;δ是步長(單位cm)。
首先把RRTstar算法運行十次,統計其規劃的結果,規劃路徑代價用軌跡長度和規劃用時表示。
作為比較,在同一環境中使用SAC算法進行避障控制實驗。為了保證對比實驗的可靠性,初始化SAC算法的經驗重播緩沖區,再次進行訓練。SAC算法的其他參數設置不變,最大訓練回合數設置為3000,每回合最大步數為100。訓練結束后,用所得的模型進行UR5機械臂的避障規劃。同樣規劃十次,統計其結果,如表6。
從表7和圖10對比中可得,在十次規劃中,相比于RRTstar算法,使用SAC算法得到的軌跡路徑長度比較穩定,與平均長度接近,并且平均長度更小。SAC算法規劃的平均用時只有7.9秒,遠遠小于RRTstar算法39.48秒的平均時間。此外,RRTstar的規劃用時的波動幅度較大,說明在控制機械臂執行同一任務時,基于隨機策略的RRTstar算法的重復穩定性較差。十次規劃中,SAC算法均可以使機械臂成功到達目標點,成功率高于RRTstar算法。綜上所述,從規劃路徑長度,規劃用時以及成功率三個方面的對比,均說明了SAC算法相比于RRTstar算法性能更加優越,更適用于多軸機械臂三維空間的避障控制。
圖11展示了從RRTstar算法和SAC算法十次規劃中,各取一次的規劃軌跡對比圖。圖12是RRT算法和SAC算法控制UR5機械臂進行避障時的關節角度變化對比圖。
圖11表明:二者的規劃軌跡的長度比較接近,最后到達目標點存在一定的誤差,但是都達到了規劃要求。但是相比于RRTstar算法,SAC算法的規劃軌跡更加平滑,角度變化的幅度和突變較小。圖12表明:在分別使用RRTstar算法和SAC算法規劃時,UR5機械臂的關節角度變化范圍相近,但是SAC算法的角度變化更加平緩,突變較少。這說明RRTstar算法用于機械臂控制時存在著規劃路徑粗糙的短板,而SAC算法規劃路徑更加平滑。這在應用于真實機械臂控制時,能夠減少機械臂的自身磨損,延長使用壽命,有利于提高規劃控制的經濟性和安全性。
4 結論
本文通過研究分析機械臂控制模型和強化學習的相關理論;結合機械臂控制的特點和常見控制算法存在的不足,提出了基于柔性角色行為評價算法(Soft Actor-Critic Algorithms,SAC)的機械臂控制方法。利用SAC算法處理連續動作與狀態空間任務的優越性能,提高了訓練的效率和穩定性。為了驗證本文方法用于真實機械臂規劃控制的實際效果,選用CoppeliaSim作為實驗平臺,UR5機械臂作為實驗對象。比較了SAC算法與DDPG算法、RRTstar算法在相同環境下的性能表現。選取不同的評價指標均表明SAC算法相比于DDPG算法速度更快,穩定性更高;相比RRTstar算法規劃的軌跡更加平滑,機械臂關節角度不會突變,并且速度和成功率更高。由此說明,本文提出的基于SAC算法的機械臂控制方法可以有效彌補傳統控制算法的不足,具有一定的自身優勢和較好的應用價值。
參考文獻:
〔1〕馮旭,宋明星,倪笑宇,等.工業機器人發展綜述[J].科技創新與應用,2019,9(24).
〔2〕Schaal, Stefan. The new robotics towards human-centered machines[J]. Hfsp Journal, 2007, 1(02):115-126.
〔3〕Schaal, Stefan. The new robotics towards human-centered machines[J]. Hfsp Journal, 2007, 1(02):115-126.
〔4〕Khatib O. Real-Time Obstacle Avoidance for Manipulators and Mobile Robots[J]. 1986.
〔5〕Lavalle S M. Rapidly-Exploring Random Trees: A New Tool for Path Planning[J]. Algorithmic & Computational Robotics New Directions, 1998: 293-308.
〔6〕Lindemann S R, Lavalle S M. Current issues in sampling-based motion planning[J]. Springer Tracts in Advanced Robotics, 2005, 15: 36-54.
〔7〕王濱,金明河,謝宗武,等.基于啟發式的快速擴展隨機樹路徑規劃算法[J].機械制造,2007,58(12):13-16.
〔8〕Peters J, Schaal S. Policy Gradient Methods for Robotics[C]// Intelligent Robots and Systems, 2006 IEEE/RSJ International Conference on. IEEE, 2006.
〔9〕Durrant-Whyte H, Roy N, Abbeel P. Learning to Control a Low-Cost Manipulator Using Data-Efficient Reinforcement Learning[C]// Robotics: Science and Systems VII. MIT Press, 2011.
〔10〕Mulling K, Kober J, Kroemer O, et al. Learning to select and generalize striking movements in robot table tennis[J]. The International Journal of Robotics Research, 2013, 32(03): 263-279.
〔11〕Gu S, Holly E, Lillicrap T, et al. Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates[C]// 2017 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2017.
〔12〕Schulman, John, Wolski, Filip, et al. Proximal Policy Optimization Algorithms[J].2017.
〔13〕Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., Graves, A., Riedmiller, M., Fidjeland, A. K., Ostrovski, G., et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529-533.
〔14〕Lillicrap T P, Hunt J J, Pritzel A, et al. Continuous control with deep reinforcement learning[J]. computer science, 2015, 8(06): A187.
〔15〕Duan Y, Chen X, Houthooft R, et al. Benchmarking Deep Reinforcement Learning for Continuous Control[J]. 2016.
〔16〕Haarnoja, Tuomas, Zhou, Aurick, Hartikainen, Kristian, et al. Soft Actor-Critic Algorithms and Applications[J]. arXiv preprint arXiv, 2018:1812.05905.
〔17〕馮尚友.信息熵與最大熵原理[J].水利電力科技,1995,24(03):26-31.
