淺談人工神經網絡
2020-11-28 07:39:56趙鈺
西部論叢 2020年11期
關鍵詞:計算機
趙鈺


1 引言
1.1 背景
如上圖所示,分別是夜景、狗、百合花的照片,我們可以快速準確的識別出來,并且通常不會出錯。但是對于計算機而言,并不會很容易的識別出,甚至會非常困難。
然而,計算機可以在1秒內計算出超級復雜的數字,而我們口算兩位數乘法都會比較困難。
因此,對比計算機與人類,發現:
就此發現,我們可以推測圖像的識別需要人類的智慧才可以解決,這才是人工智能的精髓。因此,我們就要找到新的算法賦予計算機,使他可以解決那些需要用到人類智慧的問題。
1.2 目的。1、識別手寫數字,比如說書寫者由于字跡潦草寫出的“4”、“9”分不清,利用神經網絡分析具體是哪一個數字。2、識別長文本,比如說打開一個超級多數據的文本,其中的數據用逗號隔開,我們無法識別數字的排列規律以及數據個數,因此要使用計算機識別。并給出其排列規律等需求。
2 建立神經網絡
2.1 神經元。神經元是生物大腦中最基本的單位。他的傳遞方式就是將電信號從這一端傳遞到另一端,再沿著軸突,將電信號從這一樹突傳遞到另一樹突。這就實現了將這個信號從這一神經元傳遞到下一個神經元。經過這樣一個個過程的傳遞,我們便有了感知聲、光、電、熱等信號的能力,我們便有了視覺、嗅覺、聽覺、觸覺等。而我們的大腦主要就是由神經元構成的,大約有1000億個神經元。
2.2 權重。權重最重要的作用就是可以調節每一個節點之間連接的強度。權重越大即這兩個節點之間的連接就越強,也就是說要放大信號;權重越小,即兩個節點之間的連接就越弱,也就說要縮小信號。
2.3 搭建神經網絡。搭建一個神經網絡,至少需要以下三個函數:(1)初始化函數——設置節點的數量,包括輸入層節點、隱藏層節點、輸出層節點(2)訓練——讓機器學習給定的訓練集樣本,并將所給出的權重進行優化(3)查詢——給定一個輸入值,得出一個輸出值。
3 手寫識別
我們將數據文件保存在“mnist_dataset”文件夾中,下面進行讀取數據并展示。
Data_file=open(“mnist_dataset/mnist_train_100.csv”,r)? (打開文件<路徑>,并且是只讀的模式)
Data_list=data_file.readlines() (讀取文件)
Data_file.close (關閉和清理文件)
在anaconda中跑一下,得出:
由上圖可觀察到,這是一個長度為100的列表,第一個數字是“5”,這可以看作是一個標簽。同時我們可以看到其他的784個數字是構成圖像像素的顏色值。且顏色值的范圍為[0,255]。
下面我們就要將使用上圖所示的數組進行繪圖:
Import numpy
Import matplotlib。Pyplot
%matplotlib inline
All_values=data_list[0].split(‘,)? 將長的字符串進行拆分,并且打印出來
Image_array=numpy.asfarray(all_values[1:]).reshape((28,28))? ?要使用除了列表中的第一個數字外的所有數字,并且將這些字符串都轉化為實數,而且要創建數組。將這個數組美經過28個數字就折返一次,最終形成一個28*28的正方形矩陣
Matplotlib.pyplot.imshow(image_array,cmap=Grey,interpolation=None)? ?將輸出的畫布顏色調為灰色,以便更好地展示結果。
3.1 MNIST訓練數據
首要的是要將顏色的值進行整改,我們將較大的數字進行縮放,將[0,255]這一范圍縮放為[0.01,1.0],最低點選為0.01是為了避免最小值為0最終造成權重自動更新失敗。所以要將[0,255]范圍內的數值同時除以255,得到[0,1],再乘以0.99,將范圍變到[0,0.99],最后再加上0.01,最終得到范圍是[0.01,1.0]。
Scaled_input=(numpy.asfarray(all_values[1:])/255.0*0.99)+0.01
Print(scaled_input)
對于激活函數而言,若輸出值為0或1時,會是權重達到飽和狀態,使激活函數失效,因此我們將用0.01和0.99去替代0和1,這樣“5”的數組應該由原來的[0,0,0,0,0,1,0,0,0,0]顯示為[0.01,0.01,0.01,0.01,0.01,0.99,0.01,0.01,0.01,0.01]。構建目標矩陣:
# output nodes is 10 (example)
Onodes=10
Targets=numpy.zeros(onodes)+0.01
Targets[int(all_values[0])]=0.99
3.2測試網絡。我們想要測試之前訓練的效果,獲取數據集:
# load the mnist test data CSV file into a list
Test_data_file=open(“mnist_dataset/mnist_test_10.csv”,r)
Test_data_list=test_data_file.readlines()
Test_data_file.close()
最后得出準確率為60%。
3.3 完整訓練集。下面我們將進行完整的訓練,用60000個訓練樣本來完成三層神經網絡的訓練。
如上圖所示,我們可以觀察到準確率高達了94.73%,由此我們可以認為其準確率已經是非常高的了!
4 模型改進
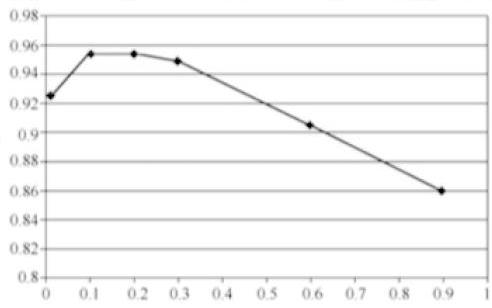
4.1 調整學習率。我們想提高準確率,首先想到的是調整學習率。我們先將學習率翻倍成0.6,但得到的結果不盡人意,最終準確率只有90.47%。于是我們決定降低學習率,將其值設為0.1,通過計算得到準確率為95.23%。再一次降低學習率至0.01,發現準確率下降至92.41%。因此,我們推測學習率對準確率的影響是一條變化的曲線,是存在峰值的。因此,繪制了學習率與準確率的圖像:
根據上圖發現,學習率大概在0.2的時候,其準確率最高。
4.2 改變隱藏層節點數量。我們還可以通過改變隱藏層節點的數目來改變整個神經網絡的形狀,從而也達到提高準確率的目的。
之前上文中我們所運用到的隱藏層的節點全部為100個,接下來就要減少、以及增加節點,來觀察準確率的變化。
經過計算統計,若隱藏節點的個數為5個時,準確率大約為70%,而增加到200個節點時,準確率增加到97.62%.繪制圖像如下:
觀察上圖可以看出,隱藏節點大約在200個時,便可使準確率達到最高。
5 結論
訓練神經網絡進行手寫識別,通過進行調整學習率和隱藏層節點個數可以大幅度提升識別的準確率。通過三層神經網絡與數據集不斷計算,使神經網絡具有學習功能。使用不同的激活函數也會有不同的效果。
猜你喜歡
小學科學(學生版)(2021年7期)2021-07-28 06:44:42
趣味(數學)(2020年9期)2020-06-09 05:35:08
鐵道通信信號(2020年12期)2020-03-29 06:21:58
科技傳播(2019年22期)2020-01-14 03:06:34
科技傳播(2019年22期)2020-01-14 03:06:30
消費導刊(2017年20期)2018-01-03 06:26:40
電子制作(2017年14期)2017-12-18 07:08:10
辦公自動化(2016年18期)2016-08-20 12:50:22
鐵道通信信號(2016年11期)2016-06-01 12:11:32
鐵道通信信號(2016年3期)2016-06-01 12:10:18
