結合卷積神經網絡與哈希編碼的圖像檢索方法
2020-12-07 06:12:45吳振宇邱奕敏周纖
現代電子技術 2020年21期
吳振宇 邱奕敏 周纖


摘? 要: 為了提高圖像檢索的精度與速度,提出一種卷積神經網絡與哈希方法結合的圖像檢索算法。該方法在深度殘差網絡的基礎上構建了一個網絡模型,將隨機選取成對的圖像(相似/不相似)作為訓練輸入,使用曼哈頓距離作為損失函數,并添加了一個二值約束正則項,促使訓練好的網絡輸出為類二值碼,再將類二值碼閾值化為二值碼,最后用于圖像檢索。在Caltech256數據集和MNIST數據集上的實驗結果顯示,文中方法的檢索性能優于其他現有方法。
關鍵詞: 圖像檢索; 卷積神經網絡; 哈希編碼; 網絡模型; 圖片對生成; 網絡訓練
中圖分類號: TN911.7?34; TP391? ? ? ? ? ? ? ? ? ?文獻標識碼: A? ? ? ? ? ? ? ? ? ? 文章編號: 1004?373X(2020)21?0021?06
Image retrieval method combining convolution neural network and Hash coding
WU Zhenyu, QIU Yimin, ZHOU Qian
(School of Information Science and Engineering, Wuhan University of Science and Technology, Wuhan 430081, China)
Abstract:In order to improve the precision and speed of image retrieval, an image retrieval algorithm combining convolutional neural network and Hash method is proposed in this paper. On the basis of the depth residual network, a network model is built with the proposed method, which can select pairs of images (similar/dissimilar) randomly as a training input. The Manhattan distance is taken as a loss function, and a binary constraint regularization is added to prompt the trained network output as approximate binary code. Then the approximate binary code threshold is converted into binary code for image retrieval. The results of experimental on Caltech256 data set and MNIST data set show that the retrieval performance of this method is better than other existing methods.
Keywords: image retrieval; convolutional neural network; Hash coding; network model; image pair generation; network training
0? 引? 言
隨著網絡多媒體的發展,互聯網上的圖片越來越多,這使得根據不同用戶要求查找相似圖片變得極其困難。而圖像檢索是從數據庫中找到與所查詢圖像相似的圖像,目前常用的方法是基于內容的圖像檢索(Content?Based Image Retrieval,CBIR)[1]。CBIR通過提取查詢圖像的特征,并將其與數據庫中的圖像特征相比較,然后將圖像按照相似度從高到低排序并返回給用戶。圖像相似度是指人類對圖像內容理解的差異,這種差異難以通過圖像的低層視覺特征反映出來。因此,基于深度學習的哈希檢索方法被學者們廣泛研究[2]。
深度學習(Deep Learning)是一種利用含有多個隱層的深度神經網絡實現學習任務的機器學習(Machine Learning)方法[3]。隨著深度學習的研究與發展,研究人員發現,經過大量帶標簽樣本訓練與學習后的卷積神經網絡(Convolutional Neural Network,CNN),有能力抽象出高層的語義特征[4]。然而,傳統的卷積神經網絡的訓練準則是針對圖像分類任務設計的,直接用于圖像檢索任務難以取得好的效果[5]。因此,針對圖像檢索任務設計特有的訓練準則,是提高檢索準確率的一種有效途徑。
雖然CNN能夠提取圖像的高層語義,但是其提取出的特征維度往往高達幾千維,直接計算這些高維特征的相似度進行圖像檢索需要耗費大量時間。因此,學者們提出了利用哈希方法[6?7]進行圖像檢索。哈希方法將圖像特征映射成緊湊的二進制代碼,近似地保留原始空間中的數據結構。由于圖像使用二進制代碼而不是實值特征來表示,因此可以大大減少搜索的時間和內存開銷。但是,哈希方法直接對圖像特征進行特征編碼,然后對特征編碼排序檢索,并沒有將相似圖像檢索的結果反饋到網絡參數的學習之中[8]。因此,如何將CNN提取特征的方法與哈希方法相結合,即在提高檢索精度的同時減少檢索時間,也是圖像檢索研究的一個關鍵問題。
為了解決傳統的卷積神經網絡直接應用于圖像檢索任務易導致檢索準確率低的問題,本文提出了一種結合深度殘差網絡(Deep Residual Network,ResNet)與哈希方法的圖像檢索算法——Residual Network Hashing(RNH)。本文在ResNet網絡模型的基礎上,通過改進損失函數和添加哈希層,設計了一個新的網絡模型ResNetH36。訓練時網絡輸入是成對的圖片,圖片對是否相似作為輸入的標簽,輸出是類二值碼。改進的損失函數采用曼哈頓距離,訓練集采用隨機選取的圖片對,以期能縮短網絡的訓練時間。為了能夠將網絡的輸出直接用于圖像檢索,在利用CNN特征提高檢索精度的同時能夠減少檢索時間,本文方法給該損失函數加上一個二值約束正則項約束網絡輸出的范圍,以便將輸出閾值化為二值碼。
1? 相關工作
傳統的圖像檢索算法[6?7]一般是將SIFT,GIST等人工特征通過哈希函數編譯成二值碼。這些哈希方法雖然取得了一定的效果,但是由于使用的是人工特征,這些特征只能反映圖像的底層視覺特征,無法捕獲真實數據中外觀劇烈變化時的高層語義特征,從而限制了得到的二值碼的檢索精度。
為了有效的進行圖像檢索,一些基于CNN的哈希方法被提出。文獻[9]提出了一種CNN與哈希方法相結合的算法CNNH,CNNH先通過對相似矩陣分解,得到圖像的二值碼,將其作為圖像的標簽訓練網絡,利用網絡擬合二值碼用于圖像檢索。雖然利用了卷積神經網絡,但是該方法沒有實現端到端的訓練。文獻[10]在CNNH方法上做出改進,提出了CNNH+方法,CNNH+用一張樣本圖片,一張相似圖片,一張不相似圖片共三張構成三元組訓練網絡,能夠同時學習哈希函數和圖像特征,但是三元組的選取質量直接影響最終網絡的性能,且利用三元組訓練網絡的過程比較麻煩。文獻[11]提出一種可以同時學習哈希函數和圖像特征的算法DSLH,DSLH將圖像原本的標簽作為監督信息。不需要進行三元組的挑選,減少了工作量。但是該方法量化時采用的是sigmoid函數,雖然能將網絡的輸出壓縮為類二值碼,但是會增加量化誤差。文獻[12]也提出一種利用深度卷積網絡框架同時學習特征和哈希函數的算法DSH,該方法利用圖片對作為輸入,將兩張圖片是否相似作為標簽,很好地描述了網絡所需要擬合的特征空間,使得最終的二值碼能夠保持原始圖像的相似性,避免了挑選三元組的過程,但是該方法的損失函數采用的是歐氏距離,且所用的在線生成圖片對方法將所有的樣本兩兩組合生成圖片對,使得網絡的訓練時間較長。
針對現有方法使用歐氏距離作為損失函數,同時訓練時用到了所有的圖片對,會使網絡訓練時間較長,且量化時采用sigmoid,tanh等約束函數會使量化誤差較大,導致檢索精度不高,本文提出了結合深度殘差網絡與哈希方法的圖像檢索算法RNH。首先,該方法的損失函數采用曼哈頓距離(Manhattan Distance),同時參考原始數據集的樣本數量隨機選取圖片對,減少了訓練網絡需要的時間。其次,通過給該損失函數加上一個二值約束正則項,使網絡輸出為類二值碼以便閾值化為二值碼,減少了量化帶來的誤差,提升了檢索精度。
2? 本文方法
為了提高卷積神經網絡應用于圖像檢索問題時的檢索精度,本文提出了一種結合深度殘差網絡與哈希方法的圖像檢索算法RNH。由于曼哈頓距離計算簡單,且用于圖像檢索問題時衡量特征數據之間相似性效果較好,所以本文損失函數采用曼哈頓距離。同時參考原始數據集數量隨機選取圖片對,以期能加快網絡的訓練速度。然后通過為損失函數添加二值約束正則項,減少量化誤差,提高檢索精度。本文方法RNH構建的圖像檢索模型如圖1所示。
首先將圖像輸入到通過本文方法訓練好的ResNetH36網絡模型中,圖像經過ResNet網絡得到其特征向量,然后經過哈希層得到類二值碼,最后閾值化得到最終的二值碼。當輸入任意一張查詢圖像時,經過上述步驟,能得到圖像的二值碼。然后計算該二值碼與數據庫中圖像的二值碼之間的漢明距離。距離按照從小到大排列返回圖像,距離越近代表該圖像與查詢圖像越相似。
2.1? ResNetH36網絡模型
網絡深度對深度學習的性能有顯著影響,但是當網絡深度加深時網絡會變得難以訓練,產生退化問題,針對這個問題,文獻[13]提出了ResNet。如圖2所示通過恒等映射(Identity Mapping)連接的殘差模塊(Residual Block)結構是ResNet的主要特點,該結構將原本網絡所需要擬合的映射[H(x)]轉換成[F(x)+x]。雖然兩種映射表達效果一樣,但是對[F(x)]進行擬合要比對[H(x)]進行擬合簡單得多。通過捷徑連接(Short Connection)將網絡的輸入和輸出疊加,就可以構成殘差模塊,通過捷徑連接疊加的卷積層不會為網絡帶來額外的參數和計算量,并且可以解決網絡層數加深時導致的退化問題,這就是ResNet比以往的網絡更深的原因。為了將ResNet的優點應用到圖像檢索任務中,本文在ResNet34的基礎上添加了一個哈希層和閾值化層,作為本文方法的網絡模型,用以提取圖像的深層特征并生成圖像檢索需要的二值碼,網絡結構如圖3所示。
圖3中從上至下省略號處分別省略了4層、6層、10層、4層卷積層,閾值化層的作用是將網絡的輸出通過式(1)閾值化為二值碼用于圖像檢索,是無參數層,因此不參加網絡的訓練,也在圖中省略。各省略處卷積層參數與省略號前一層卷積層參數相同,且每兩層有一個捷徑連接,構成殘差塊。模型由36層組成,其中,前34個卷積層的結構、參數與ResNet34相同,后面添加了一個哈希層與閾值化層。每個卷積層里面的參數依次表示卷積核局部感受野的大小和個數,“pool”表示最大池化,“avg pool”表示平均池化。第35層中的“[k]”表示二值碼的長度。閾值化層通過式(1)將35層中得到的[k]維類二值碼閾值化為二值碼,用于圖像檢索。
[Hj=1,? ? kj≥0.50,? ? otherwise,? ? j=1,2,…,k] (1)
式中:[kj]表示哈希層生成的[k]維類二值碼的第[j]位;[Hj]表示結果閾值化后的二值碼的第[j]位。
2.2? 損失函數
假設[Ω]是RGB空間,那么網絡學習的目標是學習一個從[Ω]到[k]維二值編碼空間的映射,即[F]:[Ω→{+1,-1}k],同時保持圖像的相似性。因此,相似的圖像編碼應該盡可能的接近,而不同圖像的編碼應該盡可能的遠。基于這個目標,設計的損失函數需要將相似的圖像編碼拉到一起,將不同的圖像編碼相互推開。
具體的說,假設有一對圖像[I1],[I2∈Ω],其對應的輸出[b1],[b2∈{+1,-1}k],定義[y=0]表示它們相似,[y=1]表示不相似。那么可以將損失函數定義為:
[l(b1,b2,y)=12(1-y)Dh(b1,b2)+12y max(m-Dh(b1,b2),0)] (2)
[s.t.? ?bj∈{+1,-1}k,? ? j∈{1,2}]
式中[Dh(· ,·)]表示兩個二值碼之間的漢明距離;[m>0]為邊緣閾值參數,為了讓不相似的圖像之間距離足夠遠,令[m=2k]。損失函數的第一項用于懲罰相似的圖像映射到不同的二值碼,第二項通過閾值[m],保證不相似的圖像得到的二值碼之間的距離大于[m],即讓不相似的圖像之間的距離盡可能遠。
假設有[N]個圖像對[{(Ii,1,Ii,2,yi)i=1,2,…,N}],那么整體的損失函數為:
[L=i=1Nl(bi,1,bi,2,yi)s.t.? ?bi,j∈{+1,-1}k,? ? i∈{1,2,…,N},j∈{1,2}] (3)
由于[Dh(· ,·)]不可以直接求導,而網絡的訓練要求損失函數是可導的,所以為了符合后續網絡訓練的要求,需要將其轉換成一個可以求導的距離函數,同時為了保證網絡的輸出能夠滿足約束條件與便于將其閾值化為二值碼,需要添加一個正則化項。具體來說,將式(2)中的漢明距離替換為曼哈頓距離,并增加一個[L1]正則項來替換二值約束。相較于使用歐氏距離等其他距離函數,曼哈頓距離具有更少的計算量可以減少網絡訓練時間,相較于使用tanh,sigmoid等量化函數約束網絡輸出,使用[L1]正則項能夠減少量化誤差,提高檢索準確率。最終可以得到網絡的損失函數為:
[Lr=i=1N12(1-yi)b1-b21+12yi max(m-b1-b21,0)+αbi,1-11+bi,2-11]? ? ?(4)
式中:[?1]表示[L1]范數;[α]為該正則化項的權重因子。求解式(4)采用批量梯度下降算法,計算[b1]和[b2]的偏導數時,使用反向傳播算法。
2.3? 訓練細節
批量梯度下降法能夠加快網絡的收斂速度[14],因此本文使用批量梯度下降法對ResNetH36網絡模型進行訓練學習。訓練時批量大小設為256,學習率從0.1開始。每當錯誤率平穩時,將學習率除以10,權值衰減為0.000 1,動量為0.9,[α]為0.01。網絡每一層的權重由均值為0,標準差為[2k×k×c]的高斯分布來初始化,其中[k×k]是該層卷積核的大小,[c]是該層卷積核的個數。
同時,本文隨機均勻選取圖片對。先將原始數據集中兩張標簽相同的圖片定義為相似,相似的圖片對標簽為1,不相似的圖片對標簽為-1。接著利用批量梯度下降算法將訓練集分成多個mini?batch,對于每個mini?batch,將圖像兩兩組合生成圖片對。假設整個數據集的樣本數為[n],mini?batch的個數為[m],那么在每個mini?batch隨機選取的圖片對數量為[nm]。最后利用這些圖片對進行網絡訓練。
3? 實驗結果與分析
3.1? 實驗設置
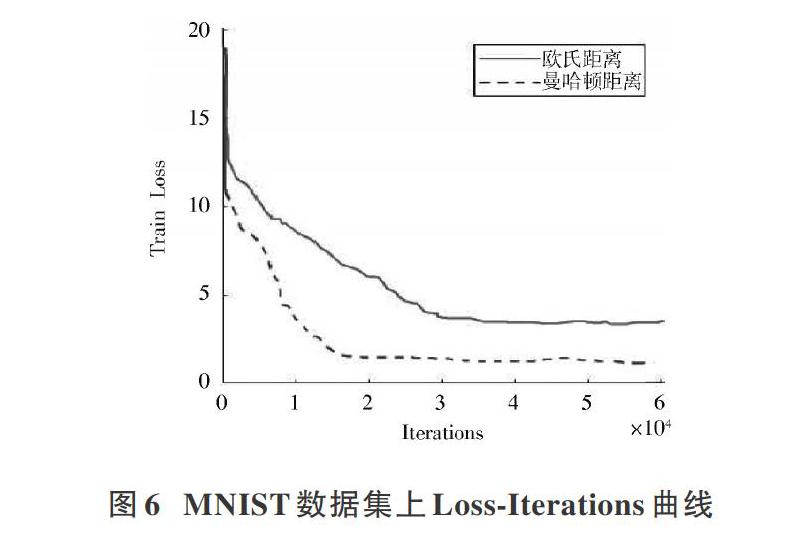
為了驗證RNH算法的有效性,本文采用Caltech256與MNIST數據集,將RNH算法與LSH,ITQ,KSH,CNNH,CNNH+等哈希方法相比較。其中CNNH,CNNH+直接使用圖像作為輸入,LSH,ITQ,KSH均使用圖像的Gist特征作為輸入。為了使實驗結果更具有說服力,本文采用平均精度(Mean Average Precision,MAP)和top?[k]近鄰域檢索準確率作為指標評價檢索精度,采用Loss?Iterations曲線作為指標評價網絡訓練時間。
MNIST是一個手寫數字識別的數據集,總共有70 000張28×28像素的圖片,包含0~9共十個類別。Caltech256是一個物體識別數據集,總共包含30 608張圖片,256個物體類別,每類最少80張,最多827張。
在本文中,MNIST數據集從生成的所有圖片對中隨機選取70 000個相似的圖片對,630 000個不相似圖片對用于訓練網絡。Caltech256數據集從生成的所有圖片對中隨機選取25 600個相似的圖片對,230 400個不相似的圖片對用于訓練網絡。在MNIST數據集中,每一類分別隨機選取100張圖片,共1 000張作為查詢圖像,構成測試集。在Caltech256數據集中,每一類分別隨機選取10張圖片,共2 560張作為查詢圖像,構成測試集。由于深度殘差網絡的輸入大小固定為224×224,所以在訓練和測試時都需將輸入圖片的尺寸縮放為224×224。
為了比較使用曼哈頓距離的損失函數與使用歐氏距離的損失函數訓練網絡時所花費的時間,本文在MNIST數據集和Caltech256數據集上分別用不同的損失函數進行訓練,實驗時除了改變損失函數,即將式(4)中的曼哈頓距離改為歐氏距離,其他條件如網絡模型、訓練參數等均保持不變。MAP值是一個反映圖像檢索方法整體性能的指標,MAP值越大,說明圖像檢索方法的檢索性能越好,其值范圍在0~1之間。top?[k]近鄰域檢索準確率是指檢索方法根據最小漢明距離排序返回的[k]張圖像中,與查詢圖像相似的圖像所占的比例。Loss?Iterations曲線表示損失函數的值隨著網絡訓練迭代次數的變化趨勢。
[10] LAI Hanjiang, PAN Yan, LIU Ye, et al. Simultaneous feature learning and hash coding with deep neural networks [C]// IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, MA, USA: IEEE, 2015: 3270?3278.
[11] LIN K, YANG H F, HSIAO J H, et al. Deep learning of binary hash codes for fast image retrieval [C]// IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Boston, MA , USA: IEEE, 2015: 27?35.
[12] LIU Haomiao, WANG Ruiping, SHAN Shiguang, et al. Deep supervised hashing for fast image retrieval [C]// IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016: 2064?2072.
[13] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition [C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016: 1063?6919.
[14] BOTTOU L. Stochastic gradient descent tricks [M]. Berlin: Springer, 2012.
作者簡介:吳振宇(1993—),男,湖北黃岡人,在讀碩士研究生,研究方向為深度學習、圖像處理。
邱奕敏(1981—),女,浙江黃巖人,博士,高級工程師,主要研究方向為圖像處理、模式識別、深度學習。
周? 纖(1993—),男,湖北仙桃人,在讀碩士研究生,研究方向為深度學習、圖像處理。
