圖紙數字化成果名稱一致性復核實踐探析
2020-12-14 03:00:02許玉德同濟大學道路與交通工程教育部重點實驗室
浙江檔案 2020年11期
許玉德/同濟大學道路與交通工程教育部重點實驗室
胡述筌 劉思磊 徐國堯/上海市軌道交通結構耐久與系統安全重點實驗室
當前,電子文件電子化歸檔和電子檔案電子化管理成為檔案工作的重要發展趨勢。現有工作實踐表明,圖紙檔案數字化成果信息采集已形成比較成熟的工作模式,但學界、實踐部門很少討論檢驗圖紙名稱準確性的方式方法。目前管理系統對檔案信息的命名有所限制,>、<、/等特殊符號不能作為檔案名稱,容易導致圖紙數字化成果名稱與數據庫目錄上的圖紙名稱不完全一致;加之數據庫的位置與圖紙數字化成果檔案的實際存儲位置通常不會在同一個地方,二者聯系需要通過超鏈接來實現,如數據庫目錄與圖紙數字化成果名稱不一致,二者超鏈接就會失效,無法通過數據庫的目錄查閱圖紙數字化成果。工作中,需要對圖紙檔案數字化成果名稱一致性進行復核。
中國鐵路上海局集團有限公司上海高鐵維修段對段內形成的所有圖紙檔案進行數字化掃描,受數據庫系統不接受特殊符號、重復命名等限制,圖紙數字化成果名稱與數據庫系統目錄中的名稱很難保證完全一致,需要對名稱一致性進行復核。統計發現,需要復核的圖紙超過10000張,若采用人工復核的方式,會造成效率低下、正確率得不到保障等問題。需要設計新的方法,復核圖紙數字化成果檔案名稱的一致性。
1 復核實踐分析
名稱一致性復核流程如下。一是選用擅長處理海量數據的Python分別爬取已建立數據庫目錄上的檔案名稱、實際存儲位置的圖紙數字化成果檔案名稱;二是以Python中內建的模糊匹配函數,進行數據庫、實際圖紙數字化成果檔案名稱一致性復核,模糊匹配函數中的匹配度,在檢查過程中需要進行循環調整,每檢查一次逐漸拉高匹配度;三是每次匹配完成后,以Excel VBA中的SQL語句檢驗兩者名稱是否不一致、是否存在冗余數據;四是反復進行二、三流程,直至兩者名稱完全對應。
1.1 圖紙數字化成果存儲路徑與格式
存放圖紙的路徑分為3個層次,即線路層、線路內的檔案層、檔案內的圖紙層,每條線路包含了數量眾多的檔案,檔案中又包含了眾多圖紙。上海高鐵維修段數據庫共搭建了3個存儲路徑,即滬寧城際(含虹橋聯絡線)、滬杭高鐵、寧杭高鐵,每條線路竣工文檔冊數分別為25555冊、12327冊、16206冊,包含圖紙張數分別為4646張、3447張、4628張。
1.2 Python模糊匹配方法
一是讀取外部儲存圖紙數字化成果名稱。Python自帶的函數庫os,提供針對系統檔案信息管理的操作接口,利用該函數庫提供的函數,可以實現批量讀取檔案存儲路徑、檔案更名、檔案存儲位置移動、檔案刪除等功能。本次數據庫使用了批量讀取檔案存儲路徑的接口函數os.walk(file_dir),作為爬取檔案路徑、圖紙數字化成果檔案名稱的手段。
二是建立外部儲存圖紙數字化成果檔案名稱的字典。Python提供了一種特殊的數據類型dictionary,具體格式如下[1]。
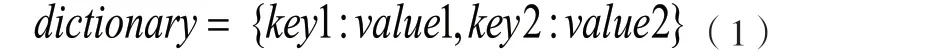
(式中key1、key2表示添加數據的鍵;value1、value2表示添加數據值)
該數據格式為每個數據提供唯一的鍵(key),通過查閱鍵找到添加數據值(value),添加數據值的形式不限于單一值,可以是數組(array)、列表(list)或字典(dictionary)。由于此次上海高鐵維修段數據庫共搭建了3個存儲路徑,存儲的圖紙數量較為龐大,所以需要用到雙層字典,將第一層字典稱為d_total,第二層字典稱為d。其中d_total的鍵為線路名稱,添加數據值為d,包含該線路下所有檔案文件夾;d的鍵為存儲文件夾名稱,添加數據值為文檔冊內的圖紙。通過此方式,可以完整有序地讀取文件夾內所有圖紙數字化成果名稱,具體格式如下。
d_total={‘線路1’: d{檔案1-1: [圖紙1-1-1,圖紙1-1-2], 檔案2: [圖紙1-2-1,圖紙1-2-2]…},‘線路2’: d{檔案2-1: [圖紙2-1-1,圖紙2-1-2], 檔案2-2: [圖紙2-2-1,圖紙2-2-2]…},….}
三是模糊查找方法與實現。引入Python中的xlwt、xlrd兩個函數庫,讀取xlsx檔格式的內部查詢數據庫圖紙目錄,以列表(List)變量的形式暫存,作為遍歷查找的母體。
由于數據庫目錄與圖紙數字化成果檔案名稱不完全一致,如以目錄名稱與圖紙數字化成果檔案名稱完全相同作為檢查判斷語句的條件,則太過苛刻,所以通過Python中difflib庫里的difflib.get_close_matches(word, possibilities,n,cutoff)函數,使用模糊查找的方式進行一致性檢核,其輸入參數解釋如下所示[2]。
word為需要查找的字符串,是讀取Excel中的數據庫圖紙目錄后,存于列表中的各個元素;possibilities為搜索匹配數據集,由創建字典的鍵、添加數據值,分別截取成為列表進行輸入;n為達到匹配相似度的模糊搜索結果,按照相似度大小依序輸出,默認值是輸出的3個結果,本文只取最大匹配相似度的搜索結果,即令n等于1;cutoff為控制匹配相似度,取值0—1,默認值為0.6,設置1為精確查找,如搜索結果的匹配相似度超過既定的cutoff值,則函數按照匹配相似度大小依序輸出查找結果。
該函數按照式(2)計算匹配相似度Ratio,若計算出來的Ratio大于cutoff值,代表查找字符串的匹配度超過默認值,通過檢核要求。
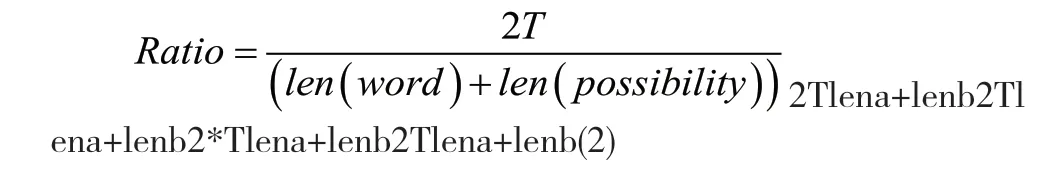
式中,len(word)為查找字符串word的長度,len(possibility)為搜索匹配數據集內某一元素字符串possibility的長度,T為word、possibility兩字符串內容完全一致的長度。
審核存于列表(List)的目錄所有標題,與讀取存儲圖紙數字化成果檔案名稱而建立的字典d_total進行模糊匹配,查找相似度最高的存儲文件夾名稱、圖紙數字化成果檔案名稱。經反復試驗,發現設置cutoff為0.7時模糊查找的效果最好,設置0.8以上則不合格率太高,無助于復驗。由于匹配的結果要導出Excel進行一致性檢驗,必須詳細記錄存儲文件夾、圖紙數字化成果檔案的名稱,與數據庫目錄名稱的異同,所以如果模糊匹配結果返回空值,必須要進行標記。
1.3 Excel VBA目錄一致性檢驗
數據庫目錄上的檔案都有固定、唯一、連續編排的序號,可利用Excel VBA中的SQL語句,遍歷選取模糊匹配而來的存儲文件夾名稱,如一個存儲文件夾名稱選取出來的數據條數,與對應的數據庫目錄數量一致,則無需進行人工修正;如連續編排序數與選取總條數不一致,代表發生資料冗余、數據缺失、匹配錯誤等現象,需對特定目錄名稱、存儲文件夾名稱進行人工修正。檢查完目錄上的檔案標題后,如未發現存儲文件夾存在數據冗余、數據缺失、匹配錯誤等問題,再用Excel VBA中的SQL語句往下遍歷選取該存儲文件夾內所有模糊匹配成功得到的圖紙數字化成果檔案名稱,若模糊匹配所對應的圖紙數字化成果檔案名稱選取結果條數大于1,代表存在圖紙數據冗余或匹配錯誤,需要進行人工修正。
1.4 信息精確復核
進行數據條數核對后,可以找出數據冗余、數據缺失、匹配錯誤等問題,再進行人工修改標題,然后再次利用difflib庫里的difflib.get_close_matches(word, possibilities,n,cutoff)函數,參照修正更新后的字典進行n=1、cutoff=1精確查找,查找完的數據匯總至Excel內,再次使用Excel VBA中的SQL語句進行遍歷,對比目錄上的檔案名稱,依次循環直到目錄中的數據百分之百通過復核。
2 復核結果
按照流程進行循環復核,各循環階段復核的結果如表1所示,可以發現第一次模糊查找的正確率為81.3%,對沒有匹配上的目錄名稱、存儲文件夾名稱、圖紙數字化成果檔案名稱進行人工修正;再次進行第二次匹配度為1的復核循環,即可得到99.8%的正確率;修正后第三次復核正確率達到100%。
3 結論
根據反復測試的結果,若初始模糊查找的相似度太高,則目錄與實際存儲數字化成果名稱不匹配的條數過多,后續修正的工作量過大,故改采用降低模糊查找相似度(本次取0.7),可有效降低不匹配的數據條數,再利用Excel VBA,進行相關數據冗余、數據缺失、匹配錯誤檢核,解決因不同檔案文件夾、圖紙數字化成果檔案名稱相似度太高,導致重復匹配的問題,最后檢核出來需人工修正數據為2385條,占比全部圖紙目錄條數約18.7%。第一次模糊查找修正完后,第二次精確查找的正確率就可達到99.8%。若沒有特定的輔助手段,則全部電子化名稱皆須人工復核,且正確率難以保證,故該方法可以達到實現與實際檔案文件夾名稱、圖紙數字化成果檔案名稱匹配正確率100%,且兼顧復核效率的目標。本次數據冗余、數據缺失、匹配錯誤是使用Excel VBA進行復核,其運行效率較為低下,往后可以針對該部分再進行相關算法的優化。
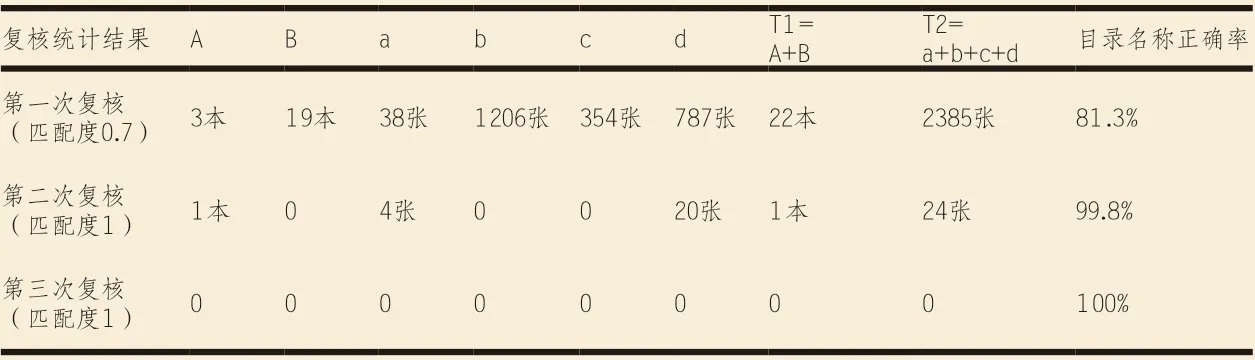
表1:圖紙復核結果統計表
猜你喜歡
汽車實用技術(2020年16期)2020-09-06 13:28:22
當代工人(2019年20期)2019-12-13 08:26:11
制造技術與機床(2017年9期)2017-11-27 02:14:26
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
河南科技(2014年12期)2014-02-27 14:10:44
世界建筑(2012年8期)2012-04-20 06:09:14
