軟件定義網絡中基于模糊邏輯的實時路由更新
2020-12-14 06:14:16李雅波姜麗芬
天津師范大學學報(自然科學版) 2020年6期
關鍵詞:實驗
李雅波,姜麗芬,劉 濤,張 棟
(天津師范大學計算機與信息工程學院,天津 300387)
軟件定義網絡(software defined networking,SDN)是當今最熱門的網絡技術之一,SDN利用分層的思想,將控制平面和數據平面相分離,分別部署在獨立的設備上實現[1].與傳統網絡技術相比,SDN有許多優點[1]:(1)控制平面統一控制轉發平面上的網絡設備,同時向上提供便捷的可編程操作;(2)網絡運營商和第三方能根據自身需求開發新的控制方案,提供全新的網絡應用和服務;(3)網絡用戶不必在意底層設備的技術細節,只需通過簡潔的編程操作就能迅速達成目標應用的需求;(4)SDN可以提供靈活的網絡資源管理和基于數據流的快速靈活的路由配置,能夠自動優化網絡資源的利用.因此,近年來SDN引起了學術界和工業界的廣泛關注.
SDN需要周期性地進行路由更新,更新執行的速度是決定網絡性能的關鍵[2],更新執行越慢,傳輸過程中數據丟失和造成網絡擁塞的可能性就越高.因此,路由更新是SDN的關鍵問題之一,眾多學者對SDN路由更新方法進行了深入研究[2-15].其中:一類更新方法[2-3]預先設定了轉發規則更新的次序,但這類方法很難適應實際數據量的動態特點;文獻[4-5]提出根據當前數據流整體狀況進行轉發規則的更新,但隨著執行更新的數據流逐漸增加,網絡性能變差,實驗分析表明[6],只更新10 kB數據流,完成流表更新尚約80 s,而實際中等規模數據中心中數據流到達的速度約為1 250~1 667 B/s.文獻[9]針對更新的帶寬開銷和交換機處理延遲等問題,提出基于通配符的請求成本優化流統計收集(CO-FSC)方案,該方案通過具有近似因子f的基于舍入的算法來降低帶寬開銷和交換機轉發規則處理的延遲.文獻[10]提出一種基于時間的更新實用方法,使用三態內容尋址存儲器條目中的時間戳字段,來實現原子束更新,以高精度地協調網絡更新.考慮到網絡功能的隨機性,文獻[11]對基于馬爾可夫鏈的路由更新算法進行了補充,在更新過程中,數據包通過選定路由的傳輸以比較所有可能的替代路由,實現了更新算法的虛擬化服務,并根據執行的算法為選擇最佳路由提供建議.文獻[12]首次提出了動態路由更新期間無縫保持一致性的方法,避免了頻繁更新而導致數據包到達過程中出現明顯的不規則延遲或“通信中斷”.上述工作討論了在路由更新中如何保持更新一致性及避免擁塞的問題,而沒有考慮實時更新的問題.文獻[13]探討快速路由更新的問題,利用線性規劃方法解決流的選取,其缺點是選擇更新數據流時沒有考慮當前鏈路的負載狀況和公平性,造成數據流的選擇不合理,并且線性規劃算法執行速度較慢.文獻[14]提出一種快速路由更新方法,適用于數據中心網絡和廣域網的更新,文獻[15]提出了一種智能規則劃分方法(SARD)來實現SDN中的快速更新,這2種方法的缺點是更新的數據流數量均較大,可能導致更新延遲過長.
本文提出一種基于模糊理論的數據流選擇及路由更新策略(fuzzy quantified based flow selection and route update,FANS).首先,使用語言量詞和模糊量化命題確定各數據流相對于路由更新標準的符合程度,并結合鏈路可用容量決定更新的數據流,然后,利用鏈路容量和交換機存儲容量限制尋找同步更新的數據流,進一步降低路由更新的延遲.仿真實驗結果表明,本文的路由更新方法具有較優越的性能.
1 模型描述
1.1 網絡模型
設網絡結構為G=(S,L),S={s1,s2,…,sn}表示交換機構成的集合,L為鏈路集.路由更新的目的是將網絡從狀態C={f,Pc(f),f∈T}更新為狀態C′={f,Pd(f),f∈T},其中:T為進行路由更新的流的集合,C和C′分別為數據流的目前傳輸路徑集合和目標傳輸路徑集合,Pc(f)為流f更新之前的傳輸通路,Pd(f)為相應更新后的通路.假設每個數據流僅擁有一條傳輸通路.
交換機可以記錄通過它的數據流,根據交換機的統計記錄,控制器可以獲知數據流的強度.但在實際情況中,數據流的強度可能會在空間和時間上呈現動態性,這種情況下控制器無法獲知數據流的強度.文獻[16]利用鏈路能夠負載數據流的數量進行強度估計,鏈路容量為歷史統計中能夠一次通過的最大流數.本文中,若數據流的強度無法獲知,則每隔一段時間記錄該時間段內一次通過鏈路e的最大流數max(Tn,e).設F(n)為當前通過鏈路e的最大流數,由指數加權平均法有
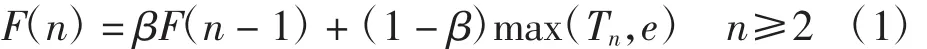
其中:F(n-1)為上一次統計中一次通過鏈路e的最大流數,β為權重.式(1)可寫為
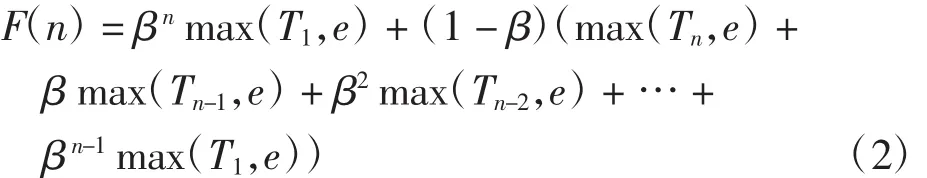
利用指數加權平均法預測最大流數,既考慮了歷史狀況,又考慮了網絡當前的流量狀態.優化算法中通常取 β≥0.9,此時有 β1/(1-β)≈1/e.由于越早的 max(Tn,e)權重越小,因此每次只需考慮最近1/(1-β)次的數據流最大個數的統計值,從而大大降低了交換機的存儲代價.
1.2 延遲模型
設di為插入一個轉發規則的時長,dm為修改一個流轉發規則的時長.令d(s,Pc(f),Pd(f))為交換機s將流f從Pc(f)更新到Pd(f)的時長,且dm≈10 ms,di≈3.3 ms,則有

2 路由更新過程
2.1 更新數據流的選擇
為滿足路由的實時更新,利用人工智能的模糊理論確定各數據流相對于更新標準的符合程度.
2.1.1 模糊量詞
令Q、X、A、B分別為模糊語言量詞、論域和2個模糊謂詞,模糊量化命題的形式為“Q XareA”或“Q B XareA”.相關研究表明[17-18],模糊量化命題“Q XareA”適用于描述用戶偏好.當Q為增量量詞時,模糊量化命題“P:Q XareA”的真值TP是X的子集,
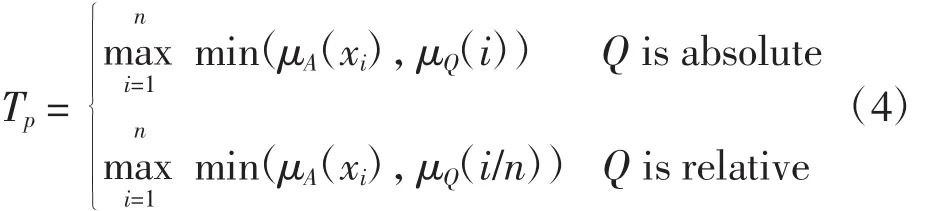
其中μA(x1)≥μA(x2)≥…≥μA(xn).
2.1.2 基于模糊運算的路由更新排序及選擇根據如下因素選擇待更新數據流:
(1)數據流強度(flow intensity),即流數大小s(f);
(2)數據流當前路由的負載(route load),定義為數據流當前路由上鏈路的最大負載,即其中H為鏈路帶寬;
(3)數據流當前路由的擁塞程度(route congestion level),即負載較重的鏈路條數與總鏈路條數的比值;
(4)選擇優先級(select priority),定義為某數據流在前m輪被選為待更新數據流的次數.
基于以上因素,每個數據流f被描述為一個具有4個對的集合{(cfk,ofk),k=1、2、3、4},其中:cfk是流f的屬性,of k為其具體取值.為選擇待更新數據流,定義選擇標準fselect,相應的,fselect具有 4 個對(cfk,pfk),k=1、2、3、4,pfk為對于cfk的選擇偏好.數據流f相對于選擇標準fselect的符合程度(記為τ(fselect|f))是模糊量化命題“幾乎所有的偏好都被滿足”的真值.基于式(4),τ(fselect|f)的取值為
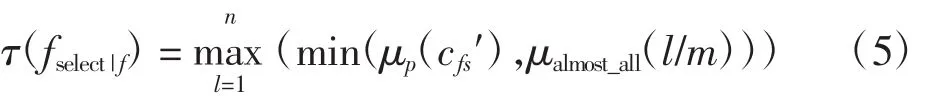
其中μp(cfs′)為數據流f的屬性對選擇偏好的符合程度,由模糊隸屬函數求出,且μp(cf1′)≥μp(cf2′)≥…≥μp(cfm′).各因素的模糊隸屬函數見圖1.
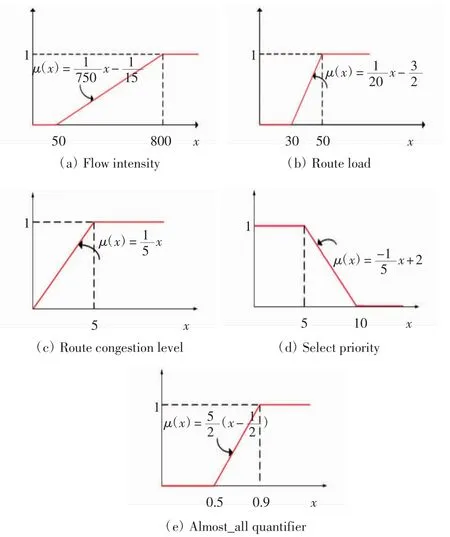
圖1 模糊隸屬函數Fig.1 Fuzzy membership functions
得到各數據流相對于選擇標準的符合程度后,對于結果不為零的數據流,按照符合程度由大到小排列,形成序列Q.從序列Q的第1個流開始依次選擇,對于流f的路徑集Rf(所有可選路徑的集合)內的各條傳輸路徑,計算其上各鏈路的目前容量c(e),進而得到傳輸路徑P的目前容量C(P)為

從路徑集Rf中選出容量最大的路徑Pmax,由式(7)判斷Pmax能否容納f,若能則將f分配給路徑Pmax.

其中λ為負載參量.上述路徑分配算法的偽代碼如下:
算法目標路徑分配

2.2 同步更新數據流的挖掘
在保證鏈路無擁塞的前提下,控制器在相應的時間段內選擇多個流同步更新,可以進一步降低路由更新的延遲.為此,在更新部分數據流的基礎上,從鏈路容量限制和交換機流表容量限制2個方面進一步挖掘同步更新的數據流.
2.2.1 鏈路容量限制
鏈路容量限制保證同步更新數據流時鏈路無擁塞.對于Q中的流f,能夠與該流同步更新的數據流滿足
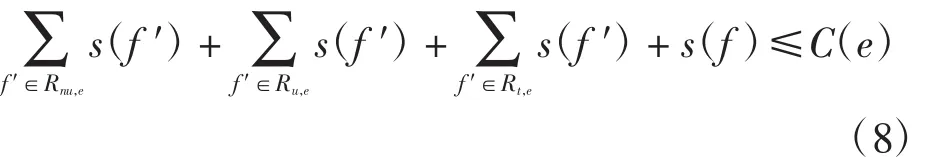
其中:Rnu,e為通過鏈路e且不需要更新路徑的數據流集合,Ru,e為源路由通過鏈路e的數據流集合,Rt,e為目標路由通過鏈路e的數據流集合.
2.2.2 交換機流表容量限制
交換機流表容量限制保證在路由更新過程中交換機的流表大小不超過最大容量.設交換機s的流表容量為CP(s),若更新后的路由通過交換機s,則其流表大小增加一個規則占用的空間rule(1),其大小取決于openflow協議的版本號.設Rnu,s為源路由通過交換機s且暫不需要更新的數據流集合,Ru,s為源路由通過交換機s且需要更新的數據流集合,Rt,s為目標路由通過交換機s的數據流集合,則有
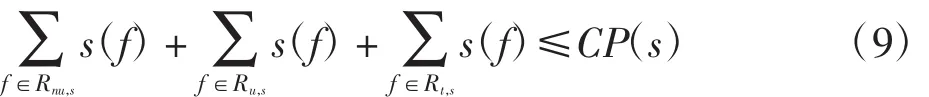
3 仿真實驗與性能分析
3.1 實驗環境
使用mininet生成網絡拓撲,同時使用與文獻[16]相同的網絡拓撲生成工具,此生成工具是PSGen拓撲生成工具的一個修改版,能夠模擬真實的大規模網絡拓撲.實驗網絡拓撲包含25臺交換機,100條鏈路,6 000個數據流,控制器選擇Ryu.模擬的數據流遵循標準的2-8原則[19].實驗中設β=0.9,λ=0.56.
采用2個性能指標評價路由更新算法的性能:(1)網絡負載率(network load ratio),該指標用于衡量網絡負載均衡度;(2)路由更新延遲(route update delay),即更新完成數據平面的總時間.
3.2 實驗結果
將 FANS 與已有算法 EMCF+DS[16]、GRSU[16]和OSPF進行性能比較,本文設計了4組實驗.
3.2.1 第1組實驗
第1組實驗考察當不同數量的數據流存在于網絡中時,路由更新延遲和網絡負載率的變化.
由于OSPF算法始終為數據流選擇最短路徑,所以這里不考慮它的更新延遲問題,圖2給出了路由更新延遲隨數據流數量的變化情況.
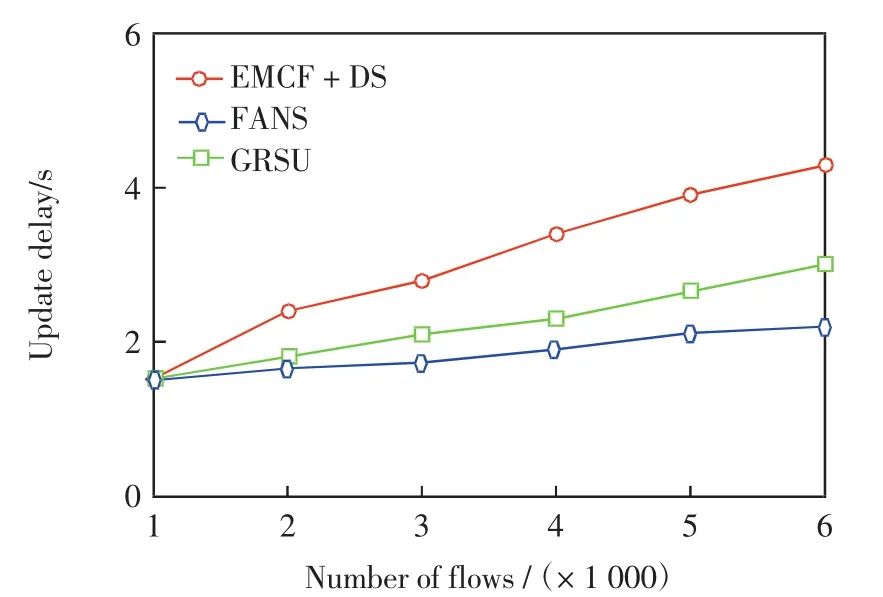
圖2 數據流的數量對路由更新延遲Fig.2 Number of flows vs.route update delay
由圖2可見,FANS的路由更新延遲要小于EMCF+DS和GRSU,當數據流數量為6 000時,FANS的路由更新延遲分別比EMCF+DS和GRSU低約2.1 s和0.8 s.EMCF+DS每次都要更新網絡中的全部大象流,因此造成更新延遲較長,GRSU在更新流的選擇時沒有考慮數據流的強度以及選擇的公平性等因素,導致更新效果略差.
圖3給出了網絡負載率隨數據流數量的變化情況.由圖3可見,FANS的網絡負載率低于GRSU,略高于EMCF+DS,但FANS的更新延遲遠低于EMCF+DS,綜合考慮,FANS算法更具優勢.另外,OSPF算法的網絡負載率最高,當數據流數量為6 000時,其網絡負載率約為0.7,這是因為數據流數量增大之后,某些主要鏈路的負載大大加重.
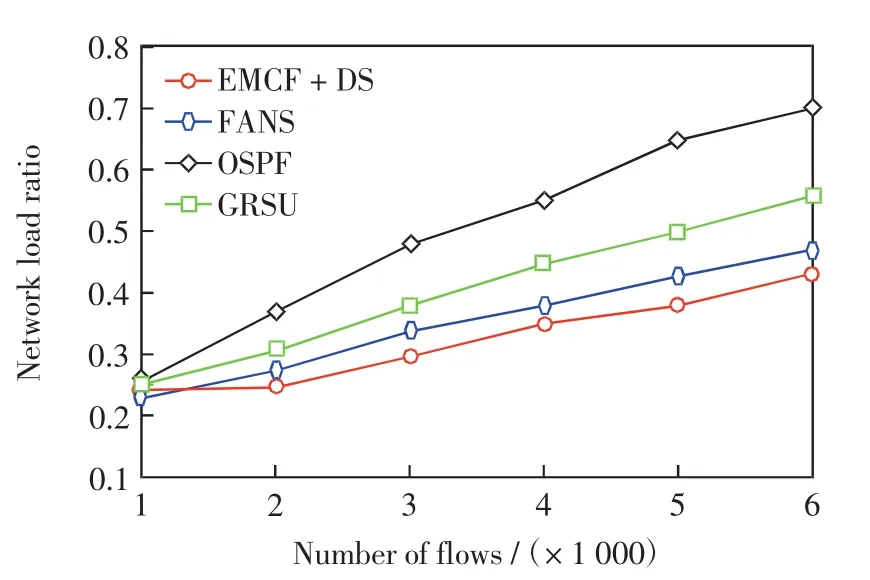
圖3 數據流的數量對網絡負載率Fig.3 Number of flows vs.network load ratio
3.2.2 第2組實驗
第2組實驗在第1組實驗的基礎上為FANS和GRSU設定一個最大更新延遲的閾值D0=1.5 s.因為GRSU為交換機設置了最大更新時延,另外當數據流量或網絡規模較大時,實時更新可能無法保證,所以通過設定這樣一個閾值來限制更新延遲.圖4和圖5分別給出了此時路由更新延遲和網絡負載率隨數據流數量的變化情況.
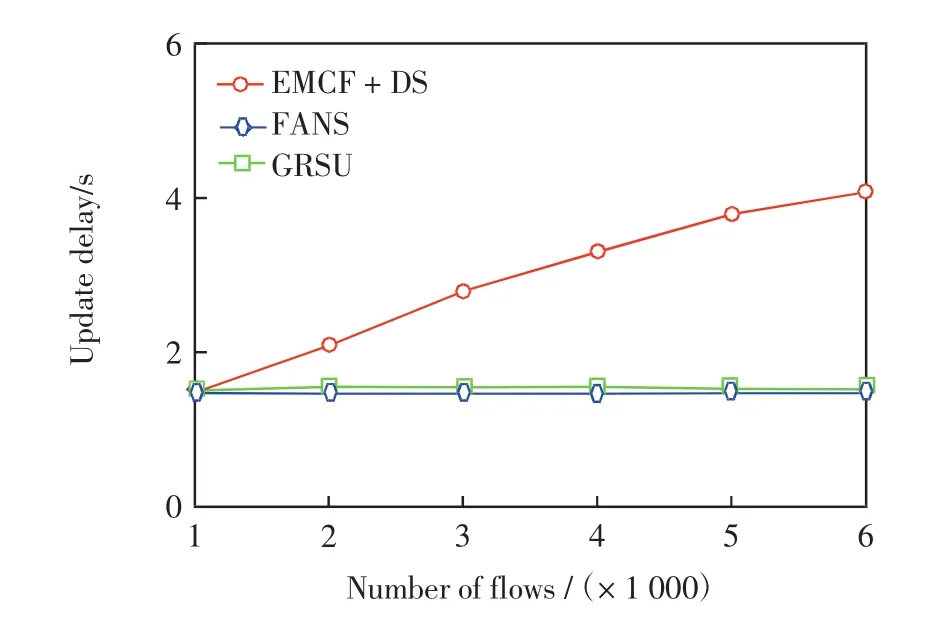
圖4 數據流的數量對路由更新延遲(D0=1.5 s)Fig.4 Number of flows vs.route update delay(D0=1.5 s)
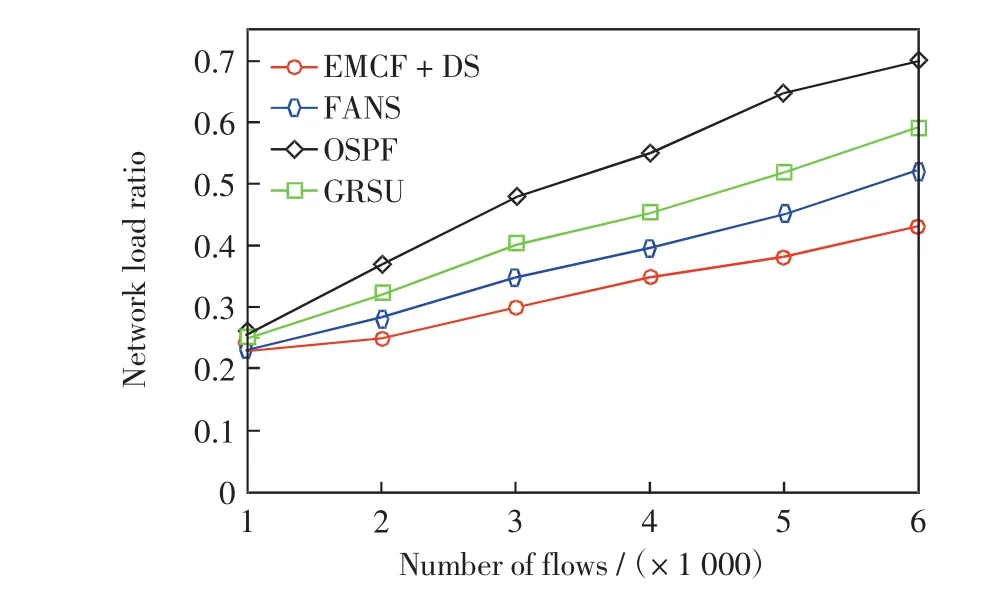
圖5 數據流的數量對網絡負載率(D0=1.5 s)Fig.5 Number of flows vs.network load ratio(D0=1.5 s)
由圖4可見,由于設定了閾值,此時數據流數量的增大對FANS和GRSU的更新延遲沒有影響,而EMCF+DS的更新延遲依然會隨數據流數量的增大而增大.對比圖5和圖3,在設定閾值的情況下,FANS的網絡負載率增大約5%,這是因為限定閾值后數據流較之前增多,能夠更新的數據流數量比無設定時少,因此路由更新后的效果變差.由圖4和圖5可以看出,FANS的網絡負載率稍高于EMCF+DS,但FANS的更新延遲卻大大低于EMCF+DS.當數據流數量為4 000時,FANS的負載率比EMCF+DS高約5%,但其更新延遲比EMCF+DS低約1.8 s,當數據流數量為6 000時,FANS的更新延遲比EMCF+DS低約2.5 s,而負載率僅高約8%,說明FANS算法通過更新部分數據流,達到了負載率和更新延遲的平衡.
3.2.3 第3組實驗
在第3組實驗中,在默認函數基礎上將大象流的門限進行擴大.當大象流的門限逐漸擴大時,圖6和圖7給出了路由更新延遲和網絡負載率的變化情況.
由圖6可見,隨著大象流門限值成倍增加,FANS的更新延遲一直低于其他算法.由圖7可見,隨著大象流門限值增加,4種算法的負載率均不斷增大,FANS的負載率僅高于EMCF+DS,當大象流門限為原來的4倍時,FANS的負載率比EMCF+DS高約5%,但更新延遲卻低約2.5 s,因此FANS的性能更優.
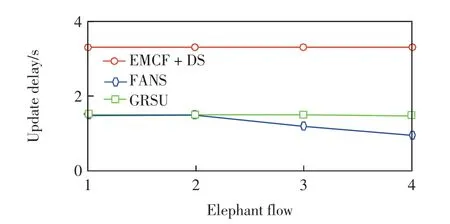
圖6 大象流門限對路由更新延遲Fig.6 Elephant flow threshold vs.route update delay
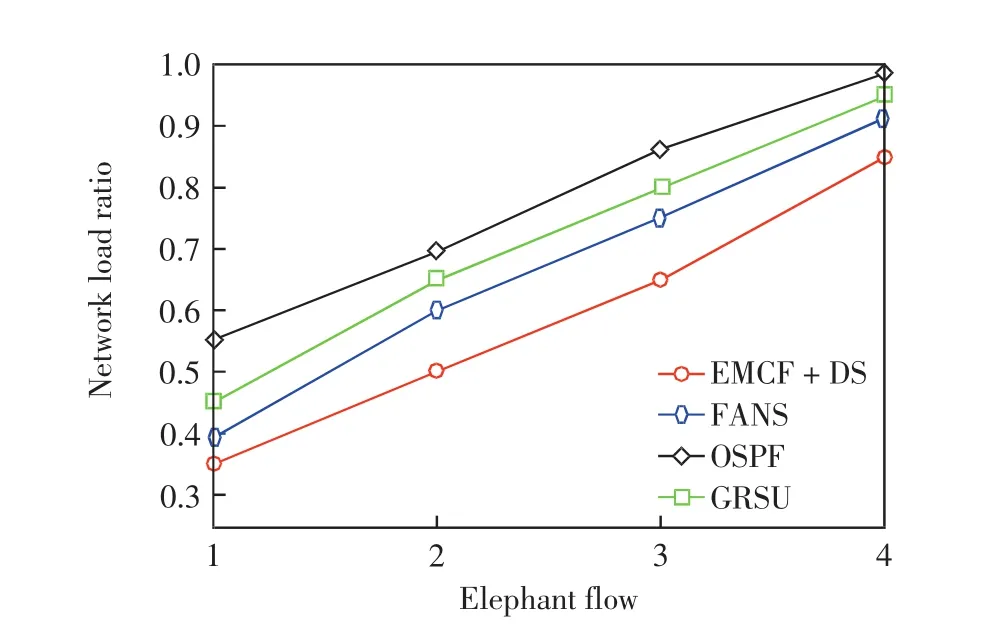
圖7 大象流門限對網絡負載率Fig.7 Elephant flow threshold vs.network load ratio
3.2.4 第4組實驗
在第4組實驗中,固定數據流數量,考察最大更新延遲閾值D0對網絡負載率的影響.圖8(a)和(b)分別給出了當數據流數量為4 000和6 000時,網絡負載率隨D0的變化情況.
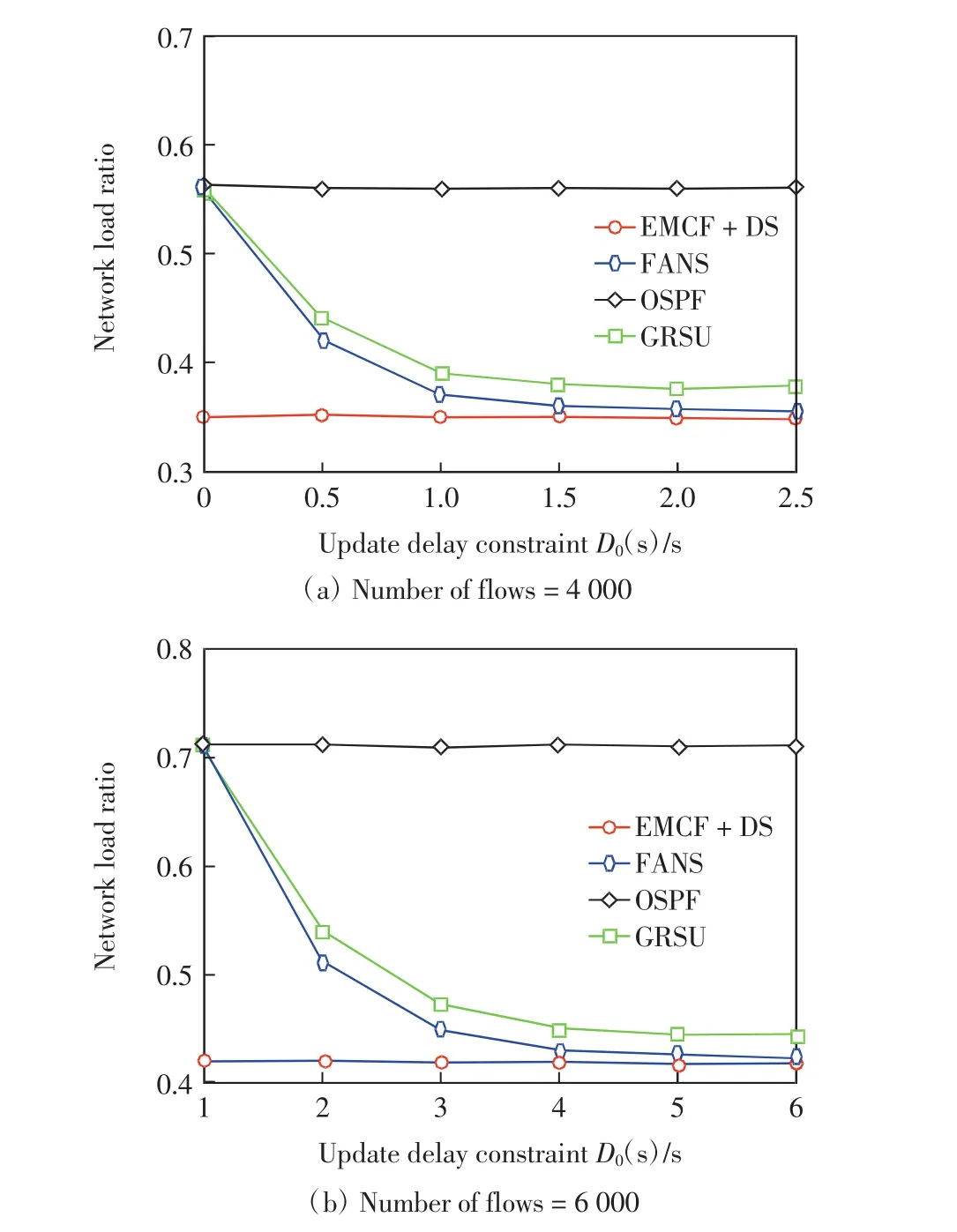
圖8 最大更新延遲閾值對網絡負載率Fig.8 Update delay constraint vs.network load ratio
由圖8可見,隨著D0的增大,FANS的負載率逐漸接近EMCF+DS,并且一直低于GRUS.但由于EMCF+DS需要更新全部大象流,因此其更新延遲會遠大于FANS,另外,FANS采用了模糊邏輯,選擇的數據流更加合理,因此負載率略低于GRSU.
3.2.5 負載參量λ對FANS性能的影響
數據流更新路徑的選擇與λ有關,因此FANS的性能受λ影響.圖9給出了數據流數量為4 000和6 000時,不同λ值下FANS的網絡負載率.由圖9可見,λ=0.6時負載率最低.當λ從0.6緩慢增大時,網絡負載率會逐漸增大,這是因為λ較大會導致一些主要鏈路負載較高,所以網絡負載率也會增大.當λ較小時,鏈路容量沒有得到充分利用,也會造成負載率較高.因此,選擇合適的負載參量對路由更新算法的性能也很重要.
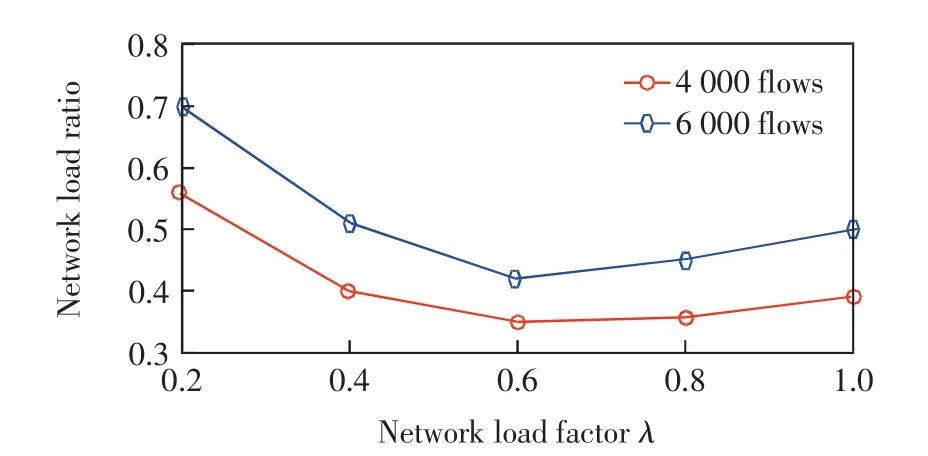
圖9 負載參量對網絡負載率Fig.9 Network load factor vs.network load ratio
4 結語
針對軟件定義網絡中的實時路由更新問題,本文利用人工智能算法的語言量詞和模糊量化命題處理數據流的選擇問題,同時考慮流的屬性和各流相對選擇標準的符合程度,盡量選擇符合程度較高的數據流進行更新,這種策略可以保證在維持網絡較小的更新延遲與開銷的情況下,盡量降低網絡負載率.仿真實驗驗證了本文所提路由更新方法具有較優越的性能.
猜你喜歡
作文·小學低年級(2025年2期)2025-02-13 00:00:00
小雪花·小學生快樂作文(2024年11期)2024-12-31 00:00:00
作文·小學低年級(2024年2期)2024-04-29 00:00:00
作文·小學低年級(2023年3期)2023-04-29 00:00:00
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小主人報(2022年4期)2022-08-09 08:52:06
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
