融合深度網絡的改進快速生成超像素算法*
2020-12-15 08:13:54盛家川王佳媛李玉芝
計算機與生活 2020年12期
盛家川,王佳媛,李玉芝,王 君
1.天津財經大學理工學院,天津300222
2.天津財經大學管理科學與工程學院,天津300222
1 引言
超像素作為取代像素應用于視覺、圖像處理等諸多領域的基本單元,一方面,使圖像更易理解和分析,有利于圖像在不同領域的后續研究;另一方面,通過給所有像素貼標簽,使相同標簽的像素組成的區域塊具有相同的視覺效果,保護了圖像的有效信息,且一般不會破壞圖像中物體的邊界信息。超像素不僅能降低將其作為特征向量和圖元的各種圖像分析以及計算機視覺任務中[1-4]的計算復雜度,而且由于超像素是通過對圖像像素進行分組而生成的圖像區域,因此可以計算圖像的局部特征,減少后續圖像處理所需圖像原語的數量,提高計算效率。
計算超像素的算法主要有兩大類,即基于圖的方法和基于聚類的方法。其中基于圖的方法將超像素分割公式化為圖分割問題,但由于離散優化涉及離散變量,因此優化目標通常是不可微的,在基于圖的方法中難以利用深度網絡。而基于聚類的超像素算法最早是Achanta等人[5]基于Lloyd算法[6]提出的簡單線性迭代聚類(simple linear iterative clustering,SLIC)算法,該算法利用CIELab顏色空間和像素位置組成的5維特征,將圖像中的像素點通過聚類生成超像素。相比基于圖的算法,SLIC能在較短時間內生成緊湊性和規則性相對較好的超像素。
受SLIC算法的啟發,使用線性光譜聚類的超像素分割算法(superpixel segmentation using linear spectral clustering,LSC)[7]、優化加權核K-means聚類初始中心點的SLIC算法(SLIC algorithm based on optimizing initial center point of weighted kernelK-means clustering,WKK-SLIC)[8]等改變SLIC中像素的特征表示實現超像素分割。Wang等人[9]提出基于測地距離的結構敏感超像素(structure-sensitive superpixels,SSS)算法,該算法考慮了圖像中的結構信息,利用幾何流計算測地距離,但測地距離的高計算成本導致SSS算法效率低下。Liu等人[10]改進SLIC算法來計算內容敏感的超像素,但由于其映射、拆分和合并過程的成本導致運行速度不及SLIC。為解決以上問題,Zhao等人[11]提出快速線性迭代聚類(fast linear iterative clustering with active search,FLIC)算法,該算法時間成本低,但生成的超像素規則性相對較差。以上算法進行超像素分割時,均依賴手工提取的像素特征,導致算法的效率低、過程繁雜。為此,本文引入深度網絡來提取更具代表性的深度像素特征。
目前,利用深度網絡提取特征已被大量研究和應用[12]。例如Weimer等人[13]提出了用于工業檢測中自動提取特征的深度卷積神經網絡架構。張偉等人[14]通過深度卷積神經網絡對中分辨率遙感影像進行特征提取和分類。最近,Jampani等人[15]充分利用深度網絡提取的像素特征,提出超像素采樣網絡(superpixel sampling networks,SSN)算法。
由于現有的超像素算法主要基于手工提取的特征,所有直接將深層特征與現有的超像素算法結合在一起并不能獲得更好的性能。為此,本文提出了融合深度網絡的改進快速線性迭代聚類算法來實現超像素分割。主要貢獻包括:(1)為了提高像素特征的提取效率,不同于現有超像素分割算法采用的手工提取的像素特征,本文提出將深度網絡嵌入到超像素生成過程中,利用含多隱含層的深度網絡進行像素特征的提取;(2)改進快速生成超像素算法[11]的初始種子點計算過程,以改善超像素分割結果。
2 相關工作
2.1 SLIC算法
SLIC算法對圖像像素在五維空間中執行K-means聚類。相較于標準K-means算法的搜索范圍,SLIC搜索種子點的2G×2G范圍內的像素點進行距離的計算,其中,N為像素點個數。圖像中任意兩像素pi、pj的距離由顏色距離dc和空間距離ds共同決定,dc、ds計算如下:

其中,顏色空間由三維CIELab(li,ai,bi)值決定,ds由二維空間(xi,yi)值決定。
SLIC算法的時間復雜度僅為O(n),在處理高分辨率圖像時可以減少時間復雜度,且分割的數目和邊緣貼合度是可控的。但基于SLIC改進的算法大多忽略了相鄰像素之間的關聯性,且像素的分配和更新步驟分步執行,這導致像素標簽更改的反饋延遲,所需的迭代次數較多。
2.2 卷積神經網絡
近年來,深度學習已廣泛應用于各種計算機視覺領域。目前大多文獻將深度網絡與已經生成的超像素結合進行研究。文獻[16]提出了利用雙邊過濾器在不同比例上的加權組合BI(bilateral inception)模塊的超像素卷積網絡。文獻[17]提出了用于顯著目標檢測的超像素卷積神經網絡。文獻[18]提出了一種用于像素語義場景標記的深度前饋神經網絡架構。但是,現有文獻沒有將深度網絡直接應用于超像素的生成過程當中,這主要有兩大原因:一是構成大多數深度網絡結構基礎的標準卷積運算通常在規則的網格上進行定義,而在不規則的超像素網格上進行處理時效率低下;二是現有的超像素算法是不可微的,因此在深層網絡中使用超像素會在端到端可訓練網絡體系結構中引入不可微模塊。
3 融合深度網絡的改進快速生成超像素算法
本文融合深度網絡的改進快速生成超像素的算法過程如圖1所示,主要由三大步驟組成:(1)深度網絡提取圖像像素的深度特征。本文使用卷積神經網絡(convolutional neural networks,CNN)的局部連接性高效地提取圖像像素特征,利用含有多隱含層的深度網絡能夠對原始輸入數據做出更加深刻和本質的刻畫,從而學習到更高級的數據特征。(2)K-means聚類計算初始種子點位置。以均勻生成的K個種子點為基礎,執行一步K-means聚類,將更新后得到的一組新的種子點當作初始種子點。通過計算種子點與像素之間的距離確定像素標簽,使每個種子中包含幾乎相似的像素,即將具有相同特征的像素點包含在同一個超像素塊內。(3)主動搜索確定像素標簽。利用相鄰像素點之間具有相鄰連續性的特點,將像素標簽的最終決定權由種子點決定改變為由像素點自主決定,以確保每個像素的標簽正確。
3.1 深度網絡提取圖像像素的深度特征
為了能使從圖像中提取的像素特征保留更多的邊界信息,本文采用由一系列卷積層組成的CNN網絡對圖像中的像素進行特征提取。經過深度網絡提取n-5維像素特征,結合輸入圖像像素的XYLab 5維像素特征,將最終所得n維像素特征傳遞給改進的快速線性迭代聚類算法以生成超像素。
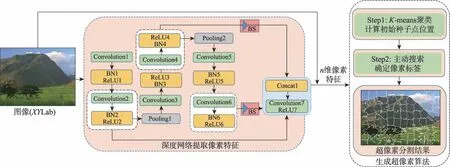
Fig.1 Overview of proposed algorithm圖1 本文算法概述
圖1所示深度網絡中,加入批歸一化層(batch normalization,BN)和ReLU(rectified linear units)激活函數以加快訓練收斂的速度;在網絡的第2層和第4層后加入最大池化層,以降低數據維度和過擬合概率,提升特征提取的魯棒性;在整個過程中,BS(bilinear sampling)表示對第4和第6卷積層的輸出進行雙線性采樣,白色框表示將第2、4、6卷積層的結果一起傳遞給藍色框所示的最后一層卷積層;在每個卷積層上,使用3×3的卷積濾波器,除最后一層網絡的輸出通道數為n-5個以外,其余每層的輸出通道數均設置為64,將得到的n-5個通道的輸出與輸入圖像像素的XYLab 5維特征結合在一起,得到給定圖像的n維像素特征。
在深度網絡提取特征時,圖像的位置和顏色特征權重分別用λpos和λcolor表示,其中λcolor與超像素的數量無關,本文默認設置為0.26;λpos受到超像素個數的影響,計算如下:
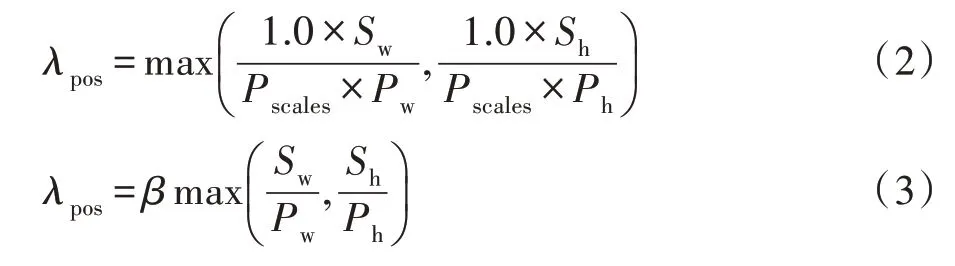
其中,本文實驗取像素尺度Pscales=0.40,Sw和Sh分別表示沿著圖像的寬度和高度方向所存在的超像素數量,Pw和Ph分別代表圖像的寬度和高度,由式(2)可得參數,因此單個訓練的深度網絡模型可利用式(3)通過輸入的位置特征λpos值,估計Sw、Sh所代表的圖像的寬度和高度方向所存在的超像素的數量。在深度網絡訓練過程中,訓練樣本使用尺寸為201×201的圖像且取超像素個數K為100。在對BSDS500[19]數據集進行數據擴充時,本文采用左右翻轉以及對圖像進行隨機縮放的方式。訓練過程均采用批量數為8,學習率為0.000 1的Adam隨機優化[20]。對于訓練模型,進行500 000次迭代,并根據驗證精度選擇最終訓練模型。
3.2 改進的快速生成超像素算法
3.2.1 K -means聚類計算初始種子點位置
初始種子點的位置對超像素的分割結果有很大影響。本文改進FLIC算法[11],基于一步K-means聚類計算初始種子點位置。包含N個像素點的圖像,每個像素pi=(li,ai,bi,xi,yi,Ni),其中(li,ai,bi)是CIELab顏色空間中的像素顏色向量,(xi,yi)是像素的坐標位置,Ni=[ni1ni2…niT]是從深層網絡中提取的特征,T=n-5。首先在圖像上均勻生成K個種子點,即圖像被分割成包含K個元素的規則網格,步長為;基于K個均勻分布的種子點,執行一步K-means操作:為了避免均勻分布的種子點落在梯度較大的輪廓邊界上,計算其3×3鄰域內所有像素點的梯度值,將種子點移到該鄰域內梯度最小的位置,然后在種子點的2G×2G范圍內,指定像素pi的初始標簽。再使用加權歐氏距離計算像素與種子點的距離,計算如下:
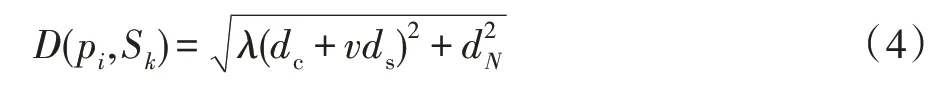
其中,Sk為種子點,dc和ds由式(1)計算所得,λ是控制圖像像素初始XYLab特征的權重值,其取值介于0到1之間;v是控制空間距離權重的變量且,m為決定超像素緊湊性的變量,dN表示提取的深度像素特征的距離,計算如下:

每個像素點取最小距離對應的種子點作為該像素點的聚類中心,所有像素都歸類完后重新得到K個超像素塊,根據每個超像素塊內包含的像素點重新計算種子點并更新種子點位置,以此獲得本文算法的初始種子點。
本文算法中像素點的遍歷順序起著重要的作用,適當的掃描順序可能會導致視覺上更好的分割。在確定種子點位置時,本文借鑒PatchMatch[21]提出的前后遍歷順序,對像素的處理也采用前后遍歷的方法,即對一個超像素塊,先從左至右在超像素塊的上半部分進行掃描,此時超像素塊頂部及其周圍像素信息決定了像素的標簽。同理再從右至左掃描超像素塊的下半部分。前后遍歷,使得后處理的像素受益于先處理的像素,對像素點周圍的信息考慮更加全面,提高了計算效率,從而產生更好的超像素塊。此外,由于在迭代過程中,每次生成的超像素塊的形狀并非完全規整,為了簡化操作,將所有的超像素塊補全為一塊規整的最小矩形框,對最小矩形框內的所有像素進行遍歷,若發生像素點的重新分配,則更新所對應超像素塊的最小邊界框,反之則不變。
3.2.2 主動搜索確定像素標簽
在大多數自然圖像中,相鄰像素往往共享相同標簽,即相鄰像素具有自然連續性。因此,本文對像素點pi考慮相鄰像素之間的關聯信息,選擇與該像素點近鄰的4個像素,當近鄰像素點中有與pi本身標簽不同的,則計算pi與標簽不同的像素所在種子點的距離,比較距離大小獲取最短距離,確定新的標簽。在這個過程中,每個像素點都是主動去尋找自己所屬的超像素塊,給自己賦予該超像素塊所屬的標簽。如圖2所示,Qi包含了像素pi及4個鄰近像素點pi1、pi2、pi3、pi4。pi2和pi4的種子點為,pi1和pi3的種子點為。兩個虛線框代表標簽為Li和Lj的超像素塊。d(i)為pi與自己所在超像素塊種子點的距離,D為pi與不同標簽的種子點的距離。對于每個像素pi,最終的標簽是唯一的,即:
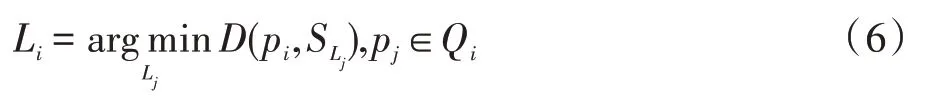
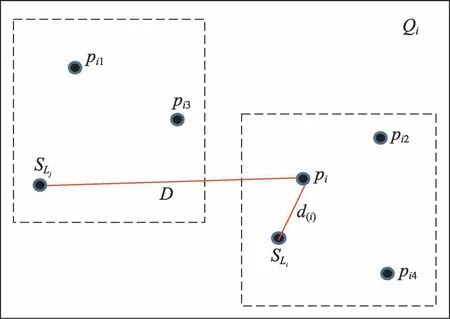
Fig.2 Active search to determine pixel labels圖2 主動搜索確定像素標簽
由于每個像素只能被分配給其至少一個鄰近的超像素塊中。因此,根據相鄰像素可以直接確定該像素的標簽,避免了額外計算與其他種子點的距離。選擇鄰近像素點有3個優點:(1)考慮到了相鄰像素點的局部連續性,充分利用了先驗信息,有助于后續操作的像素點在分配過程中做出更好的選擇;(2)加快了確定像素標簽的速度;(3)保證了超像素塊的數量,在一定程度上可以避免大量孤立區域的產生。像素點在主動搜索所屬標簽過程中,超像素種子點也在自適應地進行位置變動。值得注意的是,超像素塊內部像素的鄰域通常共享相同的標簽,因此不再需要處理它們。這一事實促使非常迅速地處理每個超像素塊。
在確定像素標簽時,如果像素的標簽發生改變,則需要對像素重新分配標簽以及信息的更新操作。分配和更新的分步進行通常需要5次以上的迭代次數,這成為快速收斂的瓶頸。因此本文基于式(6)所示的分配原則,采用將分配與更新操作“捆綁式”進行的方法,通過實驗發現,本文算法在2次迭代之后就能達到收斂。“捆綁式”操作指像素pi的標簽從Li變為Lj后,緊接著要進行更新操作,即對進行如下更新:

其中,|ψLi|表示超像素ψ里的像素數量。對也進行更新,如下:

4 實驗結果與分析
4.1 實驗平臺、數據集和評估指標
實驗平臺:本文算法運行的操作系統為Windows 10,Intel?Core?i5-3210M,4.0 GHz。本文編程環境包括VS2013、Anaconda2(Python2.7),實驗使用帶Python接口的caffe框架。
數據集:本文所使用的數據集為公開的Berkeley圖像分割BSDS500基準數據集,包括500幅321×481的自然圖像,其中有200幅訓練圖像,100幅驗證圖像以及200幅測試圖像。每個圖像都用來自多個注釋器的GT(ground-truth)段進行注釋。
評估指標:本文對不同算法在三方面進行了對比:其一為對于固定比例數據集的最佳F-measure(optimal dataset scale,ODS);其二為數據集上的F-measure,以獲得每個圖像的最佳比例(optimal image scale,OIS);其三為全召回范圍內的平均精度(average precision,AP)。圖3顯示了在BSDS500數據集上不同超像素分割算法的Precision-Recall曲線,其中弧線代表Iso-F曲線,,圓點表示人手工標定的GT的平均值。
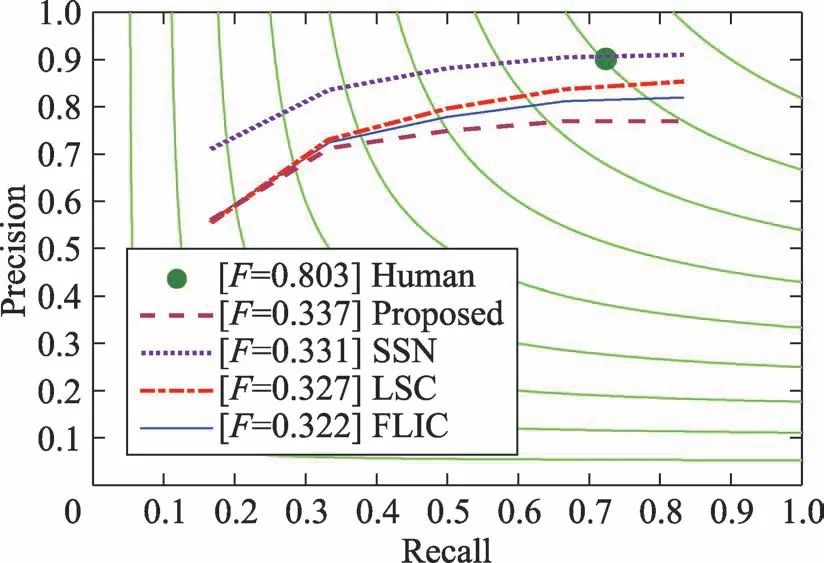
Fig.3 Precision-Recall curves of algorithms on BSDS500 dataset圖3 BSDS500數據集上算法的Precision-Recall曲線
4.2 相關參數設置
本文方法在初始需要設置3個參數:其一是期望的超像素數量K。基于聚類的超像素分割算法的一個共同優點是通過設置聚類參數K,可以直接獲得期望的超像素數。其二為最大迭代次數itr,本文采用分配與更新“捆綁式”操作的方法,打破了執行分開操作時通常超過5次迭代的瓶頸,通過實驗發現,本文算法在2次迭代后就能達到收斂,因此本文設置itr=2為默認值。其三是空間距離權重m,其取值范圍在[1,40]之間。
4.3 實驗結果
本文算法將與LSC[7]、FLIC[11]、SSN[15]進行比較。其中LSC基于均勻生成的K個初始種子點,改變像素的特征表示實現超像素分割;FLIC在SLIC算法的初始種子點的基礎上進行了主動搜索操作以提高生成超像素的效率;而本文是在均勻生成的K個種子點基礎上,執行一步K-means聚類得到本文算法的初始種子點,并且在此基礎上進行主動搜索操作。如表1所示為不同算法在BSDS500數據集上所得結果的ODS、OIS、AP值。對比其他算法,本文算法生成的區域邊界與GT匹配程度優于其他算法。
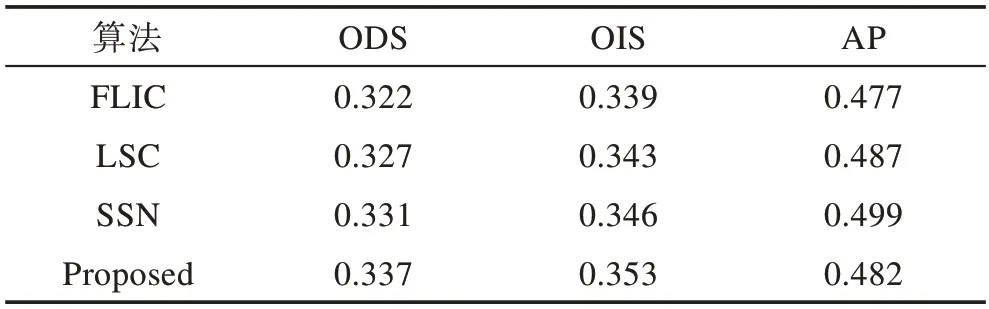
Table 1 Comparison on BSDS500 dataset表1 BSDS500數據集上的比較
如圖4所示為不同算法得到的超像素分割結果,與其他算法相比,本文算法所得超像素分割結果表現良好,在保持良好邊界性的同時產生形狀更規則的超像素。而在計算機視覺任務中恰好需要的是具有良好邊界的超像素。此外,圖5、圖6展示了對參數取不同值時的超像素分割結果。圖5為不同算法在K取200情況下,m分別取5,10,20得到的超像素分割結果,參數m影響超像素的平滑性和緊湊性,當m取值較小的時候,超像素的規則性較差但同時超像素對邊界的粘附性較強;當m取值偏大時,超像素變得更加緊湊、規則。圖6為不同算法取m=20時,超像素個數K分別為100,200,400的超像素結果,由此所得的超像素很好地粘附在區域邊界上。

Fig.4 Superpixel segmentation results of different algorithms(K=100, m=10)圖4 不同算法超像素分割結果(K=100,m=10)

Fig.5 Superpixel segmentation results of different algorithms(K=200,m=5,10,20)圖5 不同算法超像素分割結果(K=200,m=5,10,20)
5 結束語
本文提出了一種融合深度網絡的改進快速生成超像素算法。該算法將深度網絡嵌入到超像素生成過程當中,基于深度學習網絡對圖像進行像素的深度特征提取;優化初始種子點位置的計算過程,以改善超像素分割結果。一方面,相比依賴手工提取的圖像像素特征,CNN架構高效且使用CNN網絡提取到的像素特征進行后續的超像素分割有助于超像素分割結果在緊湊性、規則性等方面得到提升;另一方面,采用改進的快速線性迭代聚類算法,減少了主動搜索的計算量,且充分利用局部連續性,使復雜的低對比度圖像也能具有良好的邊界靈敏度,從而提高了圖像的分割性能。
超像素被廣泛應用在計算機視覺以及圖像處理領域。高效地生成超像素在視覺和圖像處理研究中具有重要的應用價值,因此本文研究成果有助于視覺和圖像處理領域的研究。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
