基于深度學習的卷煙牌號識別方法
2020-12-22 13:59:06陳智斌農英雄梁冬孫忱韋屹鐘征燕
煙草科技 2020年12期
陳智斌,農英雄,梁冬,孫忱,韋屹,鐘征燕
廣西中煙工業有限責任公司信息中心,南寧市西鄉塘區北湖南路28號530001
在煙草行業,卷煙零售數據是煙草企業非常重視的數據信息。通過采集和分析零售戶的卷煙零售數據,可以獲知零售戶、片區的銷售趨勢,用于指導品牌規格投放,從而提高煙草企業經營管理水平。然而傳統的卷煙零售數據采集技術,無論是依賴于市場人員到零售戶處進行采集,還是布設POS系統要求零售戶掃碼記錄,均容易出現漏報、瞞報等問題,準確性和覆蓋性不強,進而導致卷煙零售數據質量欠佳,亟需建立卷煙零售數據自動化采集系統。自動化采集系統的核心是卷煙牌號的正確識別。為了在數據采集過程中不干擾傳統購煙流程,因此需結合卷煙零售店實際場景設計一種能準確識別卷煙牌號的方法。目前,圖像識別技術是物體識別的主流技術,能夠實現較高的準確率,在煙草行業有較多的研究與應用。涂勇濤等[1]、翁迅等[2]、馮春等[3]、顏西斌[4]、曹冬梅等[5]均對條煙識別開展了研究,條煙識別的準確率和效率已取得較大提升,可基本滿足工業化自動生產線的需求,但這些算法需要特殊的設備或者光源條件才能保證較好的識別準確率,而這種條件在實際零售場景中難以具備。王鵬[6]提出了一種基于OCR視覺技術的煙箱品牌識別技術,但該方法要求的識別條件過于嚴格,實際場景中識別效率不高。謝志峰等[7]提出一種煙碼智能識別方法,可以實現煙碼的快速識別,但其識別準確率易受煙碼圖像傾斜角度的影響,魯棒性較弱。總體上看,現有算法難以滿足卷煙零售場景下卷煙牌號識別的需求。近年來,深度學習技術在圖像識別領域得到快速應用[8],其識別準確率、魯棒性較傳統的圖像識別方法有較大提升,在各類圖像識別的競賽任務中均有優異表現。因此,提出了一種基于深度學習的卷煙牌號識別方法,以期滿足卷煙零售數據自動化采集過程中準確識別卷煙牌號的需求。
1 總體設計
1.1 系統結構
卷煙牌號識別硬件系統主要由高清彩色攝像頭和工控機組成,其中攝像頭具備10倍變焦能力,可保證攝像頭安裝在4 m的高度內通過調節參數來獲取清晰的圖片;工控機配備1080 Ti顯卡,滿足深度學習算法對計算資源的需求。結合卷煙零售店實際場景,通過分析消費者的購煙流程可知,消費者的購煙過程離不開結算環節,而此環節發生在結算臺位置區域。為了不改變原有購煙流程并減少攝像頭對消費者的干擾,將攝像頭安裝在結算臺正上方,把結算臺作為卷煙牌號識別區域,當店員將卷煙放到結算臺時進行卷煙牌號識別,系統結構見圖1。
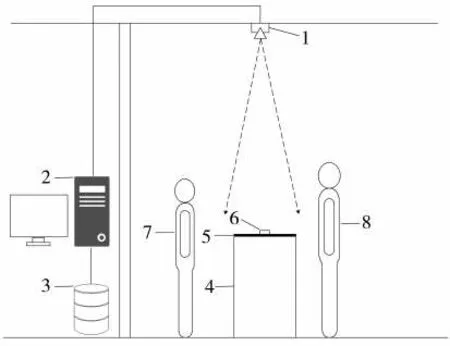
圖1卷煙牌號識別系統結構圖Fig.1 Structure of cigarette brand recognition system
1.2 技術路線
將卷煙牌號識別方法分成卷煙檢測、卷煙姿態矯正、卷煙特征提取和卷煙特征檢索4個部分,其中:卷煙檢測算法是基于CenterNet思想設計的檢測模型,負責檢測卷煙在圖像中的位置和姿態,其他物體都認為是背景;卷煙姿態矯正算法通過射影變換矯正卷煙姿態,生成卷煙的正向圖像;卷煙特征提取算法采用Darknet53作為特征提取網絡,負責提取卷煙正向圖像的特征;卷煙特征檢索算法通過歐式距離閾值從卷煙特征庫中檢索出與當前特征對應的卷煙特征和牌號信息,核心技術路線如圖2所示。
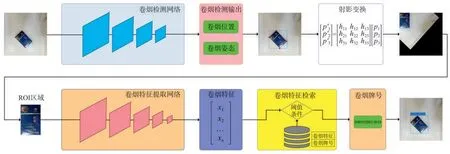
圖2卷煙牌號識別方法技術路線圖Fig.2 Roadmap of cigarette brand recognition method
2 算法設計
2.1 卷煙檢測
深度學習常用的目標檢測框架有Faster RCNN、SSD系 列、YOLO系 列 和CenterNet等,其中Faster RCNN算法的優點是目標檢測精確度高,但缺點是檢測時間過長,難以滿足實時性要求[9];SSD系列和YOLO系列都是端到端的目標檢測算法,其檢測速度相比Faster RCNN有較大提升,且精度下降較少,可以在精度和實時性之間實現較好的平衡[10-11];而CenterNet是新一代目標檢測框架,其將目標檢測任務視為一種關鍵點估計任務,并可用于3D檢測和人體姿態估計等多種任務中,具備良好的通用性,且相比SSD和YOLO有更好的檢測精度和實時性[12]。因此,為更好地實現卷煙的位置和姿態檢測,基于CenterNet設計卷煙檢測算法。
2.1.1 卷煙檢測定義
卷煙檢測任務包含卷煙的位置檢測和姿態檢測,其中位置檢測輸出卷煙的中心點位置pc(xc,yc)和卷煙包圍框的高度h與寬度w;姿態檢測輸出每盒卷煙4個角點的位置,分別為p1(x1,y1),p2(x2,y2),p3(x3,y3),p4(x4,y4),其 中x1≥x2≥x3≥x4,卷 煙 檢 測 實 例 如 圖3a所示。在卷煙檢測中,卷煙姿態信息具有重要作用,通過姿態矯正可以減少圖像背景或者其他卷煙局部圖像的干擾。如在圖3b中,由于兩盒卷煙靠得較近,如果只有卷煙位置檢測,那么卷煙檢測框中互相包含了相鄰卷煙圖像的一部分,將這些圖像直接送入卷煙特征提取網絡,易給卷煙特征提取網絡帶來二義性,不利于提升識別準確率。

圖3卷煙檢測實例Fig.3 Example of cigarette brand detection
2.1.2 卷煙檢測算法設計
假設圖像的輸入為I∈RW×H×3,其中W和H是圖像的寬度和高度。令為卷煙位置檢測輸出的卷煙中心點熱力圖,其中T是熱力圖的步長,此處采用表示在坐標(x,y)處檢測到卷煙中心點,而則 表 示 背 景。對于每盒卷煙的Ground Truth中心點p∈R2,計算p在熱力圖的坐標點并采用高斯核Yxy=在熱力圖上生成所有中心點的高斯分布,以此作為Ground Truth熱力圖。其中σp是目標尺寸自適應的標準差,當1個坐標點有多個中心點產生的高斯分布值時,選擇最大的值作為該點的值。中心點熱力圖的訓練目標是實現像素級的邏輯回歸,損失函數采用focal loss,其損失值Lk如式(1)所示。其中α和β是超參數,此處使用α=2,β=4,N為輸入圖像中含有的中心點數量。
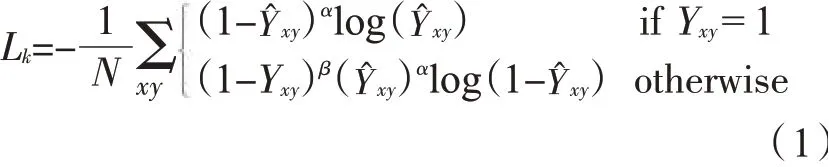
中心點坐標在下采樣的過程中產生了離散誤差,為彌補該離散誤差,需另外預測每個中心點的局部偏移量損失函數采用L1,其損失值Loff如式(2)所示。其中為在中心點預測的局部偏移量為下采樣時產生的真實離散誤差。
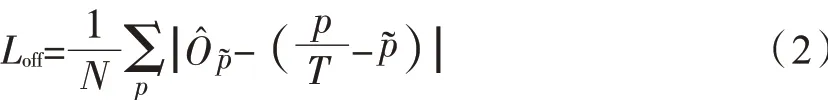

卷煙姿態檢測將卷煙4個角點的位置估計轉化成角點對中心點偏移量的估計。令為第k個卷煙的4個角點,中心點坐標為則4個角點相對中心點的偏移量在預測卷煙中心點位置的基礎上,增加預測卷煙4個角點相對中心點的偏移量損失函數采用L1,其損失值Lc如式(4)所示。
為了更加精確定位卷煙角點的位置,可進一步預測卷煙角點的熱力圖和每個卷煙角點的局部偏移量與卷煙中心點預測方法類似,令卷煙角點熱力圖的損失值為Lk-c,角點局部偏移的損失值為Loff-c,則卷煙檢測任務的總體損失值Ltotal如式(5)所示。其中λsize、λoff和λoff-c是權重參數。
卷煙檢測任務的主干網絡采用修改后的深層聚合模型DLA-34[13],其模型結構如圖4所示。其中框內的數字是指相對原始圖像的下采樣系數,對于輸入尺寸為512 px×512 px的圖像,其輸出尺寸為128 px×128 px。在主干網絡提取卷煙圖像的特征后,直接回歸出卷煙的中心點熱力圖、卷煙中心點偏移量、卷煙包圍框尺寸、卷煙角點相對中心點的偏移、卷煙角點熱力圖和卷煙角點局部偏移量這6類信息。對于卷煙角點熱力圖檢測出來的角點,其每個角點互相獨立,不屬于具體的卷煙實例,而通過卷煙角點相對中心點的偏移量預測出來的卷煙角點則對應于具體的卷煙實例,將這些角點綁定到和其最近的獨立卷煙角點上,完成獨立卷煙角點和卷煙實例的關聯,把綁定好的獨立卷煙角點作為該卷煙實例的姿態檢測結果。
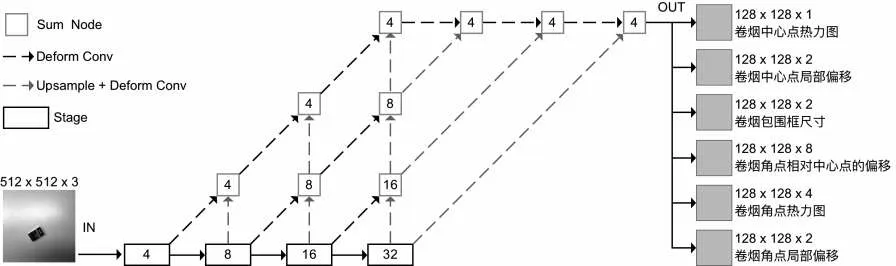
圖4模型結構圖Fig.4 Diagram of model architecture
2.1.3 數據處理與模型訓練
卷煙檢測訓練集包含5 000張在真實卷煙零售店采集的圖片,有1 920 px×1 080 px、1 080 px×1 080 px和640 px×480 px 3種像素尺寸。由于模型訓練時輸入圖片的分辨率統一為512 px×512 px,為減少直接縮放圖像導致的圖像變形,在1 920 px×1 080 px的圖像下方填充1 920 px×840 px的黑色圖像,形成1 920 px×1 920 px正方形圖像,同理填充640 px×480 px的圖像形成640 px×640 px的圖像。
模型訓練時將學習率設置為1.25e-4,批處理大小為32。權重參數λsize設置為0.1,λoff=1和λoff-c=1[12]。在裝備2個英偉達TITAN X GPU的服務器上訓練320 epochs,并在100,200,300 epochs時將學習率縮放為原來的1/10。為提升模型訓練效果,在訓練過程中采用隨機裁剪和隨機縮放等數據增強方法,并采用Adam來優化總體的目標。
2.2 卷煙姿態矯正
卷煙的正向圖像定義為由卷煙的4個角點形成的矩形圖像,矩形圖像與豎直方向的夾角為0°,且高度大于寬度。由于攝像頭安裝時可能存在一定偏轉角,以及卷煙售賣過程中姿態各異,導致通過卷煙包圍框截取出來的卷煙圖像不是正向圖像,可能包含較多的背景信息,這對卷煙識別帶來不利影響,需利用卷煙姿態信息通過平面射影變換完成卷煙的姿態矯正,生成卷煙的正向圖像。令p1,p2,p3是原始圖像上3個共線的點,而是射影變換后的3個點,射影變換滿足p'=Hp,如式(6)所示。
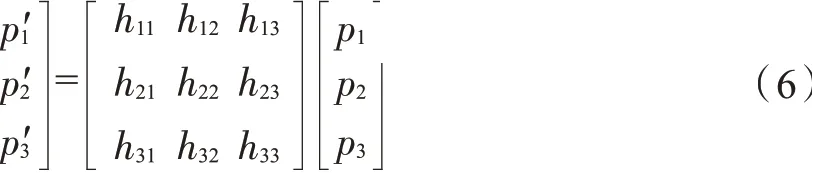
H是一個齊次矩陣,具備8個自由度,可通過變換前后的4對點求出矩陣的解。令卷煙檢測輸出的4角點p1(x1,y1),p2(x2,y2),p3(x3,y3),p4(x4,y4)為變換前的4個點,計算p1到p2距離的距離,則變換后對應的4個點按如下方式確定:
由射影變換前后的4對點求出矩陣的解H后,將原始卷煙圖像進行射影變換,并截取變換后4個角點組成的矩形區域作為卷煙正向圖像,卷煙姿態矯正實例如圖5所示。

圖5卷煙姿態矯正實例Fig.5 Example of cigarette pose correction
2.3 卷煙特征提取
優良的特征可以很好地表征一個物體的特性,從而獲得較高的物體識別正確率。本研究中選擇Darknet53模型作為卷煙特征的提取模型,該模型具備優良的特征提取能力,同時可以在運行速度和準確性之間實現平衡,具備非常靈活的特點[14]。
卷煙特征提取模型的訓練集包含10 000張卷煙正向圖片,由于卷煙存在正反面之分,而且某些牌號正反面的特征存在較大的差異。如果將卷煙的正反面都視為同一類別,將對模型訓練的收斂帶來不利影響,因此在訓練卷煙特征提取網絡時需要將卷煙正反面分成兩種不同的類別。訓練數據集在標注完成后,類別數量為210類。模型訓練時統一將輸入圖片分辨率縮放成448 px×448 px。為提升模型訓練效果,在訓練過程中采用隨機裁剪、隨機翻轉、圖像色彩調整等數據增強方法。設置學習率為1.0e-3,動量設置為0.9,批處理大小為64,在裝備2個英偉達TITAN X GPU的服務器上訓練20 000次。
2.4 卷煙特征庫構建
卷煙特征庫是用于存放每個卷煙特征向量和對應牌號信息的云端數據庫。實際應用中,選擇Darknet53最后卷積層的輸入作為卷煙的特征,該特征是1 024維的向量。為了提高識別的準確率,卷煙正反面可保存多個特征,因此一個卷煙牌號將對應多個特征,其對應關系見圖6。
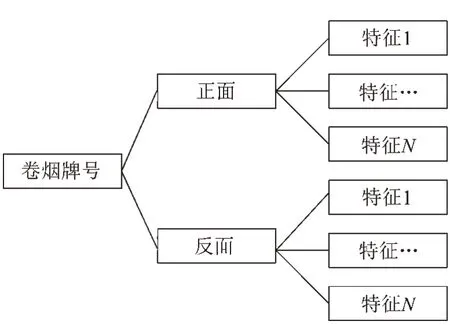
圖6卷煙牌號和特征對應關系圖Fig.6 Corresponding diagram of cigarette brand and features
根據卷煙牌號和特征的對應關系,在卷煙特征庫建立數據表,見表1。在卷煙數據集中為每種卷煙牌號的正反面選擇合適數量的正向圖片,使用Darknet53特征提取模型對正向圖片進行特征向量提取,并把特征向量和對應的卷煙牌號信息保存至數據表中,以完成卷煙的信息注冊。待全部卷煙完成注冊之后,卷煙特征庫則構建完畢。對于卷煙新產品或新包裝,采用以上相同方式完成卷煙的信息注冊,即可具備對該卷煙的識別能力,無需重新訓練卷煙特征提取模型。

表1卷煙牌號和特征數據表Tab.1 Data of cigarette brand and features
2.5 卷煙特征檢索
卷煙特征檢索是通過計算待識別特征和卷煙特征庫中每個特征的歐氏距離,從中選出歐式距離最小的值,當該值小于指定的歐氏距離閾值時,則判定兩個特征是同一牌號,否則不是同一牌號。由此在使用卷煙特征檢索前,需要確定歐式距離的閾值。選取2 000張未經卷煙特征提取模型訓練使用過的,且未在卷煙特征庫注冊過的卷煙正向圖片,形成圖片集P。使用卷煙特征提取網絡對圖片集P進行特征提取,生成F特征集,通過以下偽代碼的方法確定出閾值:
對于在F特征集中的每一個特征fi:
計算fi與卷煙特征庫里每一個特征的歐式距離,記錄最小值時的特征fi'和距離值ei;
如果fi和fi'的牌號一致,則vi=1,否則vi=0;
將ei和vi形成鍵值對<ei,vi>加入到鍵值列表List中;
將List按照ei降序排序;
正確計數count=0;
對于在List中的每一個鍵值對<ek,vk>:
ifek<thresholdandvk=1,則正確計數count加1,否則不加;
索引index增加1;
threshold=List中索引為index的ei值。
3 應用效果
3.1 材料與方法
為了測試卷煙牌號識別方法的魯棒性,在廣西南寧市若干卷煙零售店按圖1方式安裝攝像頭,采集不同店鋪、不同卷煙牌號的圖片,生成I1、I2、I3和I4測試集。其中測試集I1是包含有1 000張、105種卷煙牌號的圖片集合,該測試集的卷煙牌號是全部在訓練集中出現過的產品;測試集I2是包含有200張、20種卷煙牌號的圖片集合,該測試集的卷煙牌號是未在訓練集中出現過的新產品;測試集I3是由測試集I1真實的卷煙姿態矯正后生成的卷煙正向圖片集,該測試集包含有1 896張圖片,105種卷煙牌號;測試集I4是由測試集I2真實的卷煙姿態矯正后生成的卷煙正向圖片集,該測試集包含有364張圖片,20種卷煙牌號。測試工控機配置CPU型號為i7-8700,GPU型號為GTX1080Ti,Pytorch版本為1.1.0,CUDA版本為9.0,CUDNN版本為7.1。卷煙牌號識別方法的測試分為4個部分,分別為:
(1)卷煙檢測模型測試。在測試工控機上采用I1和I2測試集對卷煙檢測模型進行速度和精度測試,其中I1用于測試對已訓練過的卷煙的泛化檢測能力;I2用于測試對新卷煙產品的泛化檢測能力。
(2)卷煙特征提取模型測試。在測試工控機上采用I3測試集對卷煙特征提取模型進行速度和準確率測試,通過識別準確率的高低來判斷模型對卷煙特征提取能力的強弱。
(3)卷煙特征檢索識別方法測試。卷煙特征檢索識別方法指的是輸入卷煙正向圖像,采用卷煙特征提取模型提取該卷煙的特征,然后通過歐式距離閾值從卷煙特征庫中檢索出最符合條件的特征,并通過該特征獲得對應的牌號。在測試工控機上采用I3和I4測試集對卷煙特征檢索識別方法進行速度和準確率測試,其中I3用于測試對已訓練過的卷煙的泛化檢索識別能力;I4用于測試對新卷煙產品的泛化檢索識別能力。需注意的是,為了具備對I3和I4測試集中各卷煙牌號的檢索能力,已提前為每個卷煙牌號完成特征注冊和歐式距離閾值的確定。注冊過程為:先為每個卷煙牌號選擇正反面圖片各5張,然后通過卷煙特征提取模型提取各圖片的特征,最后將特征和卷煙牌號保存到卷煙特征庫中,注冊完成后卷煙特征庫的特征數量為1 250。歐式距離閾值按2.5節方式確定為
threshold=8.5。
(4)卷煙牌號識別方法整體測試。在測試工控機上采用I1和I2測試集對卷煙牌號識別方法進行準確率測試。測試時,記在正確位置標記正確的卷煙牌號為一個正確樣例,在不正確位置標記牌號、在正確的位置漏標記牌號和在正確的位置標記錯誤牌號都記為錯誤樣例,識別方法的正確率記為
3.2 測試結果分析
3.2.1 卷煙檢測模型測試結果
在測試集I1和I2上完成卷煙檢測模型的速度和精度測試。測試結果顯示幀率為21.6幀/s,在測試集I1的位置檢測單類平均精度(Average Precision,AP)為95.6%,姿態檢測多類平均精度(mean Average Precision,mAP)為93.4%;在測試集I2的位置檢測AP為94.9%,姿態檢測mAP為93.1%。結果表明:卷煙檢測模型在兩個數據集上均表現出較高的精度,體現模型對訓練過的卷煙和新卷煙產品都具備良好的檢測性能。
3.2.2 卷煙特征提取模型測試結果
在測試集I3上完成卷煙特征提取模型的速度和準確率測試。測試結果顯示幀率為35.7幀/s,準確率為99.7%。結果表明:卷煙特征提取模型對卷煙具備較強的特征提取能力,可提取出較準確的卷煙特征。
3.2.3 卷煙特征檢索識別方法測試結果
在測試集I3和I4上完成卷煙特征檢索識別方法的速度和準確率測試。測試結果顯示幀率為33.6幀/s,測試集I3的準確率為99.3%,測試集I4的準確率為98.9%。結果表明:卷煙特征檢索識別方法在兩個數據集上均表現出較高的識別準確率,體現該方法對訓練過的卷煙和新卷煙產品都具備良好的檢索識別能力。
3.2.4 卷煙牌號識別方法整體測試結果
在測試集I1和I2上完成卷煙牌號識別方法的準確率測試。測試結果顯示測試集I1的準確率為98.1%,在測試集I2的準確率為97.5%,綜合I1和I2兩個數據集的準確率為98.0%。結果表明:卷煙牌號識別方法對訓練過的卷煙和新卷煙產品都具備較好的識別能力,總體的識別準確率達到98.0%,滿足數據采集準確率90%的需求。圖7為卷煙牌號識別方法的應用實例,煙盒圖像區域上的藍底字符串為識別結果,表明該方法可在復雜背景下實現卷煙牌號的準確識別。

圖7卷煙牌號識別實例Fig.7 Example of cigarette brand recognition
4 結論
針對自動化采集卷煙零售數據中卷煙牌號識別的需求,提出一種基于深度學習的卷煙牌號識別方法,該方法首先采用卷煙檢測算法檢測卷煙在圖像中的位置和姿態,其次通過卷煙姿態矯正生成卷煙的正向圖像,然后使用卷煙特征提取模型提取卷煙正向圖像的特征,最后通過歐式距離閾值從卷煙特征庫檢索出與該待識別特征最相符的卷煙特征,由卷煙特征和牌號的關系得到待識別特征的牌號。以在卷煙零售場景中采集的數據集為對象,對該方法進行了測試,結果表明:該方法的識別準確率達98.0%,滿足數據采集的準確性要求。同時,對于新卷煙產品,只需將該卷煙注冊到卷煙特征庫中即可具備對其識別的能力,無需重新訓練模型,具備良好的泛化性能。該方法的不足之處主要有:①需要在工控機上配備GPU,硬件成本較高;②要求卷煙煙盒具備4個角點,對其他形狀煙盒(如圓角煙盒)的識別可能效果不佳;③要求把卷煙放在結算臺識別區才可以完成識別。基于上述不足,如何降低成本、擴展煙盒適應性和實現動態場景識別等方面仍需進一步研究。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
海峽科技與產業(2016年3期)2016-05-17 04:32:12
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
