基于改進(jìn)型LSTM的文本情感分析模型研究
2020-12-25 06:11:04羅正軍柯銘菘周德群
計(jì)算機(jī)技術(shù)與發(fā)展 2020年12期
羅正軍,柯銘菘,周德群
(南京航空航天大學(xué),江蘇 南京 210016)
0 引 言
互聯(lián)網(wǎng)技術(shù)與生活的聯(lián)系日趨緊密,人們?cè)絹?lái)越重視在社交媒體上發(fā)出自己的聲音,用戶愈加傾向于使用網(wǎng)絡(luò)分享自己意見,這些意見可能是網(wǎng)民對(duì)近期某一公共事件的看法,也可能是對(duì)最近消費(fèi)的商品服務(wù)的主觀評(píng)價(jià)。另一方面,對(duì)于提供商品和服務(wù)的商家而言,傳統(tǒng)的調(diào)查方式無(wú)法提供文本情感分析所能帶來(lái)的對(duì)消費(fèi)者的用戶意見以及潛在需求的了解與挖掘,商家也需要利用這些潛在信息針對(duì)性地優(yōu)化產(chǎn)品質(zhì)量,改進(jìn)銷售策略。不僅如此,消費(fèi)者也可以通過(guò)他人的評(píng)論對(duì)于商品服務(wù)或是公共事件有進(jìn)一步的了解。此類評(píng)論通常代表著其他消費(fèi)者對(duì)該商品及其相關(guān)服務(wù)的觀點(diǎn),可能是正面積極地贊許產(chǎn)品與服務(wù),或者是負(fù)面消極地發(fā)表不滿。很多用戶越來(lái)越依賴他人的評(píng)價(jià)來(lái)決定自己的消費(fèi)行為。所以,在這樣一個(gè)時(shí)代背景下,基于文本的情感分析研究有重大現(xiàn)實(shí)意義。
文本情感分析本質(zhì)上屬于文本二分類問題,問題的核心是將一段文本所表達(dá)的情感分為正向和負(fù)向兩類。決策樹、支持向量機(jī)、樸素貝葉斯等傳統(tǒng)的文本分類算法[1-6]在進(jìn)行文本情感分析時(shí),不能很好地考慮到詞與詞之間的關(guān)聯(lián)性以及詞語(yǔ)之間的極性轉(zhuǎn)移。隨著神經(jīng)網(wǎng)絡(luò)的不斷發(fā)展,許多研究自然語(yǔ)言的學(xué)者創(chuàng)新性地引入神經(jīng)網(wǎng)絡(luò)來(lái)改進(jìn)已有的語(yǔ)言模型。劉艷梅[7]結(jié)合支持向量機(jī)及循環(huán)神經(jīng)網(wǎng)絡(luò)的模型特征對(duì)文本分類器進(jìn)行改進(jìn),構(gòu)建出新的文本分類器,在微博獲取的文本數(shù)據(jù)上進(jìn)行實(shí)驗(yàn),實(shí)驗(yàn)結(jié)果良好。李陽(yáng)輝等人[8]針對(duì)情感分析問題中無(wú)標(biāo)記特征學(xué)習(xí)問題,提出了一種降噪自編碼器。朱少杰[9]完成了淺層特征與神經(jīng)網(wǎng)絡(luò)模型的融合,在該融合模型下文本情感分類的準(zhǔn)確率較之前有所提升。
1 基于LSTM的文本情感分析改進(jìn)模型的構(gòu)建
1.1 傳統(tǒng)LSTM模型在文本情感分析中的優(yōu)缺點(diǎn)
在文本情感分析中,長(zhǎng)短期記憶模型與以往傳統(tǒng)的分析模型相比,最重要的一點(diǎn)就是考慮了輸入文本的時(shí)序性[10]。與一般的數(shù)據(jù)樣本分類不同,文本情感分析的分類對(duì)象是一長(zhǎng)串的詞語(yǔ)序列、一段由詞語(yǔ)組成的文字或是若干篇由段落構(gòu)成的文章。在分類過(guò)程中,這些詞語(yǔ)若是被當(dāng)作一個(gè)個(gè)孤立的數(shù)據(jù)點(diǎn),那么訓(xùn)練出來(lái)的分類模型則只是考慮了文字表面上的特征,忽略詞與詞之間更深層的關(guān)聯(lián)性[11]。在SVM模型中,一般就一整句話中所包含的詞向量進(jìn)行均值處理,進(jìn)而作為模型的輸入數(shù)據(jù)[12-14]。但在LSTM網(wǎng)絡(luò)模型中,一整段話被視為一串文字序列,詞語(yǔ)間的相互關(guān)系得到體現(xiàn)。
盡管相較于傳統(tǒng)的文本分析方法,LSTM已經(jīng)有了很大的進(jìn)步,但是在模型內(nèi)部的參數(shù)更新以及模型優(yōu)化上依舊存在可以改進(jìn)的地方。在傳統(tǒng)的LSTM模型中,參數(shù)的更新主要使用的是梯度下降法[15]。根據(jù)梯度的性質(zhì),計(jì)算機(jī)能夠更加容易地找到目標(biāo)函數(shù)的最小值。而在機(jī)器學(xué)習(xí)算法中,一個(gè)優(yōu)秀的損失函數(shù)能夠使得模型在訓(xùn)練過(guò)程中更快地到達(dá)最優(yōu)點(diǎn)。當(dāng)損失函數(shù)最小時(shí),模型的分類效果最好。模型不斷迭代尋求最優(yōu)點(diǎn)的過(guò)程可以轉(zhuǎn)換為數(shù)學(xué)上對(duì)損失函數(shù)求解最小值的過(guò)程。
梯度下降的更新函數(shù)如下:
其中,lr為模型的學(xué)習(xí)率,可以理解為模型在迭代訓(xùn)練過(guò)程中每次向梯度下降方向所探測(cè)的步長(zhǎng)。然而,傳統(tǒng)的梯度下降法存在著一些弊端。梯度下降法主要有網(wǎng)格取值和隨機(jī)取值兩種。網(wǎng)格取值遍歷模型以求損失函數(shù)值最小的點(diǎn),但是容易陷入局部最優(yōu)的困境;隨機(jī)取值固然較網(wǎng)格取值更容易找到全局最優(yōu)的點(diǎn),但是隨機(jī)性使得其在尋找損失函數(shù)最小值的過(guò)程所花費(fèi)的時(shí)間較長(zhǎng)。
另外,在文本情感的分析過(guò)程中,交叉熵常被視為損失函數(shù)的一個(gè)好的選擇。在迭代過(guò)程中,損失函數(shù)值越小一般代表著模型的效果越好,但是這并不意味著損失函數(shù)值越小等價(jià)于模型的準(zhǔn)確率越好。從理論上來(lái)說(shuō),在損失函數(shù)的說(shuō)明中,提到的是損失函數(shù)值越小,模型最后得到的數(shù)據(jù)分布越接近數(shù)據(jù)的真實(shí)分布。如何在這一前提下,讓模型更有效率、更有目的性地進(jìn)行更新,原生的LSTM模型中并沒有考慮到。
1.2 梯度下降法改進(jìn)
針對(duì)原生LSTM模型在參數(shù)更新時(shí)隨機(jī)梯度下降法所帶來(lái)的不確定性的缺陷,該文提出了一種基于空間向量的偽梯度下降方法來(lái)改進(jìn)LSTM模型,以期新模型較之于傳統(tǒng)的LSTM模型在參數(shù)更新上更加有效。在空間向量中,兩個(gè)向量方向均是朝下時(shí)其合向量的方向也必定是向下的。借鑒空間向量中向量疊加的方法,建立如下參數(shù)更新方法:
(1)隨機(jī)取三個(gè)點(diǎn)x0(w0,L0),x1(w1,L1),x2(w2,L2),其中wi為第i個(gè)Input/Forget/Output Gate的weight值,Li為對(duì)應(yīng)的損失率。選取Loss值最大的點(diǎn),這里不妨設(shè)為x0。
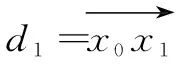
(3)確定參數(shù)更新的步長(zhǎng),因?yàn)樵贚oss值減小越多的方向步長(zhǎng)應(yīng)設(shè)置得越大,所以p1=
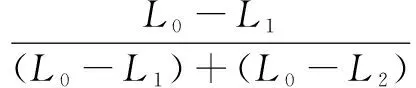
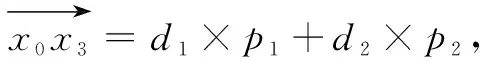
(5)直到模型的準(zhǔn)確率趨向穩(wěn)定。
考慮到隨機(jī)取點(diǎn)的不穩(wěn)定性,在這里將d1和d2替換成為當(dāng)前點(diǎn)的梯度相反方向以及前一個(gè)節(jié)點(diǎn)的梯度下降方向。這樣的替換不僅可以起到利用空間向量法取梯度下降方向的作用,而且也可以使得前一個(gè)點(diǎn)的梯度信息對(duì)當(dāng)前點(diǎn)的下降方向起到修正作用。
1.3 損失函數(shù)修正
一般地,交叉熵的損失函數(shù)表示形式為:
對(duì)于選定的閾值m,為了使得模型只針對(duì)處于敏感區(qū)域的“模棱兩可”的樣本進(jìn)行有選擇的更新,引入一個(gè)狀態(tài)更新方程μ(x)以及修正項(xiàng)λ(ytrue,ypred),其公式分別為:
λ=1-μ(ytrue-m)μ(ypred-m)-μ(1-ytrue-m)μ(0.9-ypred-m)
在新的損失函數(shù)中,若該文本樣本為積極情感樣本,則ytrue=1,代入函數(shù)得到λ(1,ypred)=1-μ(ypred-m),這時(shí)若ypred>m,即模型得出的概率值大于選定的閾值m,則損失函數(shù)為0,達(dá)到最小值,不會(huì)繼續(xù)更新;只有在ypred≤m的情況下,λ(1,ypred)=1,模型才會(huì)繼續(xù)進(jìn)行參數(shù)更新。若該文本為消極情感樣本,則ytrue=0,代入損失函數(shù)得到λ(0,ypred)=1-μ(1-m)μ(0.9-ypred-m),此時(shí)若ypred<0.9-m,則損失函數(shù)為0,達(dá)到最小值,不會(huì)繼續(xù)更新;只有在ypred≥0.9-m的情況下,λ(0,ypred)=1,模型才會(huì)繼續(xù)進(jìn)行參數(shù)更新。
2 實(shí)驗(yàn)設(shè)計(jì)及結(jié)果分析
2.1 實(shí)驗(yàn)數(shù)據(jù)及預(yù)處理
實(shí)驗(yàn)數(shù)據(jù)為30 000條已標(biāo)注的評(píng)論,涵蓋酒店、數(shù)碼產(chǎn)品、書籍以及日用品四類,每一類各7 500條評(píng)論。在每個(gè)類別中,積極情感評(píng)論與消極情感評(píng)論的分布比例是1∶1。將30 000條數(shù)據(jù)以4∶1的比例劃分成訓(xùn)練集與測(cè)試集用以模型的訓(xùn)練和測(cè)試。
利用jieba分詞庫(kù)將獲取到的已標(biāo)注文本進(jìn)行分詞,并去除了停用詞。統(tǒng)計(jì)每個(gè)句子經(jīng)過(guò)分詞后的詞數(shù)(見圖1),結(jié)果表明大多數(shù)的句子詞數(shù)都在50以內(nèi)。因此選取50作為L(zhǎng)STM模型中隱藏層的數(shù)量。

圖1 文本詞數(shù)分布
2.2 文本情感分析實(shí)驗(yàn)過(guò)程
2.2.1 改進(jìn)模型與傳統(tǒng)模型的對(duì)比實(shí)驗(yàn)
將訓(xùn)練文本通過(guò)Word2Vec算法模型映射成詞向量,該向量作為L(zhǎng)STM網(wǎng)絡(luò)模型的輸入。積極的評(píng)論標(biāo)簽為1,消極的評(píng)論標(biāo)簽為0。利用Keras搭建LSTM網(wǎng)絡(luò),隱藏層的節(jié)點(diǎn)數(shù)為256,參數(shù)優(yōu)化算法為改進(jìn)的偽梯度下降法,重新定義學(xué)習(xí)率,激活函數(shù)為sigmoid函數(shù),損失函數(shù)為二分類下的交叉熵Binary_cross_entropy,訓(xùn)練過(guò)程中batch_size為128,函數(shù)返回模型在訓(xùn)練時(shí)每個(gè)epoch結(jié)束后的loss值和準(zhǔn)確率,并最終返回在測(cè)試樣本上的準(zhǔn)確率。
在酒店、書籍、數(shù)碼產(chǎn)品以及日用品四大類別上分別用SVM模型、原生LSTM模型以及引入偽梯度下降法的LSTM模型,經(jīng)過(guò)多次實(shí)驗(yàn),均選取最后的分類結(jié)果,如表1所示。
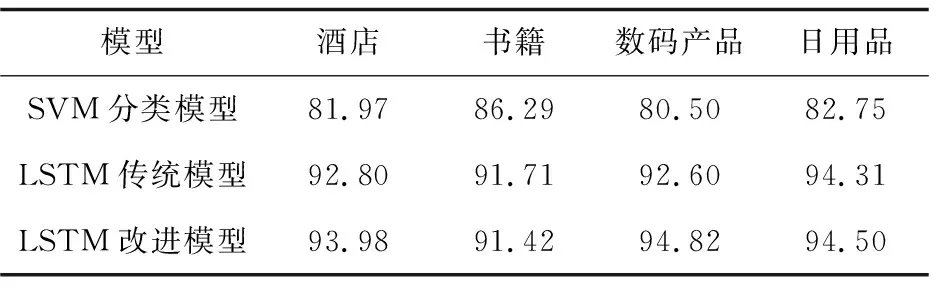
表1 三個(gè)模型在不同類別下的分類準(zhǔn)確率 %
從表1可以看到,在每個(gè)類別中LSTM模型的分類準(zhǔn)確率均高于SVM模型。這是因?yàn)镾VM模型在輸入時(shí)取的是句子中詞向量的均值,只考慮了詞語(yǔ)之間的組合關(guān)系,忽略了排列關(guān)系,不能反映詞語(yǔ)之間的相互聯(lián)系。
然后考察在整個(gè)樣本中,基于隨機(jī)梯度下降法的原生LSTM模型與基于偽梯度下降法的LSTM改進(jìn)模型在訓(xùn)練過(guò)程中準(zhǔn)確率和損失函數(shù)值的變化。從圖2中可以看到,原生LSTM模型在經(jīng)歷了600次迭代后達(dá)到一個(gè)穩(wěn)定的最高準(zhǔn)確值,約95%。隨機(jī)梯度下降雖然能夠?qū)ふ业饺肿顑?yōu)的點(diǎn),但是陷入局部最優(yōu)時(shí)需要較長(zhǎng)的時(shí)間才能走出困境。
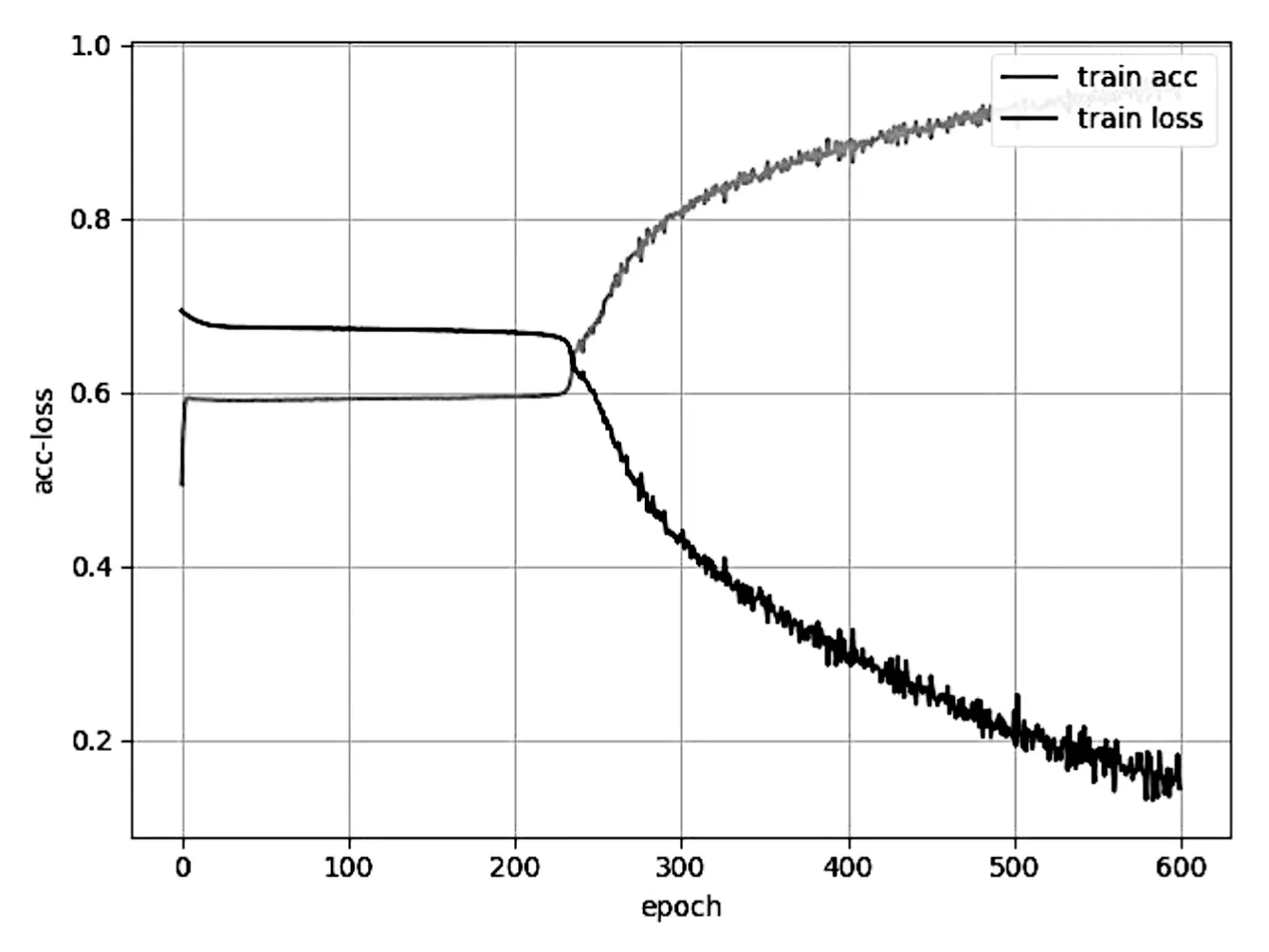
圖2 原生LSTM模型的迭代過(guò)程
而基于偽梯度下降法的改進(jìn)模型在更少的迭代次數(shù)內(nèi)達(dá)到了最高準(zhǔn)確率,約96.3%,如圖3所示。
2.2.2 閾值探究實(shí)驗(yàn)
對(duì)于改進(jìn)的模型,將所有測(cè)試文本通過(guò)Word2Vec算法模型映射成詞向量,該向量作為L(zhǎng)STM網(wǎng)絡(luò)模型的輸入。利用Keras中的model.predict()函數(shù)輸出每一個(gè)文本經(jīng)過(guò)模型計(jì)算后的分類預(yù)測(cè)值。該值是一個(gè)0到1之間的浮點(diǎn)數(shù),并計(jì)算出在不同閾值下測(cè)試樣本結(jié)果的真正的積極情感類別正確率與真正的消極情感類別正確率。根據(jù)不同閾值下,測(cè)試樣本中真正的積極情感類別與真正消極情感類別正確率的變化情況,確定模型中測(cè)試樣本結(jié)果表現(xiàn)不穩(wěn)定的閾值區(qū)間,并根據(jù)此區(qū)間修改模型的損失函數(shù),改進(jìn)模型。
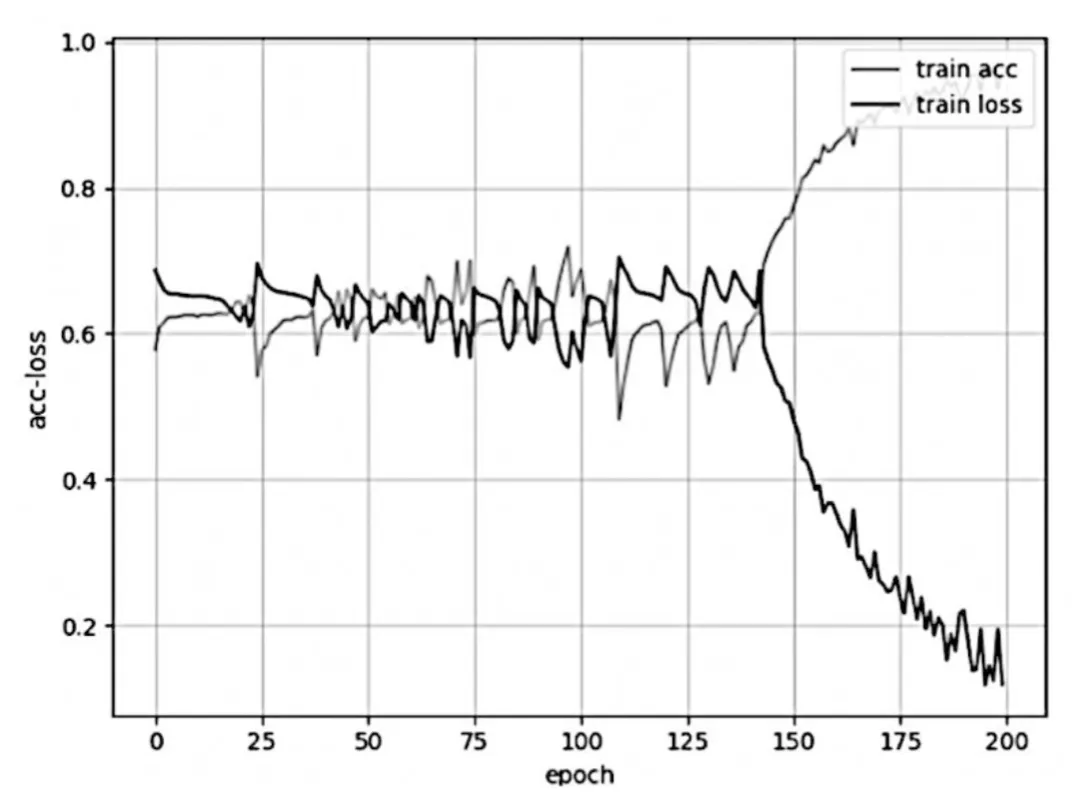
圖3 LSTM改進(jìn)模型的迭代過(guò)程
從圖4可以看到,在閾值取到0.425到0.475的區(qū)間時(shí),兩個(gè)類別的分類正確率的變化率較大,因此認(rèn)為0.425到0.475是對(duì)分類結(jié)果產(chǎn)生不穩(wěn)定影響的區(qū)間,應(yīng)該舍去。在閾值的選擇上,在模型計(jì)算出文本的情感概率值后,當(dāng)概率值大于0.475時(shí),判斷其是正向的、積極的情感;當(dāng)概率值小于0.425時(shí),判斷其是負(fù)向的、消極的情感;而[0.425,0.475]為分類閾值的敏感區(qū)域。
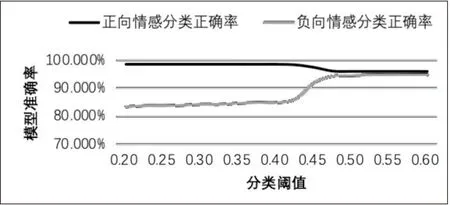
圖4 不同分類閾值下模型的分類準(zhǔn)確率
2.2.3 基于LSTM的文本情感分析改進(jìn)模型
重新定義了模型損失函數(shù)后,在所提出的偽梯度下降法和改進(jìn)后的損失函數(shù)的基礎(chǔ)上訓(xùn)練LSTM神經(jīng)網(wǎng)絡(luò)模型,在訓(xùn)練集的迭代過(guò)程中的模型正確率變化如圖5所示。
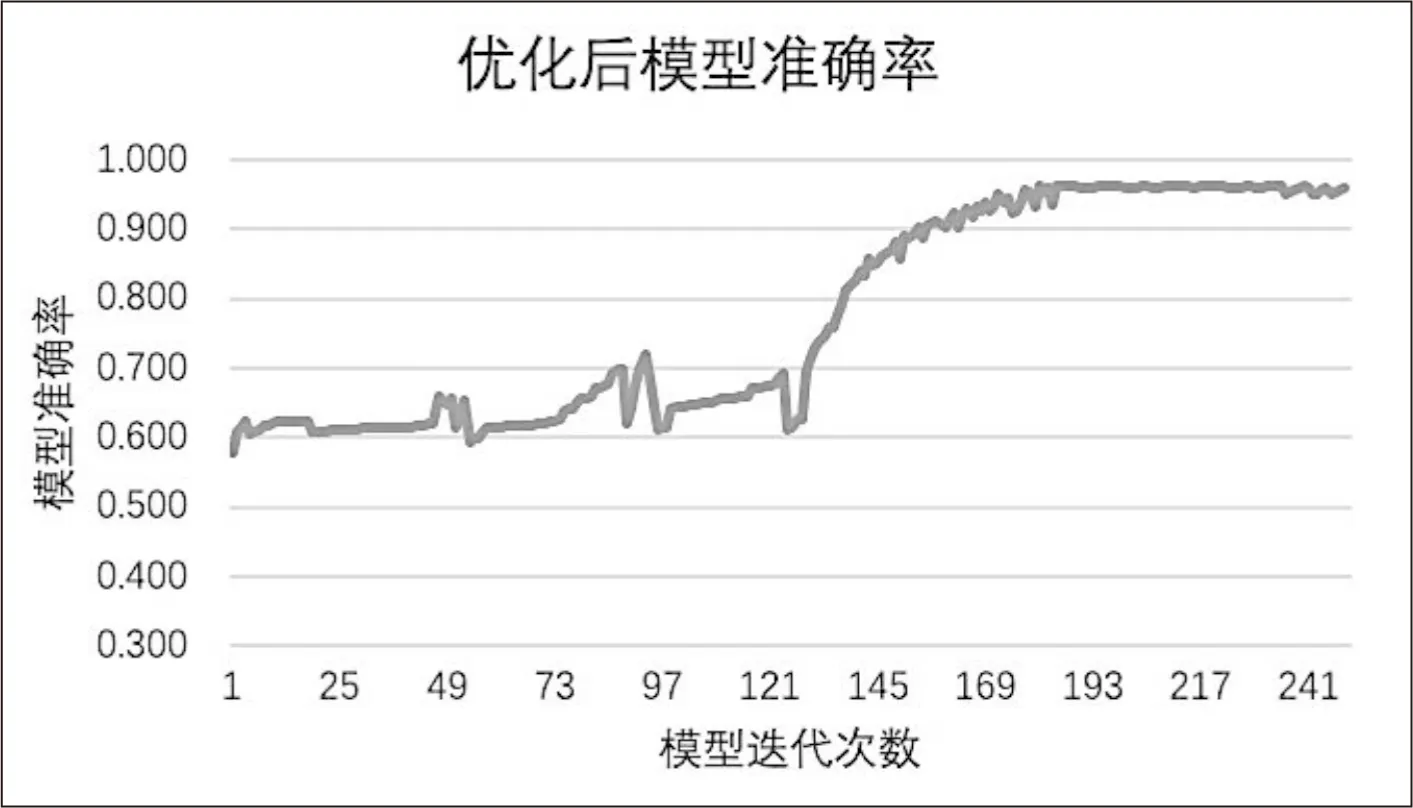
圖5 模型優(yōu)化后準(zhǔn)確率隨迭代次數(shù)的變化過(guò)程
2.3 實(shí)驗(yàn)結(jié)果分析
從圖6中可以看出,對(duì)于引入的LSTM模型,可以看到在書籍和日用品類別中,準(zhǔn)確率與原生的LSTM模型基本持平,在酒店和數(shù)碼產(chǎn)品類別中,改進(jìn)后的模型準(zhǔn)確率略高于原生模型的準(zhǔn)確率。這說(shuō)明引入了偽梯度下降法進(jìn)行參數(shù)更新的方法在樣本中的表現(xiàn)較之于隨機(jī)梯度下降法是有進(jìn)步的。
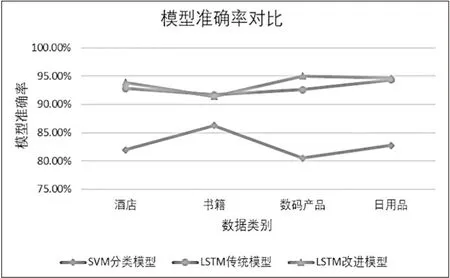
圖6 三個(gè)模型在不同類別下的分類準(zhǔn)確率對(duì)比
而損失函數(shù)修改后的LSTM模型較改進(jìn)的LSTM模型在分類正確率上減少了準(zhǔn)確率上下振蕩的情況,這說(shuō)明在迭代過(guò)程中文中定義的新?lián)p失函數(shù)的優(yōu)化具有意義,在一定范圍內(nèi)使模型具備了選擇性更新的能力。在達(dá)到模型最終準(zhǔn)確率的過(guò)程中,僅使用偽梯度下降法的模型在經(jīng)過(guò)大約200次迭代后達(dá)到最高準(zhǔn)確率,約96.3%;在修改了損失函數(shù)使得模型有選擇的進(jìn)行更新后,模型在大約205次迭代后達(dá)到最高準(zhǔn)確率,約96.8%。在迭代周期相差不大,最優(yōu)準(zhǔn)確率略有提升的情況下,二次優(yōu)化后的模型在到達(dá)最優(yōu)情況的過(guò)程中準(zhǔn)確率的振蕩情況改善很多,所以修改損失函數(shù)對(duì)模型的改進(jìn)具有重要的現(xiàn)實(shí)意義。
3 結(jié)束語(yǔ)
該文主要是在LSTM神經(jīng)網(wǎng)絡(luò)模型的基礎(chǔ)上提出并實(shí)現(xiàn)基于LSTM改進(jìn)型的文本情感分析模型。使用長(zhǎng)短期記憶模型進(jìn)行文本情感分析,與常用的支持向量機(jī)模型相比,克服了無(wú)法保留輸入序列時(shí)序性的問題,可以挖掘到詞語(yǔ)之間更深層次的關(guān)系。但是,LSTM模型本身在進(jìn)行模型訓(xùn)練的過(guò)程中使用的隨機(jī)梯度下降模型對(duì)模型訓(xùn)練過(guò)程中的參數(shù)更新帶來(lái)不確定性[16-17]。另一方面,在文本情感分類時(shí),分類閾值的選取左右著最后的分類效果,常用的0.5作為分類閾值并沒有科學(xué)的解釋。在此基礎(chǔ)上,傳統(tǒng)模型中采用的交叉熵?fù)p失函數(shù)與模型的準(zhǔn)確率只存在經(jīng)驗(yàn)上的相關(guān),并不是完全的等價(jià)[18]。
基于以上問題,提出了基于空間向量的偽梯度下降法,探究了在已標(biāo)注的文本數(shù)據(jù)中合理的分類閾值區(qū)域,并根據(jù)該區(qū)域自定義了新的損失函數(shù),以期讓模型在訓(xùn)練過(guò)程中更有效率地選擇性更新。因此,主要做了如下實(shí)驗(yàn):
對(duì)文本情感分析模型進(jìn)行對(duì)比分析,將SVM模型、原生的LSTM文本情感分析模型以及使用空間向量法改進(jìn)后的文本情感分析模型的實(shí)驗(yàn)結(jié)果進(jìn)行對(duì)比,分析實(shí)驗(yàn)結(jié)果,找出改進(jìn)后模型的不足。探究在該模型中不同的分類閾值下積極情感和消極情感的分類準(zhǔn)確率,找出變化率較大的區(qū)間,即為較敏感的分類閾值不穩(wěn)定區(qū)間。在此區(qū)間上,修改模型的損失函數(shù),進(jìn)行驗(yàn)證。
最終,完成了一個(gè)基于偽梯度下降法以及帶有修正項(xiàng)損失函數(shù)的LSTM文本情感分析模型,模型在測(cè)試樣本上的分類正確率約為96.8%。實(shí)驗(yàn)結(jié)果表明,提出的改進(jìn)在實(shí)驗(yàn)中對(duì)模型正確率有改進(jìn)作用,說(shuō)明這一方案具有現(xiàn)實(shí)意義。同時(shí),該模型為分類模型的參數(shù)更新提供了一個(gè)新的思路。
猜你喜歡
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
中國(guó)生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽(yáng)畫報(bào)(2019年10期)2019-11-04 02:57:59
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中國(guó)生殖健康(2018年5期)2018-11-06 07:15:40
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
