注入主流價值導向的電影個性化推薦研究
2020-12-31 01:08:14孫宜宋卿
現代電影技術 2020年8期
孫 宜 宋 卿
(中國傳媒大學,北京 100024)
1引言
2019年8月30日,中國互聯網絡信息中心(CNNIC)發布了第44次《中國互聯網絡發展狀況統計報告》。報告表明,截止2019年6月,中國網民數量達到8.54億,手機網民數量達到8.47億,網絡視頻用戶規模達到7.59億,約占我國人口總數的54.2%。
個性化推薦技術本質上是系統主動進行內容和用戶的匹配,因此內容標簽和用戶標簽就成為個性化推薦的基礎。其中,用戶標簽往往也被稱為用戶畫像技術。用戶畫像近年來在個性化推薦領域發展非常迅速,該技術可以多維立體地將用戶的行為偏好抽象成一個個標簽,用戶的標簽與電影的標簽相匹配,再結合目前常用的協同過濾推薦算法,便可以達到高速有效地為用戶推薦電影的目的。
對于電影的個性化推薦不僅要考慮到算法的準確度,還要考慮電影的社會功能。將主流價值觀的注入與推薦算法結合,可以平衡現代互聯網技術與大眾文化,為人民群眾所喜聞樂見。
2 相關工作
“個性化推薦”的概念最早在1995年被提出,美國卡耐基梅隆大學的羅伯特·阿姆斯特朗等人在美國人工智能協會上提出的個性化導航系統采用了“個性化推薦”的概念。幾乎同時,斯坦福大學的研究者也提出了一個個性化推薦系統,拉開了個性化推薦的發展序幕。
20世紀90年代,推薦算法開始被研究。目前較為常用的推薦算法有基于關聯規則的推薦、基于內容的推薦、協同過濾推薦和混合推薦等。在電影的個性化推薦中,協同過濾推薦算法使用最為廣泛。
鄧愛林等提出了一種基于項目評分預測的協同過濾推薦算法,通過對項目之間相似性的分析,對未打分的商品進行預測,以解決電子商務中用戶評分極端稀疏情況下傳統推薦系統存在的弊端,顯著提高推薦系統的質量;張光衛等人將云模型與協同過濾算法結合起來,利用云模型在知識層面分析用戶相似度以達到更好的個性化推薦效果;范波等人通過分析用戶對多個不同類型項目的評分相似度,提出了用戶間多相似度的協同過濾算法,有效提高了預測用戶評分以及個性化推薦的準確率;朱磊等提出將用戶的評分偏好與時間因素、物品屬性結合起來,改進相似度的度量公式,有效提高個性化推薦的準確度;畢閏芳針對電影個性化推薦系統提出了基于SVR的協同過濾和用戶畫像融合的推薦算法,將用戶對電影內容的偏好以用戶畫像的方式融入到協同過濾中,獲得更好的推薦效果。
當下,對于個性化推薦的研究多是以提高推薦準確率為目的,誠然高準確度的推薦系統提高了用戶體驗,也幫助網站提升了轉化率。但完全依賴于機器學習的推薦系統也漸漸將用戶困于“信息繭房”中,在算法中加入價值觀引導成為不可避免的趨勢。
3 關鍵技術
3.1 用戶畫像
用戶畫像是對用戶的基本信息與行為信息進行高度凝練得到的特征標簽集合,“貼標簽”是構建用戶畫像最核心的工作。
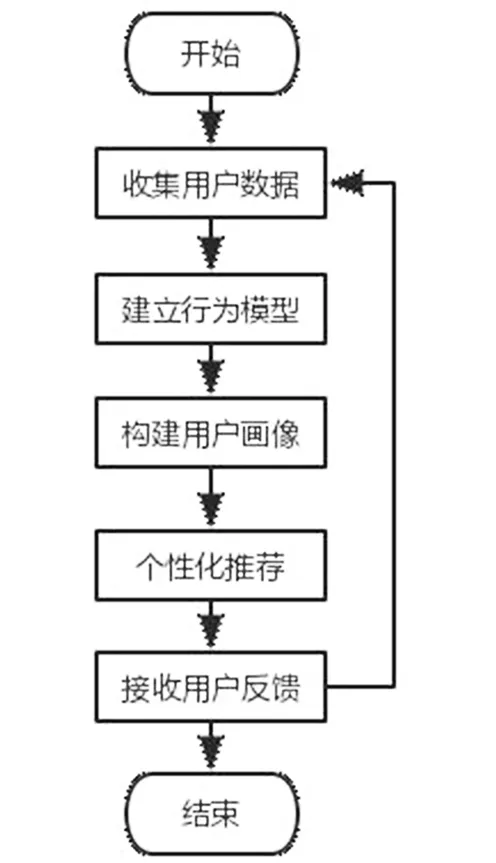
圖1 用戶畫像構建流程圖
構建用戶畫像包括基礎數據收集、行為建模、構建畫像三步,畫像構建完畢后對用戶進行每一次個性化推薦時,將用戶的反饋納入到數據收集環節,再次進行構建用戶畫像的流程,如圖1所示,以此循環可將用戶畫像動態化,提高推薦的準確度。
用戶數據的收集主要分為靜態數據收集與動態數據收集兩種。靜態數據主要是用戶填寫的個人資料,包括姓名、性別、年齡等自然屬性,職業、學歷、婚姻狀況等社會屬性,這些數據通常具有較高的穩定性,在較長一段時間內不會發生非常大的改變。而動態數據主要是從用戶的行為和偏好中得到的數據,包括用戶的瀏覽行為信息數據、偏好行為信息數據和交易行為信息數據。
在獲取了用戶的基礎靜態信息和行為信息后,利用自然語言處理、機器學習、聚類算法、預測算法等技術,抽象出用戶的個性化標簽,對用戶行為進行建模。一個行為模型主要包括時間、地點、人物、方式、內容五要素,具體可以描述為什么用戶(who)在什么時間(when)什么地點(where)以什么方式(how)做了什么事(what)。
通過技術手段對用戶行為進行建模后,則可以針對具體的應用場景為用戶定義多維度的標簽體系,以可視化的方式構建出用戶畫像。
3.2 協同過濾算法
協同過濾推薦算法主要通過用戶過去的行為與相似用戶的行為來預測用戶未來可能感興趣的項目,以達成精準化、個性化推薦效果。在實際應用中,基于用戶的協同過濾算法與基于項目的協同過濾算法通常是結合起來使用的。
基于用戶的協同過濾算法是通過對有相似偏好的不同用戶進行交叉推薦,以達到給用戶推薦可能感興趣的項目的目的。尋找行為偏好相似的用戶是使用基于用戶的協同過濾算法的前提,故這一算法的核心是用戶之間相似度的計算。使用適用于特定環境的方法完成對用戶相似度的計算后,可對用戶群體進行分類或聚類,在未來的觀影行為中同類的用戶之間更有可能有相似的喜好,因而可以向用戶推薦同類用戶觀看過而本人未觀看過的電影。
基于項目的協同過濾算法是通過分析用戶以往感興趣的項目,將與之相似的項目推薦給用戶的推薦算法。與基于用戶的協同過濾算法相似,基于項目的協同過濾算法的核心便是判斷項目之間的相似性。除了傳統的相似性判斷方法外,在電影領域,還可以通過電影的導演、演員等要素對電影進行基于一定權重的直接劃分,進而找到相似的電影進行推薦。
4 注入主流價值導向的電影個性化推薦
4.1 電影個性化推薦算法的價值觀缺失問題分析
電影個性化推薦算法過于單一時容易使用戶陷于“信息繭房”,視野逐漸窄化。推薦算法的極端情況便是“你喜歡什么,你的世界就只剩下什么”。每天看到相似甚至是相同的電影推薦,漸漸地就會給用戶一種“電影都是這樣”的錯覺,極大地限制了用戶的視野,久而久之,便會在不知不覺中將用戶困在興趣的小圈子里,就像是困在一個“繭房”中。在更極端的情況下,用戶甚至會出現“信息異化”的情況,個人想法被看到的信息所影響,成為被信息支配的奴隸,不再具有作為信息控制主體的能力。若用戶本身的情感傾向與價值觀就與主流價值觀相悖,那推薦算法就可能將他引入歧途。
在當今的網絡環境之下,“流量明星”具有巨大的影響力,這并非健康的網絡環境應有的特征。為改善這一情況,一方面要對內容加強監管,盡量控制流量明星的龐大粉絲群進行“控評”“刷屏”等行為,另一方面也要主動出擊,利用個性化推薦算法來弘揚主流價值觀。
電影不同于高度依賴個性化推薦的短視頻,短視頻不僅有高度的娛樂功能,還具有非常重要的教化功能。因此傳統的個性化推薦算法不能全然照搬到電影推薦領域中,主流價值觀的注入成為必然。
4.2 打破個性化推薦算法的“信息繭房”
基于協同過濾的推薦算法不同于以今日頭條為代表的新聞客戶端所使用的基于內容的推薦算法,它將推薦的維度提高,將“人群”作為推薦的基數數據,不斷進行優化和迭代。基于協同過濾的推薦算法相較于基于內容的推薦算法擁有更大的靈活性,其推薦的內容也更加豐富,可以有效避免用戶接收到的信息窄化的問題,打破“信息繭房”。
個性化推薦依賴機器學習與深度學習,它足夠智能化,卻不夠人性化,而多元化、開放式、動態化的推薦算法可以在一定程度上規避算法帶來的缺陷。為打破“信息繭房”,需要改進算法,使用糾偏技術。不但要動態跟蹤用戶的使用行為和使用偏好,及時轉變推薦的重心重點內容,還要定期給用戶推薦非計劃中的電影,找到用戶可能感興趣但目前還沒有了解過的電影,拓寬用戶的視野,打破“信息繭房”,讓推薦算法更人性化。
4.3 個性化推薦算法注入主流價值觀
在互聯網上的傳播環境是一個逐漸去中心化的系統,在這樣的前提下,視頻網站與視頻客戶端必須把握住意識形態的主動權。作為一個傳播平臺,必須有以多樣化的方式宣揚社會主義核心價值觀的意識和作為。對主流價值觀的注入不僅要依靠集中力量加強人工審核,結合大數據技術進行溯源,把握不良電影和不良畫面的來源,從源頭上遏制不良內容流出,提高電影質量,還要從推薦系統本身入手,拒絕簡單粗暴的置頂方式,更加人性化地對價值觀進行個性化引導。
電影的推薦本質上是對文化的傳播過程,這一過程會對用戶產生潛移默化的作用,進一步會對整個社會的風氣和價值觀產生巨大的影響。當前廣泛使用的用戶畫像的標簽體系中,通常沒有主流內容的標簽維度,而在電影的個性化推薦中主流內容的標簽維度是必不可少的。對于主流內容標簽,應根據具體情況對其權重進行適當加強,在尊重用戶興趣的前提下,將主流價值觀以多樣化的方式傳遞給用戶。
將用戶畫像與協同過濾算法結合不僅可以很好地解決協同過濾算法忽略用戶對電影內容的偏好的問題,在用戶畫像構建過程中,通過分析用戶的行為數據,特別是對評論等文本信息進行情感分析,還可以獲得用戶在一定時間段內的情感傾向,當用戶出現負面情緒或價值觀明顯偏離主流正確價值觀方向時,及時做出反應,將部分包含正面情緒和主流的正向價值觀的內容推薦給用戶,改變“算法無價值觀”的現狀。
5 總結與展望
隨著5G移動網絡的建設和高清編碼技術的發展,會有越來越多的用戶隨時隨地通過移動終端觀看4K/8K高清電影。個性化推薦技術的引入,恰好能夠幫助我們在紛繁復雜的電影資源庫中快速找到那一部“對”的電影。
在目前人工智能大發展、大數據技術大應用的背景下,個性化推薦技術已經成為內容傳播行業的標準配置,也將成為線上電影行業持續健康發展的突破口。用戶畫像基于用戶自身數據的采集分析,幫助視頻網站更加懂得用戶所想,為每一個用戶打造與眾不同的觀影體驗。而用戶畫像與協同過濾算法融合,將“歷史行為”“用戶分群”“電影內容”都作為推薦的基數數據,不斷進行優化和迭代,具有更大的靈活性,其推薦的電影準確性也會得到一定的提高,在此過程中,通過對用戶情緒與價值觀的監測并及時做出反應,可以有效避免用戶接收到的信息窄化問題,對用戶的價值觀進行及時的引導。

猜你喜歡
科學大眾(2022年11期)2022-06-21 09:20:52
小天使·一年級語數英綜合(2022年4期)2022-04-28 08:42:36
建材發展導向(2021年6期)2021-06-09 05:58:06
商用汽車(2016年11期)2016-12-19 01:20:16
臺聲(2016年2期)2016-09-16 01:06:53
商用汽車(2016年6期)2016-06-29 09:18:54
現代企業文化·綜合版(2016年6期)2016-05-14 16:38:34
商用汽車(2016年4期)2016-05-09 01:23:12
學習月刊(2015年9期)2015-07-09 05:33:44
創業家(2015年5期)2015-02-27 07:53:25
