基于密集連接塊U-Net的語義人臉圖像修復
2020-12-31 02:24:42楊文霞
計算機應用 2020年12期
楊文霞,王 萌,張 亮
(1.武漢理工大學理學院,武漢 430070;2.廣西科技大學啟迪數字學院,廣西柳州 545006)
(?通信作者電子郵箱mwang007@gxust.edu.cn)
0 引言
圖像修復[1]是針對圖像的缺損部分,填入符合視覺常識及圖像語義的數據,以生成具有真實感的圖像處理。圖像修復在目標隱藏、圖像信息理解、場景補全等領域有廣泛的應用。傳統的基于模型的修復方法,如基于偏微分方程的擴散模型[2-3]和基于樣例的圖像修復[4],不能正確捕捉和修復圖像的語義。例如,對于被遮住鼻子和眼睛的人臉,上述方法無法理解和生成語義圖像目標。
語義圖像修復,不僅要保證修復圖像結構和紋理的空間一致性,而且要求修復符合視覺常識。生成對抗網絡(Generative Adversarial Network,GAN)[5]依賴于大型數據集,將圖像修復看成圖像生成與推斷問題,具有學習與推理圖像語義的能力。Pathak 等[6]首先將深度學習用于圖像修復,使用編碼器-解碼器CE(Context Encode)結構的深度網絡,通過編碼器將待修復圖像特征映射到低維特征空間,解碼器端通過反卷積重建輸出信號。Yeh等[7]利用均勻分布的隨機變量z來訓練深度卷積GAN(Deep Convolutional GAN,DCGAN),然后利用該訓練好的網絡,通過引入l2損失和先驗損失生成修復圖像。Iizuka 等[8]提出了GLC(Globally and Locally Consistent image completion),使用擴張卷積,通過引入一個局部和全局性判別器,來保留圖像的空間結構。以上兩種方法需用泊松混合后處理方法[9]以保證修復區域邊界與周圍像素的連續性,而泊松混合算法使用迭代優化進行求解,訓練時間較長。Yu等[10]引入由粗到細的兩階段修復方法,首先得到缺損區的粗略估計,然后引入注意力機制,來搜索數據集中和初步結果有高度相似性的圖像塊,對粗略結果精細化。袁琳君等[11]提出一個兩階段修復算法,利用姿態關鍵點實現人像精細姿態修復。上述方法主要針對圖像的固定中心模板修復,對任意模板的修復效果較差。此外,還可利用預訓練輔助網絡或輔助信息指導修復過程。Yu 等[12]引入門控卷積(Gated Convolution,GC),利用手繪待修復區間的草圖骨架信息來引導修復,但修復結果依賴于邊界草圖效果。
Hong 等[13]提出了DF(Deep Fusion),通過引入特征融合網絡對U-Net[14]進行改進而進行圖像修復;洪漢玉等[15]利用U-Net 模型,檢測繩帶并進行航拍圖像去繩帶修復;陳俊周等[16]提出一個級聯對抗網絡,使用密集連接塊(Dense Block,DB)[17]實現對人臉圖像的矩形區域修復。上述方法主要針對小目標效果較好,但當待修復區域變大時,由于圖像待修復區域語義缺失,且深度卷積本身會損失圖像信息,修復效果不可避免存在視覺不合理及修復邊界不連貫現象。
針對上述問題,考慮U-Net 網絡結構在提取圖像語義方面的優越性能,以及密集連接網絡在圖像特征再利用方面的優勢,本文提出了基于密集連接塊的U-Net 結構的端到端人臉圖像修復模型,實現對任意形狀的語義修復。本文的主要工作如下:1)網絡結構汲取了密集連接和U-Net 網絡的優點,將U-Net 中的普通卷積模塊用密集連接塊代替,使用跳連接來提取圖像缺損區域的語義,可有效促進下采樣過程中的特征再利用;這些再利用可以有效彌補圖像缺損部分的特征損失,在增強特征傳播的同時,緩解梯度消失的問題。2)提出了一個聯合損失函數,通過引入全局對抗損失、內容損失和局部總變分損失訓練生成器,通過Hinge 損失[12]訓練判別器。其中總變分損失不是直接計算生成圖像全圖的總變分,而是計算待修復區域與其周圍環繞真實圖像的局部的總變分,使修復邊界具有自然的顏色過渡,且避免了全圖模糊。
1 模型網絡結構設計
本章詳細介紹所提修復模型的網絡結構與工作原理。網絡由一個生成器和一個判別器組成,如圖1 所示。給定一幅原圖Igt,以及一個0-1模板M,這里M和Igt的大小相同,
M的元素為1 的位置代表待修復區域。生成網絡G的輸入圖像為含缺損區域的待修復圖像Igt⊙(1-M),生成器生成的圖像為Igen,則修復后的輸出圖像為:
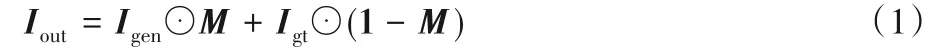
式中,⊙代表Hadamard 乘積。判別器D接收到合成的圖像后,試圖區分它是真還是假,并將結果進行反饋以提高判別器精度。通過生成器和判別器的損失函數分別對生成器和判別器進行訓練,直到收斂。
1.1 生成器結構
生成器網絡采用編碼器-解碼器(Encoder-Decoder)架構,編碼器(也稱下采樣)和解碼器(也稱上采樣)各由四個密集連接塊組成,由瓶頸層(bottleneck)相連。使用編碼器-解碼器結構可以增加輸入圖像的平移、旋轉等基本變換的魯棒性[6],這對具有姿態變化的人像圖像的修復非常重要;同時,該結構可以減少過擬合的風險,使用下采樣可以增加感受野,減少參數存儲計算量。
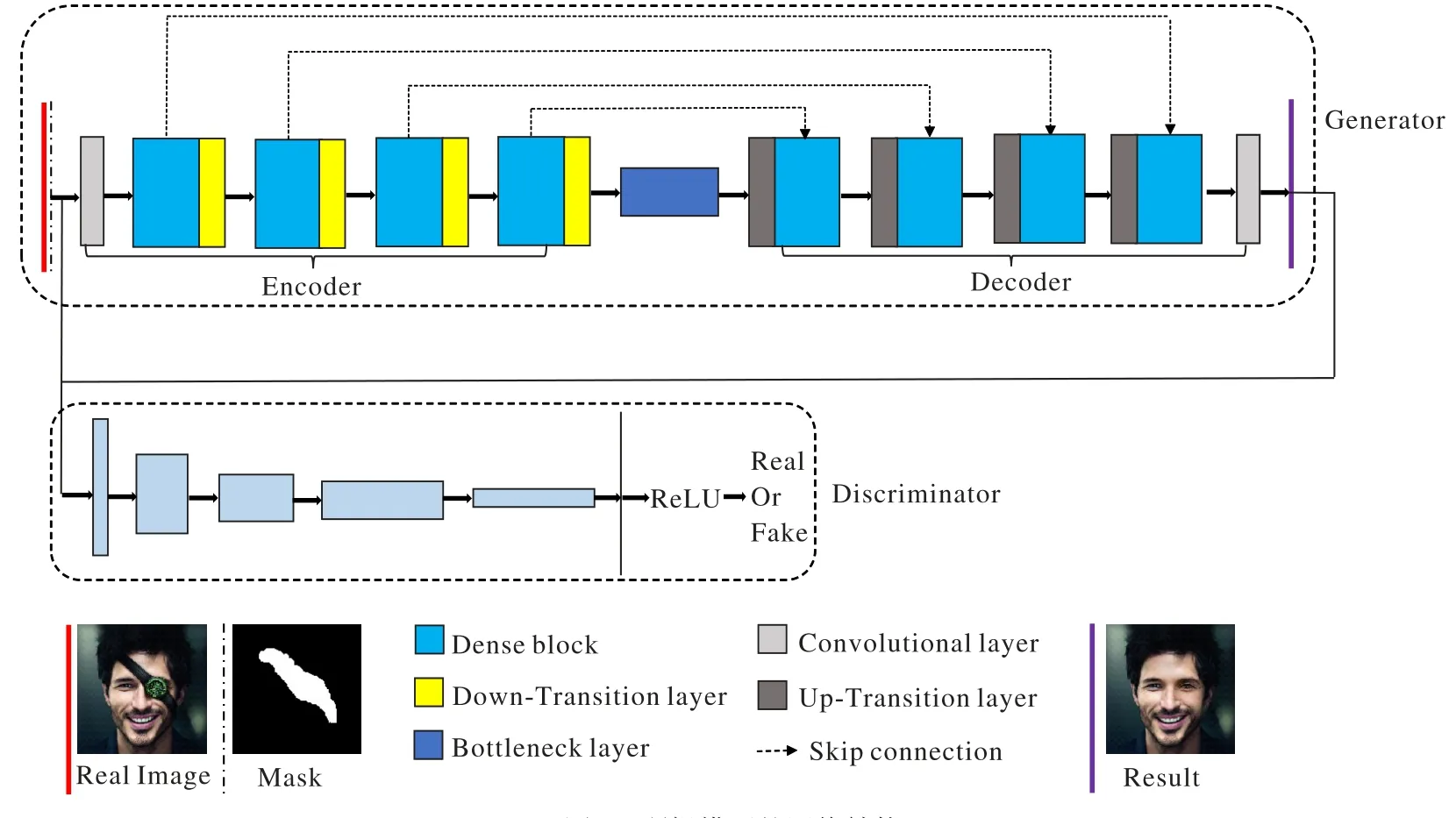
圖1 所提模型的網絡結構Fig.1 Network structure of proposed model
1.1.1 編碼器結構
在編碼器側,輸入圖像首先由64 個3×3 的卷積核生成初始卷積圖,然后進入第一個密集連接塊。每一個密集連接塊由L個密集層組成。每個密集層由卷積層、Batch Normalization 層和線性整流函數(Rectified Linear Unit,ReLU)層組成,其中所有卷積層卷積核大小為3×3,輸出和輸入具有相同的特征圖尺寸,以便于和其他特征圖進行拼接。每一個密集層產生k個特征圖,這k個特征圖通過和前面所有層的輸入拼接之后,輸入到下一層。后面層接受前面所有層的特征圖,并輸出k個特征圖,每個密集連接塊的最終輸出是前面所有的輸入和輸出特征圖之和,因此,k也叫增長率。密集連接確保了層之間的信息傳遞,提高梯度流動。為方便顯示,一個具有三個密集層,增長率為3(L=3,k=3)密集連接塊的結構如圖2所示。
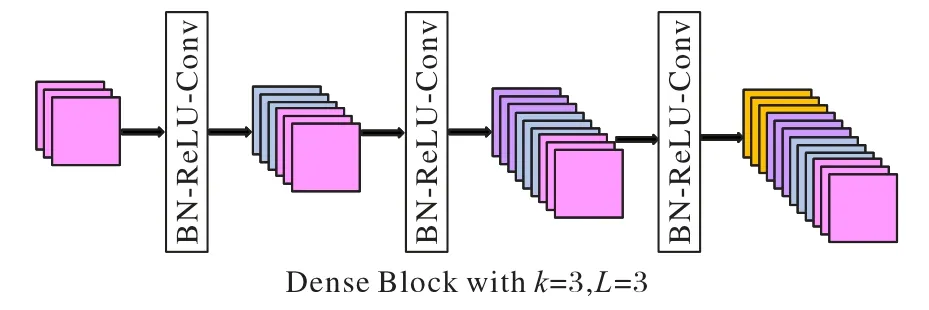
圖2 三層密集連接塊示意圖(k=3)Fig.2 Schematic diagram of dense block of three layers(k=3)
編碼器在每一個密集連接塊后,引入一個下采樣過渡層(Transition Down layer,TD),該過渡層接受前面所有的特征圖,并將特征圖尺寸減半。下采樣過渡層由1×1卷積層及2×2池化層組成。通過四層密集連接塊形成的編碼器后,最終得到8×8×1 024 的低維瓶頸層(Bottleneck Layer,BL),然后進行解碼。
1.1.2 解碼器結構
本網絡生成器的數據流信息如表1所示。

表1 生成網絡的數據構成Tab.1 Data composition of generative network
解碼器同樣由4 個上采樣塊密集連接塊和上采樣過渡層加上一個全卷積層組成。上采樣密集連接塊結構與下采樣密集連接塊結構類似。同樣,在不同上采樣密集連接塊之間,引入上采樣過渡層(Transition Up layer,TU),上采樣過渡層由1×1 卷積層及一個轉置卷積層組成,以接受前面所有特征圖,并增大一倍特征圖尺寸。
為更好地搜尋和提取圖像缺損區的語義信息,在上采樣和下采樣之間的相同分辨率的特征圖之間引入跳連接(Skip Connection),這些跳連接不僅向解碼器提供低維特征信息,也提供了從淺層向更深層提供更多梯度流信息,從而改進訓練速度,提高訓練性能。
1.2 判別器結構
判別器D的輸入是大小為256×256×3 的圖像Iout,判別器判別該輸入圖像是否為真實圖像。判別器使用步幅為2 的卷積層進行維度縮減,經過6 個下采樣塊后圖像維度變成4×4,鋪平后,經過最后的全連接層,輸出判別器的結果。卷積層均采用3×3 大小的卷積核,激活函數均為LeakyReLU。使用Dropout正則防止過擬合,Dropout概率為p=0.2。輸出層采用Tanh激活函數。
2 損失函數與隨機模板生成
2.1 損失函數
本文使用全局重建損失Lrec、對抗損失Ladv和局部總變分(Total Variation,TV)損失LlocalTV這三者的聯合損失對生成器進行訓練。使用l1損失作為重構損失,用來衡量生成圖像Igen和真實圖像Igt的相似程度,即

該損失保證生成器產生預測目標的粗輪廓,但如果僅用重構損失,模型只生成模糊圖像,并沒有清晰的邊界和紋理信息。因此,加入對抗損失來判別生成的修復圖像是來自生成器,還是來自真實的圖像,通過訓練使得使結果具有更多的邊緣和紋理結構。對抗損失定義為:

其中,D表示判別器的輸出結果。但該對抗損失只判斷待修復區域內圖像真偽,反向傳播時很難對已知區域產生影響,因此造成修復區域的邊界位置像素不連續。為改善修復區域和已知區域邊界像素的視覺一致性,本文對生成器加入局部總變分損失(Local Total Variation)LlocalTV,其定義為:
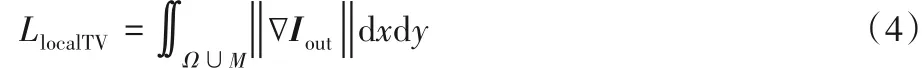
最終生成器損失函數為:
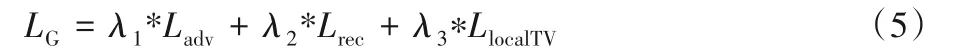
實驗中參考文獻[12]的建議,經過對比實驗后選擇λ1=0.1,λ2=1,λ3=0.05。對于判別器,使用hinge 損失作為目標函數來判別輸入圖像的真偽。hinge 損失對于判別器的輸出有截斷,更加關注輸入圖像是否真實本身,而不是真實程度。在實際訓練過程中,hinge 損失更加穩定,收斂速度也更快。其定義為:


圖3 M、Ω及局部總變分計算區域Ω ∪MFig.3 M,Ω and area Ω ∪M to calculate local total variation
2.2 隨機待修復模板生成
在實際修復圖像時,待修復區域大小和形狀都是未知的隨機模板,因此在訓練過程中生成隨機待修復模板至關重要。隨機模板需與實際使用時類似,即針對訓練集中的每一張圖像隨機生成不同的模板。本文在訓練和測試過程中,隨機生成兩種不同形狀的隨機模板:第一類是位置和大小隨機的矩形模板;第二類是具有隨機條狀及圓形的組合模板。這兩類模板出現的概率各種為1/2。隨機條狀的像素寬度在[4,14]上均勻分布,圓形模板的半徑在[3,10]上均勻分布。隨機模板生成算法如下。
算法1 生成隨機形狀模板。
步驟1 初始化:設二維數組Mask=0,Mask大小和圖像大小一致,H和W分別是圖像高和寬。
步驟2 初始化模板面積占比Ratio=0。
步驟3 生成[0,1]上均勻分布的隨機數p。如果p> 0.5,生成位置和面積隨機的矩陣模板;否則,生成隨機方向和隨機寬度的條狀模板,生成隨機圓心和半徑的圓形模板。
步驟4 計算模板面積占比Ratio,如果Ratio小于30%,則轉步驟3;否則結束。
在模型訓練和測試過程中,對每一張圖像施加不同隨機模板以得到待修復圖像。在應用于實際圖像修復時,隨機模板必須能通過交互操作指定。因此,開發了一個圖形用戶界面程序,使用戶能用鼠標以類似畫筆的形式生成自定義隨機模板,也可通過導入0-1 二進制圖像文件作為隨機模板,以實現單張圖像的修復。
3 實驗與結果分析
3.1 數據集與運行環境
在人臉數據集CelebA-HQ[18]上測試了本文圖像修復模型。該數據集共30 000張圖像,選取26 000張為訓練集,其余4 000 張為測試集,分辨率為256×256。模型使用TensorFlow v 1.9 和CUDA 10.0 訓練,分別使用中心模板(占圖像面積的25%)和2.2 節中算法生成的隨機模板進行訓練。生成器生成和原圖大小相同的圖像,并按式(1)合成最終結果。訓練時mini-batch 的尺寸為16,初始學習率為lr=2×10-3,在迭代過程中,使用逐漸降低,這里total_iter是總迭代次數,iter是當前迭代次數。在訓練過程中通過tensorboard 查看損失函數,觀察訓練約40 個epoch可收斂至較穩定狀態。
3.2 實驗結果定量比較
如文獻[12]所述,圖像修復缺乏很好的定量衡量參數,視覺和語義合理性是其最終目標。在大多數實際應用場合,如從人臉圖像上移去遮擋目標,和真實圖像(被遮擋的圖像)相比缺乏合理性,甚至有時沒有真實圖像做對比。但考慮到此數據集的大多數圖像均為無遮擋的正面人臉圖像,一些傳統的衡量圖像相似性的參數在此數據集上仍具有參考意義。因此,使用峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)及結構相似性指數(Structure SIMilarity index,SSIM)這兩個傳統參數來衡量測試集的平均修復效果,SSIM 的窗口尺寸為11。此外,對測試集的圖像在進行修復時,不同文獻的方法在測試時所生成的修復模板是隨機而各不相同的。因此,再引入Frechet Inception 距離(Frechet Inception Distance,FID)[19]來衡量不同模型的生成圖像和真實圖像的特征距離。在同一數據庫上進行實驗,將本文方法與不需要輔助數據集的最新文獻方法進行對比,對比模型分別是GLC[8]、DF[13],以及GC[12]。表2是不同方法的實驗結果。由表2可以看出,本文模型的定量指標優于其他對比模型。相較性能第二的GC模型,本文模型中心模板修復的SSIM 和PSNR 分別提高了5.68% 和7.87%,FID 降低了7.86%;本文模型隨機模板修復的SSIM 和PSNR分別提高了7.06%和4.80%,FID降低了6.85%。

表2 實驗結果定量對比Tab.2 Quantitative comparisons of experimental results
3.3 人臉圖像修復定性分析
本節按人臉修復的不同應用場合與目的,展示本文模型和對比模型的實驗結果。根據圖像修復的應用場合,分成展示人臉生成與修復、人臉物體移除(反遮擋)及數據集外的普通人臉修復。實驗結果表明,本文模型在各類應用場合均具有良好的效果。
3.3.1 不同面積矩形區域修復結果
為測試模型對人臉圖像語義抓取和生成能力,圖4 分別展示了中心模板占面積分別為12.5%、25%及遮住整個臉部(大約40%)的人臉圖像的修復結果。實驗結果表明,當被遮擋面積較小時,由于人臉語義特征較為集中,各類方法都能得到比較自然和具有真實感的人臉。隨著遮擋面積的增加,生成人臉和真實人臉差異變大,且結果開始出現一些瑕疵。其中,GLC出現明顯的模糊和視覺不一致,且生成圖像和周圍真實圖像像素值之間存在較明顯差異;而DF 遮住整個人臉后,由于缺乏周邊的語義信息,人臉比例和表情看起來比較奇怪;GC和本文結果在被遮擋面積較大時,仍然能生成真實感的人臉,但GC生成的牙齒和嘴唇之間有較明顯的銜接瑕疵。本文方法能生成真實的毛發和五官等重要語義信息,頭發和眉毛等細節清晰,模板邊界周圍和真實皮膚銜接光滑,皮膚顏色比GLC更自然。

圖4 不同模型針對不同面積的矩形模板修復結果Fig.4 Inpainting results of different models on rectangular masks with different areas
3.3.2 同一張圖像在不同隨機模板的修復
為測試本文模型修復的圖像與真實圖像之間的相似性,圖5 展示了同一張最常見的人臉圖像,使用四種不同形狀的隨機模板遮擋后的修復效果。最常見的人臉圖像,指正面無遮擋物(如沒戴眼鏡、墨鏡、眼罩,抽煙等),儀態正常(無托腮、捂嘴等動作)的圖像。利用圖形用戶界面程序生成模板,使模板不僅包含皮膚等光滑單一語義目標,還特意遮擋住重要語義目標及過渡帶,如眼睛、鼻子、眉毛、牙齒與嘴唇銜接處等位置。由圖5(c)的修復圖像可以看出,本文模型能有效抓取人臉語義特征,生成圖像與真實圖像相近。對比圖4 中第三行和第六行可見,在生成整張面部時,不需要考慮生成圖像和未遮蓋區域之間的銜接問題,因此,雖然修復結果和真實圖像差異較大,但修復結果具有真實感,基本沒有瑕疵。在圖5(c)的修復結果的第三幅圖像(從左到右)中,由于被遮蓋區域需要考慮與周邊真實圖像的銜接,牙齒和嘴唇區反而會存在少量銜接不自然的瑕疵。

圖5 本文模型對不同形狀隨機模板的修復結果Fig.5 Inpainting results of proposed model on different random masks
3.3.3 目標移去與修復
圖像修復的一個重要目的是為了去除圖像中不需要或被遮擋的物體,填入自然的語義信息,本節展示該應用的效果。圖6 第一列和第二列展示去掉人臉上所不需要的眼鏡和眼罩。
圖6 中,第一行和第二行的結果表明,和對比模型相比,本文模型摘去眼鏡的效果良好,生成的人眼及鼻梁與周邊真實圖像之間過渡自然,不存在參考文獻中明顯的膚色過渡不均勻、局部模糊、目標錯位、膚色差異等現象。第三行是要修復單側戴眼鏡的眼睛。由于數據集中大部分都是不戴眼鏡的人臉,因此對于第三行的待修復圖像,包括本文模型在內的所有模型,都沒能生成自然連續的鏡框圖像。GLC和DF基本沒有生成鏡框,和其他模型相比,本文模型生成了較為明顯的鏡框,但鏡框邊界較模糊,而且生成右眼和左眼明顯不對稱。

圖6 不同模型對人臉的特定目標移去的修復對比Fig.6 Inpainting comparison of different models on specific facial target removing
3.3.4 數據集外人臉圖像修復結果
圖7 展示使用訓練好的模型對數據集外的人臉圖像根據實際應用需求有針對性地進行修復的結果。

圖7 本文模型對數據集外人臉的修復結果Fig.7 Inpainting results of proposed model on faces out of dataset
圖7 中,第一行結果表明本文模型在移除人臉特定目標時具有較好的性能,和早前對該圖像使用基于模型的方法[20]所得到的結果(因篇幅限制,本文中未重復給出相應結果展示,可自行查看文獻[20]中結果)相比,在眼睛、嘴唇和眉毛等關鍵語義處的修復結果更加真實自然。由第二行可見,本文模型傾向于生成相對光滑的皮膚,因此可以用于移除人臉表情紋和皺紋。由第三行可以看出,由于該訓練集的數據絕大多數都是歐美西方人臉,在東方人臉被遮掉大部分人臉區域后,本文模型生成一張具有西方人特色的臉。實驗顯示本文模型對于人臉圖像修復與生成具有較好的泛化能力,也許這一特性可以用在人臉風格遷移等應用中。
3.4 密集連接塊有效性分析
為測試模型中引入的密集連接塊對圖像語義提取的有效性,將其結果與利用原始U-Net 網絡的修復結果進行對比,并給出兩個模型的訓練損失函數值對比。在訓練原始U-Net 網絡時,所使用損失函數和超參數均和所提模型相同。圖8 為使用本文模型和原始U-Net 模型的生成器在訓練過程中的損失函數值。可見由于密集連接塊和跳連接的引入,增加了梯度信息的傳遞,使前期訓練過程更加穩定,同時增加了圖像信息的再利用,獲得更低的損失函數。圖9 為圖像使用原始U-Net網絡進行修復的結果,前兩張分別為圖4 中第一行和第四行輸入圖像的修復結果,第三張為圖7 第三張圖像的修復結果。可見由于待修復區域信息缺失,直接使用U-Net 只能得到圖像的部分語義,不能生成具有真實感的人臉圖像。實驗結果驗證了本文模型的有效性。
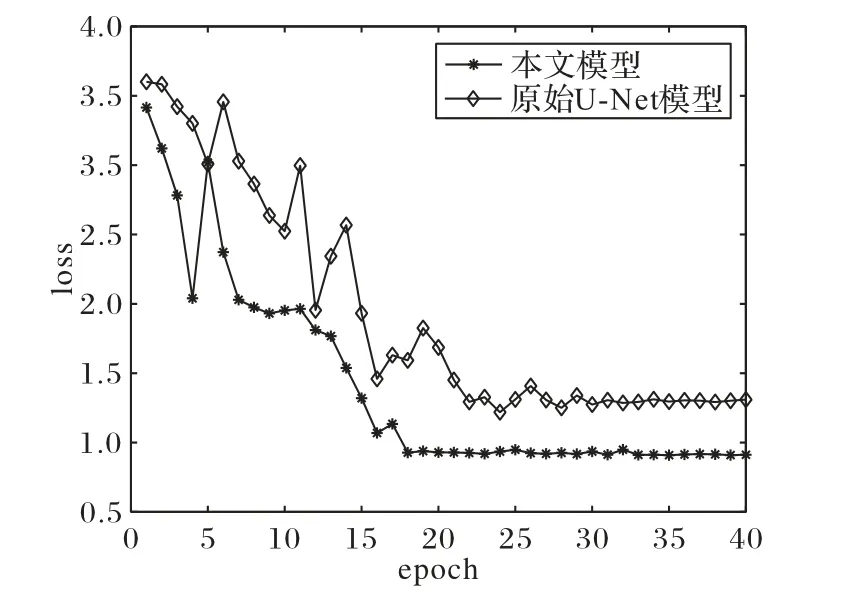
圖8 本文模型與原始U-Net模型生成器訓練損失函數對比Fig.8 Comparison of generator training loss functions of proposed model and original U-Net model

圖9 使用原始U-Net的修復結果Fig.9 Inpainting results of original U-Net
4 結語
本文提出了一個基于密集連接塊的U-Net 結構的人臉圖像修復模型,該修復模型使用生成對抗網絡思想,采用聯合損失函數來訓練生成器,使用密集連接塊和跳連接來確保語義信息的再利用與捕捉。但該模型也有其局限性,例如,對人臉的對稱結構特征學習不足,對于有些圖像,生成的一只眼睛與人臉上原有的眼睛不夠對稱。此外,由于數據集內大多數圖像是不戴眼鏡的,因此在修復戴眼鏡的單側眼睛時,眼鏡框架存在較明顯的瑕疵。針對該模型的局限性可從以下方面進行改進,即:在模型中增強抓取單幀圖像的對稱特征的能力,并采取一些均衡化數據處理方法或預標注方法,解決眼鏡人臉樣本數不足的問題。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
核科學與工程(2015年4期)2015-09-26 11:59:03
大連民族大學學報(2015年2期)2015-02-27 08:28:11
當代修辭學(2011年6期)2011-01-29 02:49:50
外語學刊(2011年1期)2011-01-22 03:38:33
