基于改進(jìn)LDA模型的信息安全事件提取算法
2021-01-10 08:22:32吳君戈張笑笑鄒春明宋好好
網(wǎng)絡(luò)空間安全 2020年12期
吳君戈,張笑笑,鄒春明,宋好好
(公安部第三研究所/上海網(wǎng)絡(luò)與信息安全測(cè)評(píng)工程技術(shù)研究中心,上海 200031)
1 引言
隨著互聯(lián)網(wǎng)技術(shù)的不斷發(fā)展,信息化已經(jīng)深入到人們生活的方方面面,信息化高速發(fā)展也導(dǎo)致了各式各樣信息安全事件的出現(xiàn),給人民的財(cái)產(chǎn)安全造成了嚴(yán)重的威脅[1]。與此同時(shí),信息安全事件往往被淹沒在海量的新聞事件中,研究人員較難快速地定位到信息安全事件之上,難以有針對(duì)性地提出解決方案[2]。因此,如何有效地從海量的新聞事件中抽取出信息安全事件,對(duì)于維護(hù)社會(huì)穩(wěn)定和公共利益具有積極而重要的意義[3]。
近年來(lái),國(guó)內(nèi)外學(xué)者針對(duì)信息安全事件的分類提取工作進(jìn)行了大量的研究。文獻(xiàn)[4]中,作者利用TextRank和隱含狄利克雷分布(Latent Dirichlet Allocation,LDA)模型對(duì)信息安全熱點(diǎn)事件進(jìn)行分類和提取,然而LD模型需提前預(yù)設(shè)參數(shù),參數(shù)選擇對(duì)于其分類性能有著直接的影響。文獻(xiàn)[5]中,G Jelena等人提出了基于K最近鄰(k-Nearest Neighbor,KNN)分類算法和支持向量機(jī)(Support Vector Machine, SVM)的多層文本分類算法,并證明了所提算法的有效性。然而,實(shí)驗(yàn)中所用數(shù)據(jù)需提前進(jìn)行主標(biāo)簽分類,當(dāng)數(shù)據(jù)量增加時(shí)分類效率必然會(huì)有所降低。文獻(xiàn)[6]中,A Ritter等人提出利用弱監(jiān)督學(xué)習(xí)算法從Twitter上提取信息安全事件,但是由于Twitter屬于文本表現(xiàn)自由的短文本,較之新聞文本有較大差別,因此該算法用于新聞文本中進(jìn)行信息安全事件的分類抽取時(shí)并無(wú)優(yōu)勢(shì)。
對(duì)于信息安全管理而言,如何快速、準(zhǔn)確地從大量新聞事件中提取信息安全事件是一個(gè)挑戰(zhàn)。為了解決這個(gè)問題,本文提出一種基于改進(jìn)LDA模型的信息安全事件提取方法,首先通過對(duì)傳統(tǒng)LDA模型中文本主題數(shù)確定指標(biāo)進(jìn)行優(yōu)化,提高LDA模型對(duì)于事件主題挖掘的準(zhǔn)確性,進(jìn)而從海量新聞事件中形成信息安全事件候選事件集,最后采用投票機(jī)制從候選事件集中分類出真正的信息安全事件。
2 基于改進(jìn)LDA模型的候選事件集構(gòu)建
2.1 傳統(tǒng)LDA模型
隱含狄利克雷分布(Latent Dirichlet Allocation,LDA)模型由D M Blei等人提出,通過無(wú)監(jiān)督學(xué)習(xí)方法分析文檔集中每篇文檔的主題分布,然后根據(jù)主題分布進(jìn)行主題聚類或文本分類[7]。LDA模型認(rèn)為一篇文檔可以包含多個(gè)主題,這與一個(gè)信息安全事件往往涉及多個(gè)主題相吻合。
LDA模型的基本思想:首先是生成“主題-詞匯”多項(xiàng)分布,此多項(xiàng)分布是服從參數(shù)為 β 的狄利克雷先驗(yàn)分布,再生成“文檔-主題”多項(xiàng)分布,此多項(xiàng)分布是服從參數(shù)為 的狄利克雷先驗(yàn)分布,具體過程如圖1所示[8]。

圖1 LDA模型實(shí)現(xiàn)圖
LDA模型具體實(shí)現(xiàn)就是確定出參數(shù)(α,β),常用的估計(jì)方法有期望傳播、貝葉斯推斷和Gibbs抽樣等,由于Gibbs抽樣的算法比較簡(jiǎn)單,而且對(duì)參數(shù)的抽樣效果較為理想,因此在LDA主題模型中,常使用Gibbs抽樣方法對(duì)語(yǔ)料庫(kù)中的所有文檔和詞匯的主題進(jìn)行提取,具體流程如下[9]:
1)選擇合適的主題數(shù)K,初始化參數(shù)向量α和β;
2)對(duì)應(yīng)語(yǔ)料庫(kù)中每一篇文檔的每一個(gè)詞,隨機(jī)的賦予一個(gè)主題編號(hào)Zm,n;
3)重新掃描語(yǔ)料庫(kù),對(duì)于每一個(gè)詞,利用Gibbs采樣公式更新它的主題編號(hào),并更新語(yǔ)料中該詞的編號(hào);
4)重復(fù)第3)步的基于坐標(biāo)軸輪換的Gibbs采樣,直到Gibbs采樣收斂;
5)統(tǒng)計(jì)語(yǔ)料庫(kù)中的各個(gè)文檔各個(gè)詞的主題,得到文檔主題分布,統(tǒng)計(jì)語(yǔ)料庫(kù)中各個(gè)主題詞的分布,得到LDA的主題與詞的分布
由上述流程可以看出,確定參數(shù)(α,β)需提前預(yù)設(shè)好最優(yōu)主題個(gè)數(shù),因此影響最終LDA模型主題分類效果的一個(gè)重要因素是最優(yōu)主題個(gè)數(shù)的確定。
2.2 改進(jìn)的LDA模型
目前,LDA模型中常用于衡量最優(yōu)主題數(shù)的指標(biāo)有困惑度(Perplexity)、JS散度(Jensen-Shannon Divergence)等[10]。然而,Perplexity指標(biāo)注重模型對(duì)新文檔的預(yù)測(cè)能力,往往導(dǎo)致求得的最優(yōu)主題數(shù)偏大,而JS散度側(cè)重于主題之間的差異性和穩(wěn)定性,雖彌補(bǔ)了Perplexity的缺點(diǎn),但求得的主題數(shù)偏小。因此,本文結(jié)合兩者的優(yōu)點(diǎn)提出一種改進(jìn)的最優(yōu)主題數(shù)確定指標(biāo)Perplexity-Aver,來(lái)得到更貼合實(shí)際要求的主題數(shù)目。
為衡量主題空間的整體差異性,首先在JS散度的基礎(chǔ)上引入JS散度平均值A(chǔ)ver(T)的概念,表達(dá)式如下所示:
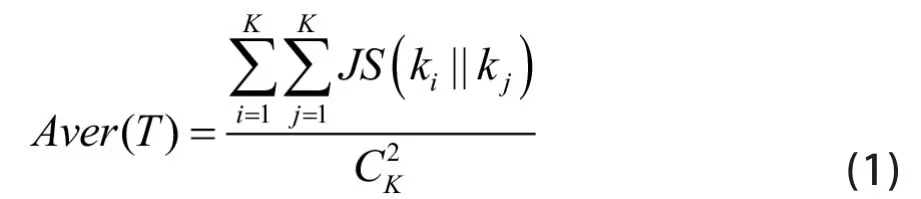
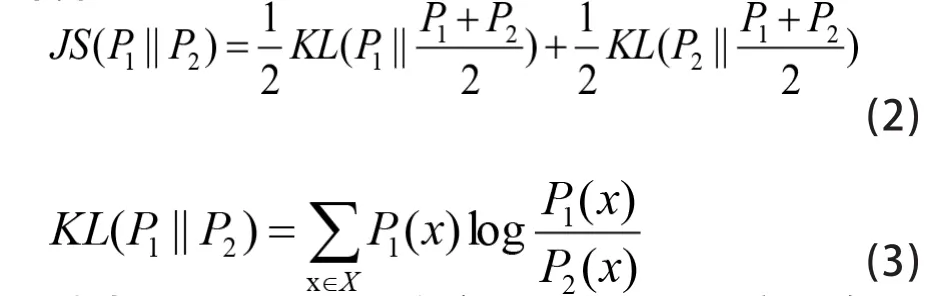
其中,P1和P2分別為主題k1和k2的概率分布。
最后,綜合Perplexity和Aver(T)兩個(gè)指標(biāo),提出一種確定最優(yōu)主題數(shù)指標(biāo)Perplexity-Aver,其計(jì)算方法如下:
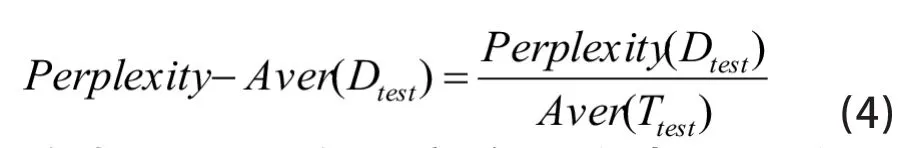
其中,Dtest表示實(shí)驗(yàn)的文本數(shù)據(jù)集,Perplexity(Dtest)表示實(shí)驗(yàn)數(shù)據(jù)集的困惑度,Aver(Ttest)表示實(shí)驗(yàn)數(shù)據(jù)集的JS散度平均集。
由公式(4)可以看出,當(dāng)Perplexity(Dtest)越小時(shí),主題模型的泛化能力越強(qiáng),對(duì)新文檔主題的預(yù)測(cè)效果更好;當(dāng)Aver(Ttest)越大時(shí),主題模型各主題之間的差異就越大,主題的平均相似度就越小,主題抽取的效果就越好。因此,當(dāng)Perplexity-Aver的指標(biāo)最小時(shí),對(duì)應(yīng)的主題數(shù)是最優(yōu)主題數(shù)。
綜上所述,利用改進(jìn)的LDA模型進(jìn)行主題建模時(shí)分為七步驟:
1)將各類別混合的N篇文檔進(jìn)行預(yù)處理,包括去分詞和去停用詞;
2)將預(yù)處理好的文檔集輸入改進(jìn)的LDA主題模型,輸入模型參數(shù)K、α、β;
3)利用Gibbs抽樣計(jì)算出模型的θ和φ分布;
4)改變K的值,重復(fù)步驟2)和3),得到不同主題數(shù)下的建模結(jié)果;
5)根據(jù)Perplexity-Aver確定最優(yōu)主題數(shù)K;
6)修剪無(wú)關(guān)的詞匯,輸出各類信息安全事件下的關(guān)鍵詞;
7)輸出主題建模結(jié)果。
其中,步驟1)中分詞是指遵循一定的規(guī)則,將一個(gè)個(gè)連續(xù)的字序列劃分為詞匯的過程;去停用詞是指刪除文檔中出現(xiàn)的虛詞和對(duì)文本分類沒有實(shí)際意義的高頻詞匯。
2.3 候選事件集構(gòu)建
通過改進(jìn)的LDA模型進(jìn)行主題建模,可以得到信息安全事件的幾大類別,并得到每一類主題下的主題詞,主題詞可以作為該類信息安全事件的觸發(fā)詞,由觸發(fā)詞引發(fā)的事件集合稱為候選事件集。
然而,并非所有含觸發(fā)詞的事件都是與信息安全相關(guān)的事件。例如表1所示,只有句子1是信息安全相關(guān)事件,即句子中的“病毒”是網(wǎng)絡(luò)病毒的含義;句子2和句子3都不屬于信息安全事件的范疇,不是我們真正關(guān)注的事件。
因此,本文對(duì)事件觸發(fā)詞進(jìn)行改進(jìn),將觸發(fā)詞分為“限制詞”和“業(yè)務(wù)詞”,業(yè)務(wù)詞是指事件涉及到的敏感詞匯,限制詞則根據(jù)每一類事件實(shí)際描述的事件內(nèi)容,限定了業(yè)務(wù)詞引起的事件的范圍。將“限制詞”和“業(yè)務(wù)詞”同時(shí)作為觸發(fā)條件,以使候選事件更接近于信息安全相關(guān)事件。

表1 觸發(fā)詞觸發(fā)的事件示例

表2 業(yè)務(wù)詞和限制詞共同觸發(fā)的事件示例
雖然將事件觸發(fā)詞改進(jìn)為“限制詞”和“業(yè)務(wù)詞”,可以提高候選事件集中信息安全事件的比例,但是得到的候選事件集中仍然存在不合要求的事件。例如表2所示,其中句子1和3是與信息安全相關(guān)的事件,句子2和4明顯是與信息安全無(wú)關(guān)的事件。
因此,本文選擇觸發(fā)語(yǔ)句所在位置、觸發(fā)語(yǔ)句在全文的比例、標(biāo)題是否為觸發(fā)語(yǔ)句作為候選事件集中的特征項(xiàng)對(duì)候選事件集進(jìn)行特征提取,具體定義為:
① 觸發(fā)語(yǔ)句所在位置F1的計(jì)算方式如公式(5)所示:

其中,Nrank表示觸發(fā)語(yǔ)句在文中的位置,即觸發(fā)語(yǔ)句在文中第幾句;Ntotal表示文中句子總數(shù)。
② 觸發(fā)語(yǔ)句在全文中的比例F2的計(jì)算方式如公式(6)所示:

其中,ntotal表示觸發(fā)語(yǔ)句在文中的數(shù)量。
③ 標(biāo)題是否為觸發(fā)語(yǔ)句F3的計(jì)算方式如公式(7)所示:

3 基于改進(jìn)LDA模型的信息安全事件提取算法
由于候選事件集中的文章僅有兩類,與信息安全相關(guān)的事件和與信息安全無(wú)關(guān)的事件,因此識(shí)別真正的信息安全事件問題可以看作是一個(gè)二分類問題。基于此,本文對(duì)候選事件集進(jìn)行特征提取之后,利用投票機(jī)制,完成對(duì)信息安全事件和與信息安全無(wú)關(guān)的事件的分類。
基于投票機(jī)制的文本分類屬于集成學(xué)習(xí),其基本思路是先使用多個(gè)分類器單獨(dú)對(duì)樣本進(jìn)行預(yù)測(cè),然后通過一定的方式將各個(gè)分類器的分類結(jié)果融合起來(lái),以此決定文本的最終歸屬類別。集成學(xué)習(xí)是否有效的關(guān)鍵有兩點(diǎn):
一是各個(gè)基分類器必須有一定的差異性;
二是各個(gè)基分類器的預(yù)測(cè)正確率必須不小于50%。
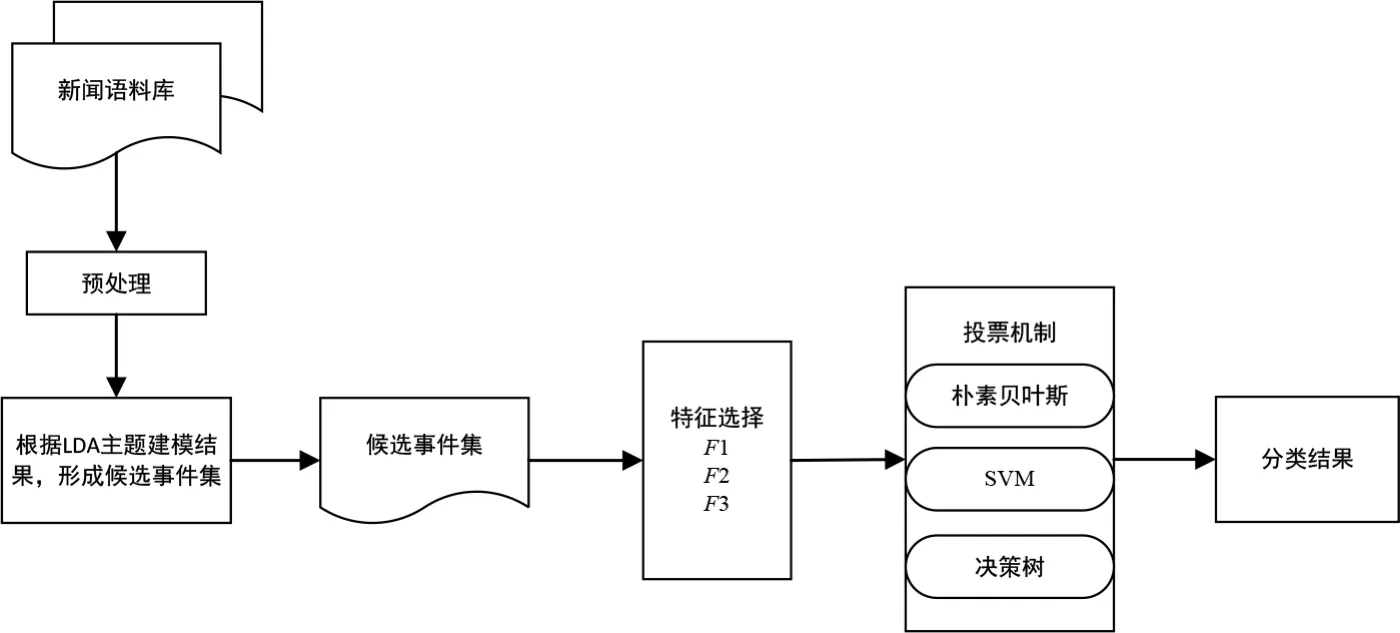
圖2 信息安全事件提取算法流程圖
因此,本文選取樸素貝葉斯、SVM、決策樹構(gòu)建投票機(jī)制,利用候選事件集特征F1、F2和F3,供二元分類算法學(xué)習(xí),進(jìn)而采用訓(xùn)練完成后的投票機(jī)制進(jìn)行預(yù)測(cè),預(yù)測(cè)數(shù)據(jù)的最終結(jié)果為服從多數(shù)分類器預(yù)測(cè)的結(jié)果,具體算法流程圖如圖2所示。
4. 實(shí)驗(yàn)結(jié)果及分析
4.1 實(shí)驗(yàn)數(shù)據(jù)及預(yù)處理
本文通過網(wǎng)絡(luò)爬蟲工具GooSeeker,收集國(guó)內(nèi)主流的信息安全網(wǎng)站(中國(guó)信息安全等級(jí)保護(hù)網(wǎng)、中國(guó)信息安全網(wǎng)等)2015年1月1日至2019年12月30日期間報(bào)道的信息安全事件作為原始數(shù)據(jù)集。原始數(shù)據(jù)集內(nèi)容為上述網(wǎng)站的新聞內(nèi)容、標(biāo)題和發(fā)布時(shí)間,其中新聞內(nèi)容只保留文字,去除視頻、圖片等格式的數(shù)據(jù)。
由于采集到的原始數(shù)據(jù)中含有垃圾數(shù)據(jù),因此經(jīng)對(duì)采集到的數(shù)據(jù)進(jìn)行去除重復(fù)數(shù)據(jù)和刪掉無(wú)文本的空白數(shù)據(jù)后,共獲得有效數(shù)據(jù)13,684條。
4.2 實(shí)驗(yàn)結(jié)果分析
本文在對(duì)對(duì)原始數(shù)據(jù)進(jìn)行分詞和去停用詞的預(yù)處理后,利用改進(jìn)的LDA模型對(duì)原始數(shù)據(jù)集進(jìn)行主題建模,設(shè)置迭代次數(shù)為100,經(jīng)驗(yàn)值參數(shù)α和β參照文獻(xiàn)[11]分別設(shè)置為50/k和0.01。對(duì)于主題數(shù)量K,根據(jù)以往信息安全事件的分類經(jīng)驗(yàn),將主題數(shù)量約定在3~10之間,利用Perplexity-Aver確定最優(yōu)的主題數(shù)K。圖3為主題建模過程中Perplexity-Aver值與Perplexity、JS散度的對(duì)比關(guān)系,從圖3中可以看出,Perplexity因更看重對(duì)新文檔的預(yù)測(cè)能力導(dǎo)致主題數(shù)偏大,而JS散度因更看重整體的差異性和穩(wěn)定性而導(dǎo)致主題數(shù)偏小。
為了進(jìn)一步驗(yàn)證本文所提信息安全事件提取方法的性能,選取準(zhǔn)確率(Precision)、召回率(Recall)和F值作為評(píng)價(jià)標(biāo)準(zhǔn),表達(dá)式如下所示:

其中,TP表示正確匹配的樣本數(shù)量,即將信息安全事件樣本預(yù)測(cè)為信息安全事件的數(shù)量,F(xiàn)N表示漏報(bào)的樣本數(shù)量,即將信息安全事件的樣本錯(cuò)誤預(yù)測(cè)為非信息安全事件的數(shù)量,F(xiàn)P表示誤報(bào)的樣本數(shù)量,即將非信息安全事件的樣本錯(cuò)誤預(yù)測(cè)為信息安全事件的數(shù)量,TN表示正確的非匹配樣本數(shù)量,即將非信息安全事件的樣本預(yù)測(cè)為非信息安全事件的數(shù)量。
實(shí)驗(yàn)中,使用交叉驗(yàn)證的方法進(jìn)行5折交叉驗(yàn)證,即每次選擇實(shí)驗(yàn)數(shù)據(jù)的1/5作為測(cè)試數(shù)據(jù),剩下的4/5作為訓(xùn)練數(shù)據(jù),進(jìn)行5次試驗(yàn),并將5次試驗(yàn)結(jié)果的準(zhǔn)確率、召回率、F值的平均值作為最終的準(zhǔn)確率、召回率和F值。為了驗(yàn)證本文所提信息安全事件提取方法的有效性,選取文獻(xiàn)[4]和文獻(xiàn)[12]中所提分類算法進(jìn)行比較,其中文獻(xiàn)[4]為采用傳統(tǒng)LDA模型進(jìn)行文本分類提取的方法,文獻(xiàn)[12]提出一種基于改進(jìn)BP神經(jīng)網(wǎng)絡(luò)的文本分類方法,結(jié)果如表3所示
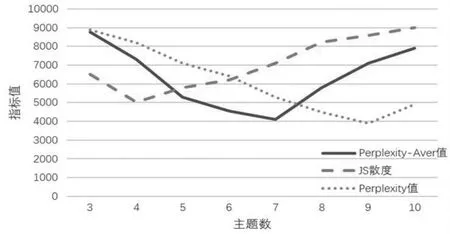
圖3 Perplexity-Aver與Perplexity、JS散度的對(duì)比關(guān)系
從表3中可以看出,在準(zhǔn)確性、召回率和F值指標(biāo)上,本文所提事件提取方法均要優(yōu)于文獻(xiàn)[4]和文獻(xiàn)[12]所提的文本分類方法,這是證明了本文所提算法在信息安全事件提取方面的有效性。

表3 本文方法與其他文獻(xiàn)方法性能比較
5 結(jié)束語(yǔ)
本文提出一種基于LDA模型和投票機(jī)制的信息安全事件提取方法,通過利用LDA主題模型和改進(jìn)的主題數(shù)確定指標(biāo)Perplexity-Aver對(duì)新聞事件進(jìn)行主題建模,得到信息安全候選事件集,最后利用投票機(jī)制從候選事件集中識(shí)別出真正的信息安全事件。仿真結(jié)果表明,本文所提信息安全事件提取方法,無(wú)論在準(zhǔn)確率、召回率,還是F值方面,均優(yōu)于傳統(tǒng)的文本方法,可以獲得較好的文本分類性能。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
