基于集成學習的地質災害危險性評價
2021-01-14 07:57:30崔陽陽鄧念東曹曉凡邢聰聰
水力發(fā)電 2020年10期
崔陽陽,鄧念東,曹曉凡,丁 一,邢聰聰
(西安科技大學地質與環(huán)境學院,陜西 西安 710054)
0 引 言
地質災害危險性評價是對一個復雜系統(tǒng)的定量化分析過程[1]。近年來,隨著GIS技術快速發(fā)展,基于GIS技術的地質災害危險性評價不僅提高了工作效率,也提升了地質災害管理的信息化水平[2]。隨著機器學習的發(fā)展,地質災害危險性評價模型由簡單到復雜,由單一模型逐漸發(fā)展為耦合模型和集成模型。常見的單一模型有邏輯回歸模型[3]、人工神經(jīng)網(wǎng)絡模型[4]、決策樹模型[5]、支持向量機模型[6]等,該類模型對分類器的預測精度要求較高。耦合模型是將2種或2種以上的單一模型進行耦合,預測結果往往比單一模型更可靠。張俊等[7]人采用粒子群優(yōu)化算法(PSO)與支持向量機回歸(SVR)耦合模型對滑坡位移進行預測發(fā)現(xiàn),PSO-SVR耦合模型的預測精度要明顯高于BP神經(jīng)網(wǎng)絡模型和支持向量機模型;徐峰等[8]運用自適應變異粒子群優(yōu)化算法(AMPSO)和支持向量機(SVM)耦合模型對三峽庫區(qū)白水河滑坡位移進行預測表明,AMPSO-SVM耦合模型對于滑坡位移的預測性能優(yōu)于BP神經(jīng)網(wǎng)絡預測模型和SVM模型;栗澤桐等[9]以青海沙塘川流域黃土梁峁區(qū)為例,對比分析了基于信息量、邏輯回歸及兩者耦合模型的滑坡易發(fā)性評價的技術流程及結果發(fā)現(xiàn),兩者耦合模型成功率明顯高于其他單一模型。集成學習模型通過將多個單一學習模型按照不同的算法結合而得到,從而獲得更準確、穩(wěn)定和強壯的結果,其往往具有很高的預測精度。大部分集成學習模型分為分類集成學習模型,半監(jiān)督集成學習模型和非監(jiān)督集成學習模型3類。其中,分類集成學習模型應用最為廣泛,包括一系列常見的分類技術,如Bagging、Boosting、隨機森林等[10-12]。
鑒于單一模型與耦合模型對數(shù)據(jù)參數(shù)選取的局限性以及結果的差異性,本文基于集成思想分別采用Bagging、Boosting以及隨機森林(RF)3種集成算法,對府谷縣地質災害危險性進行評價研究,并對預測結果以及模型的性能進行檢驗。該結論為研究區(qū)地質災害危險性評價模型的確定以及后期區(qū)內(nèi)地質災害防治工程的設計提供參考。
1 研究區(qū)概況
府谷縣位于陜西省最北端,地處陜、晉、蒙三省(區(qū))交界處,隸屬陜西省榆林市管轄,面積3 229 km2,屬中溫帶干旱大陸性季風氣候,年均氣溫 9.1 ℃,年均降水量428.6 mm。地形由東南向西北逐漸抬升,最大高程為1 414 m,最小高程為765 m,河流均屬于黃河水系。區(qū)內(nèi)地貌單元主要包括黃土梁崗、黃土梁峁溝壑、峽谷丘陵、河谷階地等,地質構造總體上為一向西傾斜的單斜構造,地層東老西新,依次出露奧陶系、石炭系碳酸巖類和二疊系、三疊系、侏羅系碎屑巖類,地表多被第四系中、上更新統(tǒng)黃土以及全新統(tǒng)沖洪積層覆蓋,巖土體較為松散。區(qū)內(nèi)巖土體類型劃分為堅硬塊狀碳酸巖類,層狀堅硬~半堅硬砂泥巖互層碎屑巖類,層狀較軟弱砂質粘土碎屑巖類,粗砂礫石黃土狀土、黃土,風成中細砂等。區(qū)內(nèi)斷層發(fā)育,主要發(fā)育F1、F2、F3、F4、F5共5組斷層。區(qū)內(nèi)主要人類工程活動有大范圍采礦活動,市政設施、公路和鐵路建設以及削坡建房、坡地耕種等。據(jù)統(tǒng)計,境內(nèi)地質災害主要類型分為崩塌、滑坡、泥石流和地面塌陷4類,共計184處。地理位置及災害點分布情況見圖1。
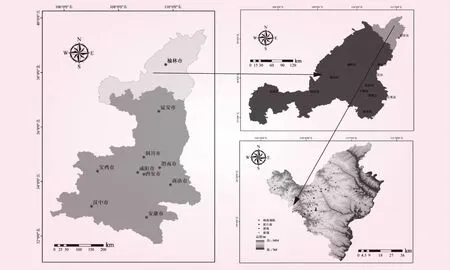
圖1 研究區(qū)地理位置及災害點分布
2 評價模型簡介
2.1 Bagging算法
Bagging算法又稱裝袋法,是在同一種基分類器下對訓練樣本使用Bootstrap抽樣法訓練多個基分類器,最后通過投票法得出結果[13],可有助于降低訓練數(shù)據(jù)的隨機波動導致的誤差。Bagging算法最常用的不穩(wěn)定基分類器有決策樹(Decision Tree,DT)和神經(jīng)網(wǎng)絡(Neural Net-works,NN)。本文選取決策樹作為集成模型的基分類器,對研究區(qū)地質災害危險性進行評價。
2.2 Boosting算法
Boosting 算法是一種將弱學習器轉換為強學習器的迭代方法。通過增加迭代次數(shù),產(chǎn)生一個表現(xiàn)接近完美的強學習器[14],被認為是統(tǒng)計學習中性能最好的方法之一[15]。Boosting算法通過提高那些在前一輪被弱分類器分錯樣例的權值,減小前一輪分對樣例的權值,使分類器對于誤分的數(shù)據(jù)有較好的效果,依據(jù)此規(guī)則得到最終的Boosting模型。
2.3 隨機森林算法
隨機森林(RF)是一種結合裝袋法(Bagging)生成多個獨立的樣本集和多棵分類回歸樹(Classification and Regression Tree,CART)來進行預測的集成學習方法,結果由投票得分最多或取平均決定[16-18]。其主要思想在于多個弱分類器經(jīng)過一定策略進行組合,形成一個較單一分類器預測性能更加優(yōu)越的集成模型。
隨機森林算法具體實現(xiàn)過程如下:利用裝袋法從總的樣本中隨機有放回地抽取n個(與總樣本數(shù)相同)樣本作為獨立空間訓練樣本集,對每個訓練集分別建立決策樹。其中,從總的特征數(shù)中隨機選取m個特征數(shù)(m≤特征數(shù))進行內(nèi)部節(jié)點分支,得到n棵獨立的隨機決策樹,將n棵決策樹所得結果采取投票原則或取其平均值作為最終預測結果[19-20]。
3 指標因子構建
本文用到的數(shù)據(jù)來源主要包括:①府谷縣地質災害詳查報告;②府谷縣1∶50 000地質圖、地貌類型圖和巖土體類型圖;③府谷縣分辨率為30 m的DEM數(shù)字高程數(shù)據(jù);④府谷縣 1∶50 000的路網(wǎng)圖與水系圖;⑤30 m分辨率的Landsat8遙感影像圖。根據(jù)研究區(qū)面積以及地質災害規(guī)模,本文采用30 m×30 m的柵格作為地質災害預測的評價單元,共劃分為3 553 404個柵格。
通過地質災害詳查報告獲取地質災害點位置坐標,利用ArcGIS 10.0軟件轉化得到地質災害點圖層。利用ArcGIS工具對DEM影像處理,得到高程、坡度、坡向、坡度變率、坡向變率、平面曲率、剖面曲率和曲率圖層;利用地貌類型圖提取研究區(qū)地貌類型,利用ArcGIS工具對其按不同地貌類型進行重分類、面轉柵格等操作獲得地貌類型圖層;同上,利用巖土體類型圖和地質圖分別提取研究區(qū)巖土體類型和斷層分布,按不同巖土體類型進行分類,對斷層進行歐氏距離分析,得到地質災害點到各斷層的實際距離;利用EARDAS軟件對Landsat8遙感影像處理得到研究區(qū)歸一化植被指數(shù)(NDVI)圖層;根據(jù)研究區(qū)年降雨量資料利用ArcGIS工具采用克里金插值獲得降雨量等值線圖層;利用ArcGIS對路網(wǎng)圖以及水系圖矢量化,然后用歐氏距離分析工具獲得地質災害點到各要素的距離。提取得到的各因子圖層見圖2、3、4。
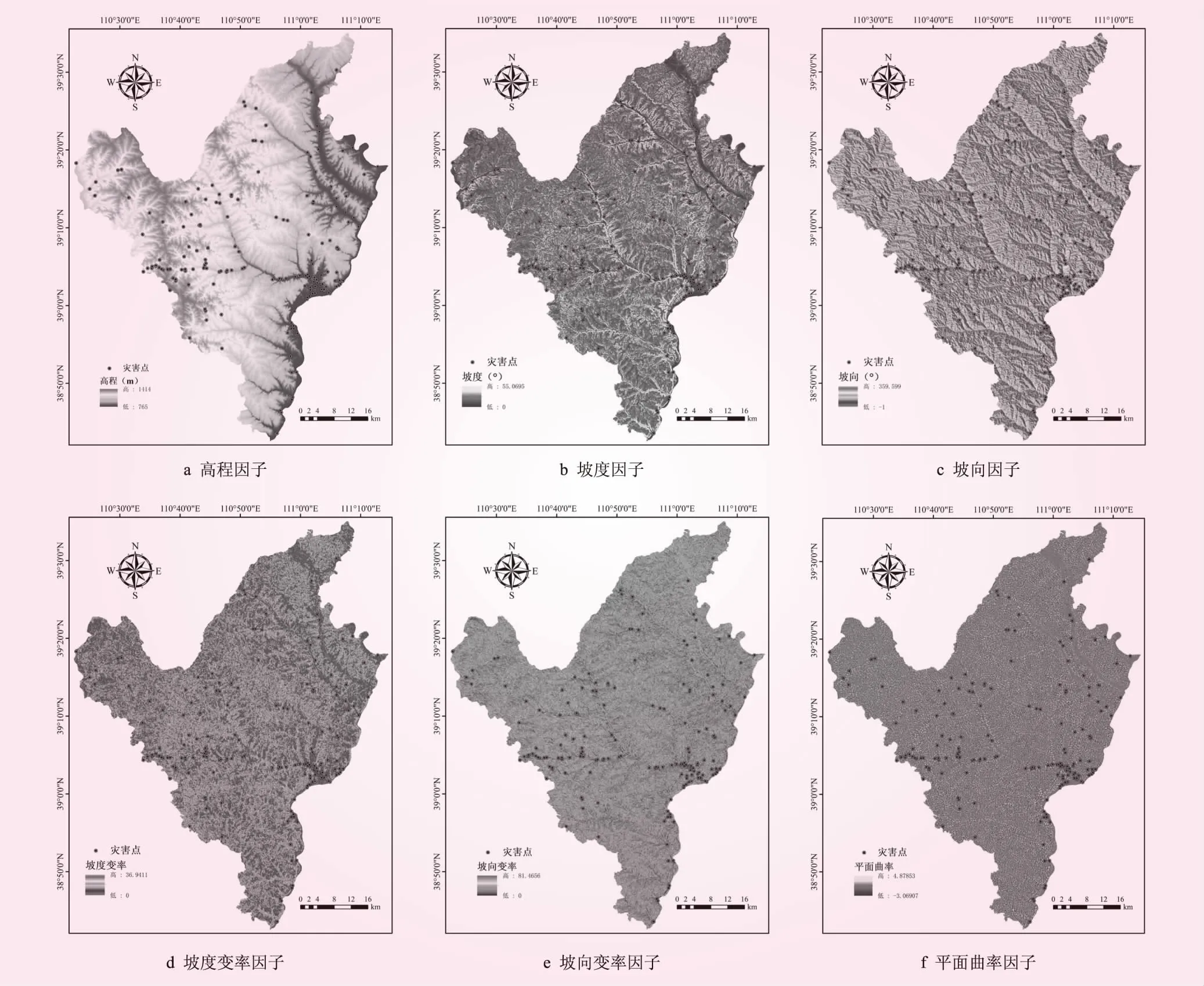
圖2 各評價因子圖層(一)

圖3 各評價因子圖層(二)
4 地質災害危險性評價
采用ArcGIS軟件柵格轉點工具提取地質災害點圖層以及15類評價因子圖層數(shù)據(jù),構建地質災害危險性評價數(shù)據(jù)庫。選取所有災害點與相等數(shù)量的非災害點數(shù)據(jù)作為樣本點,將災害點隨機分為2個部分,一部分(總災害點的70%)作為訓練樣本數(shù)據(jù),剩余部分(總災害點的30%)作為測試樣本數(shù)據(jù)。將樣本數(shù)據(jù)導入R語言中進行訓練,得到基于Bagging、Boosting以及RF的危險性評價模型,然后提取整個研究區(qū)的數(shù)據(jù)帶入訓練好的模型中計算,得到研究區(qū)地質災害危險性指數(shù)。將地質災害危險性指數(shù)通過ArcGIS軟件賦值到研究區(qū)圖層中,采用自然間斷點法將研究區(qū)劃分為5個等級(極高危險區(qū)、高危險區(qū)、中危險區(qū)、低危險區(qū)和極低危險區(qū)),得到基于集成學習算法的研究區(qū)地質災害危險性區(qū)劃圖(見圖5)。Bagging、Boosting及隨機森林(RF)3種模型的預測正確率分別為76.36%、74.54%和77.28%,均大于70%,預測精度較高。
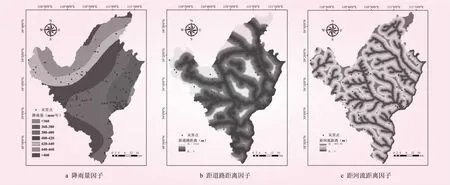
圖4 各評價因子圖層(三)
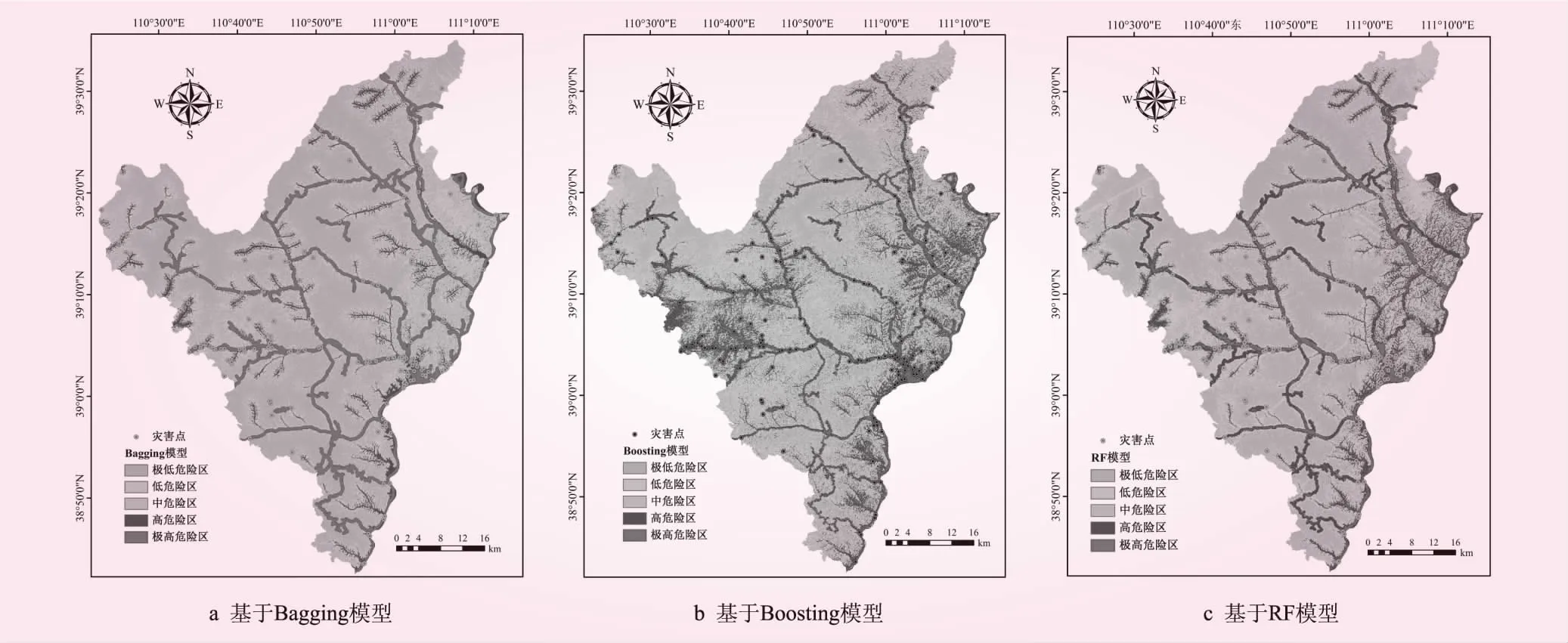
圖5 研究區(qū)地質災害危險性區(qū)劃
本文利用受試者工作特性曲線(Receiver Operating Characteristic,ROC),對3種模型的性能進行檢驗與對比。ROC曲線橫坐標代表特異性,即非災害點預測為災害點的占比;縱坐標表示敏感性,即災害點預測為災害點的占比。曲線下的面積(AUC)代表模型精確性,AUC取值范圍為[0,1],值越大代表模型性能越優(yōu)越。將3種模型測試數(shù)據(jù)計算得到的危險性指數(shù)帶入SPSS軟件進行分析,得到3種模型的預測率曲線(見圖6)。由圖6可知,通過對比3種模型的AUC值可以發(fā)現(xiàn),3種模型的預測精度均較高(AUC>0.7),RF模型在地質災害空間預測中表現(xiàn)得更好(AUC>0.8)。

圖6 3種模型的預測率
根據(jù)地質災害危險性區(qū)劃圖,運用ArcGIS軟件多值提取至點功能分別統(tǒng)計各危險性分區(qū)內(nèi)歷史災害點數(shù)所占總災害點的百分比見圖7。從圖7可知,在Bagging、Boosting以及隨機森林(RF)3種模型的結果中,歷史災害點在高~極高危險區(qū)所占的比例分別為77.17%、89.67%和91.85%,表明RF模型較其他2種模型歷史災害點在極高~高危險區(qū)分布更為集中,其更適用于地質災害危險分析的實際應用。
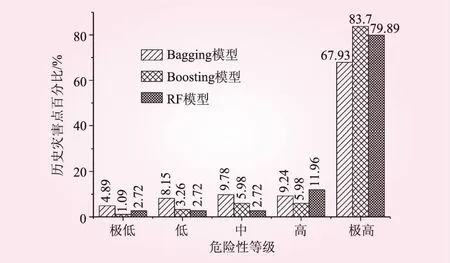
圖7 各危險區(qū)歷史災害點所占比例
5 結 語
本文以府谷縣作為研究區(qū),選取了地形地貌類、地質類、水文類、人類工程活動等15種評價因子,結合歷史地質災害點數(shù)據(jù),分別采用Bagging、Boosting及隨機森林(RF)3種集成學習模型,對該區(qū)地質災害危險性進行了分區(qū)評價研究。結論如下:
(1)Bagging、Boosting及隨機森林(RF)3種模型的預測正確率分別為76.36%、74.54%和77.28%,預測精度均較高。
(2)通過ROC曲線對比分析,Bagging、Boosting及隨機森林(RF)3種模型的AUC值分別為0.792、0.799、0.815,3種集成模型在研究區(qū)地質災害危險性評價的精度均較高,RF模型的性能較其他2種表現(xiàn)更為優(yōu)越。
(3)分別統(tǒng)計各危險性分區(qū)內(nèi)歷史災害點數(shù)所占總災害點數(shù)的百分比表明,Bagging、Boosting及隨機森林(RF)3種模型下的歷史災害點在高~極高危險區(qū)所占的比例分別為77.17%、89.67%和91.85%,RF模型較其他2種模型災害點在極高~高危險區(qū)分布更為集中,更適用于地質災害危險分析的實際應用。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
石油瀝青(2021年4期)2021-10-14 08:50:44
世界科學技術-中醫(yī)藥現(xiàn)代化(2021年10期)2021-03-02 05:52:06
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
中國工程咨詢(2015年2期)2015-02-14 02:59:26
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
