多傳感器融合的建筑入住率感知模型研究
2021-01-15 08:31:32盧楚杰李思慧
計算機應用與軟件 2021年1期
盧楚杰 李思慧
1(廣東工業(yè)大學計算機學院 廣東 廣州 510006) 2(湖南大學土木工程學院 湖南 長沙 410082)
0 引 言
研究表明,以用戶為核心(Occupant-centric)的建筑設備控制策略具有巨大的節(jié)能潛力[1]。以空調系統(tǒng)為例,房間內用戶存在與否影響著空調的啟停狀態(tài),用戶數量影響著空調的送風溫度和新風量等運行參數,而用戶行為在更高層次上影響著控制和節(jié)能策略[2]。
建筑入住率感知(Occupancy Sensing)是指獲取建筑內用戶存在與否、用戶數量等信息[3],這些信息除了用于建筑設備控制以外,還可被用作建筑能源模擬與管理,是智慧建筑的重要組成部分[4-5]。機器學習技術已經被廣泛運用于建筑入住率感知模型[6],其框架通常涉及數據采集、特征選擇、算法選擇、訓練和性能評估五個步驟。入住率感知模型包括基于運動檢測(紅外傳感器、超聲波傳感器等)、基于環(huán)境參數(CO2傳感器、溫濕度傳感器等)、基于終端設備(智能手機、RFID等)、基于信號強度(Wi-Fi、藍牙等)、基于圖像目標檢測(攝像頭等)、基于智慧電表等方法[3]。但是每種方法均有弊端,比如:紅外傳感器易于獲取用戶存在與否,但難以獲取用戶人數等詳細信息,同時其感知范圍受限于視距,并且難以感知靜止的人體,誤差較大;CO2傳感器等環(huán)境傳感器讀數具有一定的延時性,且感知精度有限;攝像頭等利用計算機視覺技術的方法雖然具有極高的感知精度,但是由于涉及隱私問題,這類方法在許多室內應用場景中難以推廣。
為了避免涉及隱私問題的同時改善入住率感知精度,本文提出一種基于機器學習框架的建筑入住率感知模型。利用多傳感器獲取建筑內已存在的數據流(不涉及隱私問題),嘗試將不同數據源的信息進行融合,評價不同機器學習算法在建立建筑入住率感知模型時的有效性。此外,還將進一步地探索不同模型在不同季節(jié)、不同樓層之間的可轉移性。
1 研究方法
1.1 數據描述
文獻[7]提供了位于加拿大渥太華卡爾頓大學某辦公樓的入住率及相關數據,其中包括室內多個位置的CO2傳感器讀數,接入Wi-Fi終端設備數,瞬時照明負載和瞬時插座負載,同時利用攝像頭記錄下每個時刻的真實用戶數量,記錄的時間間隔均為5分鐘。為了便于分析,本文將原始數據集按照樓層和季節(jié)劃分成了四個數據集,具體細節(jié)見表1。
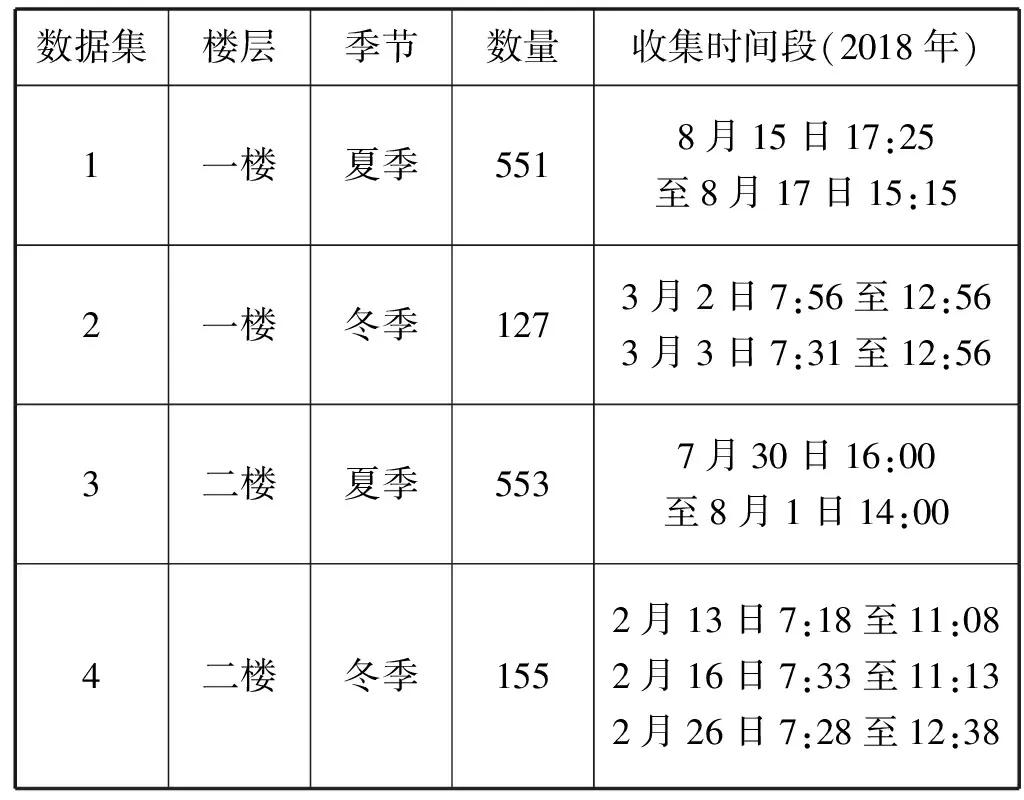
表1 數據集劃分
1.2 數據預處理
從建筑物中收集的原始數據一般不能直接用于機器學習建模,因為原始數據中可能具有以下問題:1) 原始數據一般包含噪聲和缺失值;2) 原始數據通常具有無關信息或冗余信息。前者一般通過數據清洗等數據預處理方法解決;后者一般通過特征選擇來進行數據篩選,常用的方法有主成分分析[8]、信息增益理論[9]等。
圖1(a)為數據集1中的各項數據(特征),其中:CO2濃度是指原始數據中室內多個位置的CO2傳感器讀數的平均值;總負載是原始數據中照明負載與插座負載之和。表2中,建筑內的實際人數被劃分成了四個入住率水平,這是因為對實際的建筑設備而言,如空調系統(tǒng),入住率水平已能夠滿足其控制策略的優(yōu)化,同時降低了建立入住率感知模型的難度。圖1(b)為數據集1中的實際人數與入住率。

圖1 數據集1展示
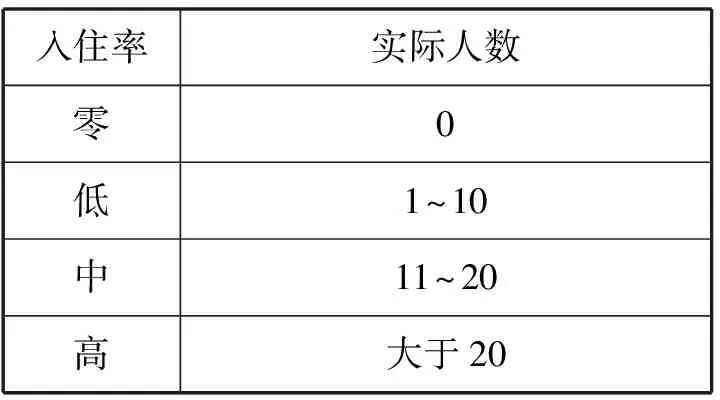
表2 入住率水平
1.3 特征選擇
數據集1中的5個特征可以組成31個特征子集,通過基于相關性的特征選擇方法(Correlation-based Feature Selection,CFS)對特征子集進行篩選,有助于提高入住率感知模型的準確率。好的特征子集需要包含與類高度相關的特征,并且特征之間彼此不相關,CFS的優(yōu)勢便是其不僅考察特征子集中單個特征的預測能力,還考察特征之間的冗余程度[10],其啟發(fā)式方程為:
(1)
式中:Merit是包含n個特征的特征子集的啟發(fā)式“度量”,大小在0到1之間,值越靠近1則說明該特征子集越好;rcf和rff均為皮爾遜相關系數,rcf為特征-類相關系數,rff為特征-特征相關系數。
1.4 算法選擇與訓練
建筑入住率感知模型屬于多元分類任務,將選取7種常見的監(jiān)督學習類機器學習算法,包括邏輯回歸、支持向量機(線性、徑向基)、K近鄰、樸素貝葉斯、決策樹、隨機森林。
處理多元分類任務時,邏輯回歸算法一般確定為最大概率的類別;線性支持向量機用于處理線性可分的數據,通過訓練樣本尋找超平面來進行分類,而徑向基支持向量機分別用于處理線性不可分的數據,將其映射至更高維度,再進行分類;K近鄰算法通過距離度量找出離測試例最近的K個訓練樣本,以此確定測試例的類別;決策樹從訓練樣本中學習將預測空間簡單劃分為多個區(qū)域,從而進行多元分類;隨機森林通過創(chuàng)建許多分類樹來提高預測準確性[6,11]。
為了增強測試結果的穩(wěn)定性和保真性,在訓練機器學習算法時對數據集應用k折交叉驗證法,即將數據集劃分成k份,每次用k-1份的并集作為訓練集,用剩下的1份作為測試集,從而進行k次訓練與測試,最終返回的是k個測試結果的平均值[11]。
1.5 性能評估
利用機器學習進行建模之后,需要對入住率感知模型的性能進行評估,選取兩個常用的指標[12]:
(1) 準確率(Accuracy):即入住率感知正確的樣本數占樣本總數的比例。入住率感知模型目標是將準確率最大化。
(2)
(2) 均方根誤差(Root Mean Square Error,RMSE):入住率感知結果的平均誤差幅度。入住率感知模型目標是將均方根誤差最小化。
(3)
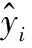
2 研究結果與分析
2.1 特征選擇
圖2為各特征與入住率之間的相關性熱點圖。可以看出,各特征與入住率水平都具有較高的相關性,其中最高的是Wi-Fi設備數,為0.81,說明建筑內接入Wi-Fi終端設備數最能反映入住率水平。同時各特征之間的相關性也很高,說明可能存在冗余特征。其中,照明負載、插座負載與總負載之間的相關性分別達到了0.95和0.93,呈高度相關,這是因為總負載是由前兩者求和所得。
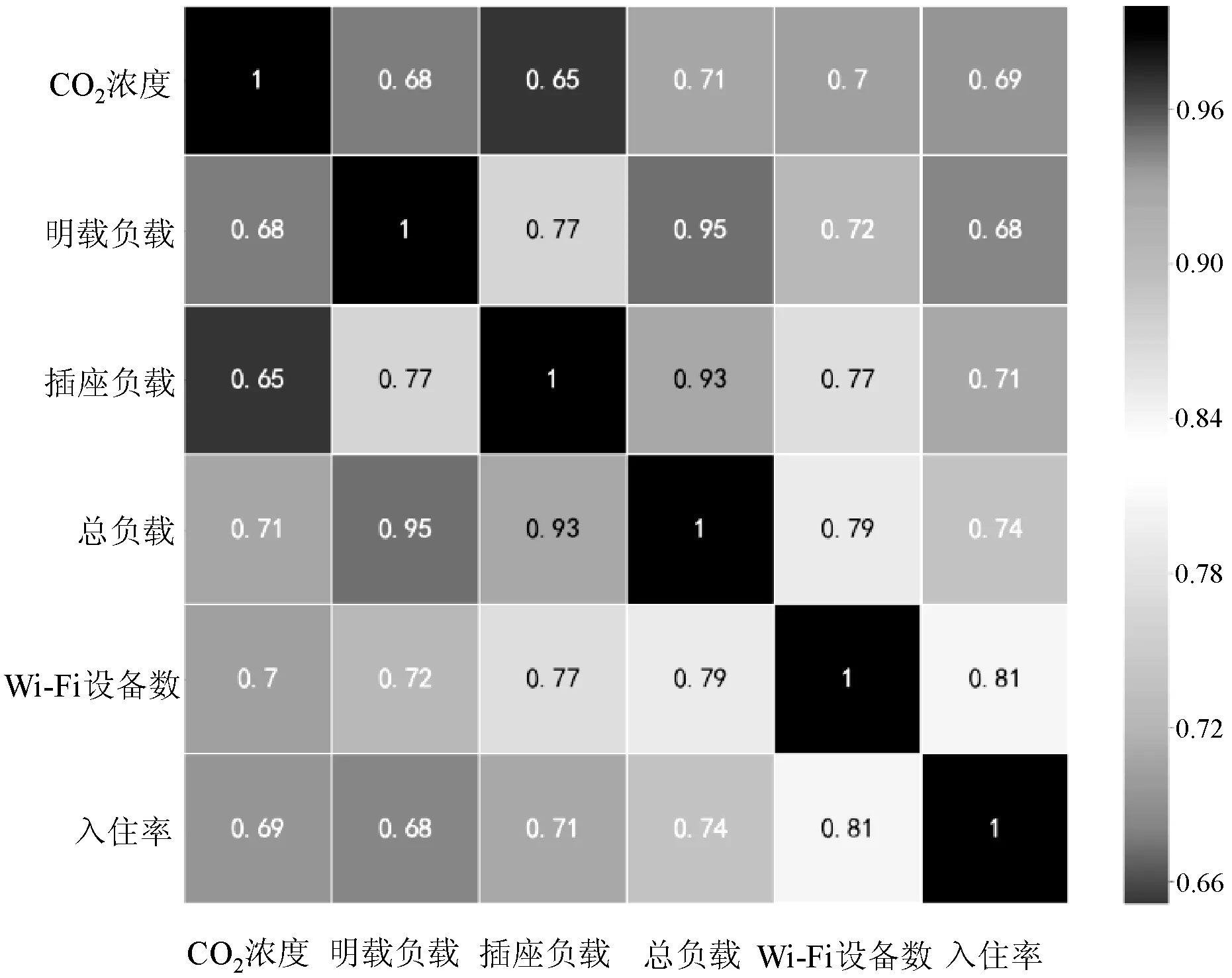
圖2 各特征間相關性熱點圖
表3為利用CFS對各特征子集的預測能力進行評估的結果。在單個特征的子集中,Wi-Fi設備數的Merit值最高,說明Wi-Fi設備數的預測能力最強,這與相關性熱點圖分析結果是一致的。在所有特征子集中,總負載與Wi-Fi設備數兩個特征融合的子集的Merit值最高,說明其預測能力最強,所以選擇該特征子集建立入住率感知模型。同時,可以看出多個特征融合的子集的Merit值不一定比單個特征的子集高,比如Wi-Fi設備數的Merit值為0.81,CO2濃度、照明負載、插座負載、總負載和Wi-Fi設備數五個特征融合的子集Merit值僅為0.798,說明多傳感器融合的預測能力不一定比單傳感器的預測能力強。
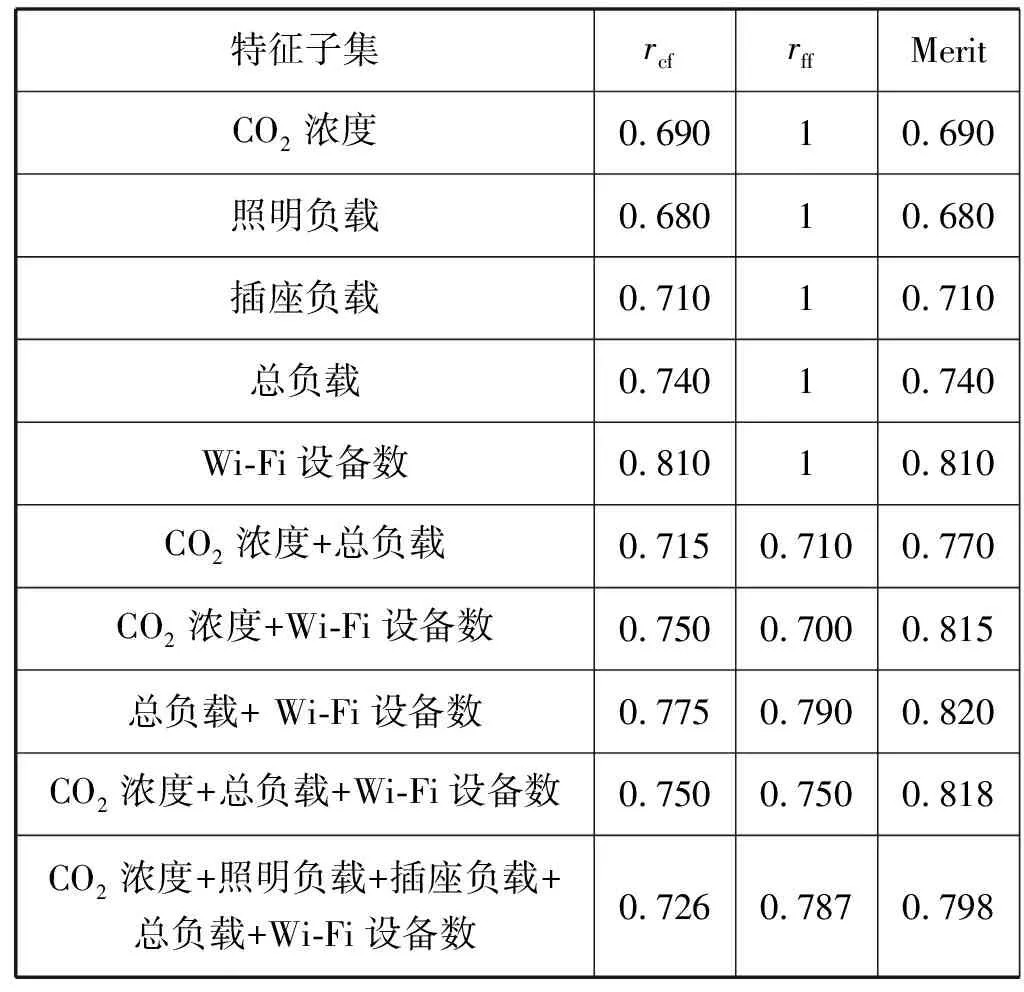
表3 基于相關性的特征選擇
2.2 入住率感知模型評估結果
(1) 有效性分析。有效性分析是指在同一數據集(即同一季節(jié)同一樓層)中進行訓練與測試。以數據集1為例,選取總負載與Wi-Fi設備數兩個特征融合的子集進行有效性分析,利用10折交叉驗證法確保評估結果的穩(wěn)定性,結果見表4。所有算法的準確率平均值都超過了60%,說明總負載與Wi-Fi設備數兩個特征融合能夠有效感知建筑內入住率水平。其中:線性支持向量機獲得了最高的準確率平均值(77%)和最低的均方根誤差平均值(0.37);徑向基支持向量機和樸素貝葉斯也有較好的結果;而決策樹的結果最不理想,準確率僅為61.7%。
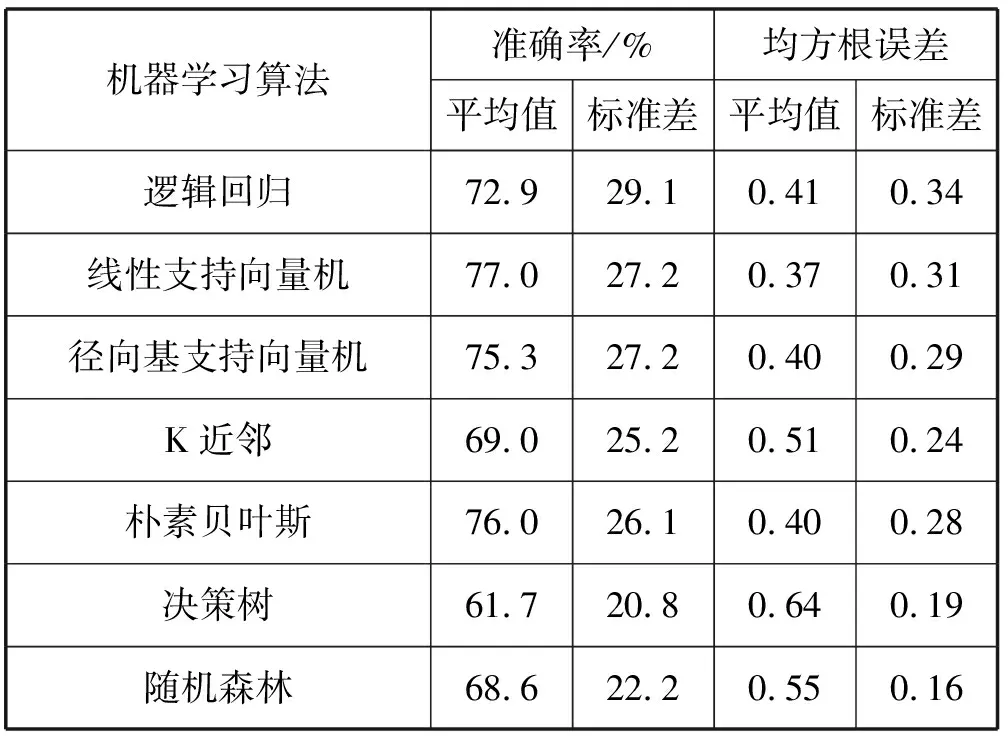
表4 入住率感知模型的有效性分析
(2) 可轉移性分析。可轉移性分析是指將訓練好的入住率模型在不同樓層或不同季節(jié)中測試(即在一個數據集上訓練的入住率感知模型在另一個數據集上進行測試分析)。監(jiān)督類機器學習算法在建立入住率感知模型時需要收集一定的數據,十分耗時,若能夠將訓練好的入住率感知模型在不同建筑或房間、不同季節(jié)間進行轉移,則能夠大大減少訓練成本,增加入住率感知模型的可用性。
表5為同一樓層不同季節(jié)中的可轉移性測試結果(在數據集1上訓練,在數據集2上測試)。可以看出,所有算法的準確率也都超過了60%,并且與在同一季節(jié)同一樓層測試的結果接近,說明入住率感知模型在不同季節(jié)間是可以轉移的。其中徑向基支持向量機和樸素貝葉斯獲得了較高的準確率(84.3%和82.7%)和較低的均方根誤差(0.40和0.42),而決策樹算法的結果依舊是最差的(68.5%和0.56)。
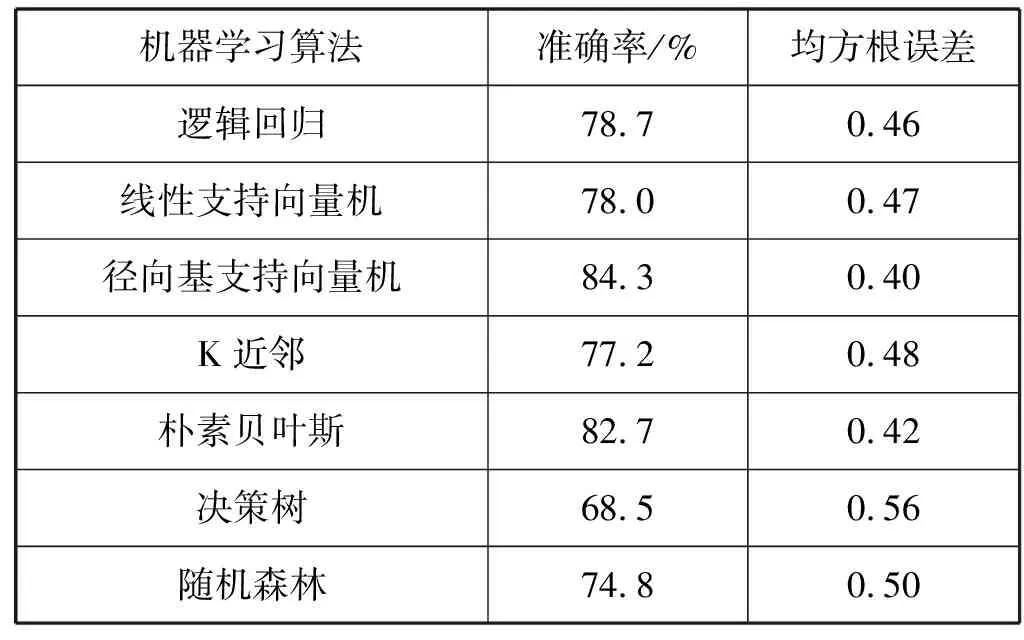
表5 入住率感知模型在不同季節(jié)的可轉移性分析
表6為不同樓層同一季節(jié)的可轉移性測試結果(在數據集1上訓練,在數據集3上測試),表7為不同樓層不同季節(jié)的可轉移性測試結果(在數據集1上訓練,在數據集4上測試)。在不同樓層中轉移應用時,各算法的準確率基本都低于40%,說明基于這些機器學習算法的入住率感知模型在不同樓層中的可轉移性是不可靠的。可以看出,即便本文中不同樓層的大小、結構和方向大致相同,但是室內布置、傳感器位置和用戶行為的變化都可能為入住率感知模型的轉移增加許多挑戰(zhàn),需要探索新的特征或者其他更先進的機器學習算法。
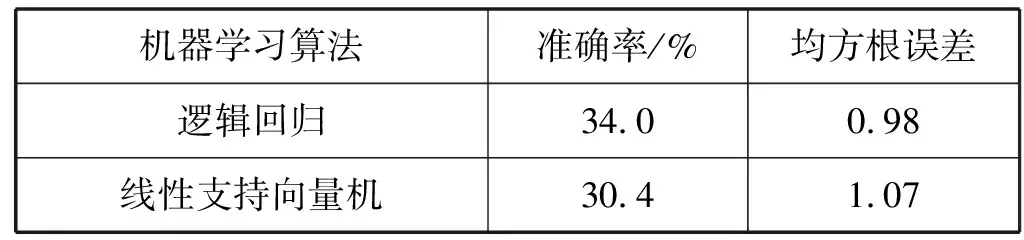
表6 入住率感知模型在不同樓層的可轉移性分析

續(xù)表6
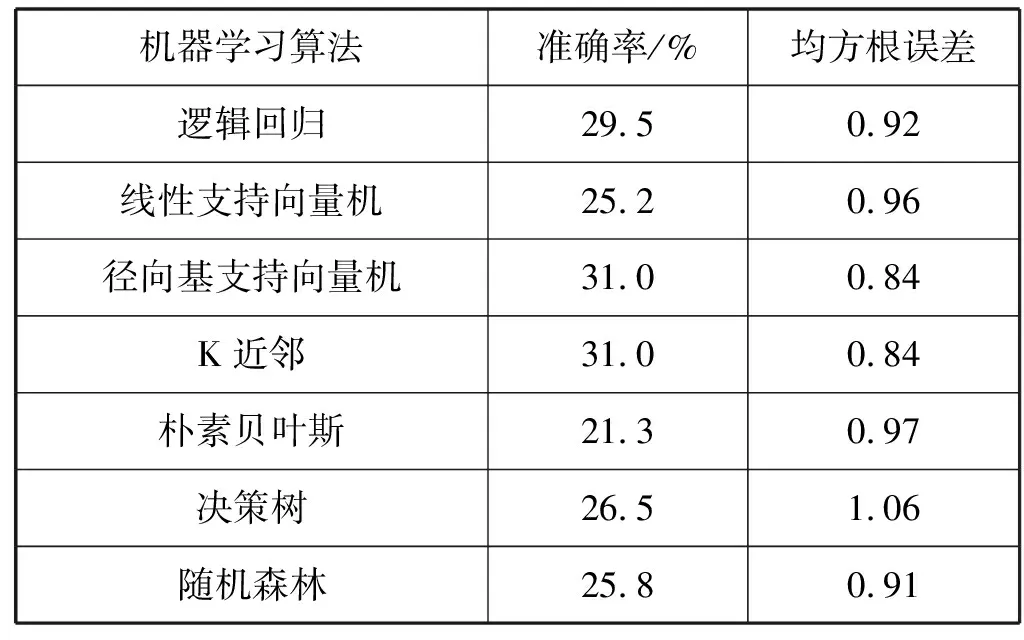
表7 入住率感知模型在不同樓層和不同季節(jié)的可轉移性分析
3 結 語
為了避免涉及隱私問題的同時改善入住率感知精度,首先利用CFS對多傳感器數據進行篩選,再利用7種機器學習算法建立入住率感知模型。以某辦公樓的入住率數據為例進行研究,結果顯示多傳感器融合能夠有效感知建筑入住率水平,并且入住率感知模型能夠應用在不同季節(jié)中,支持向量機(包括線性和徑向基)和樸素貝葉斯算法在預測入住率時均具有較好的預測性能。但是入住率模型在不同樓層中應用時,所有算法準確率均偏低。此外,研究結果還表明,由于冗余特征的存在,多傳感器融合的預測能力不一定比單傳感器的預測能力強。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫(yī)藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
