云數據中心能量與熱量感知的虛擬機合并與部署
2021-01-15 08:31:34張靜
計算機應用與軟件 2021年1期
張 靜
(常州信息職業技術學院 江蘇 常州 213164)
0 引 言
云計算將傳統的計算能力獲取模式轉變為當前的服務租用模式[1],基于資源的實際使用情況,按需以即付即用的彈性服務利用方式向用戶提供資源。云數據中心是云服務的支撐基礎設施。為了滿足巨量規模云服務不斷增長的計算需求,數據中心需要配置數以千計的服務器。然而,數據中心同時需要消耗巨大的能量提供云服務。根據美國能源部的報告[2],美國的數據中心消耗了其國家總能量的2%(約7×1010kWh)。數據中心不僅消耗能量,同時還會產生巨量的溫室氣體,導致很高的碳排放。具體地,每年有430億噸CO2排放,每季度在以13%的速度增長[3-4]。因此,改進數據中心的能效對于云計算的可持續發展和營運代價將是至關重要的。
云數據中心的主要能耗來源于計算系統和冷卻系統,基本上,冷卻系統的能耗等于計算系統的能耗[5]。因此,數據中心資源管理系統需要同步考慮計算和冷卻系統,從而實現全局整體能效的改進。
為了降低計算能耗,將負載合并至更少的主機上是一種有效方法,這樣可以保持未使用的主機處于低功能狀態[6-9]。然而,這種激進的合并可能導致局部熱點的產生。熱點主機的產生對于整個數據中心系統的可靠性具有很大的不利影響[10]。此外,若超過主機的溫度閾值也會導致CPU硅組成的損壞,進而導致主機的失效。為了進一步解決散熱問題,冷卻系統會傳輸很多的冷空氣進而增加冷卻系統的代價。而通過最優的負載分布的熱量管理方法可以有效避免熱點出現,并同步降低數據中心的能耗。
數據中心的溫度變化也與多個因素相關。首先,主機功耗所揮發的熱量會分布至數據中心環境中[11],這種功耗與資源的利用率是成正比的。其次,機房空調系統CRAC所提供的冷空氣本身也會攜帶一定溫度,即所謂的供冷溫度。最后,主機的入口溫度具有時空現象[12]。從一臺主機所揮發的熱量會影響其他主機的溫度。由于熱空氣熱力學的特征,這種熱量會在數據中心內循環存在。經過主機的空氣并不會完全到達回流口,部分仍將留在主機所在空間。解決這種時空特征也可以優化能量使用。
此外,估算數據中心溫度也有一定難度。目前主要有三種方法:(1) 計算流體動態模型進行精確預測[13],這種方法固有的復雜性使其應用在實時在線調度問題上計算代價太高;(2) 利用如機器學習的預測模型,這種方法極大地依賴于預測模型和數據的數量和質量;(3) 分析模型,主要根據熱量的熱力學特征和數據中心的物理屬性進行預測。
動態虛擬機合并是數據中心節省能耗的有效手段,而這些合并算法對于實體布局和物理主機的位置并不可知。進一步,由于數據中心內部溫度的分布,將負載合并至較少的主機上并不一定會節省能耗,這可能導致冷卻系統的代價升高和創建一些熱點主機,但部分合并的確能解決部分能耗問題。
相關研究中,文獻[7]設計了一種功耗感知的PABFD算法。該算法是一種基于功耗感知的修改最佳適應算法,但僅僅考慮了合并過程中的CPU利用率,并沒有考慮虛擬機合并和部署過程的主機熱量問題。文獻[14]在異構數據中心中提出一種功耗和溫度感知的負載分配算法,但算法中沒有對空調系統的制冷模型進行建模和考慮,導致最終的負載分配得到的能耗并不是全局最佳的。文獻[15]提出基于DVFS的對偶時空感知的作業調度算法,但是這些方案均不能直接應用于虛擬云數據中心中。文獻[16]提出一種GRANITE算法,該算法是一種以最小化數據中心能耗為目標的貪婪虛擬機調度算法,可以動態地進行虛擬機遷移,從而將負載均勻分配,使主機溫度在確定的溫度閾值以內。然而,貪婪算法的尋優解雖然可以控制主機溫度不超過閾值,但實際溫度距離閾值仍有距離,即主機利用率并未達到最優,總體能耗仍有下降的余地。文獻[17]提出了一種TAS算法,該算法是一種溫度感知調度算法,所選目標主機是溫度最低的主機。文獻[18]設計了一種二階段啟發式虛擬機部署算法,先降低主機利用數量,再進行虛擬機遷移。文獻[19]提出一種能耗與性能協調的虛擬機重部署方法,同樣使用了與上文類似的裝箱思想對主機利用數量進行優化。以上兩篇文獻的問題在于僅僅以最小化主機使用量來降低總體能耗,沒有考慮冷卻系統帶來的能耗問題,因此最終能耗并不一定是最優的。
本文使用溫度狀態的分析模型提出一種基于動態虛擬機合并的在線調度算法,同步考慮主機能量利用和冷卻系統的能耗問題,利用貪婪隨機自適應搜索機制求解能效更高的虛擬機合理部署方案,并通過在實際負載下的一系列仿真實驗,驗證算法在能效提高和性能提升上的優勢。
1 系統模型
表1為本文涉及的主要符號和說明。
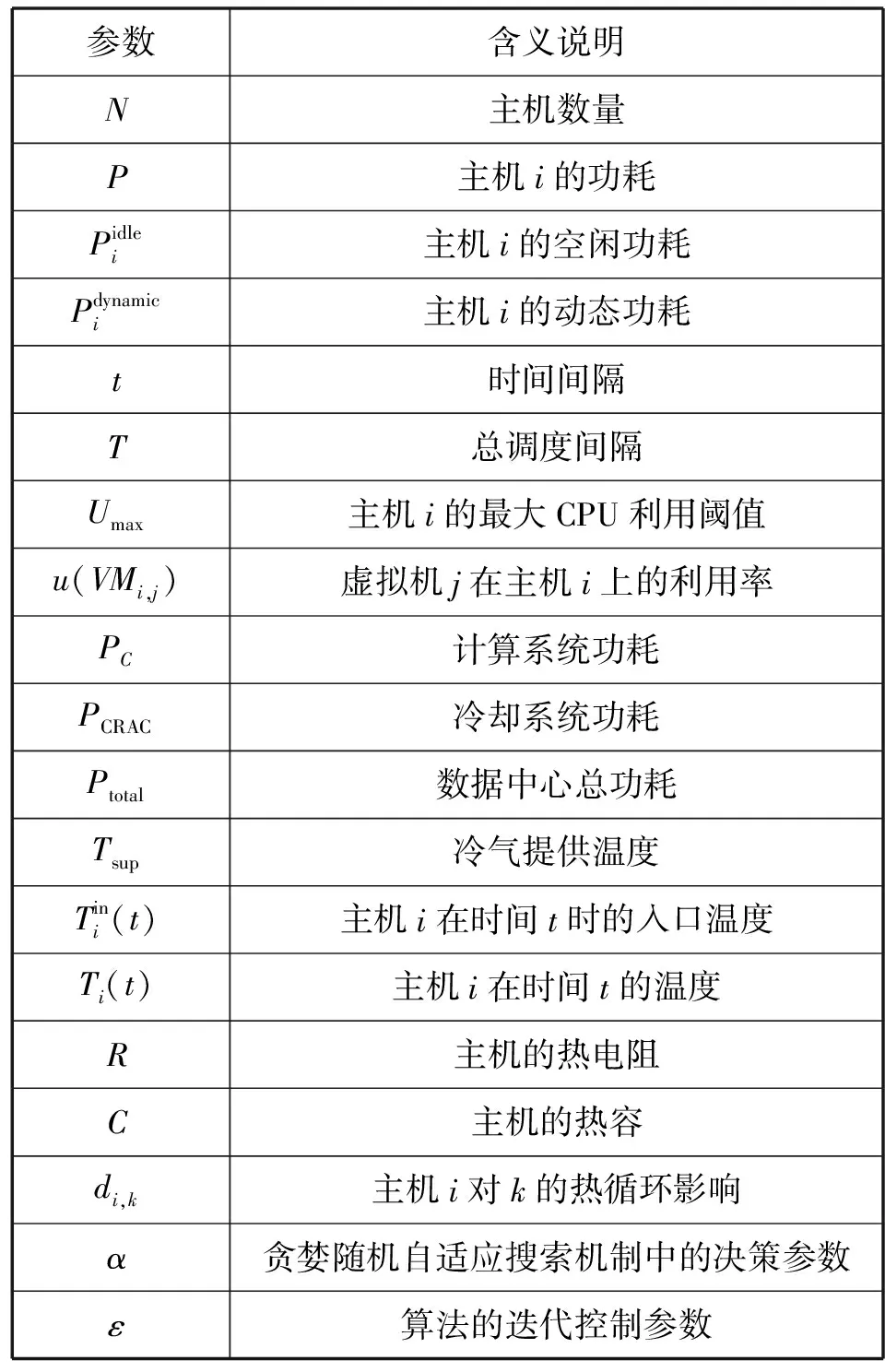
表1 參數說明
1.1 主機模型
數據中心由若干具有不同處理能力的異構主機組成,主機功耗主要由其資源利用等級決定,本文利用以下的線性功耗模型:
(1)
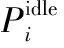
1.2 溫度模型
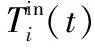
(2)
考慮到在數據中心內部以及主機的物理機架部署情況下熱量再循環的存在,本文將這種熱量再循環的影響量化為一種熱量分布矩陣D,每個元素di,k表示主機i對主機k的進氣溫度的影響因子,這種影響因子為主機k的功耗Pk(t)的數量級。由式(2)可知,盡管機房空調系統CRAC能夠傳送類似的冷氣溫度至所有數據中心內的主機,但每個主機由于其物理位置不同和熱量再循環的影響,其進氣溫度依然是變化的。
主機i的CPU溫度由其CPU的散熱決定,根據RC模型可定義時間t時的溫度為:
(3)
式中:e為自然常數,Tinitial為CPU初始溫度。根據式(3)可知,主機CPU溫度不僅由功耗控制(主要因素,正比于CPU速率或負載級別),還由硬件特定量R和C以及進氣溫度決定,說明式(3)所使用的CPU溫度分析模型可以捕捉主機溫度的動態行為。
1.3 機房空調系統CRAC模型
數據中心的熱量管理主要由機房空調系統CRAC進行。現代數據中心中,機架通常安排在通風口,冷空氣從機架底部向上流通。假設數據中心由多個CRAC單元組成,表示為CRAC={CRAC1,CRAC2,…,CRACn}。考慮CRAC為數據中心內唯一可用的冷卻來源。這種冷卻系統的效率以性能度量系數CoP進行度量。CoP是冷氣提供溫度Tsup的函數,定義為計算系統的總體功耗與冷卻系統的總功耗之比:
(4)
數據中心的CoP對于不同的數據中心環境配置也不相同,它取決于物理布局及數據中心熱力學特征。本文使用HP Lab數據中心的性能度量模型:
(5)
式(5)表明,通過增加Tsup值,可以增加冷卻系統的效率和降低冷卻功耗。
1.4 負載模型
用戶向云數據中心發送的請求可考慮為任務形式,假設n為任務總量,也可理解為任務執行請求n個虛擬機,將其表示為VM={VM1,VM2,…,VMn}。根據虛擬機建立負載模型,每個虛擬機可執行單個任務,每個任務擁有CPU請求Rcpu、內存請求Rmem、任務長度l。因此,每個任務可表達為三元組{Rcpu,Rmem,l}。為了解決動態虛擬機合并問題,實驗中將一次性發送所有任務請求,在每個間隔中利用調度策略進行動態的虛擬機合并和部署,并分析算法性能。
2 能量和熱量感知的虛擬機合并
2.1 問題描述
數據中心能耗主要產生于計算和冷卻系統,計算系統由主機構成,其能耗可定義為:
(6)
根據式(6)計算系統能耗為所有主機能耗之和。變量xj表示:若主機j為活躍狀態,則其值為1;否則為0。計算系統的能耗由所有活躍主機能耗組成,因此,在每個調度間隔中優化活躍主機的數量是至關重要的。
冷卻系統CRAC能耗定義為熱負荷與數據中心CoP之比。考慮到計算系統能耗基本隨著熱量消散至數據中心的周圍環境,可將熱負荷表示為PC。因此,冷卻系統能耗可定義為:
(7)
式中:ThermalLoad表示熱負荷。
根據式(7),冷卻系統能耗可通過增加CRAC提供的冷氣溫度或降低熱負荷的方式降低。因此,通過虛擬機合并,可以降低數據中心熱負荷,并同步在給定冷氣溫度下主動地避免產生熱點主機。數據中心總體能耗表示為:
(8)
虛擬機部署與合并算法需要同步感知計算系統和冷卻系統能耗,由于過多虛擬機合并會導致熱點主機,而負載過于分散又會導致過高的能耗。因此,本文的最優化問題可定義為:
目標函數:
(9)
約束條件:
u(hi)≤Umax
(10)
Ti(t)≤Tred
(11)
(12)
xj∈{0,1}
(13)
式(9)為最小化數據中心總體能耗;式(10)確保主機利用率需小于或等于占用閾值;式(11)確保主機溫度需小于或等于最高溫度閾值;式(12)確保主機必須具有滿足需求的CPU和內存資源才可以進行虛擬機部署,即能力約束;xj為二進制變量,若虛擬機部署于主機i,則取值為1,否則為0。考慮到目標函數最優化求解在一定規模的數據中心內是一個NP問題,本文將設計一種基于貪婪隨機自適應搜索機制GRASP的啟發式算法進行虛擬機能效部署求解,并以合理的時間復雜度得到近似最優解。
2.2 算法設計
本節設計基于貪婪隨機自適應搜索機制GRASP的虛擬機部署算法。GRASP是一種迭代式隨機優化方法,其每次迭代由兩個階段組成:1) 貪婪構建階段,即通過從解空間中隨機取樣的方式基于貪婪函數構建解列表;2) 局部搜索階段,即從先前貪婪構建列表中通過鄰居搜索方式尋找當前最優解。迭代過程到達確定的終止條件為止。GRASP的自適應特征可以動態地更新目標的貪婪值,而基于概率的取樣特征則有機會完成近似最優解。同時,其解空間規模的靈活選擇特征以及終止條件的設置也可以調整貪婪值和計算復雜性的程度。
動態虛擬機部署主要由三步構成:
1) 發現熱點主機和低負載主機。
2) 從步驟1得到的主機中選擇需要遷移的虛擬機。
3) 將所選虛擬機重新部署至新的目標主機上。
對于動態合并的前兩個步驟,使用如下策略。為了發現超載主機,算法利用靜態CPU利用率閾值Umax和CPU溫度最高閾值Tred作為門限參數。若兩個參數其一被超過,則視為超載主機。低載主機的發現思想是:對于所有未超載的活躍主機,如果這類主機上的所有虛擬機可遷移至其他主機上,則該主機視為低載主機。對于動態合并的第二個步驟,需要從超載主機選擇虛擬機遷移至其他主機直到該主機不超載。算法主要思想是選擇擁有最小遷移時間的虛擬機進行遷移,從而降低主機負載,由于這類虛擬機擁有更小的內存使用,在帶寬有限的情況下,其遷移過程花費的時間更少。
假設在優化開始之前,數據中心已經到達穩定狀態,即所有請求的虛擬機已經部署至主機上,且數據中心的溫度狀態已經達到穩定。算法1在每個調度間隔(5分鐘)開始時執行,得到此時需要遷移的虛擬機以及目標主機。
算法1能量和熱量感知的虛擬機合并算法
輸入:VMList,hostList。
輸出:energy,number of hotspot,SLA violation。
1. Initialize Tred,α,ε
2. for t=0 to T do
3. VMList←getVMsFromOverAndUnderUtilizedHosts()
4. for each vm in VMList do
5. allocatedHost=null
6. isSolutionNotDone←true
7. while isSolutionNotDone do
8. SolutionList←ConstructGreedySolution(VM,hostList)
9. newHost←LocalSearch(SolutionList)
10. δ=allocatedHost.τ-newHost.τ
11. if δ>ε then
12. allocatedHost←newHost
13. else
14. isSolutionNotDone←false
15. end if
16. end while
17. if allocatedHost==null then
18. allocatedHost=getNewHostFromInactiveHostList()
19. end if
20. end for
21. end for
算法1的第一步需要對紅線溫度Tred、GRASP中的約束候選解的規模α及解的改進質量控制參數ε進行初始化。在每個間隔中,步驟3對超載和低載主機上的所有虛擬機進行標識。對于來自于遷移列表中的每個虛擬機,步驟5將初始化待分配的主機為空,步驟7-步驟16則為貪婪隨機自適應搜索機制中的貪婪策略。該階段中,每次迭代有兩個步驟:1) 在搜索空間中構建可行解列表,即一個容納當前虛擬機的可能的主機列表;2) 執行局部搜索,尋找局部最優候選解,即子最優解。為了達到全局最優,在每次迭代中,所分配的主機需要根據步驟12中構建階段的貪婪值τ進行更新。如果當前分配的主機和新分配的主機貪婪值τ之差大于預定義參數ε,則迭代過程繼續;否則,終止迭代,將當前分配的主機返回為最終結果,即步驟11-步驟15。這里,ε是決定在先前解的基礎上新解改進質量的參數。如果當前迭代中的新解比較先前迭代時的ε沒有得到改進,則終止過程。若該過程無法找到容納當前虛擬機的可用主機,則從空閑主機列表中啟動新主機,即步驟17-步驟18。
算法2是貪婪構建解階段。算法將虛擬機和主機列表作為輸入,并輸出可行部署解。過程第一步是構建RCL,它代表在有限解搜索空間中所構建的一個解列表。RCL的形成可以限制解空間中的搜索數量,降低算法時間復雜度。最后,需要排列不活躍主機,并從活躍主機中選擇百分比為α的主機進入RCL,這可以確保搜索空間進一步降低。另外,通過隨機取樣方式選擇活躍主機的百分比α進入RCL即為GRASP的概率機制。RCL中的每個主機的代價可表示為τ。
算法2貪婪構建可行部署解算法(Construct Greedy Solution)
輸入:VM,hostList。
輸出:SolutionList。
1. SolutionList←null
2. RCL←makeRCLFromActiveHostList
3. for each s in RCL do
4. if s is suitable for VM then
5. s.τ←(1+1/CoP(Tsup))Pi
6. end if
7. SolutionList←∪S
8. end for
9. return SolutionList
算法3顯示了局部搜索機制,以尋找每次迭代中的局部最優解。基于所計算的貪婪值τ,最優局部候選解被返回為算法3的解。該算法不僅可以降低能耗,而且可以在滿足資源能力在CPU、內存、帶寬約束下避免溫度高于閾值。算法2的步驟4即可滿足式(9)的約束條件。并且,參數α和ε起到了調節參數作用,用于調整算法的貪婪程度和決策時間。若系統精確度要求較高,則可設置更大的參數值,但可能在搜索最優解時需要花費更長的時間。
算法3最優候選解局部搜索算法(Local Search)
輸入:SolutionList。
輸出:Host with local optima。
1. LocalOptimalHost←null
2. for each s in SolutionList do
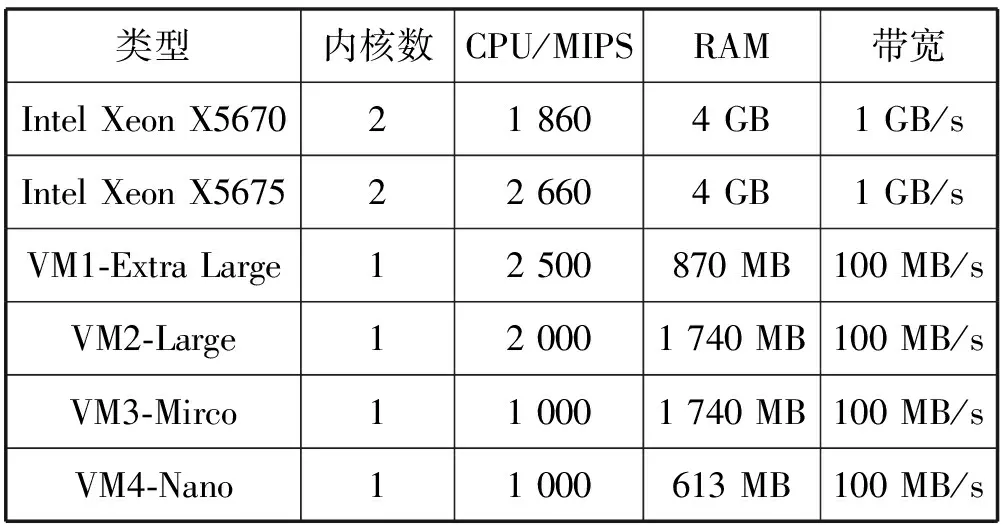
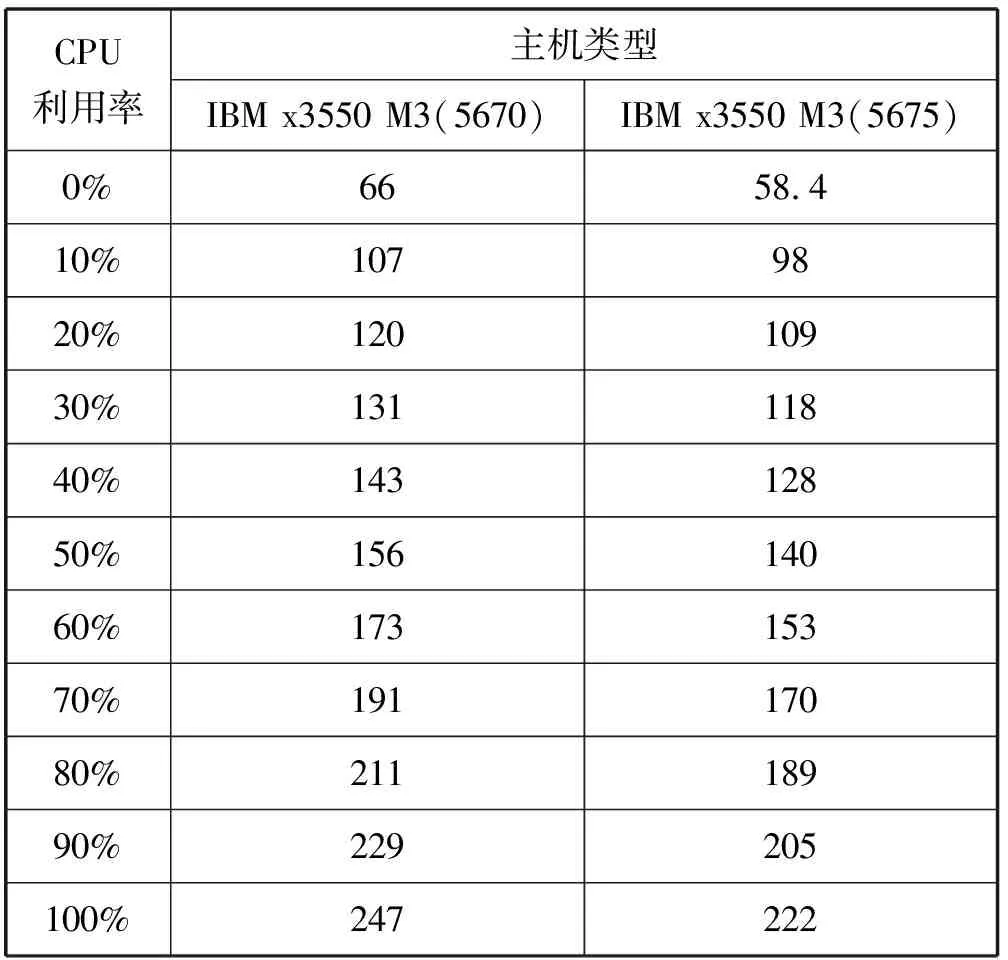
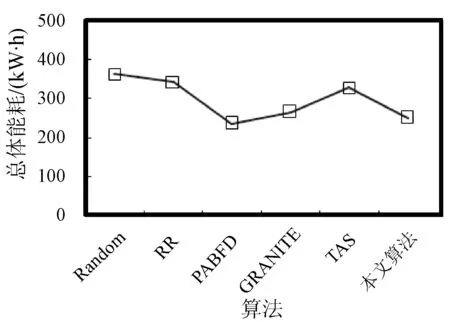
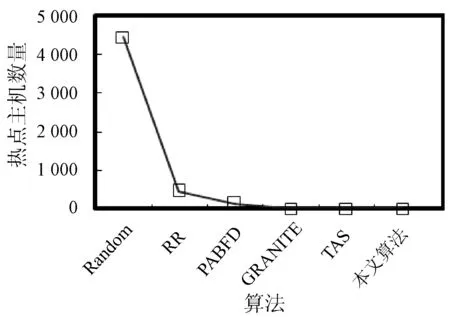
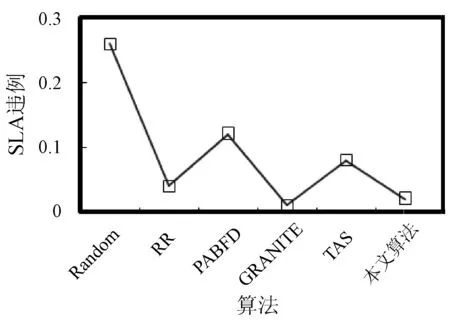
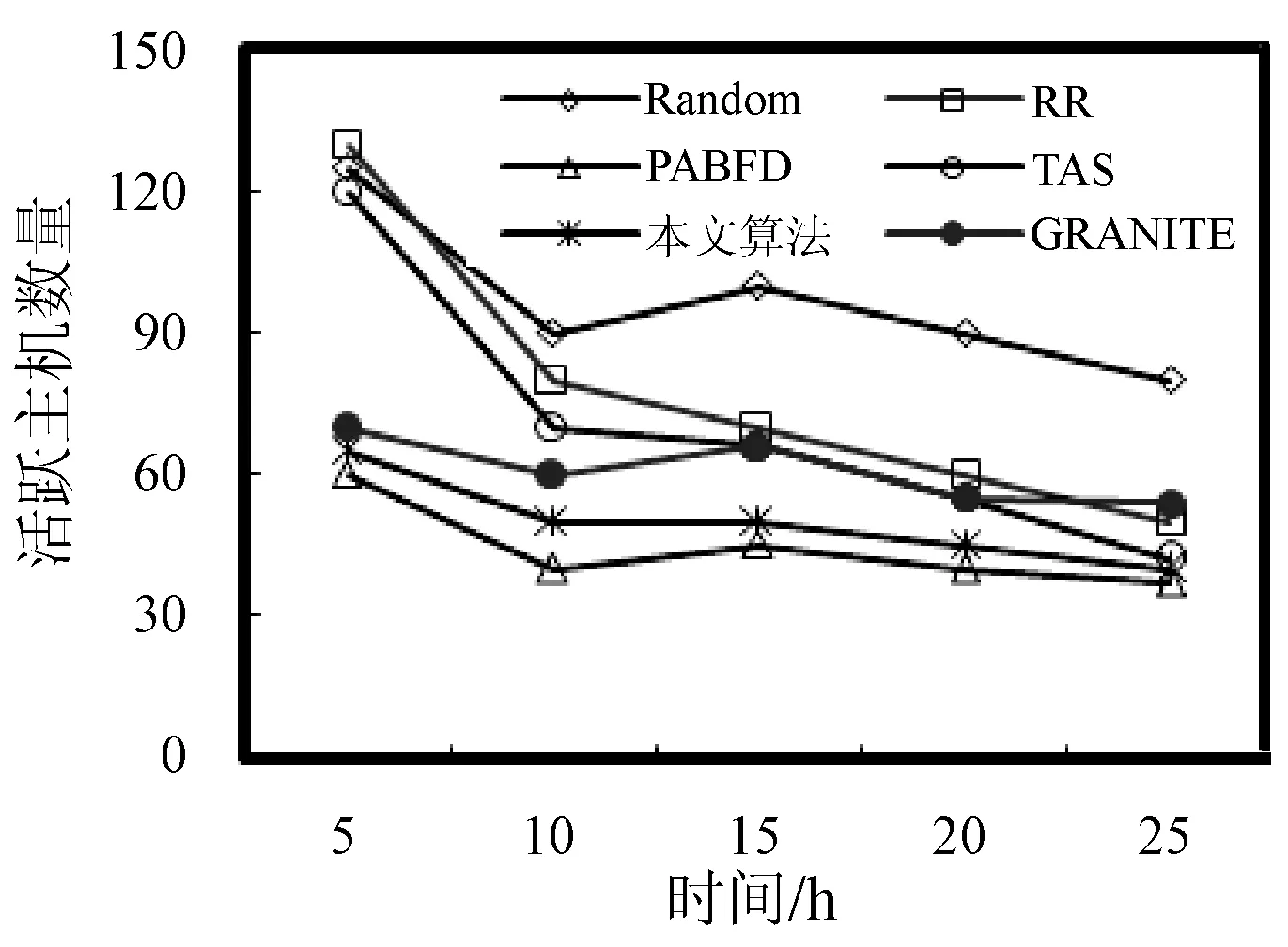
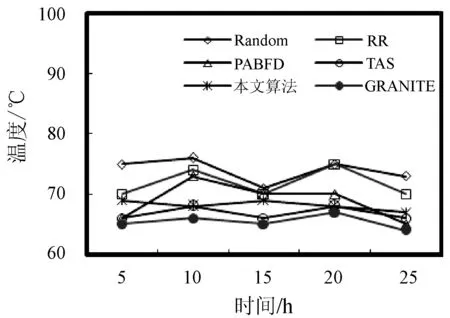
3. if s.τ 4. LocalOptimalHost=s 5. end if 6. end for 7. return LocalOptimalHost 本節評估算法可行性和性能,在cloudsim中構建仿真環境,模擬云計算系統。數據中心基礎設施由1 000臺異構主機組成,主機配置的處理能力參考IBM x3550 M3,處理器為Intel Xeon X5670和X5675,具體參數如表2所示。采用內核較少的CPU的原因在于可以展示在大量的虛擬機遷移下動態合并的效率。若內核較多,其容納虛擬機數量也越多,則虛擬機遷移機會也會降低。系統功耗利用SPECpower實驗床中的數據,它提供了在不同CPU利用率情況下對應主機的功耗情況,兩種主機類型的功耗情況如表3所示。 表2 主機CPU和虛擬機類型和配置 表3 主機功耗情況 W 虛擬機參考AWS給出的配置,如表2所示。主機配置在機架結構上,機架安排在若干區域內,每個區域配置10個機架,總共10行,每行10臺主機。假設在單個區域內存在熱循環,但在不同區域間不存在。實驗利用PlanetLab系統[20]生成仿真的負載流,該負載流統計了若干月份中數千臺虛擬機的資源利用率狀況,數據記錄每5分鐘進行一次,利用一天的數據流生成虛擬機的負載。 Random算法:將所有虛擬機隨機部署在所選主機上,不考慮主機熱量或功耗狀態。 RR算法:輪轉法,所有虛擬機以輪轉方式部署至主機上,試圖以均勻方式將負載分布至活躍主機上。 PABFD算法[7]:一種基于功耗感知的修改最佳適應算法,但僅僅考慮了合并過程中的CPU利用率,而沒有考慮熱量問題。 GRANITE算法[16]:一種以最小化數據中心能耗為目標的貪婪虛擬機調度算法,可以動態地進行虛擬機遷移,從而將負載均勻分配,使主機溫度保持在確定的溫度閾值以內。 TAS算法[17]:一種溫度感知調度算法,所選目標主機是溫度最低的主機。 式(3)中的熱電阻和熱容分別為0.34 K/W和340 J/K,初始的CPU溫度設置為318 K,CRAC提供的冷氣溫度Tsup=25 ℃。主機最高溫度閾值設置為95 ℃。需要注意的是,主機溫度并不是CPU散熱的唯一因素,還包括CRAC提供的冷氣。將CPU的動態最大溫度閾值設置為70 ℃。換言之,主機最大溫度閾值為95 ℃,在排除靜態部分Tsup之后,動態閾值溫度為70 ℃。CPU靜態利用閾值Umax設置為90%,參數α和ε設置為0.4和10-1。 能耗:主機執行負載帶來的能耗,單位kW。 由于過量訂購原因,主機可能達到滿利用率等級100%,此時,這類主機上的虛擬機會表現較差性能,即出現單個活動主機的SLA違例SLATAH,定義為式(14)。進一步,由于虛擬機遷移所帶來的虛擬機合并還會帶到性能開銷。這種虛擬機遷移所帶來的性能下降PDM可定義為式(15)。SLA違例:該指標描述由于動態合并帶來的性能開銷,定義為式(16)。 (14) (15) SLAviolation=SLATAH×PDM (16) 式中:N為主機總量;Tmax為主機經歷100%占用時間;Tactive為主機總活躍時間;M為虛擬機總量;pdmj為由于虛擬機j遷移帶來的性能下降,實驗設置為10%;Cdemandj為虛擬機j在周期內請求的CPU資源總量。總體SLA違例SLAviolation為兩個指標的乘積。 熱點主機:描述超過閾值溫度的主機數量。 活動主機:描述整個實驗過程中活躍主機的數量。 峰值溫度:描述調度間隔中任意主機的最大溫度。 圖1是算法的能耗情況,隨機算法最高能耗有363 kW·h,RR、PABFD、GRANITE和TAS算法分別達到342、235、265、327 kW·h,本文算法約為250 kW·h,同時還具有95%的置信區域CI,即(247,252)。換言之,本文算法比較隨機算法、RR、GRANITE和TAS算法能耗分別降低了31%、27%、23%。比較PABFD,本文算法能耗略高6%,這是由于PABFD算法比較本文算法進行了更積極的虛擬機合并,所使用的主機數量更少。但這種極端合并忽略了潛在的熱量約束,可能導致熱點。 圖1 能耗 圖2是算法得到的熱點主機情況,盡管PABFD比本文算法的能耗更少,但其創造了大量熱點主機。隨機算法的隨機順序對于能耗和熱點的產生均有較大影響,熱點最多。RR算法的均勻分布策略比較隨機算法具有一定優勢,熱點降低至約416臺,然而其能耗太高。PABFD約有123臺熱點主機,本文算法沒有產生一臺熱點主機。本文算法雖然能耗略高于PABFD,但沒有產生熱點,其優勢在于:1) 溫度過高可能使服務器失效;2) 熱點產生后,數據中心管理員需要進一步降低冷卻溫度,這會進一步增加冷卻系統能耗。 圖2 熱點主機數量 圖3是算法的SLA違例情況。算法的總體SLA違例需要計算出單個活動主機的SLA違例和所有的虛擬機遷移所帶來的性能下降。由式(14)可知,實驗中通過統計所有主機的總活躍時間和滿負載時間兩個參數值即可計算出單個活動主機的SLA違例。由式(15)可知,實驗中僅僅需要記錄虛擬機在周期內請求的CPU資源總量這一個可變參數即可計算出虛擬機遷移所帶來的性能下降。結合這兩個參數值,即可計算出算法在整個虛擬機部署周期內的SLA違例情況。隨機算法、PABFD和TAS的SLA違例較多,其他三種算法較少。盡管RR算法在做出部署決策時沒有考慮SLA需求,但其固有的負載均勻分布特征較隨機算法、PABFD和TAS算法還是可以降低一定SLA違例的。本文算法在SLA違例上表現得足夠優秀,同時還可以降低能耗和避免熱點主機產生,綜合性能最優。 圖3 SLA違例 圖4是算法活躍主機數量情況。標記時間是每隔一小時得到的均值結果。PABFD得到更少的活躍主機,而本文算法在PABFD的基礎上仍有增加,GRANITE則又高于本文算法,這種結果也可從圖1的能耗結果中推斷出來。隨機算法擁有最多活躍主機數量,TAS的增加幅度最小,并小于RR算法。同時,活躍主機數量、熱點主機及能耗之間的關系也可被推斷出來,擁有更少活躍主機的算法也傾向于會產生較多熱點主機。隨機算法顯得比較異常,由于它是隨機選擇主機的。總體來看,活躍主機數量在所有算法間并未表現出很大不同,原因在于算法在超載主機和低載主機發現機制上采用了相同策略。本文算法雖然沒有得到最少的活躍主機,但較PABFD能夠避免負載過于集中,溫度過高并避免熱點主機產生。 圖4 平均資源利用率 圖5是算法主機的峰值溫度情況。本文由于利用其熱量感知的虛擬機部署機制從未超過紅線溫度,并接近于紅線溫度,這樣極大提高了資源利用率,降低了冷卻代價。TAS總是運行在一個更低的溫度等級,而PABFD幾乎均運行在紅線溫度周圍,甚至超過紅線溫度70 ℃。GRANITE的主機峰值溫度一直是最低的,由于該算法僅僅考慮了溫度閾值,高溫度主機上的虛擬機會被遷移出去,從而均衡負載。盡管RR是均勻分配負載,但由于主機性能的差異以及未進行熱量感知,部分主機會超過紅線溫度。同時需要注意,圖5中的溫度結果并非所有主機的溫度均值結果,而是所有主機中最高的溫度。 圖5 主機的峰值溫度 本文提出一種同步優化計算系統和冷卻系統能耗的虛擬機合并算法。算法利用貪婪隨機自適應搜索機制,可以均衡虛擬機的合并積極度和虛擬機的稀疏分布,并有效避免產生熱點主機,導致主機溫度過高,使系統失效。大量仿真實驗結果證明,本文算法不僅可以節省更多能源,避免熱點主機生成,而且在性能保障方面(SLA違例)也表現出很好的性能。下一步的研究可考慮將機房空調系統CRAC的冷氣輸出溫度根據數據中心的運行狀況設置為變化的溫度,并在此基礎上設計虛擬機能效部署與合并算法,更好地節省能耗。3 仿真實驗
3.1 實驗配置
3.2 對比算法
3.3 參數選擇
3.4 性能指標
3.5 結果分析
4 結 語
