基于在線評論的企業競爭情報需求挖掘研究
2021-01-15 13:17:40谷瑩李賀李葉葉劉嘉宇
現代情報 2021年1期
谷瑩 李賀 李葉葉 劉嘉宇


收稿日期:2020-09-08
基金項目:國家自然科學基金項目“基于圖模型的多源異構在線產品評論數據融合與知識發現研究”(項目編號:71974075)。
作者簡介:谷瑩(1991-),女,博士研究生,研究方向:情報分析、數據挖掘。李賀(1964-),女,教授,研究方向:數據挖掘、知識管理。李葉葉(1994-),女,碩士研究生,研究方向:數據挖掘。劉嘉宇(1995-),男,碩士研究生,研究方向:數據挖掘。
摘 要:[目的/意義]提出一種基于在線產品評論的競爭情報挖掘框架,為企業改進產品設計和制定競爭策略提供參考。[方法/過程]利用Word2vec技術構建產品特征詞集合,識別用戶評論主題特征。然后使用情感分析方法對評論文本進行分類,得到特征維度的評論情感。最后從產品主題特征和情感態度特征兩方面進行數據分析,并以可視化結果呈現。[結果/結論]以汽車行業的評論數據為例進行實驗,結果表明該方法能夠有效提取產品情報信息,幫助企業有效識別自身品牌及競爭對手的優勢和劣勢,為大數據環境下的競爭情報挖掘提供方法指導。
關鍵詞:在線評論;企業;競爭情報;數據挖掘;Word2vec;情感分析;汽車行業
DOI:10.3969/j.issn.1008-0821.2021.01.003
〔中圖分類號〕G250.25 〔文獻標識碼〕A 〔文章編號〕1008-0821(2021)01-0024-08
Research on Demand Mining of Enterprise Competitive
Intelligence Based on Online Reviews
Gu Ying Li He Li Yeye Liu Jiayu
(School of Management,Jilin University,Changchun 130022,China)
Abstract:[Purpose/Significance]This paper proposes a competitive intelligence mining framework based on online product reviews,for the aim of providing a reference for companies to improve product design and formulate competitive strategies.[Method/Process]Word2vec was used to construct product feature word collections to identify user comment topic features.Then,the paper applied sentiment analysis methods to classify review texts and obtain review sentiment in feature dimensions.Finally,this paper took the review data of automobile industry as an example,and presented the visualization results.[Result/Conclusion]The experimental results showed that the method could effectively extract product information,help companies effectively identify the advantages and disadvantages of their own brands and competitors,and provide method guidance for competitive intelligence mining in a big data environment.
Key words:online product reviews;enterprise;competitive Intelligence;data mining;Word2vec;sentiment analysis;automobile industry
隨著Web技術的迅速發展和信息化的廣泛應用,人們信息交流和信息獲取的方式發生了顯著變化。據CNNIC的第45次《中國互聯網絡發展狀況統計報告》顯示,截至2020年3月,中國網民規模為9.04億,互聯網普及率64.5%,較2018年底提升4.9個百分點[1]。互聯網環境下,越來越多的消費者傾向于通過網絡平臺分享關于產品的使用體驗和看法,這些評論以文本的形式傳播,從而形成網絡口碑。作為網絡口碑的主要來源,在線評論體現出消費者對產品質量的情感評價。研究表明,在線產品評論會影響消費者的品牌認知,從而影響其決策行為[2]。同時企業市場競爭日趨激烈,產品同質化嚴重,在線評論作為一種新型情報源,挖掘評論中潛在的價值,有助于企業經營管理和建立良好的品牌形象[3]。互聯網平臺為企業提供了開放的信息渠道,通過獲取用戶反饋信息,企業可以進行自我分析與競爭對手分析,從而改進產品設計,制定正確的市場競爭策略[4]。然而在線產品評論數量巨大,多以非結構化文本呈現,傳統分析方法難以適用,如何從海量的評論中提取高質量的信息成為亟需解決的問題。鑒于此,本文提出一種面向在線產品評論的競爭情報需求挖掘框架,采用深度學習技術和情感分析方法,從用戶視角細粒度挖掘企業情報。
1 相關研究
1.1 在線評論特征詞抽取研究
特征是用戶評論語句中粒度最細的評價單元,產品特征主要表現為消費者對某一產品功能、組成部件及屬性的關注程度。產品特征抽取作為研究在線評論挖掘的關鍵技術,特征抽取的準確性直接影響評論挖掘的效果。關于產品關鍵詞抽取,學者們已經積累了不少研究成果。Hu M等最早提出結合詞頻和關聯規則方法從產品評論中抽取候選關鍵詞,并使用剪枝過濾算法識別出評價對象及其功能特征[5]。Quan C等在產品特征提取研究中,將互信息法引入Tf-idf算法中,設計新的相似性度量方法用以評估候選對象與領域實體關系,據此實現無監督的抽取方法[6]。王娟等結合句法結構和依存關系抽取情感評價單元,完成了領域情感評價對象的自動抽取,提高了情感傾向計算的準確性[7]。彭云等利用句法分析和詞義理解獲取語義關系,提出SRC-LDA主題模型,挖掘特征詞與情感詞語義相關性,實現語義約束下的細粒度主題特征抽取[8]。王榮洋等基于條件隨機場模型,引入語義角色標注方法,捕獲評價對象和情感詞的關系,用于評價對象的抽取[9]。已有研究主要通過詞頻規則或主題模型提取產品特征,然而這些方法沒有考慮詞語信息的深層語義聯系。
近年來,隨著深度學習技術的出現,神經網絡模型在情感分析領域逐漸受到關注。相比其他模型,Word2vec以無監督的方式從海量評論語料中學習詞語的向量表示,不需要人工標注和復雜的特征工程[10],因而很多學者將Word2vec詞表征方法引入關鍵詞抽取研究中。如Poria S等結合詞嵌入和卷積神經網絡模型,提出基于深度學習方面的提取方法,改善了關鍵詞的抽取性能[11]。寧建飛等將詞向量模型引入Textrank算法中,依據詞匯相似度和鄰接關系構建概率矩陣,實現詞圖迭代的關鍵詞抽取方法[12]。文秀賢等在商品特征提取任務中,利用Word2vec模型對評論關鍵詞向量化,采用K-means聚類算法確定商品維度,提升了用戶偏好挖掘的準確性[13]。綜上可知,與傳統的關鍵詞抽取方法相比,Word2vec模型能夠表達豐富的語境信息,更適合于關鍵詞抽取。
1.2 在線評論與競爭情報挖掘研究
互聯網技術的發展帶來口碑傳播方式的變化。在線評論作為新型口碑傳播方式,是企業獲取消費者意見反饋的重要信息來源和途徑,對企業開展競爭情報工作具有重要意義。如何從在線評論中挖掘潛在的規律是競爭情報領域的重點關注問題。
目前,國內外學者已對競爭企業的在線評論挖掘進行了大量研究。國外學者研究主要集中在商業情報價值分析方面。Zhang W等以客戶評論反饋意見為數據集,利用情感分析系統挖掘產品評價語句的情感極性,從而識別出影響用戶滿意度的因素[14]。He W等通過收集競爭對手的評論數據,提出基于情感基準的社交媒體競爭分析框架,以增強企業營銷情報并進一步改善客戶體驗[15]。Xu K等利用亞馬遜評論數據,提出圖模型方法從用戶評論中挖掘產品比較關系并可視化,以幫助企業進行風險管理和提供決策支持[16]。Xu X等將文本挖掘方法和LSA模型應用于酒店用戶評論中,從消費者滿意度的角度挖掘用戶對產品的評價,從而改進企業的市場定位和營銷策略[17]。He W等以社交網站的比薩連鎖店為研究案例,利用文本挖掘和價值分析方法,深入挖掘不同連鎖店的用戶偏好,有效地評估了不同企業的競爭環境[18]。
國內學者更注重探索情感分析和機器學習技術在產品競爭情報領域的應用。翟東升等爬取手機評論數據,通過構建情感詞典的方法挖掘企業競爭情報,分析競爭產品的優勢及需要改進的方向[19]。張洋等提出基于多源用戶評論數據的競爭情報模型,從內容分析、情感分析和共現分析角度挖掘用戶評論數據,從而幫助企業確定產品競爭領域[20]。肖璐等利用信息抽取技術和情感分析技術對本企業產品特征進行優劣勢分析,并根據產品相似度算法識別出企業競爭對手[21]。聶卉等利用機器學習方法對餐飲業的在線評論數據進行挖掘,實現了企業細粒度的競爭情報獲取[22]。王樹義等提出將情感分類和LDA主題模型結合的方法,對企業新聞評論進行分析,識別出不同企業新聞的關注重點,提高了主題抽取的效率[23]。陳元等以競爭情報工作流程為出發點,利用SVM和SO-LSA算法對用戶評論數據進行情感分析,進而獲取企業產品情報[24]。
通過文獻梳理可以發現,國內外關于競爭情報的研究傾向于和情感分析相結合,但現有研究存在情感分析粒度不夠細致、產品特征提取方法較為簡單等問題。而企業產品特征的情報挖掘更適合細粒度情感分析[25]。因此,本文以細粒度情感分析為出發點,提出基于在線產品評論的企業競爭情報分析框架,以汽車品牌的評論數據為數據源,結合詞向量技術和自然語言處理技術,挖掘競爭企業產品情報,為企業品牌營銷和戰略定位提供參考。
2 基于在線產品評論的競爭情報挖掘框架
為了準確、高效地獲取企業情報信息,本研究基于Word2vec構建了一個在線產品評論競爭情報挖掘框架,具體任務包括:①通過爬蟲技術抓取競爭企業的在線評論文本并進行預處理,形成實驗數據集;②對處理后的文本抽取產品關鍵詞,借助Word2vec學習特征詞在專業領域的向量表達,得到產品特征指標詞集合;③利用深度學習情感分類模型獲取情感標簽,根據特征維度匯聚產品評論情感;④根據競爭企業評論挖掘結果進行可視化分析。
2.1 在線產品評論數據獲取與處理
本文以專業社交媒體測評網站為數據來源。為了全面獲取用戶評論數據,實驗通過Python制定相應規則抓取汽車評論文本。抓取的記錄包括評論內容、用戶名、評論時間、產品類型等字段,將采集到的數據存放于Excel文件中保存,提取評論內容字段信息,作為評論語料。為確保數據分析的質量,需要清理噪音數據,去除與評論主題無關的廣告信息和重復評論記錄。分詞是自然語言處理的基礎工作,由于Jieba分詞簡單易用,對中文文本處理效果較好,所以本研究使用該工具對實驗數據集進行分詞和詞性標注。為提高分詞準確性,根據初始分詞結果和領域詞典構建自定義詞典,并加載停用詞表,去除與產品特征和情感表達無關的詞語,為后續的分析做準備。
2.2 基于詞向量的特征提取
Word2vec是由Mikolov T等提出的一種詞語語義計算工具[26],通過神經網絡算法訓練模型,然后將詞語轉化為詞向量,映射到高維空間中進行向量運算,從而預測與其語義相關的詞語。Word2vec包含兩種模型:CBOW模型和Skip-gram模型。CBOW模型是通過周圍詞預測當前詞語概率;而Skip-gram模型則依據當前詞預測周圍詞語的概率。由于Skip-gram模型對低頻詞匯處理具有優勢[27],因此本文采用Skip-gram模型進行訓練,模型主要由輸入層、投影層、輸出層組成,其結構如圖2所示。
Skip-gram模型主要通過隨機梯度下降算法訓練目標函數,模型目標是根據當前詞語預測上下文的信息。模型訓練完成后,可以獲得詞語的向量表示,詞語之間的相似度通過余弦距離來衡量。語義相似度的計算公式為:
Semantic_similarity=cosθ=u·vu·v(1)
其中,u和v分別表示兩個詞匯的詞向量,語義相似度的取值為[0,1]。
產品特征抽取是用戶評論挖掘的基礎,同時在企業競爭情報挖掘環節起著關鍵作用,故本文采用Word2vec詞向量聚類的方法構建產品特征詞集,產品特征詞集構建步驟如下:
1)初始特征詞匯選取。對經過預處理后評論文本中的名詞和動詞詞頻進行統計,選取高頻詞語作為種子詞語,然后將詞義相同的特征詞進行歸類,形成初始產品特征指標詞集。
2)詞向量訓練。利用Gensim庫的Word2vec工具對分詞后的評論語料進行訓練,可以得到詞向量模型以及相應維度的詞語向量表示。上下文窗口距離和向量空間維度是模型訓練的重要參數,窗口越大,涉及的語境信息越多,向量表征效果越好。本文將上下文窗口距離設為5,詞語向量維度500。
3)產品特征詞集構建。為了全面獲取產品特征,使用Word2vec模型計算評論集中詞語與初始指標詞語的夾角余弦值,選取相似度較高的若干詞語作為候選特征詞,完成產品特征詞庫的擴充。
2.3 評論情感分類
使用基于深度學習的情感自動分類模型,對汽車評論文本進行情感分類。獲取評論數據集的評價短語,這些短語經過模型處理后,每一個評價短語會被標記為帶有正負極性的情感標簽。
本文借助百度AI開放平臺提供的深度語義情感分析模型對評論文本進行細粒度情感分析。首先運用Python語言獲取Access Token,然后調用AIPNLP模塊,對輸入的文本進行循環處理,最終輸出評論情感標簽及評論情感極性。Senta情感分析系統是基于大規模評論語料進行訓練,能夠對輸入文本進行語義理解,并基于語義表示進行情感傾向判斷,情感分類準確度較高。
2.4 情感值量化與可視化分析
針對抽取的特征-評價短語,按產品屬性匯聚評價情感詞,統計用戶對同一屬性的情感傾向,實現用戶情感的量化分析。通過特征-評價短語的匯聚,得到不同品牌用戶關注特征的正面評論和負面評論比例分布,有助于企業從用戶角度獲取有價值的信息,從而識別品牌特征優劣,更好地改進產品設計以滿足用戶需求。
3 實驗過程及結果分析
3.1 實驗數據來源
太平洋汽車網是國內專業的汽車測評網站,網站具有覆蓋范圍廣、專業性強、商業化程度低等特點,網站的評論內容能夠真實反映用戶見解和情感信息。本文以太平洋汽車網為研究對象,利用數據挖掘方法,實現競爭情報信息的獲取。根據品牌知名度和產品綜合排名,選取桑塔納和卡羅拉兩個品牌作為研究樣本,利用Python編程抓取研究數據,截止時間為2020年5月25日,共采集9 139條評論語料,經數據清洗后得到實驗數據集。借助Jieba函數對實驗文本進行分詞處理,同時加入自定義詞表和停用詞表,得到最終分詞結果。
3.2 產品特征指標提取和分類
針對汽車評論數據集,根據句法規則對其進行標注,按照標注結果選取評論中的動詞和名詞作為備選產品特征指標詞,選取詞頻統計排名前100的詞為產品特征指標詞。由于存在非領域特征詞,需要人工對其進行篩選,將篩選后的詞語進行分類,對同義詞進行合并,作為產品特征種子詞;將分詞后的評論文本作為Word2vec的輸入語料,借助Gensim庫的Word2vec函數訓練生成詞向量文件,利用相似度函數,計算種子詞語的相似特征詞。產品指標詞的詞向量結果如表1所示。以指標詞“造型”為例,相似度排名前30的詞語如表2所示。按照上述方法,擴充種子詞匯,形成最終產品特征詞集,如表3所示。
3.3 競爭情報挖掘結果分析
本研究共獲得80 285條特征-情感詞對,通過用戶評論挖掘,將產品主題特征劃分為9個維度。根據產品特征詞分類結果,計算用戶對產品特征的關注程度;將產品特征和用戶評論情感匯聚,計算不同主題特征的用戶情感,實現用戶評論細粒度情感分析。
3.3.1 產品關注特征對比分析
圖3顯示了用戶對兩個品牌產品特征的關注情況分布。可以看出,用戶對桑塔納和卡羅拉的產品關注特征基本一致,主要體現在空間、舒適性、外觀、性價比、動力方面。不同的是,在空間和性價比特征上,用戶對卡羅拉的關注程度明顯高于桑塔納;而在動力和系統方面,用戶對桑塔納的關注程度較高。說明對于某一產品特征,用戶對不同品牌的關注程度有所不同。總體而言,企業應準確把握和評估用戶產品關注特征,確定企業品牌的重點發展方面,找到產品創新點,以吸引更多的用戶。
3.3.2 品牌情感特征對比分析
根據情感分類結果,計算用戶情感極性,繪制品牌情感特征柱形圖。根據圖4可知,該品牌汽車在外觀、空間、操控等方面好評率占比較高,用戶認可度較大,因此這些特征可以作為該品牌營銷的優勢和亮點,從而使產品更加具有競爭力。但是在動力特征上,品牌負面評價占比較大。大部分用戶對產品動力表現不滿意,動力性差是消費者對產品使用的整體感受,是產品營銷的劣勢,不利于產品的競爭,設計人員應重點對動力特征進行改進。而內飾和舒適性屬性用戶滿意度一般,沒有明顯態度傾向,說明這兩個屬性是企業繼續努力提升的兩個產品特征。
圖5為卡羅拉用戶評論情感量化結果。可以看出,該品牌產品“空間”屬性的用戶正面評價比例最高,大多數關于空間的評價是空間寬敞、儲物空間豐富、容量足等,說明用戶對該品牌的空間特征很滿意。但產品舒適性方面評分較低,主要體現在隔音效果不好、胎噪聲大、乘坐不舒適等,研究人員應予以重視。而系統配置的好評率最低,說明用戶對產品配置最為不滿,配置不足是該品牌的痛點所在,企業應盡快對痛點問題進行改進。
綜上可以看出,桑塔納在外觀、操控、油耗方面優勢較為突出,用戶整體評價表現為高認可度,但用戶對系統配置較為不滿;卡羅拉在外觀和操控上用戶滿意度也較高,而油耗特征的表現不如桑塔納突出,但內飾和系統配置方面比桑塔納更具有吸引力。根據以上分析可知,兩個品牌在外觀和操控方面整體好評率較高,表明獲得了用戶普遍認可,而系統配置特征都顯示出低滿意度,說明企業應注重產品機械部件等硬件方面性能的提升。不同企業品牌在產品特征方面各有優劣,企業應針對自身的優劣對產品進行改進,在了解競爭對手的產品特征情況下,保持自己的優勢特征,改進劣勢特征,對企業的長久發展具有重要作用。
3.3.3 品牌服務特征對比分析
根據關鍵詞抽取結果,將產品評論服務特征分為3類,分別為售后維修、故障情況和服務態度。根據服務特征詞分類表,利用Excel對用戶評論數量進行統計,計算產品服務特征的用戶關注度,產品服務特征的評論占比統計結果如圖6所示。
從圖6可以看出,桑塔納售后維修的評論占比最高,服務態度和故障情況的評論占比相對較低,僅占據服務特征總體評論的1/4;對卡羅拉而言,用戶對故障情況的討論明顯高于服務態度和售后維修,并且用戶對服務態度的討論最少。綜上可知,在服務特征評論中,售后維修和故障情況是兩個品牌的關注重點,企業應加強對產品服務質量的改進。
3.3.4 細粒度評價對比分析
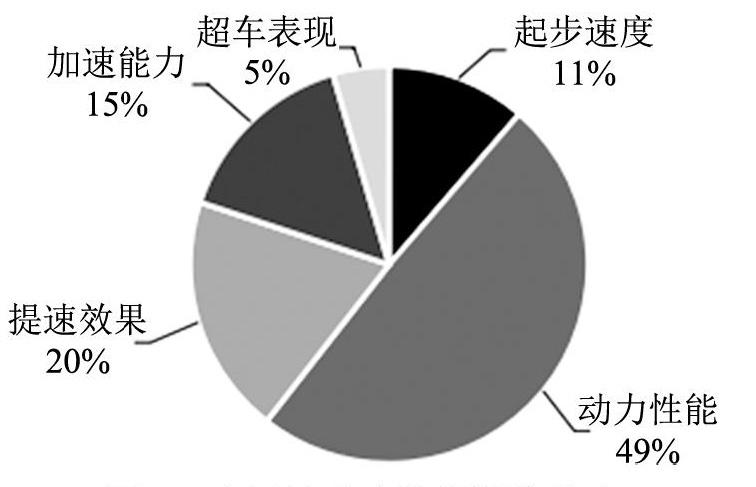
圖7顯示了用戶關于動力屬性的細粒度評價統計分布。由圖7可知,動力屬性評價主要包括超車、起步、加速、提速和動力性等方面。從評論中可以看出,正面評價主要表現為提速效果好、起步輕松、加速能力出眾、動力表現優秀、超車迅速。而負面評價表現為超車困難、加速能力弱、提速表現不好、起步速度慢、動力性差。由此可知,用戶關于動力特征的關注方面較為集中,動力能力的提升對企業來說至關重要,有利于企業口碑的改善,塑造良好企業形象,從而提高消費者的滿意度。
4 結束語
網絡評論日益豐富,大數據環境下的競爭情報挖掘具有重要理論意義和應用價值。本文以社交媒體評論數據為研究對象,提出一種面向在線產品評論的競爭情報挖掘框架,該框架綜合運用自然語言處理技術和深度學習技術,從用戶關注度和滿意度兩方面對產品評論數據進行分析,通過Word2vec構建產品特征詞庫,實現產品特征詞聚類;并在此基礎上分析用戶情感傾向,據此實現細粒度情感分析。為驗證模型可行性,以桑塔納和卡羅拉兩個競爭品牌作為研究案例進行實驗分析。依據實驗結果,本文提出的模型和方法是有效的,運用這種方法可以將用戶生成內容轉化為有價值的情報,幫助企業系統分析自身品牌及競爭對手的優勢和劣勢,從而為產品改進和戰略規劃提供決策依據。本研究也存在一些不足:本文僅利用產品評論內容數據進行分析,沒有考慮到時間因素和其他形式數據;研究框架有待完善,情感分類算法還需進一步優化,未來研究將考慮利用多平臺數據進行深入分析。
參考文獻
[1]中國互聯網絡信息中心.第45次中國互聯網絡發展狀況統計報告[EB/OL].http://www.cnnic.net.cn/hlwfzyj/hlwxzbg/hlwtjbg/202004/P020200428596599037028.pdf,2020-05-25.
[2]Hu N,Liu L,Zhang J J.Do Online Reviews Affect Product Sales?The Role of Reviewer Characteristics and Temporal Effects[J].Information Technology & Management,2008,9(3):201-214.
[3]王仁武,宋家怡,陳川寶.基于Word2vec的情感分析在品牌認知中的應用研究[J].圖書情報工作,2017,61(22):6-12.
[4]周珍妮,黃曉斌.網絡用戶評論在企業競爭情報研究中的應用[J].情報理論與實踐,2012,35(5):15-20.
[5]Hu M,Liu B.Mining and Summarizing Customer Reviews[C]//Tenth Acm Sigkdd International Conference on Knowledge Discovery & Data Mining.ACM,2004.
[6]Quan C,Ren F.Unsupervised Product Feature Extraction for Feature-oriented Opinion Determination[J].Information Ences,2014,272:16-28.
[7 ]王娟,曹樹金,謝建國.基于短語句法結構和依存句法分析的情感評價單元抽取[J].情報理論與實踐,2017,40(3):107-113.
[8]彭云,萬常選,江騰蛟,等.基于語義約束LDA的商品特征和情感詞提取[J].軟件學報,2017,28(3):676-693.
[9]王榮洋,鞠久朋,李壽山,等.基于CRFs的評價對象抽取特征研究[J].中文信息學報,2012,26(2):56-61.
[10]李楓林,柯佳.詞向量語義表示研究進展[J].情報科學,2019,37(5):155-165.
[11]Poria S,Cambria E,Gelbukh A,et al.Aspect Extraction for Opinion Mining with a Deep Convolutional Neural Network[J].Knowledge Based Systems,2016:42-49.
[12]寧建飛,劉降珍.融合Word2vec與TextRank的關鍵詞抽取研究[J].現代圖書情報技術,2016,(6):20-27.
[13]文秀賢,徐健.基于用戶評論的商品特征提取及特征價格研究[J].數據分析與知識發現,2019,3(7):42-51.
[14]Zhang W,Xu H,Wan W.Weakness Finder:Find Product Weakness from Chinese Reviews By Using Aspects Based Sentiment Analysis[J].Expert Systems with Applications,2012,39(11):10283-10291.
[15]He W,Wu H,Yan G,et al.A Novel Social Media Competitive Analytics Framework with Sentiment Benchmarks[J].Information & Management,2015,52(7):801-812.
[16]Xu K,Liao S S,Li J,et al.Mining Comparative Opinions from Customer Reviews for Competitive Intelligence[J].Decision Support Systems,2011,50(4):743-754.
[17]Xu X,Wang X,Li Y,et al.Business Intelligence in Online Customer Textual Reviews:Understanding Consumer Perceptions and Influential Factors[J].International Journal of Information Management,2017,37(6):673-683.
[18]He W,Zha S,Li L.Social Media Competitive Analysis and Text Mining:A Case Study in the Pizza Industry[J].International Journal of Information Management,2013,33(3):464-472.
[19]翟東升,徐穎,黃魯成.基于產品評論挖掘的競爭產品優勢分析[J].情報雜志,2013,32(2):45-51.
[20]張洋,凌婉陽.基于多源社會化媒體評論的競爭情報挖掘研究[J].情報理論與實踐,2015,38(7):59-66.
[21]肖璐,陳果,劉繼云.基于情感分析的企業產品級競爭對手識別研究——以用戶評論為數據源[J].圖書情報工作,2016,60(1):83-90.
[22]聶卉,李通,何歡,等.基于在線評論的商業競爭情報自動獲取[J].情報雜志,2018,37(10):167-173.
[23]王樹義,廖樺濤,吳查科.基于情感分類的競爭企業新聞文本主題挖掘[J].數據分析與知識發現,2018,2(3):70-78.
[24]陳元,趙靜.基于WEB用戶產品評論的企業競爭情報挖掘實證研究[J].情報科學,2016,34(4):80-85.
[25]唐曉波,劉廣超.細粒度情感分析研究綜述[J].圖書情報工作,2017,61(5):132-140.
[26]Mikolov T,Sutskever I,Chen K,et al.Distributed Representations of Words and Phrases and Their Compositionality[C]//Advances in Neural Information Processing Systems,2013:3111-3119.
[27]王仁武,陳川寶,孟現茹.基于詞向量擴展的學術資源語義檢索技術[J].圖書情報工作,2018,62(19):111-119.
(責任編輯:郭沫含)
猜你喜歡
當代水產(2022年8期)2022-09-20 06:44:30
當代水產(2022年6期)2022-06-29 01:11:44
當代水產(2022年5期)2022-06-05 07:55:06
當代水產(2022年3期)2022-04-26 14:27:04
當代水產(2022年2期)2022-04-26 14:25:10
大眾投資指南(2021年35期)2021-02-16 01:06:26
云南畫報(2020年9期)2020-10-27 02:03:26
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
