基于無人機航拍與改進YOLOv3模型的云杉計數
2021-01-19 04:59:46陳鋒軍朱學巖周文靜顧夢夢趙燕東
農業工程學報 2020年22期
陳鋒軍,朱學巖,周文靜,顧夢夢,趙燕東
(1.北京林業大學工學院,北京 100083;2.城鄉生態環境北京實驗室,北京 100083;3.德州農工大學園藝系,大學城 77843;4.林業裝備與自動化國家林業局重點實驗室,北京 100083)
0 引 言
苗木庫存是苗木相關企業優化管理、預測收益、防控病蟲害和核算經營成本等方面的重要參考數據[1]。傳統苗木庫存統計的方法是由人工計數,勞動力成本高、重復性強、效率低并且不能保證結果的準確率。自動、快速并且準確的統計苗木庫存數量已經成為迫切需要解決的問題,利用無人機航拍苗木圖像準確計數是一種理想的解決方法。目前苗木數量統計的方法除了人工計數方法之外,還包括傳統機器視覺方法以及深度學習相關的方法。
傳統機器視覺方法一般是提取顏色[2-5]、形狀[6-7]以及紋理[8-10]等淺層特征,通過閾值分割[11]、人工神經網絡[12]和支持向量機[13]等方法識別目標后計數。目前,基于傳統機器視覺的計數方法已被應用到小麥麥穗[14-15]、玉米[16]、柑橘樹[17]、棉花行數[18]以及棕櫚樹[19]的計數中。She等[20]將無人機航拍多年生花生圖像按 2G-R-B特征分割后通過計算花生冠層投影面積實現計數,精度為 95%。Dilel等[21]采用閾值分割、邊緣檢測和Hough圓檢測的方法統計柑橘樹數量,計數結果準確率 80%以上。傳統機器視覺方法一般都利用無人機獲取圖像,但是苗木特征選擇顏色、形狀和紋理時易受光照條件變化影響苗木識別結果,閾值分割、人工神經網絡和支持向量機等模式識別方法也沒有很好的解決苗木陰影和粘連分割的干擾,無法勝任自然條件下推廣應用的實際需求。
深度學習相關方法通過設計深層卷積神經網絡自動提取圖像的淺層和深層特征,克服了傳統機器視覺方法表征能力不足的問題。目前深度學習的方法已被應用到小麥麥穗[22]、蘋果[23]、受蟲害的油松[24]等的計數中。Michael等[25]利用R-CNN模型實現阿爾伯塔北部森林針葉樹幼苗的計數,準確率達到 81%;李越帥等[26]提出一種基于 U-Net模型的胡楊樹冠計數方法,準確率達到94.1%;Li等[27]提出一種基于CNN的遙感圖像棕櫚樹計數方法,準確率達到 96%。卷積神經網絡在苗木識別和計數研究中優勢顯著,其中YOLOv3模型能對尺寸差異較大的目標快速準確識別和計數,被應用于蘋果[28]、柑橘[29-30]、荔枝串[31]、草莓[32]、芒果[33]和番茄[34]等農林業作物的識別。孫壯壯等[35]采用YOLOv3模型實現了小麥、大麥、水稻以及玉米葉片不同大小氣泡的快速識別和計數,準確率達到89%;熊俊濤等[36]提出Des-YOLOv3模型實現夜間復雜光照下的粘連成熟柑橘識別,準確率達到90.75%;Liu等[37]提出了YOLO-Tomato模型實現復雜環境下不同大小和不同粘連情況的番茄識別,準確率達到94.75%;趙德安等[38]使用YOLOv3模型檢測圖像中不同大小的蘋果準確率高達97%。
快速準確檢測尺寸差異大的云杉目標,YOLOv3模型優勢非常顯著,主要是因為利用了特征圖像金字塔模塊和多尺度預測模塊。實際使用中發現YOLOv3模型存在無法避免的問題:1)小樣本云杉數據在訓練中容易產生過擬合;2)特征提取中降采樣環節只能利用少量維度特征,導致云杉特征信息的丟失。如果直接使用YOLOv3模型計數無人機航拍圖像中的云杉,容易出現過擬合和遺漏計數問題,導致計數結果與實際數量差距較大。為此,本文在YOLOv3模型的特征提取網絡中添加密集連接模塊和過渡模塊形成Darknet-61-Dense特征提取網絡,構建改進YOLOv3模型,以期為實現苗木數量統計解決關鍵算法問題。
1 材料與方法
1.1 圖像獲取和擴充
試驗研究區域選取位于內蒙古和林格爾縣蒙樹苗木基地(111°49′47′E,40°31′47′N,海拔 1 134 m)。云杉人工種植區域面積大,主要依山地的地形和起伏種植,因為種植時間差異,不同地塊云杉個體大小不一。本文試驗選取種植地勢相對平坦地塊相對規整的區域進行拍攝,行間距為1.5 m,株距為1 m。2017年7月、2018年10月和2019年9月通過大疆精靈4無人機獲取云杉圖像。無人機相機鏡頭焦距20 mm,像元尺寸2.4um,有效像素 2 000萬,設置相機分辨率 4 000×3 000(像素),選取成像角度-90°,相機鏡頭與地面平行;飛行高度在12~36 m之間,S型飛行路線定點懸停,飛行速度2 m/s,6塊電池,每塊電池最大飛行時間約為25 min。
3 a共采集3 147幅云杉圖像,以24位真彩色JPEG格式存儲。利用Pix4Dnaper軟件對云杉圖像進行拼接,通過裁剪消除圖像邊緣異常值,獲得20幅完整地塊云杉圖像,其中拼接剪裁后完整地塊云杉圖像實際覆蓋面積約為675 m2(45 m×15 m)。按照株齡、光照條件和飛行高度盡量多樣的原則挑選558幅云杉圖像,另外增加20幅拼接后完整地塊云杉圖像,共計578幅構成試驗數據。采用旋轉、變換圖像大小和對比度的方法進一步擴充云杉圖像數據,以期增強模型對云杉個體尺寸差異和光照變化的魯棒性。旋轉角度、縮放比例系數和對比度系數分別在(0°, 90°]、[0.5, 1.5]和[0.2, 1.8]區間隨機生成,模擬云杉個體尺寸差異和不同光照條件下的成像。采用旋轉、變換圖像大小和對比度的方法擴充后,云杉圖像增至2 312幅,其中2 232幅為無人機航拍圖像,80幅為拼接剪裁后完整地塊云杉圖像。
1.2 數據集搭建
按照7∶3的比例將擴充后的云杉圖像2 232幅劃分為訓練集和測試集1,將80幅拼接剪裁后完整地塊的云杉圖像仍然按照7∶3的比例劃分為訓練集和測試集2。即云杉訓練集圖像共 1 618幅,包含擴充后的云杉圖像1 562幅加上拼接裁剪后完整地塊的56幅;測試集1包含擴充后的云杉圖像670幅;測試集2為拼接剪裁后完整地塊的24幅云杉圖像。
2 改進YOLOv3模型
2.1 改進YOLOv3模型建立
無人機獲取的云杉圖像為小樣本數據,圖像中云杉個體尺寸的差異很大,還有自然光照條件變化多樣,地面雜草等背景復雜以及云杉之間粘連的問題,導致準確統計云杉數量非常困難。為了有效解決過擬合問題以及云杉特征信息丟失的問題,在原有YOLOv3模型[39]特征提取網絡 Darknet-53中加入密集連接模塊和過渡模塊構成改進后的 Darknet-61-Dense特征提取網絡,建立改進YOLOv3模型統計云杉數量。
2.1.1 密集連接模塊
云杉訓練集一共有 1 618幅圖像,屬于小樣本訓練集,直接訓練YOLOv3模型容易出現過擬合問題。為解決該問題,參考 DenseNet網絡[40],在特征提取網絡Darknet-53中加入密集連接模塊,強化云杉特征的傳遞以及特征的復用,抑制過擬合問題的產生。密集連接模塊將云杉特征提取網絡中所有層兩兩相連,保證網絡每一層都包含前面所有層的云杉特征信息,具體如式(1)所示,網絡第l層的輸入是第1層到第(l-1)層所有特征圖的拼接。

式中Hl代表卷積、批量歸一化和Leaky-ReLU激活函數組成的復合函數,x1,x2,......,xl-1代表第1層到第l-1層的云杉特征圖。密集連接模塊的基本結構如圖1所示。
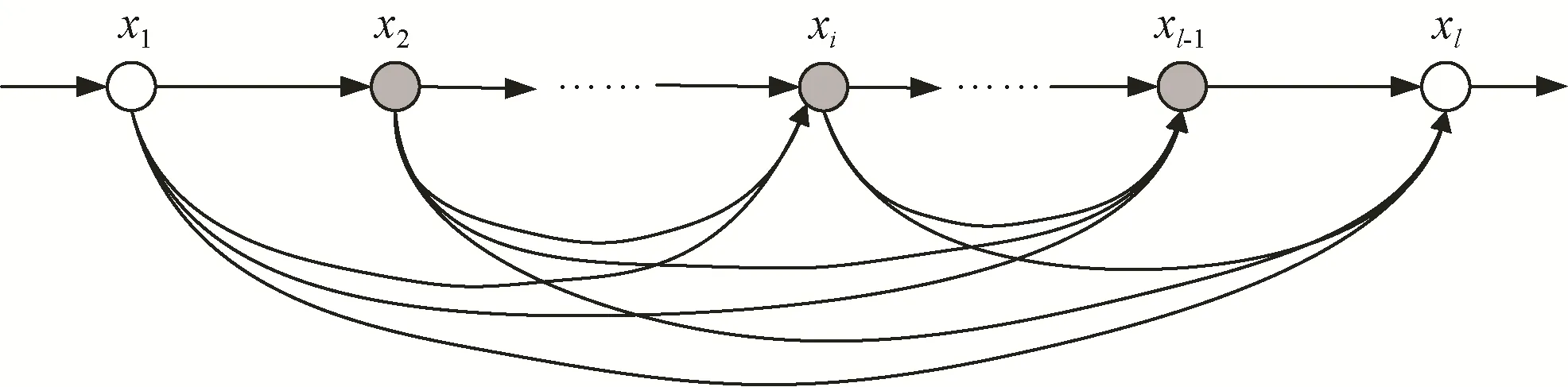
圖1 密集連接模塊Fig.1 Dense connection module
在密集連接模塊中,云杉特征的重復使用有效避免了特征提取模型對冗余云杉特征圖的重新學習,提高正則化水平,有效抑制因云杉數據集較小導致的過擬合問題。
2.1.2 過渡模塊
YOLOv3模型特征提取網絡 Darknet-53降采樣過程僅使用少量維度的信息,存在云杉特征信息丟失的問題,影響云杉檢測和計數的精度。參考Inception網絡[41],在云杉特征提取網絡 Darknet-53中加入過渡模塊。改進后的云杉特征提取網絡采用不同大小的濾波器和池化操作提取和融合云杉特征信息,得到尺寸減半的云杉特征圖,如圖2中輸入尺寸為104×104的云杉特征圖,經過渡模塊處理后尺寸減半為52×52。過渡模塊主要包含1×1卷積核、3×3的卷積核和最大池化,3×3的卷積核和最大池化的作用是降低云杉特征圖的維數,1×1的卷積核的作用是降低模型參數的復雜程度從而減少計算量。
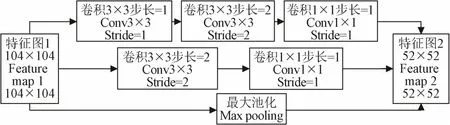
圖2 過渡模塊Fig.2 Transition module
2.1.3 建立改進YOLOv3模型
在YOLOv3模型的特征提取網絡Darknet-53中加入密集連接模塊和過渡模塊,構成改進后的 Darknet-61-Dense特征提取網絡,有效抑制YOLOv3模型存在的過擬合和云杉特征信息丟失的問題,改進YOLOv3模型的結構如圖3所示。
圖3中FS表示特征拼接,功能塊Fun由殘差塊改進而來,具體操作是將殘差單元替換為密集連接單元并引入過渡模塊,其結構如圖4a。在功能塊Fun中,密集連接單元數量用n表示。密集連接單元結構如圖4b。
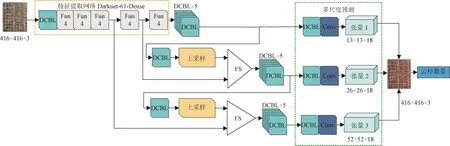
圖3 改進YOLOv3模型Fig.3 Improved YOLOv3 model

圖4 改進YOLOv3模型各功能模塊Fig.4 Function block of improved YOLOv3 model
改進 YOLOv3模型中特征提取網絡 Darknet-61-Dense的網絡參數如表1所示。
2.2 訓練改進YOLOv3模型
利用LabelImg軟件人工標注云杉訓練集圖像,標注規則為:1)不標注圖像邊界不完整的云杉;2)分別標注相互粘連的云杉。對每一幅人工標注的云杉圖像,LabelImg軟件自動生成對應的xml文件,包含云杉標注矩形框的左上角坐標和右下角坐標,標注矩形框的長和寬以及標注的類別名稱信息。為加快模型處理速度,提高對不同尺寸云杉的預測能力,歸一化處理云杉標注矩形框,具體如式(2)所示。

表1 Darknet-61-Dense網絡參數Table 1 Darknet-61-Dense network parameters
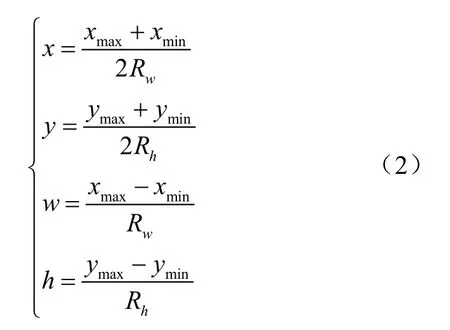
式中x、y、w和h分別為歸一化后云杉標注矩形框中心點坐標以及歸一化后云杉標注矩形框的寬度和高度。xmin、ymin、xmax和ymax分別為人工標注的云杉標注矩形框左上角和右下角的坐標。Rw和Rh分別為云杉圖像的寬度和高度,pixel。
訓練和測試的硬件平臺配置為:Intel(R) Core i7-8700K CPU @ 3.70 GHz處理器,16 GB內存,11 GB GeForce GTX 1080 Ti顯卡,500 G固態硬盤和 4TB機械硬盤。在Ubuntu16.04系統和Tensorflow框架下使用Python編程實現,程序運行中調用CUDA、Cudnn和OpenCV第三方庫。根據經驗設置訓練權值衰減和初始學習率分別為0.000 5和0.001;為縮短模型訓練時間,采用批處理量為64的批處理訓練方式;權值更新過程,采用正則化處理并根據經驗在每一層中加入丟棄比為0.5的丟棄層(Dropout),動量設置為0.9;繪制錨點框數量和平均交并比之間的關系曲線,根據試驗測試結果選定錨點框數量為9,平均交并比為84.55%。
2.3 評價改進YOLOv3模型
本研究改進YOLOv3模型云杉計數過程需同時考慮檢測精度、計數精度以及速度,故選用精確率P、召回率R、平均精度AP、平均計數準確率MCA和平均檢測時間ADT作為評價指標[42-44]。計算公式為


式中TP表示模型預測為正樣本且實際也是正樣本的情況,FP表示模型預測為正樣本但實際是負樣本的情況,FN表示模型預測為負樣本但實際為正樣本的情況。N為云杉圖像的數量,i表示第i幅云杉圖像,Gi為第i幅圖像中云杉的真實數量,由人工計數得到。Ei為改進YOLOv3模型對第i幅圖像中云杉的計數結果,tN為改進YOLOv3模型檢測N幅圖像的總耗時,s。
3 結果與分析
3.1 試驗結果
為驗證改進YOLOv3模型的性能,首先對測試集1中的670幅云杉圖像進行測試。改進YOLOv3模型利用最優云杉預測邊界框標識檢測到的云杉,統計最優云杉預測邊界框的數量即為云杉計數結果。具體示例如圖5所示。

圖5 人工計數和改進YOLOv3模型計數結果Fig.5 Manual counting and improved YOLOv3 model counting results
接來下對測試集2中的 24幅拼接裁剪后完整地塊的圖像進行測試。直接將大小為5 000×1 000(像素)包含千余株云杉目標的圖像壓縮為 416×416(像素)的圖像輸入改進YOLOv3模型不能準確計數。對測試集2拼接剪裁后完整地塊的 24幅云杉圖像進行測試,首先將拼接裁剪后的云杉地塊圖像按照均等原則裁剪成為1 250×1 000(像素)的4幅子圖像;然后將這4幅子圖像分別輸入改進YOLOv3模型進行計數;最后將4幅子圖像計數結果求和即視為整個地塊內云杉的數量,具體示例如圖6所示。

圖6 完整地塊云杉圖像計數Fig.6 Image count in complete plot spruce
3.2 對比分析
為進一步測試改進YOLOv3模型的性能,以精確率P、召回率R、平均精度AP、平均計數準確率MCA和平均檢測時間ADT為評價指標,給定閾值為0.3,將改進YOLOv3模型與YOLOv3模型、SSD模型和Faster R-CNN模型在測試集1和測試集2上分別進行比較。測試集1的對比試驗結果如表2所示。

表2 測試集1試驗結果對比Table 2 Comparison for experimental results of test set 1
改進YOLOv3模型在測試集1中的精確率P、召回率R、平均精度 AP和平均計數準確率 MCA分別為96.81%、93.53%、94.26%和98.49%,遠超YOLOv3模型、SSD模型和Faster R-CNN模型,平均檢測時間ADT僅為0.351 s。相比原有YOLOv3模型,精確率P、召回率R、平均精度 AP和平均計數準確率 MCA分別提升 2.44、1.68、3.53和 8.25個百分點,平均檢測時間 ADT增加0.043 s;相比SSD模型,精確率P、召回率R、平均精度AP和平均計數準確率MCA分別高出4.13、2.92、6.77和9.74個百分點,平均檢測時間ADT低0.544 s;相比Faster R-CNN模型,精確率P、召回率R、平均精度AP和平均計數準確率MCA分別高出0.84、1.04、1.41和1.23個百分點,平均檢測時間ADT低2.176 s。改進YOLOv3模型通過加入密集連接模塊和過渡模塊,有效解決了云杉特征提取時信息丟失問題和小樣本訓練導致過擬合的問題,準確統計云杉數量。
改進 YOLOv3模型與 YOLOv3模型、SSD模型和Faster R-CNN模型在測試集2的對比試驗結果具體如表3所示。
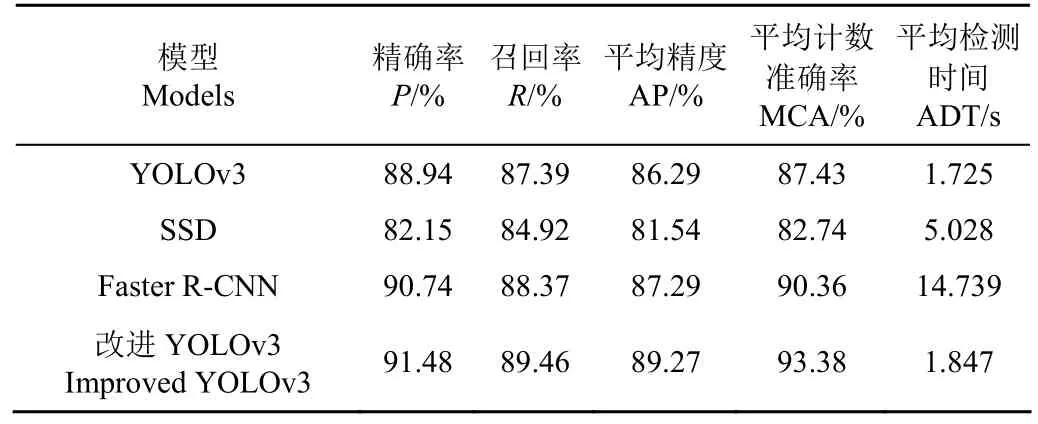
表3 測試集2試驗結果對比Table 3 Comparison for experimental results of test set 2
在測試集 2中,改進 YOLOv3模型對整個地塊內云杉計數的精確率P、召回率R、平均精度AP和平均計數準確率 MCA分別為 91.48%、89.46%、89.27%和93.38%,平均檢測時間 ADT為 1.847 s。相比原有YOLOv3模型,精確率P、召回率R、平均精度AP和平均計數準確率MCA分別提升2.54、2.07、2.98和5.95個百分點,平均檢測時間ADT增加0.122 s;相比SSD模型,精確率P、召回率R、平均精度AP和平均計數準確率 MCA分別高出9.33、4.54、7.73和10.64個百分點,平均檢測時間ADT低3.181 s;相比Faster R-CNN模型,精確率P、召回率R、平均精度AP和平均計數準確率MCA分別高出0.74、1.09、1.98和3.02個百分點,平均檢測時間ADT低12.892 s。改進后的YOLOv3模型同樣大幅度優化云杉計數結果,很大程度上解決云杉信息丟失和過擬合的問題。
同時不難發現改進YOLOv3模型在測試集1和測試集2上的計數結果差異較大。在精確率P、召回率R、平均精度AP和平均計數準確率MCA這4個評價指標上,在測試集2的表現分別比測試集1的表現降低5.33、4.07、4.99和5.11個百分點;在平均檢測時間ADT這一指標上,測試集2比測試集1高1.496 s。原因主要是完整地塊的云杉拼接圖像尺寸大,云杉目標稠密,不能壓縮后直接輸入模型,采用裁剪成 4幅子圖像分別輸入模型計數,過程中 3條裁剪線必然會對部分云杉進行切割,根據文中標注的規則:圖像邊界不完整的云杉不標注,最終導致模型沒有統計這部分被切割的云杉。解決包含稠密云杉目標的大尺寸圖像計數是下一步工作需要進一步解決的問題。
經過對比發現改進YOLOv3模型通過加入密集連接模塊和過渡模塊,有效避免了冗余特征圖重復學習導致的過擬合問題以及采樣過程信息丟失問題,很好的解決了光照條件變化、云杉之間陰影遮擋、稠密云杉目標檢測和云杉粘連分割的困難,快速準確的統計無人機拍攝圖像中的云杉數量。對于拼接后完整地塊云杉圖像,由于尺寸較大,云杉目標稠密,對于這樣的問題需要進一步深入的研究,尋找有效解決方案。
4 結 論
本文以無人機航拍的云杉圖像為研究對象,針對YOLOv3模型存在的小樣本數據集訓練過擬合問題和特征提取網絡降采樣過程信息丟失問題,在特征提取網絡 Darknet-53中加入密集連接模塊和過渡模塊設計新的特征提取網絡 Darknet-61-Dense,提出一種改進YOLOv3模型的云杉計數方法。測試改進YOLOv3模型并且與原有 YOLOv3模型進行對比分析,得到以下主要結論:
1)改進YOLOv3模型能夠對無人機航拍云杉圖像進行快速準確的計數,有效解決原有YOLOv3模型的過擬合和云杉特征信息丟失的問題。改進YOLOv3模型精確率P、召回率R和平均精度AP和平均計數準確率MCA分別為96.81%、93.53%、94.26%和98.49%,平均檢測時間ADT為0.351 s。在前4個指標上,相對原有YOLOv3模型性能提升2.44、1.68、3.53和8.25個百分點,平均檢測時間ADT增加0.043 s。很好的解決了光照變化、云杉之間陰影遮擋、稠密云杉檢測和云杉粘連的問題,準確快速的統計無人機航拍圖像中的云杉數量。
2)改進YOLOv3模型相比原有YOLOv3模型大幅提升完整地塊云杉圖像的計數精度。在精確率P、召回率R、平均精度AP和平均計數準確率MCA這4個評價指標上,改進YOLOv3模型相比原有YOLOv3模型性能提升2.54、2.07、2.98和5.95個百分點,平均檢測時間ADT增加0.122 s,為真正解決生產單位苗木數量統計的實際問題做出了有益的探索。
3)拼接剪裁后完整地塊云杉圖像計數方法的改進和完善是下一步工作的重點研究方向。由于拼接剪裁后完整地塊圖像尺寸大,云杉目標稠密,不能直接輸入改進YOLOv3模型。采用裁剪成 4幅子圖像分別統計云杉數量再匯總的方法,導致最后的計數結果因為沒有統計剪切線被剪切的云杉而出現漏數問題,影響計數精度。后續研究中解決包含稠密云杉目標的大尺寸圖像計數成為亟待解決的問題。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
艦船科學技術(2022年15期)2022-09-14 09:21:50
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
電子制作(2019年15期)2019-08-27 01:12:00
電子制作(2018年19期)2018-11-14 02:37:08
自動化學報(2017年11期)2017-04-04 02:52:58
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
