結合XGBoost和條件隨機場的城市場景機載LiDAR分類
2021-01-20 10:41:38劉翼王譜佐胡翔云修林冉
遙感信息 2020年6期
劉翼,王譜佐,胡翔云,修林冉
(1.中國石油西氣東輸管道公司 科技信息中心,武漢 430000;2.武漢大學 遙感信息工程學院,武漢 430079;3.中國石油西氣東輸管道公司 管道處,上海 200000)
0 引言
隨著城市化的快速發展,如何在城市規劃中有效管理資源成為決策者的難題,而掌握精確的土地覆蓋數據能極大地幫助管理城市。由于機載激光雷達數據能夠快速提供高精度三維信息,己成為一種重要的遙感數據源,在城市遙感、森林遙感、石油管理信息化等領域發揮著重要作用[1]。目前,將三維點云用于城市遙感信息提取任務己經成為熱門研究。機器學習方法可利用提取出的數據特征組合[2],通過數學模型自動學習分類判別規則并有效分類城市復雜場景的不同地物。提取三維點云數據中的特征信息是區分不同地物的關鍵。Chehata等[3]總結了21種機載點云數據常見特征;Weinmann等[4]設計了一系列結合2D和3D的點云特征;Blomley等[5]使用了從不同鄰域類型和多個尺度中提取的互補型幾何特征。在機器學習模型的使用上,不同學者結合了不同的分類器方法[6-11]包括決策樹、支持向量機(support vector machine,SVM)、隨機森林等。極限梯度算法(eXtreme gradient boosting,XGBoost)分類模型[12]因為其優異的性能在數據挖掘中使用廣泛。然而,這些分類器通常獨立地使用局部特征標記每個點,通常會導致噪聲結果。為此,一些學者提出了幾種基于上下文特征的分類方法,這些方法可以考慮其相鄰點之間的語義標簽分布來改善分類結果[13-14]。本文提出了一種機載激光點云的自動分類方法,通過XGBoost訓練從點云數據中抽取的特征信息,并結合全連接條件隨機場優化初始分類模型,得到城市地區點云的精細分類結果。
1 激光點云分類
本文方法首先從機載激光點云中提取分類判別特征,考慮高度、形狀和物理屬性3個方面;然后采用XGBoost分類模型對激光點云數據進行分類,并使用網格搜索方法確定較優的模型超參數;最后利用全連接條件隨機場語義標簽平滑方法,加入點云顏色特征信息作為約束并結合初始分類標簽信息,在后處理步驟中提高點云分類精度。實驗數據選取了國際攝影測量和遙感學會(international society for photogrammetry and remote sensing,ISPRS)三維語義標注競賽公開數據集[15]。
1.1 特征信息提取
從高度、形狀特征、物理屬性3個方面挖掘數據的特征信息,并針對不同的特征信息設計了不同的鄰域大小選擇方法。
1)高度特征。提取原始點云數據的歸一化數字表面模型(normalized digital surface model,nDSM)作為一維高度特征,地表濾波過程使用了Zhang等[16]提出的布料模擬Lidar數據濾波算法。nDSM可以排除地形起伏的影響,獲取地物真實的離地高度,其表達如式(1)所示。
nDSM=DSM-DEM
(1)
此外,使用一組計算單點與位于其所在鄰域內其他點的高度關系而產生的高度特征。①單點與所在鄰域內最低點的高程差Z-Zmin。②單點局部鄰域內所有點的高程值標準差σ2。③單點與所在鄰域內最高點的高程差Zmax-Z。④單點所在鄰域內最高點與最低點的高程差Zmax-Zmin。

3)物理特征。點云數據的物理特性與點云自身所表示的地物特性有關。直接使用點云數據內包含的強度數據,并針對少數點強度值遠大于其他點的現象,通過直方圖均衡方法,減少異常數據的影響。另一方面,通過激光點云數據與對應區域的遙感影像數據相結合,計算單點在影像中的對應像素,通過影像提供的光譜信息輔助點云進行信息提取。
4)鄰域選擇。不同的鄰域類型由提取特征的需求所決定。在抽取高度特征時,需要考慮一點在高程值Z上的空間分布,因此圓柱體形的鄰域類型適應于高度特征的提取,并考慮了3種不同的鄰域大小(2.0 m、4.0 m、6.0 m),對高度特征進行了多尺度提取。而在計算點云表面特征時,需要關注該點與在一定距離內點云的空間關系并獲取幾何形態,本文選擇聚集于單點的球面鄰域(2.0 m)。
1.2 XGBoost分類
XGBoost屬于提升式系列的分類器,在梯度提升樹(gradient boosting decision tree,GBDT)的基礎上做了一些改進,得到了一個更高效準確的機器學習模型,因此在數據挖掘應用中得到廣泛使用。其主要特點有:在模型中加入了正則項,用于控制模型的復雜度;對代價損失函數進行了二階泰勒展開,同時用到了一階和二階導數;收縮和列取樣,可增大迭代生成的樹模型的影響,并在一定程度上防止過擬合;在樹模型分割點的特征值上實行并行,大幅度提高運行效率;對決策樹最佳分裂點的改進。
本文在使用XGBoost分類器的過程中,為了使模型更適應于點云數據的分類工作,采用了超參數設計方法對模型參數進行調優,另外使用了網格搜索的功能,逐步搜索確定最佳參數值。
1.3 全連接條件隨機場優化
針對機器學習方法在特征空間中單獨標記每個點的標簽而造成的分類結果不連續性的問題,使用全連接條件隨機場融入了點云之間的語義信息[17]。應用在點云模型中,每2個點間的邊是由高斯核在任意特征空間的線性組合定義的,而算法基于條件隨機場分布的平均場近似,通過聚合來自所有其他變量的信息進行迭代優化。
(2)
式中:i和j表示從1到N的每個點;?u(xi)是一元項能量函數,用于約束優化結果與初始結果的差異,定義為?u(xi)=-log(p(xi));?p(xi,xj)是二元項能量函數,用于提取點云的鄰域信息,如式(3)所示。
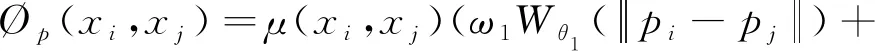
(3)
式中:Wθ1表示為標準差為θ1的高斯函數。核函數中的參數采用訓練的方式,通過L-BFGS方法優化得到。一個簡單的標簽兼容性函數μ由Potts模型給出:
μ(xi,xj)=[xi≠xj]
(4)
具體實施參考了Wang等[18]對點云分類優化的處理,利用XGBoost得到的初始分類概率作為?u,用于保證優化結果位于初始分類概率的一定區間內;將?p設置為點云與影像匹配生成的顏色信息與強度信息,考慮到顏色與強度特征在同一類別中一般是連續的,這樣更符合平滑分類結果的要求。通過能量函數的最小化求解,得到優化后的分類結果。
2 實驗與分析
2.1 實驗數據
本文選用了ISPRS三維語義標注比賽提供的公開數據集作為激光點云分類的基準。激光點云數
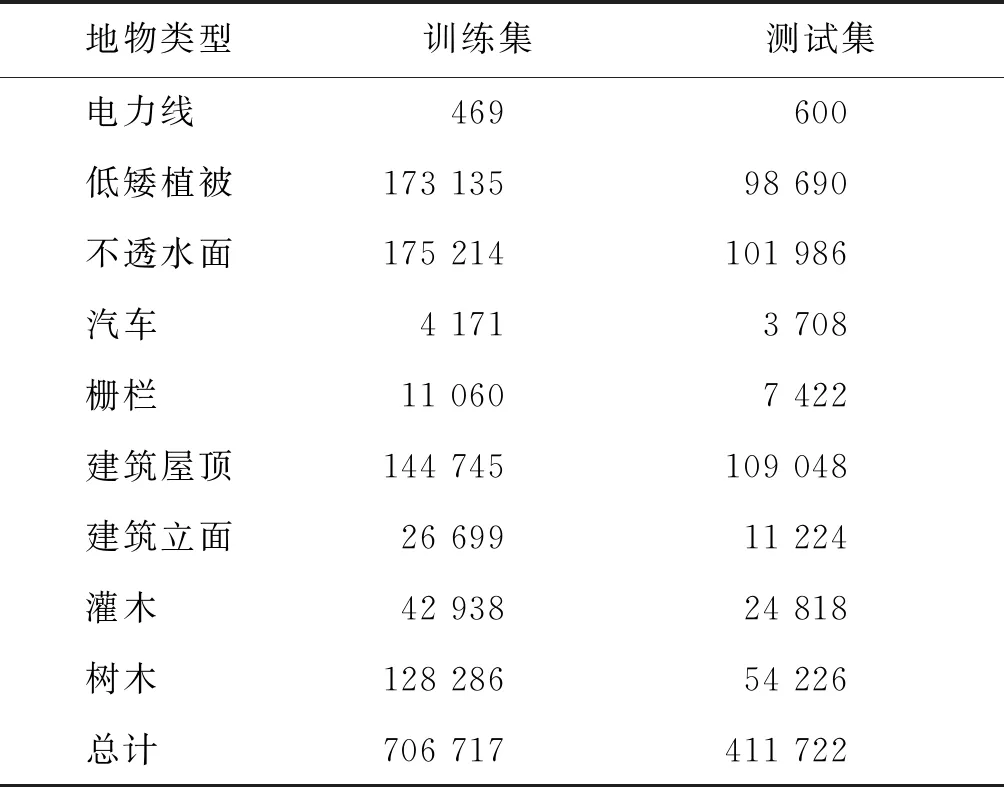
表1 數據類別分布
據集包含使用Leica ALS50系統獲得的ALS數據,點密度在4~7點/m2。此外,激光雷達的多次回波信號和強度值被記錄下來。數據集一共包含9類地物,包括電力線、低矮植被、不透水面、汽車、柵欄、建筑屋頂、建筑立面、灌木和樹木。整個區域都位于建筑物密集的城市中心。相對應的遙感影像包含整個地區范圍,地面采樣距離為8 cm,為假彩色合成影像。

圖1 實驗數據集
2.2 實驗過程
特征提取過程中,基于圓柱形的鄰域采用了規則格網的方法進行簡化,而基于最近鄰的鄰域采用了KD樹建立索引。XGBoost的超參數選擇中通過網格搜索功能,逐步搜索每個超參數在一定范圍內的最優值。本文對模型最大樹深度、子節點最小權重和、最小損失下降值、樣本采樣比例和分裂列采樣比例進行了區域最優搜索,通過設置一定范圍內的典型值,獲取更優模型。本文采用的精度評價指標包括混淆矩陣、總精度和F1分數。
2.3 結果分析
圖2(a)為分類結果,用不同顏色表示。圖2(b)中綠色表示正確分類,藍色表示錯誤分類。

圖2 分類結果
混淆矩陣表示不同類別的相互錯分情況,每一行代表真實數據的歸屬類別分布。從表2可以看出,在點云數量較多的低矮植被、不透水面、建筑屋頂和樹木4大類別中,該分類器取得了較好的分類效果;而對于一些小型地物的分類效果不佳,特別是對于柵欄這一類地物,召回率很低,這與點云數據集中柵欄的數量較少有關。另外,在數據集中柵欄這類地物本身就由植被組成,并在城市中通常位于其他植被附近,因此出現了較嚴重的錯分現象。
為評價該模型的有效性,本文將分類結果與該實驗數據集競賽中的其他方法做了比較。從表3可以看出,本文方法在總體精度上有較大的優勢,在幾個點數多的大類上取得了較好的分類精度。對比4種機器學習模型,LUH方法在F1分數上表現較好,在多個類別上取得了最佳的效果。文本方法在低矮植被和不透水面的類別精度上取得了最好的結果,在電力線、汽車和建筑屋頂3類地物中取得了和最佳值相近的效果。
另外,與數據競賽上一些基于深度學習方法相比,本文方法與其中一些相比具有優勢,但與其中2個最佳的分類精度模型相比,文本方法在F1分數和總體精度均有劣勢。其中,WhuY4方法平均F1=69.2%,總體精度=84.9%;NANJ2方法(將點云插值圖像并通過多尺度卷積神經網絡(MCNN)模型分類)平均F1=69.3%,總體精度=85.2%。考慮到深度學習在處理三維點云所需的高性能計算顯卡,經典機器學習模型只需要CPU就能運行,本文方法在一定程度上不受計算機性能的約束。
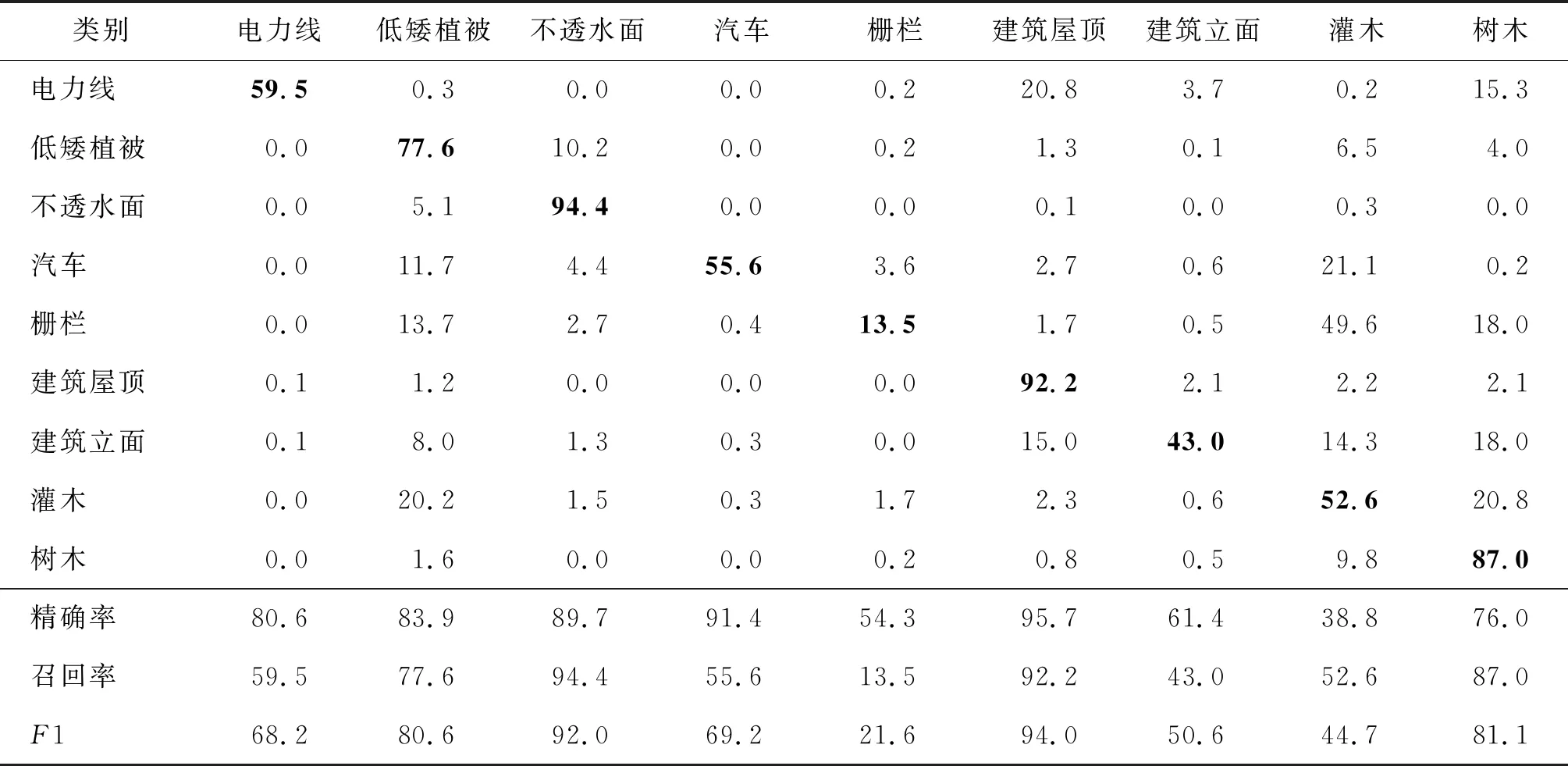
表2 分類混淆矩陣 %

表3 不同方法比較 %
3 結束語
本文總結了一些高效的機載激光點云特征描述方法,并結合機器學習XGBoost分類模型和全連接條件隨機場后處理優化方法,提出了一套機載激光點云分類方法。在未來的工作中,對于復雜的城市場景,需要采用更多新的特征提取方法,從多層次、多尺度來深度挖掘點云信息。另外,需要結合特征選擇的功能,通過分析特征之間的關系抽取有效的特征信息。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
