基于BERT-PGN模型的中文新聞文本自動摘要生成
2021-01-21 03:23:10譚金源刁宇峰祁瑞華林鴻飛
計算機應用 2021年1期
譚金源,刁宇峰,祁瑞華,林鴻飛*
(1.大連理工大學計算機科學與技術學院,遼寧大連 116024;2.大連外國語大學語言智能研究中心,遼寧大連 116024)
0 引言
隨著近些年互聯網產業的飛速發展,大量的新聞網站、新聞手機軟件出現在日常生活中,越來越多的用戶通過新聞網站、手機軟件快速獲取最新資訊。根據中國互聯網絡信息中心(China Internet Network Information Center,CNNIC)第42 次發展統計報告,到2018年6月,中國的移動電話用戶規模達到7.88 億,網民接入互聯網的比例也在增加,通過手機達到98.3%[1]。網友人數增多、新聞媒體網絡平臺使用率不斷提升,網友們使用今日頭條等新聞媒體的頻率也不斷提升。
為了適應當下快節奏的生活,網友需要閱讀最少的新聞字數,獲取新聞文章的關鍵內容。網友們可以通過文本自動摘要技術,概括出新聞的主要內容,節省閱讀時間,提升信息使用效率。因此,本文提出的面向新聞的文本自動摘要模型具有重要意義。
國內外學者針對文本自動摘要已經做了大量的研究。文本自動摘要是20 世紀50 年代出現的一種用計算機完成的文本摘要技術,幫助人們從信息海洋中解放,提高信息的使用效率[2]。自2001年美國國家標準技術研究所舉辦文檔理解會議以來,文本自動摘要研究得到了越來越多的關注[3]。
本文受文獻[4]啟發,針對網友閱讀理解新聞時需要花費大量時間的問題,基于BERT(Bidirectional Encoder Representations from Transformers)和指針生成網絡(Pointer Generator Network,PGN),提出了一種面向中文新聞文本的自動摘要模型——BERT-指針生成網絡(Bidirectional Encoder Representations from Transformers-Pointer Generator Network,BERT-PGN),能夠有效節省時間,提高信息使用效率。該模型首先利用BERT 預訓練語言模型獲取新聞文本的詞向量,結合多維語義特征對新聞中的詞所在的句子進行打分,其結果作為輸入序列輸入到指針生成網絡中進行訓練,得到新聞摘要的結果。
本文主要貢獻如下。
1)本文提出了一種面向新聞文本進行自動摘要的模型——BERT-PGN,分為兩個階段實現:基于預訓練模型及多維語義特征的詞向量獲取階段以及基于指針生成網絡模型的句子生成階段。
2)實驗結果表明,該模型在2017 年CCF 國際自然語言處理與中文計算會議(the 2017 CCF International Conference on Natural Language Processing and Chinese Computing,NLPCC2017)單文檔中文新聞摘要評測數據集上取得了很好的效果,Rouge-2和Rouge-4指標分別提升1.5%和1.2%。
1 相關工作
自動文本摘要有兩種主流方式,即抽取式摘要和生成式摘要[5]。在對文本進行語義挖掘的研究中,許多經典的分類、聚類算法被先后提出[6]。最早的摘要工作主要是利用基于詞頻和句子位置的基于統計的技術[7]。1958 年,Luhn[8]提出了第一個自動文本摘要系統。近十幾年來,隨著機器學習(Machine Learning,ML)以及自然語言處理(Natural Language Processing,NLP)的快速發展,許多準確高效的文本摘要算法被提出[9]。互聯網作為商業媒介快速發展,導致用戶吸收了太多信息。為了解決這種信息過載,文本自動摘要起到了關鍵作用。文本自動摘要可以在屏蔽大量干擾文本的同時,讓用戶更加快捷地獲取關鍵信息,適應當下快節奏的生活[10]。
抽取式摘要方法是將一篇文章分成小單元,然后將其中的一些作為這篇文章的摘要進行提取。Liu 等[11]提出了一個抽取式文本摘要的對抗過程,使用生成對抗網絡(Generative Adversarial Network,GAN)模型獲得了具有競爭力的Rouge分數,該方法可以生成更多抽象、可讀和多樣化的文本摘要;Al-Sabahi 等[12]使用分層結構的自注意力機制模型(Hierarchical Structured Self-Attentive Model,HSSAM),反映文檔的層次結構,進而獲得更好的特征表示,解決因占用內存過大模型無法充分建模等問題;Slamet 等[13]提出了一種向量空間模型(Vector Space Model,VSM),利用VSM 進行單詞相似性測試,對文本自動摘要的結果進行測評,比較文本摘要實現的效果;Alguliyev 等[14]發現,與傳統文本自動摘要方法相比,基于聚類、優化和進化算法的文本自動摘要研究最近表現出了良好的效果。但抽取式摘要并未考慮文本的篇章結構信息,缺少對文本中關鍵字、詞的理解,生成的摘要可讀性、連續性較差。
生成式摘要方法是一種利用更先進自然語言處理算法的摘要方法,對文章中的句子進行轉述、替換等生成文章摘要,而不使用其中任何現有的句子或短語。隨著近些年深度學習的快速發展,越來越多的深度學習方法被利用到文本摘要中。Cho 等[15]和Sutskever 等[16]最早提出了由編碼器和解碼器構成的seq2seq(sequence-to-sequence)模型;Tan 等[17]提出了基于圖的注意力機制神經模型,在文本自動摘要的任務中取得了很好的效果;Siddiqui等[18]在谷歌大腦團隊提出的序列到序列模型的基礎上進行改進,使用局部注意力機制代替全局注意力機制,在解決生成重復的問題上取得了很好的效果;Celikyilmaz 等[19]針對生成長文檔的摘要,提出了一種基于編碼器-解碼器體系結構的深層通信代理算法;Khan 等[20]提出了一種基于語義角色標記的框架,使用深度學習的方法從語義角色理解的角度實現多文檔摘要任務;江躍華等[21]提出了一種基于seq2seq 結構和注意力機制并融合了詞匯特征的生成式摘要算法,能在摘要生成過程中利用詞匯特征識別更多重點詞匯內容,進一步提高摘要生成質量。
現階段大多數的文本自動摘要方法主要是利用機器學習或深度學習模型自動提取特征,利用模型進行摘要句子的選取及壓縮。但自動提取的特征和摘要文本會存在不充分、不貼近的情況,不能很好地刻畫摘要文本。本文提出的BERTPGN 模型基于BERT 預訓練語言模型及多維語義特征,針對中文新聞文本,從更多維度進行特征抽取,深度刻畫摘要文本,能夠得到更貼近主題的摘要內容。
2 BERT-PGN模型
本文提出的BERT-PGN 模型主要分成兩個階段實現,即基于預訓練模型及多維語義的詞向量獲取階段以及基于指針生成網絡模型的句子生成階段,如圖1 所示。該模型第一階段利用預訓練語言模型BERT 獲取新聞文章的詞向量,同時利用多維語義特征對新聞中的句子進行打分,將二者進行簡單拼接生成輸入序列;第二階段將得到的輸入序列輸入到指針生成網絡模型中,使用coverage 機制減少生成重復文字,同時保留生成新文字的能力,得到新聞摘要。
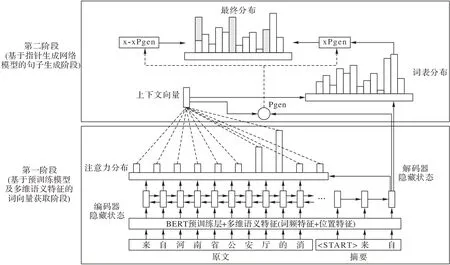
圖1 BERT-PGN模型Fig.1 BERT-PGN model
2.1 基于預訓練模型及多維語義特征的詞向量獲取階段
2.1.1 BERT預訓練語言模型
語言模型是自然語言處理領域一個比較重要的概念,利用語言模型對客觀事實進行描述后,能夠得到可以利用計算機處理的語言表示。語言模型用來計算任意語言序列a1,a2,…,an出現的概率p(a1,a2,…,an),即:
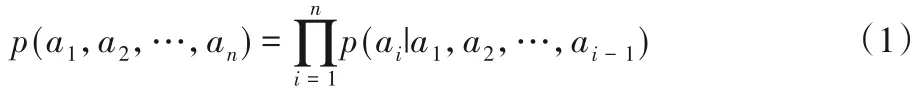
通過傳統的神經網絡語言模型獲取的詞向量是單一固定的,存在無法表示字的多義性等問題。預訓練語言模型很好地解決了這一問題,能夠結合字的上下文內容來表示字。BERT 采用雙向Transformer 作為編碼器進行特征抽取,能夠獲取到更多的上下文信息,極大程度地提升了語言模型抽取特征的能力。Transformer 編碼單元包含自注意力機制和前饋神經網絡兩部分。自注意力機制的輸入部分是由來自同一個字的三個不同向量構成的,分別Query向量(Q),Key向量(K)和Value向量(V)。通過Query向量和Key向量相乘來表示輸入部分字向量之間的相似度,記做[QK]T,并通過dk進行縮放,保證得到的結果大小適中。最后經過softmax 進行歸一化操作,得到概率分布,進而得到句子中所有詞向量的權重求和表示。這樣得到的詞向量結合了上下文信息,表示更準確,計算方法如下:
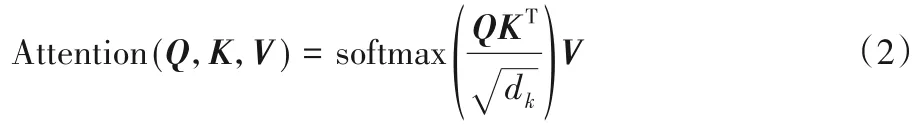
BERT 預訓練模型使用了“MultiHead”模式,即使用了多個注意力機制獲取句子的上下文語義信息,稱為多頭注意力機制。BERT 預訓練語言模型能夠使詞向量獲取更多的上下文信息,更好地表示原文內容。
2.1.2 多維語義特征
針對中文新聞重點內容集中在新聞開頭、關鍵詞出現頻率高等特點,本文引入了傳統特征以及主題特征對中文新聞文本中的句子進行細粒度的描述,提升對文本中句子的上下文語義表述性能。
1)傳統特征。
本文所選擇的傳統特征主要為句子層次的兩種特征:句子中的詞頻以及在文章中的位置。
詞頻特征是反映新聞文章中最重要信息的一種統計特征,也是最簡單、最直接的一種統計特征。新聞文章中出現詞的詞頻可以利用式(3)進行計算:

其中,wordj代表文章中第j個詞出現的次數。
在本文中,選擇文章中的句子作為最終的打分基本單位。句子是詞的集合,如果句子包含的詞語中,有在新聞文章中頻繁出現的高頻詞,則認為這個句子在文章中更加重要。新聞文章中第i個句子的詞頻特征打分公式如下:

其中:TFi表示第i個句子中包含的詞的詞頻之和,seni代表第i個句子中包含的所有詞。
位置特征同樣是反映新聞文章中重要信息的一種統計特征。一篇新聞文章是由多個句子組成的,句子所在的位置不同,其代表的重要性也不同,例如文章中的第一個句子大多是新聞文章中最重要的一句話。新聞文章中第i個句子的位置特征打分公式如下:

其中:Posi代表第i個句子的位置得分,pi代表第i個句子在新聞文章中的位置,n代表文章中的句子總個數。
2)主題特征。
本文選取的主題特征也可表述為標題特征。新聞文章中的標題具有很高的參考價值,很大程度上可以代表文章中的主題。因此,如果文章中的句子與新聞文章的標題有較高的相似度,那么這個句子更容易被選擇為文章摘要中的句子。本文使用余弦相似度計算新聞文章中第i個句子的主題特征得分,打分公式如下:
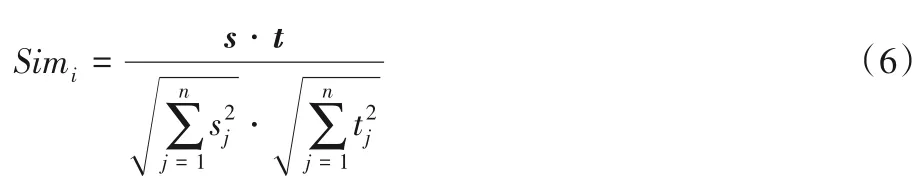
其中:Simi表示第i個句子與新聞文章標題的相似度,s和t分別代表標題和新聞文章中句子的向量化表示。
2.2 基于指針生成網絡模型的句子生成階段
指針生成網絡模型結合了指針網絡(Pointer Network,PN)和基于注意力機制的序列到序列模型,允許通過指針直接指向生成的單詞,也可以從固定的詞匯表中生成單詞。文本中的文字wi依次傳入BERT-多維語義特征編碼器、雙向長短時記憶神經網絡(Bidirectional Long Short-Term Memory,Bi-LSTM)編碼器,生成隱層狀態序列hi。在t時刻,長短時記憶(Long Short-Term Memory,LSTM)神經網絡解碼器接收上一時刻生成的詞向量,得到解碼狀態序列st。
注意力分布at用來確定t時刻輸出序列字符時,輸入序列中需要關注的字符。計算公式如下:
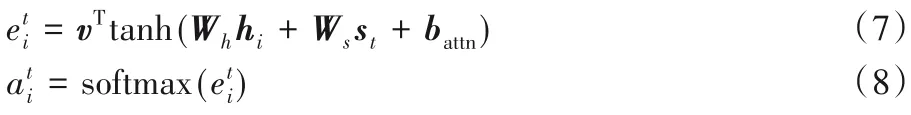
其中,v、Wh、Ws、battn是通過訓練得到的參數。利用注意力分布對編碼器隱層狀態加權平均,生成上下文向量

將上下文向量ht*與解碼狀態序列st串聯,通過兩個線性映射,生成當前預測在詞典上的分布Pvocab,計算公式如下:
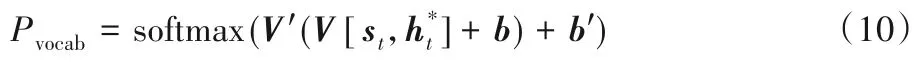
其中,V′、V、b、b′是通過訓練得到的參數。
模型利用生成概率Pgen來確定復制單詞還是生成單詞,計算公式如下:
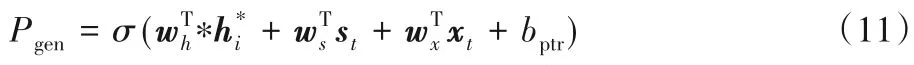
其中,wh、ws、wx、bptr是通過訓練得到的參數,σ是sigmoid 函數,xt是解碼輸入序列。將at作為模型輸出,得到生成單詞w的概率分布:
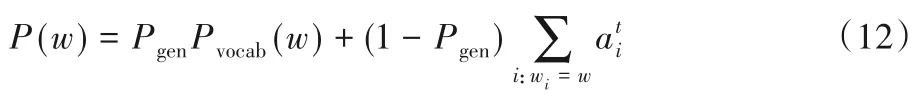
為了解決生成詞語重復的問題,本文引入了coverage 機制。通過coverage 機制對指針生成網絡模型進行改進,能夠有效減少生成摘要中的重復。引入coverage 向量ct跟蹤已經生成的單詞,并對已經生成的單詞施加一定的懲罰,盡量減少生成重復。coverage向量ct計算方式如下:

通俗來說,ct表示目前為止單詞從注意力機制中獲得的覆蓋程度。使用coverage向量ct影響注意力分布,重新得到注意力分布at,計算公式如下:
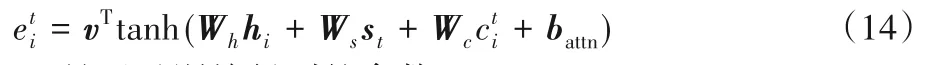
其中Wc是通過訓練得到的參數。
3 實驗與分析
3.1 實驗數據
本文的實驗部分使用的數據是由2017 年CCF 國際自然語言處理與中文計算會議(NLPCC2017)提供,來自于NLPCC2017 中文單文檔新聞摘要評測數據集,包含訓練集新聞文本49 500 篇,測試集新聞文本500 篇。該任務中要求生成的摘要長度不超過60個字符。
3.2 評價指標
Rouge 是文本自動摘要領域摘要評價技術的通用指標之一,通過統計模型生成的摘要與人工摘要之間重疊的基本單元,評判模型生成摘要的質量。本文參考NLPCC2017 中文單文檔新聞摘要評測任務,使用Rouge-2、Rouge-4 和Rouge-SU4作為評價指標,對摘要結果進行評價。
3.3 對比實驗
本文實驗部分選取8 種基本模型:NLPCC2017 單文檔新聞摘要評測任務結果較好團隊(ccnuSYS、LEAD、NLP@WUST、NLP_ONE)提出的模型[22]、PGN(without coverage mechanism)[23]、PGN[23]、主題關鍵詞信息融合模型[24]以及BERT-PGN(without semantic features)。對人工提取的主題特征、傳統特征進行特征的有效性驗證,驗證本文提出方法的有效性。
1)ccnuSYS[22]:使用基于注意力機制的LSTM 編碼器-解碼器結構模型生成摘要。
2)LEAD[22]:從原文選取前60個字作為文本摘要。
3)NLP@WUST[22]:使用特征工程的方法進行句子抽取,并利用句子壓縮算法對抽取的句子進行壓縮。
4)NLP_ONE[22]:NLPCC2017 單文檔新聞摘要評測任務第一名的算法,包含輸入、輸出序列的注意力機制。
5)PGN(without coverage mechanism)[23]:ACL2017 中提出的一種生成模型,使用指針網絡和基于注意力機制的序列到序列模型生成摘要,不使用coverage機制。
6)PGN(coverage mechanism)[23]:改進的指針生成網絡模型,利用coverage機制解決生成重復詞和未登錄詞的問題。
7)主題關鍵詞融合模型[24]:一種結合主題關鍵詞信息的多注意力機制模型。
8)BERT-PGN(without semantic features):本文提出的一種基于BERT 和指針生成網絡的模型,利用coverage 機制減少生成重復內容。
9)BERT-PGN(semantic features):在BERT-PGN(without semantic features)模型上進行優化得到的模型,結合多維語義特征獲取細粒度的文本上下文表示。
3.4 實驗環境及參數設置
本文實驗使用單個GTX-1080Ti(GPU)進行訓練。本實驗獲取文本詞向量使用BERT-base 預訓練模型。BERT-base 模型共12 層,隱層768 維。設置最大序列長度為128,train_batch_size為16,learning_rate為5E-5。
指針生成網絡模型設置batch_size為8,隱層256 維,設置字典大小為50k。訓練過程共進行700k 次迭代,訓練總時長約為7 d5 h(合計173 h)。
3.5 實驗結果與分析
3.5.1 總體摘要結果對比實驗
本文重新運行了部分baseline模型,將獲取的結果與本文提出的模型結果做對比,實驗結果如表1。
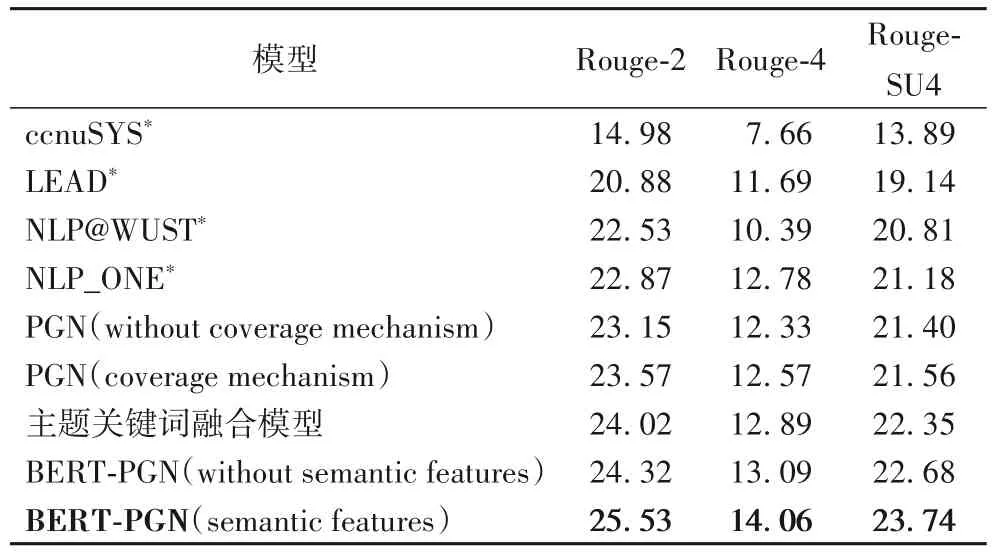
表1 總體摘要結果對比Tab.1 Results comparison of overall summarization
從表1 可以看出,本文提出的模型性能相較于PGN、NLP_ONE 等模型有了顯著的提升,在Rouge-2、Rouge-4 以及Rouge-SU4 的評價指標中有著明顯的優勢,Rouge 指標提升了1.2~1.5個百分點。
由BERT-PGN(semantic features)模型與PGN、BERT-PGN(without semantic features)模型進行對比,可以看出使用BERT預訓練模型并結合有效的多維人工特征,能夠顯著提升模型效果。使用BERT 預訓練模型并結合人工抽取的特征得到的句子上下文表示,對文本中句子的語義理解更加深刻、準確,在文本自動摘要任務中能夠有效提升性能。
根據表2 不同模型生成摘要的內容可以發現,本文提出的BERT-PGN 模型相較于其他模型,在中文新聞文本的自動摘要任務中生成的摘要內容更豐富、更全面、更貼近標準摘要,說明該模型對全文的理解更加充分,能夠結合文中句子的上下文充分理解句子、詞語的含義,對文中的句子、詞語進行更細致的刻畫。

表2 摘要結果示例Tab.2 Summarization result examples
3.5.2 多維語義特征對比實驗
多維特征選取的部分,本文針對新聞文本“主要內容集中在開頭部分”的特點,選取傳統特征、主題特征中的詞頻特征、位置特征以及標題特征,分別表示為TF、Pos以及Main。
由表3 可以看出,同一模型結合人工提取的詞頻特征和位置特征效果最好,Rouge-2 指標最多提升了1.2 個百分點,Rouge-4指標最多提升了1.0個百分點。
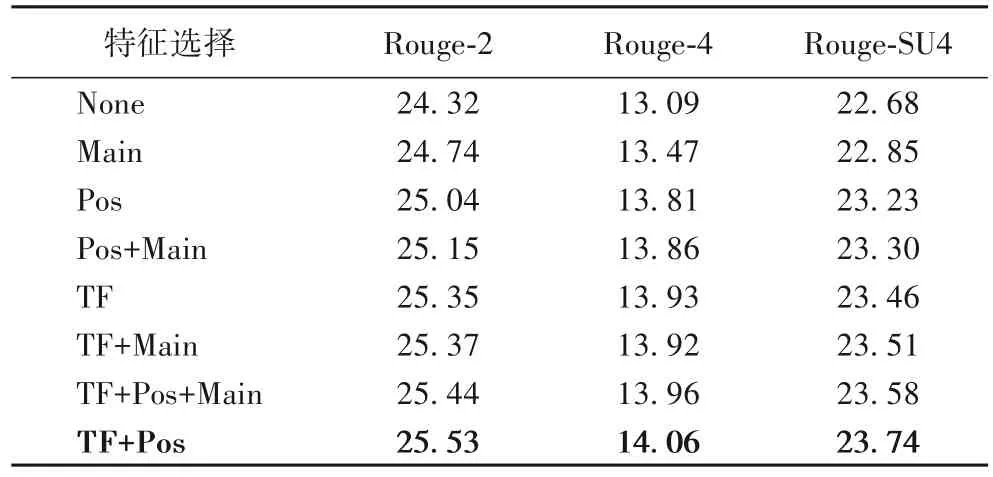
表3 特征組合結果對比 單位:%Tab.3 Feature combination result comparison unit:%
本文選取的主題特征Main 能夠在一定程度上提升模型的Rouge 指標。從Pos 和Pos+Main、TF 和TF+Main 的特征組合結果對比可以得知,主題特征結合詞頻特征時提升明顯,結合位置特征時基本沒有提升。句子在新聞中的位置靠前時,與標題的相似度也更高,說明兩種人工特征在衡量句子在新聞中的重要性時起到了相似的作用。通過對比TF+Main 和TF+Pos 兩種特征組合的結果可以得知,詞頻信息結合位置信息相較于結合主題信息效果更好,能夠充分表達句子在新聞文章中的重要性。因此,本文選擇使用詞頻特征以及位置特征的特征組合作為多維特征。
新聞文章中多次出現的關鍵詞,是反映新聞文章中最重要信息的一種統計特征,進行詞頻統計的意義在于找出文章表達的重點;此外,句子出現的位置也是反映句子重要程度的關鍵,出現的位置越靠前,說明該句子在文章中起到的作用越大。因此,詞頻、位置特征是自動摘要模型提升的關鍵。
3.5.3 coverage機制實驗分析
本文使用的模型使用了coverage 機制,試圖解決生成重復內容的問題。通過計算生成摘要中1-gram、2-gram、3-gram以及4-gram 所占比例,定量分析引入coverage 機制解決生成內容重復問題的效果。
由表4 可以看出,本文提出的BERT-PGN 模型相較于NLP_ONE 能夠有效減少生成內容的重復,在解決重復的方面效果明顯,在3-gram、4-gram 的摘要結果定量分析中,接近標準摘要的效果。
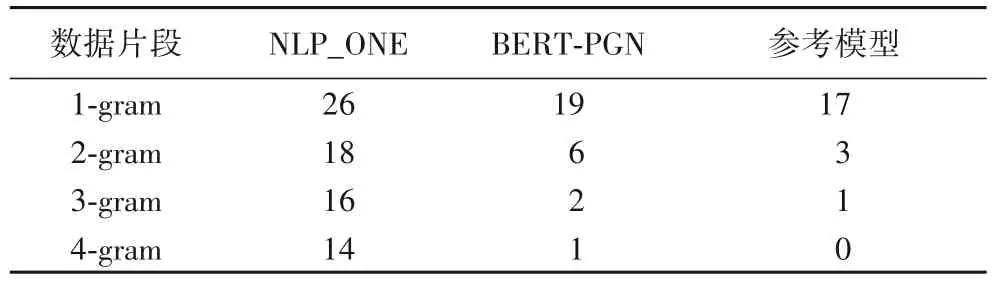
表4 coverage機制驗證 單位:%Tab.4 Verification of coverage mechanism unit:%
4 結語
本文提出了一種面向中文新聞文本的BERT-PGN 模型,結合BERT 預處理模型及多維語義特征獲取詞向量,利用指針生成網絡模型結合coverage 機制減少生成重復內容。經實驗表明,BERT-PGN 模型在中文新聞摘要任務中,生成的摘要結果更接近標準摘要,包含更多原文的關鍵信息,能有效解決生成內容重復的問題。
下一步將嘗試挖掘更多要素,例如:面向新聞文本的有效人工特征等,提升摘要結果;簡化模型,縮短模型訓練時間;提升生成摘要內容的完整性、流暢性;構建新聞領域的外部數據,幫助模型結合句子上下文充分理解句子含義。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
文苑(2018年21期)2018-11-09 01:23:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
中國衛生(2015年9期)2015-11-10 03:11:12
大連民族大學學報(2015年2期)2015-02-27 08:28:11
中國衛生(2014年3期)2014-11-12 13:18:12
中國火炬(2014年4期)2014-07-24 14:22:19
