
基于注視興趣區域聚類和轉移的群體掃視路徑生成
2021-01-21 03:23:14劉楠博張文雷李旺鑫
計算機應用 2021年1期
劉楠博,肖 芬,張文雷,李旺鑫,翁 尊
(智能計算與信息處理教育部重點實驗室(湘潭大學),湖南湘潭 411105)
0 引言
人類通過視覺這一重要感官捕獲到日常生活中的海量信息。在人類視覺系統(Human Visual System,HVS)選擇注意機制的引導下,人們將視覺注意集中于海量信息的感興趣區域(Region Of Interest,ROI),摒棄了其中的大量冗余,使人腦實時、高效地完成視覺信息處理[1]。挖掘、研究人類視覺系統的選擇注意機制,賦予機器類人的視覺信息處理能力,對于人工智能和機器視覺領域的發展具有重要意義[2]。
目前,人們利用眼動追蹤技術記錄的眼動數據研究視覺注意的分布和轉移。原始的眼動數據是通過紅外設備以一定頻率采集的視線位置樣本點,經后處理操作可以得到注視點數據和掃視路徑數據。長期以來,多數工作利用計算建模的方法挖掘群體觀察者的注視點數據研究人類的視覺注意機制,通過生成靜態顯著圖直接、整體地反映人類對圖像場景的視覺注意程度[3-6]。然而人類觀察圖像是一個動態的視覺注意轉移過程,靜態顯著圖無法反映群體觀察者整體的視覺注意轉移模式。相較于注視點數據,掃視路徑數據額外記錄了注視點的轉移信息,可以反映視覺注意的動態變化,具有更高的研究價值。
在相同的觀看條件下,群體觀察者的掃視路徑雖然復雜多變,但是個體掃視路徑間具有相似但不等同的潛在特性[7]。例如,通過分析閱讀場景下的群體觀察者的掃視路徑數據探索中文閱讀中的詞切分,研究人類的閱讀認知行為[8];通過研究廣告與網頁等刺激樣本下的群體掃視路徑設計,可以設計并優化網頁排版[9-14];自然場景下通過歸結表征群體的掃視路徑,不僅能為基于深度學習的掃視路徑預測模型提供監督信息,而且有助于計算機優先定位、處理人類的感興趣區域信息,提升智能圖像處理模型的速度和精度[15-16]。挖掘群體觀察者的掃視路徑數據,歸結一條包含共有注視信息和注視轉移模式的群體掃視路徑,不僅能夠表征刺激樣本和刺激內容對人類的吸引程度,更重要的是,可以建模人類的動態視覺注意,對于探究人類的認知行為、精準改善視覺效果、提升計算機視覺的智能性都具有重要理論意義。
1 相關工作
近年來,群體掃視路徑研究相對較少,現有的生成方法主要基于三種思路。其一,將群體觀察者的掃視路徑映射為字符串序列,利用序列模式挖掘進行群體注視模式歸結。2006年West 等[17]開發了eyePatterns 工具,該工具通過統計單個序列中所有子序列模式及出現頻率,提取出現次數或涵蓋人數最多的序列模式生成群體掃視路徑;同年,Hembrooke 等[18]提出多序列對齊方法,通過迭代過程將某一序列與其他所有序列逐一進行對齊操作,提取共有、對齊的子序列和序列元素生成群體掃視路徑;2010 年Goldberg 等[19]提出Dotplot 對齊算法,可用于提取兩個序列的共有、最長序列模式,在此基礎上Eraslan 等[9]提出eMine 方法,通過迭代過程提取所有序列的共有、最長序列模式;2012 年,Hejmady 等[20]提出序列模式挖掘算法(Sequential Pattern Mining Algorithm,SPAM),通過提取所有序列的頻繁子序列生成群體掃視路徑。此類方法可以挖掘有代表性的子序列和序列元素,但當個體注視行為差異較大,沒有共同子序列或共同子序列過短時都會影響生成路徑質量。其二,確定群體觀察者的共同視覺元素,歸結其轉移模式。2010 年Tsang 等[21]開發了eSeeTrack 工具,按照時間軸生成群體觀察者視覺元素間轉移概率的可視化樹,并分析群體的注視轉移模式;2014 年Chuk 等[22]及2015 年Kang 等[23]構建視覺元素間的馬爾可夫轉移概率矩陣,研究群體的注視轉移模式。采用這些策略依據視覺元素間的轉移概率生成群體路徑時,常常存在重復、循環某一轉移模式的現象,為防止生成路徑過長需要預設長度閾值。2016 年Eraslan 等[11]提出掃視路徑趨勢分析(Scanpath Trend Analysis,STA)方法,該方法對網頁進行分割,將所有觀察者觀看的區域視作共同視覺元素,定義優先度排序共同視覺元素,最終生成群體掃視路徑。其三,將群體觀察者的掃視路徑表征為多個多維向量,尋找或生成表征群體的掃視路徑向量。2017 年Li 等[15]提出基于候選約束的動態時間規整質心平均方法(Candidate-constrained Dynamic time warping Barycenter Averaging method,CDBA),通過動態時間規整策略找出與其他個體掃視路徑動態時間規整距離最小的一條個體掃視路徑,使用親和力傳播聚類算法生成的聚類區域調整該個體路徑中的注視點,最終生成群體掃視路徑。2018 年Li 等[16]提出Heuristic 方法,該方法在CDBA框架的基礎上加入注視時間分析模塊,生成包含注視時間的群體掃視路徑。此方法中動態時間規整策略找出的個體掃視路徑往往較短,直接受該個體路徑影響,生成的群體掃視路徑包含的注視興趣區域數目較少、路徑長度較短。
值得注意的是,目前掃視路徑的研究主要針對的是網頁場景[9-14,17-18,20,22-23]、自然場景的掃視路徑研究較少[15-16]。究其原因,本文認為網頁排版較為固定,注視區域基本呈現F 型,所以掃視路徑相對有規律,生成較簡單;而自然圖像中由于場景的多樣性、目標的復雜性,導致注視區域復雜多變,因此群體掃視路徑研究相對困難,生成方法十分欠缺。本文借鑒自然場景中聚類注視點生成注視區域的思想以及網頁場景中注視區域的轉移策略,考慮不同類型的注視行為,提出了一種針對自然場景的群體路徑生成方法。圖1 展示了所提生成方法的模型框架。

圖1 群體掃視路徑生成模型的框架Fig.1 Framework of group scanpath generation model
2 基于注視興趣區域轉移的群體掃視路徑生成方法
2.1 注視興趣區域提取
眾所周知,人類在觀察、獲取圖像信息時,圖像對人類的視覺吸引源于場景中的某個區域而非某個具體像素。即使觀察者們注視了場景中的同一區域,由于高度的觀察自由度,注視點著落的像素位置不盡相同。本文通過親和力傳播(Affinity Propagation,AP)聚類算法[24]對位置相關的觀察者注視點進行聚類,確定注視興趣區域。
AP 算法適用于高維、多類型數據的快速聚類。該算法無需事先設定生成聚類的數目,將所有數據點都視作潛在意義上的聚類中心,通過數據點間的通信,找出最適合作聚類中心的數據點。算法輸入節點間相似度矩陣S,s(i,j)表示節點i和j之間的相似度;定義節點間的吸引度矩陣R和歸屬度矩陣A,并通過如式(1)~(3)更新矩陣(R0,A0均為零矩陣),直至聚類結果穩定或算法執行超過設定的迭代次數(1 000次),結束算法,輸出聚類結果。

其中:rt+1(i,j)表示t+1時刻節點j作i聚類中心的適合程度,at+1(i,j)表示t+1時刻節點i對j作其聚類中心的認可程度。
對自然場景圖像,本文將所有p名觀察者注視點位置的負歐氏距離作為相似度矩陣S,執行AP 算法生成n個聚類注視點的集合Θ1,Θ2,…,Θk,…,Θn,將每個集合作為一個注視興趣區域,其邊界由集合中注視點的位置確定。
2.2 注視興趣區域篩選
每個注視興趣區域包含了不同的圖像內容,對群體觀察者具有不同的視覺吸引程度。為獲取能夠吸引群體視覺注意的興趣區域,本節提出如下迭代篩選策略。
給定一組興趣區域Θ1,Θ2,…,Θk,…,Θm,分別統計每個興趣區域Θk的觀察者數目ok、觀看頻次fk和觀看時長tk,對各區域指標進行歸一化后形成3個m元向量:O、F和T。定義興趣區域注視強度Φ=(φ1,φ2,…,φk,…,φm)以及注視強度差E=(ε1,ε2,…,εk,…,εm),其中:

εmin_index表示向量E中的最小分量。通過迭代過程不斷刪去min_index 對應的注視強度最低的興趣區域,更新O、F、T、Φ和E,直至min(E) <mean(E) -std(E)或者size(E) ≥m/2終止迭代。對聚類的n個興趣區域執行以上過程,最終篩得n′個具有較高注視強度的興趣區域。
2.3 注視興趣區域轉移
實驗發現,注視興趣區域的內容、空間位置及關聯程度均會影響群體觀察者的注視順序。為生成群體路徑,本文考慮每個興趣區域中注視點在個體掃視路徑中的注視順序,在此基礎上統計興趣區域的注視優先度以及轉移模式。
假設興趣區域Θk有來自不同觀察者的l個注視點,Θk={θk,1,θk,2,…,θk,l},定義其注視優先度為ζk:
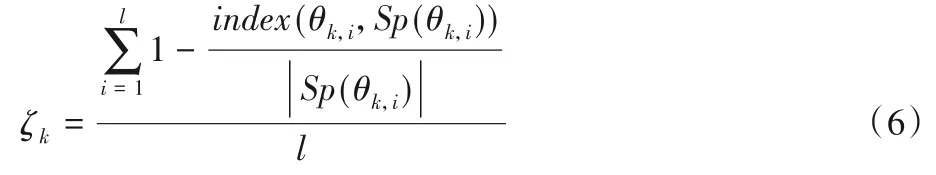
其中:Sp(θk,i) 表示獲取θk,i所在的個體掃視路徑,index(θk,i,Sp(θk,i))表示θk,i在Sp(θk,i)中的順序索引,|Sp(θk,i)|是個體掃視路徑長度。
考慮到生成路徑的表征性能,本文僅統計篩選后的興趣區域的注視優先度和轉移模式,通過式(6)得到注視優先度向量Z=(ζ1,ζ2,…,ζk,…,ζn′)。分量ζk值越高,其對應的興趣區域被優先注視的可能性越大,降序排列Z的分量得到興趣區域轉移模式。
2.4 群體掃視路徑生成方法SCA
本節提出基于注視興趣區域提取、篩選和轉移的群體掃視路徑生成方法(Sorting Clusters Approach,SCA)。算法1 展示了SCA方法的具體流程。
算法1 群體掃視路徑生成方法SCA。
輸入 所有觀察者的掃視路徑矩陣AllScanpathMat。
輸出 群體掃視路徑GroupScanpath。

3 基于注視行為的群體掃視路徑生成方法
在SCA 的基礎上,本章通過定義4 種注視行為對興趣區域作進一步細分,結合興趣子區域的轉移模式,研究基于注視行為的群體掃視路徑生成方法。
3.1 注視興趣子區域提取
實際觀看過程中,內涵豐富、相互關聯的興趣區域往往會吸引觀察者產生多次、反復的注視行為。如圖2 所示,圖像中存在3 個興趣區域Θ1、Θ2和Θ3,scanpath_1 是一條個體掃視路徑。觀察可知,Θ1區域可能包含豐富的圖像內容,引起scanpath_1 觀察者產生θ1,1,θ1,2,θ1,3,θ1,4,θ1,5共5 個注視點。這些注視點在位置、時間、順序上存在一定差別,為了獲取群體觀察者不同時刻、不同順序關注的不同局部信息,本文定義了興趣區域Θk的首視注視點、首視連續注視點、回視注視點和回視連續注視點,將Θk劃分為4 個獨立的注視點集Ffixk、FSfixk、Bfixk和BSfixk。
定義1首視注視點:x∈Θk并且x是對應個體掃視路徑Sp(x) 中第一個落于興趣區域Θk的注視點,如圖2 中θ1,1∈Ffix1。
定義2首視連續注視點:x∈Θk,其個體掃視路徑Sp(x)中x的前序注視點是興趣區域Θk的首視注視點或x的多個前序注視點同屬于興趣區域Θk且包含首視注視點,如圖2 中{θ1,2,θ1,3}?FSfix1。
定義3回視注視點:x∈Θk,其個體掃視路徑Sp(x)中前序注視點不屬于興趣區域Θk,但x非首視注視點,如圖2 中θ1,4∈Bfix1。
定義4回視連續注視點:x∈Θk,其個體掃視路徑Sp(x)中x的前序注視點是興趣區域Θk的回視注視點或x的多個前序注視點同屬于興趣區域Θk且包含回視注視點,如圖2 中θ1,5∈BSfix1。

圖2 注視興趣區域與個體掃視路徑示意圖Fig.2 Schematic diagram of fixation region of interest and individual scanpath
將Ffixk、FSfixk、Bfixk和BSfixk作為興趣區域Θk的興趣子區域,分別表示群體觀察者首次、首次連續、回視、回視連續注視關注的興趣區域局部,其邊界由各點集中注視點的位置確定。若Θk中某注視行為的注視點集為空集,則該興趣區域不存在相應興趣子區域。
3.2 注視興趣子區域篩選和轉移
實驗發現,觀看不同圖像時,觀察者產生各類注視行為的次數有所差別。為保證生成路徑符合實際、表征群體,本節統計觀各圖像中所有觀察者產生各類注視行為的平均次數,提出如下篩選策略。
對迭代篩選后的興趣區域,本文考慮所有這些區域的首視興趣子區域,篩選閾值記為len1,len1=n′。首視連續興趣子區域的篩選閾值記為len2:

其中:size(FSfixi)表示FSfixi區域首視連續注視點的數目,p為觀察者數目。在FSfix1,FSfix2,…,FSfixn′中篩選出觀察者數目最多的len2 個子區域。回視、回視連續興趣子區域的篩選過程與首視連續興趣子區域一致。通過式(7)得到len3 和len4,最終篩得(len1+len2 +len3+len4)個興趣子區域。
通過式(6)計算首次、回視興趣子區域的注視優先度向量Z′=(ζ1′,ζ2′,…,ζlen1+len2′),降序排序Z′中的分量生成首視、回視興趣子區域的轉移模式。將篩得的(len3+len4)個連續注視興趣子區域插入相應的首視、回視興趣子區域之后,得出最終的興趣子區域轉移模式。
3.3 群體掃視路徑生成方法DFS
本節提出基于劃分、篩選、轉移興趣區域的群體掃視路徑生成方法(Devide,Filter,Sort Clusters Approach;DFS)。算法2展示了DFS方法的具體流程。
算法2 群體掃視路徑生成方法DFS。
輸入AllScanpathMat,迭代篩選的興趣區域結構體NewThetaStruct。
輸出GroupScanpath。
第一階段 興趣子區域劃分、篩選。

第二階段 興趣子區域轉移。

第三階段 生成群體路徑
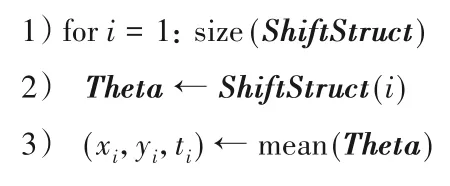

4 實驗與結果
為驗證所提方法的有效性,本文在MIT1003[25]和OSIE[26]兩個公共數據集進行相關實驗,并與現有方法進行對比。
4.1 實驗數據集
MIT1003 數據集包含1 003 幅多個類別、尺寸不一的自然場景圖像,對每張刺激樣本采集15 名觀察者3 s 觀察時長的眼動數據。OSIE 數據集包含700 幅多個類別、尺寸相同的自然場景圖像,圖像尺寸統一為800×600 像素,每張刺激樣本收集15名觀察者3 s觀察時長的眼動數據。
本文統計了兩個數據集中每張刺激樣本的平均注視點數和平均興趣區域數,如表1 所示。通過對比兩數據集的刺激樣本和眼動數據,本文發現OSIE 中多數圖像擁有較為明顯的物體,觀察者產生的注視點相對較多,注視區域分布較為集中;而MIT1003 中圖像較為復雜,觀察者產生的注視行為較少,注視點分布較為分散,因此MIT1003數據集的群體掃視路徑生成更為困難。

表1 數據集對比Tab.1 Dataset comparison
4.2 定性分析
本節將提取的興趣區域、篩選的興趣區域、SCA 和DFS方法生成的群體掃視路徑進行可視化處理,依據可視化結果作出定性分析。
圖3展示了聚類注視興趣區域的可視化結果。

圖3 注視興趣區域可視化Fig.3 Visualization of fixation regions of interest
圖3(a)是未經篩選的興趣區域,圖3(b)是篩選后的興趣區域,圖像樣本1、2 取自MIT1003 數據集,圖像樣本3、4 取自OSIE數據集。通過對比可以發現,對圖像樣本1~4,經篩選步驟,圖3(a)中注視點數目較少、注視強度相對較低的興趣區域能夠被適當剔除,注視點數目較多、注視強度相對較高的興趣區域可以被有效保留。
圖4展示了群體掃視路徑可視化結果,圖像樣本1、2取自MIT1003 數據集,圖像樣本3、4 取自OSIE 數據集。通過對比可以發現,對圖像樣本1~4,所提兩種方法的群體掃視路徑(b)、(c)能夠涵蓋群體觀察者真實掃視路徑(a)中的注視興趣區域,可以表征群體的注視轉移趨勢。另外,DFS方法的群體掃視路徑(c)包含了高注視強度興趣區域的連續注視和回視,更加貼合真實的掃視路徑。

圖4 群體掃視路徑可視化Fig.4 Visualization of group scanpaths
4.3 定量評價
目前常用的定量評價策略是將生成的群體掃視路徑與每一條真實記錄的個體掃視路徑作相似度比較,以相似度的均值定量衡量其表征能力。
4.3.1 評價指標
比較眼動數據相似度的方法[27-29]有很多,它們不盡相同,各有側重。本文采用了兩種較常應用的針對掃視路徑的評價指標MultiMatch[28]和ScanMatch[29],從時間和空間角度比較群體掃視路徑與個體掃視路徑的相似度。
MultiMatch 指標將掃視路徑視作注視點排列形成的掃視向量,利用Dijkstra 算法[30]生成兩掃視向量的對齊矩陣,從掃視向量形狀、長度、方向和注視點位置、時間5 個維度量化計算對齊部分子向量的相似度,求取對齊子向量相似度的均值衡量兩掃視路徑的相似度。通過計算群體路徑與每條個體路徑五項相似度指標的均值,衡量群體路徑與所有個體路徑的相似性,指標越高,表明群體路徑的表征效果越好。實驗中MultiMatch 中的參數設置為:global Threshold=Diagonal/10,direction Threshold=45,duration Threshold=inf。
ScanMatch 指標對圖像作隔柵劃分將掃視路徑映射為字符串序列,利用Needleman-Wunsch 算法[31]計算兩掃視字符串序列的最佳對齊分數,對齊分數越高,兩掃視路徑的整體相似性越高。通過計算群體路徑與每條個體路徑的對齊分數均值,衡量群體路徑與所有個體路徑的相似性,指標越高,表明群體路徑的表征效果越好。另外,通過設置TempBin參數該指標可以考慮時間因素對兩路徑對齊的影響,假設格柵Grid1中存在一個300 ms 的注視點,TempBin=0 時,映射出的字符串序列為(Grid1),TempBin=100 時,映射出的字符串序列為(Grid1,Grid1,Grid1)。實驗中ScanMatch 的參數設置為:Xbin=24,Ybin=18,Threshold=3.5,GapValue=0,TempBin=100(不考慮時間因素時TempBin=0)。
4.3.2 對比實驗及分析
文獻[16]中,Li 等將所提的自然場景群體掃視路徑生成方法CDBA[15]、Heuristic[16]應用于MIT1003 和OSIE 兩個公共的自然場景數據集,利用MultiMatch 和ScanMatch 指標,與網頁場景的生成方法eMine[9]、STA[11]、SPAM[20]進行比較,取得了全面超越的效果[16]。為了衡量所提生成方法SCA和DFS有效性以及與現有方法的差距,本文使用相同的數據集、評價指標分別進行了生成實驗、定量評價,并與文獻[16]中現有方法的評價結果進行比較。由于MultiMatch 指標中參數durationThreshold=inf,對比過程對子路徑進行了簡化,導致SCA 方法在MIT1003 數據集中1 張圖像和OSIE 數據集中11幅圖像上簡化后的路徑過短,無法與真實路徑對比,因此,SCA 的MultiMatch 評價結果中未計入這12 幅圖像。表2 展示了不同生成方法的指標結果。
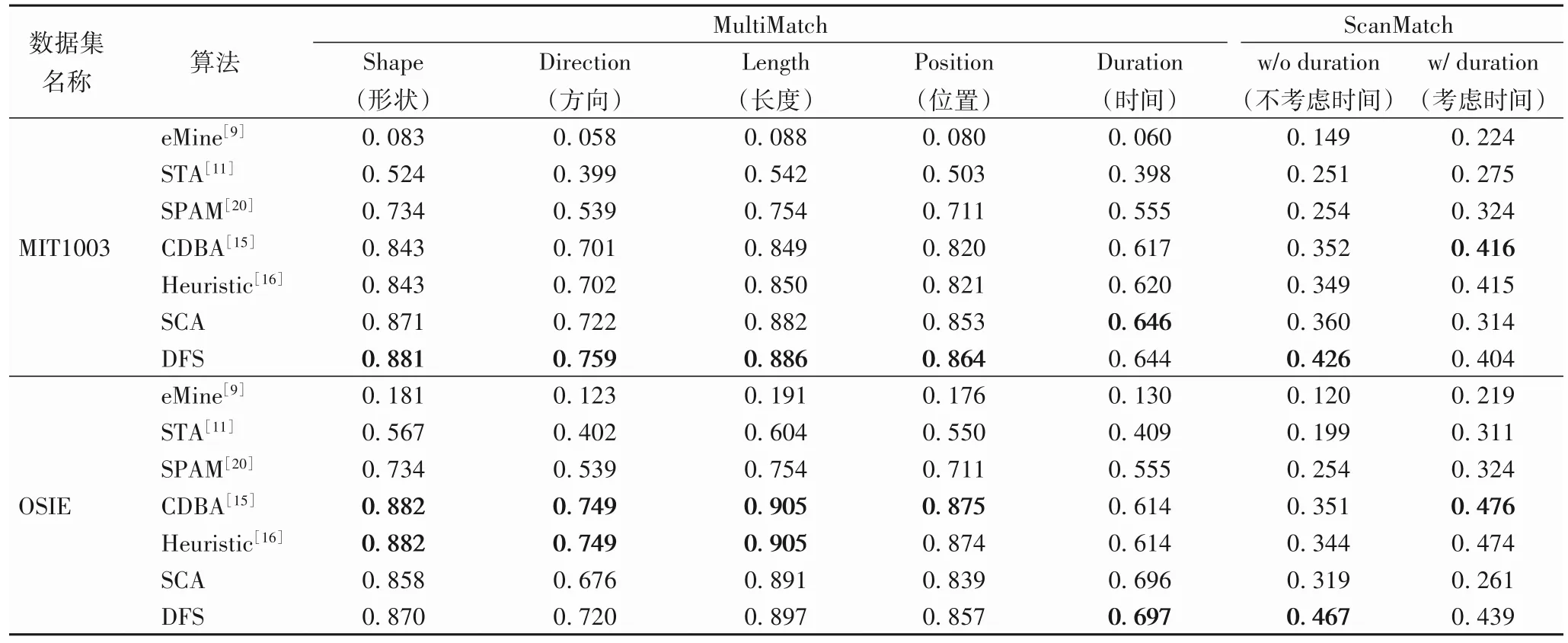
表2 利用MultiMatch↑和ScanMatch↑評估群體路徑算法Tab.2 Evaluation of group scanpath algorithms by MultiMatch ↑and ScanMatch ↑
首先,對比SCA和DFS方法可以發現,通過注視優先度排序注視興趣區域的SCA能夠生成一條與真實路徑具有一定相似度的群體掃視路徑。對SCA進行改進的獨立處理不同注視興趣子區域的DFS 方法,在MultiMatch 的掃視路徑形狀、方向、長度和注視點位置指標上,以及ScanMatch 的兩項指標上都取得了一定的提升,實驗數據驗證了考慮注視興趣區域的不同注視行為,生成的群體掃視路徑會更加貼合真實掃視路徑。
其次,將SCA、DFS 方法與網頁場景方法eMine[9]、STA[11]、SPAM[20]對比可以發現,網頁場景的生成方法不適用于自然場景的復雜情況,需要研究針對自然場景情形的方法。
最后,將SCA、DFS 方法與自然場景方法CDBA[15]、Heuristic[16]對比。由相關工作及評價指標的介紹可知,CDBA[15]、Heuristic[16]是基于篩選最佳對齊向量的生成方法,MultiMatch 是僅衡量對齊部分子向量平均相似度的指標,理論上這兩種方法的MultiMatch 指標應該最優。通過觀察可以發現,SCA 和DFS 方法在興趣區域眾多、圖像較復雜的MIT1003 數據集上表現優于其他方法,初步判斷原因在于本文聚類獲取的注視興趣區域結果較好,本文生成路徑考慮的興趣區域更全面、轉移模式更詳細,生成路徑與真實個體路徑達到了較好的對齊效果,得到了較高的對齊子路徑平均相似度。ScanMatch 指標上,不考慮時間因素時,DFS 方法的生成路徑可以取得與真實路徑較高的對齊分數,說明生成路徑的注視區域和注視順序與真實路徑相似;考慮時間因素時,對齊分數有所降低,是因為DFS 方法將篩得所有興趣子區域的時長直接疊加,生成路徑總時長超過了真實觀察時長,導致生成路徑未能與真實路徑較好對齊,影響了最終的評價結果。DFS生成方法的時間策略有欠合理,有待繼續改進。
5 結語
本文研究自然場景中人類的注視注意,通過分析同一刺激樣本下多名觀察者的眼動數據,提出了基于注視興趣區域聚類和轉移的群體掃視路徑生成方法。可視化及指標結果表明所提方法的生成路徑能夠貼合群體觀察者的實際的眼動行為且具有一定的表征能力。今后的工作中,會繼續改進生成方法使之更好地適用于不同的數據集,提升模型的魯棒性;繼續研究合理的時間生成策略使之更好地貼近真實視覺注視和轉移,提升模型的精確性;研究針對掃視路徑的評價指標,探索新的評價方法。
猜你喜歡
今日農業(2021年9期)2021-11-26 07:41:24
發明與創新·小學生(2021年3期)2021-03-25 11:48:49
兒童故事畫報(2019年5期)2019-05-26 14:26:14
意林原創版(2016年10期)2016-11-25 10:28:30
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
