基于區(qū)塊鏈技術(shù)的多維大數(shù)據(jù)交互式查詢方法分析
2021-01-21 12:35:16段平
電子設(shè)計工程 2021年1期
關(guān)鍵詞:數(shù)據(jù)庫信息
段平
(西北工業(yè)大學計算機學院,陜西 西安 710072)
區(qū)塊鏈是信息技術(shù)領(lǐng)域的專業(yè)術(shù)語,從數(shù)據(jù)本質(zhì)角度來講,它屬于一種標準化共享數(shù)據(jù)庫,能公開追溯存儲信息或數(shù)據(jù)的具體來源,具有公開性、透明性、維護性、集體性等多項應用特征。在分布式數(shù)據(jù)存儲空間內(nèi),區(qū)塊鏈是屬于比特幣技術(shù)的重要物理概念,可在加密算法、共識機制等應用模式的支持下,去除位于數(shù)據(jù)庫中間位置的特征信息,再聯(lián)合底層比特處置技術(shù),生成一連串與查詢密碼相關(guān)的數(shù)據(jù)塊組織,從而使每一個區(qū)塊單元都能獲得一個獨立的信息交互密碼本[1-2]。
通常情況下,隨著數(shù)據(jù)存儲量水平的提升,既定信息之間調(diào)取與應用會受到查詢密碼條件的影響,從而導致數(shù)據(jù)傳輸準確性不斷下降。為解決上述問題,傳統(tǒng)MySQL數(shù)據(jù)庫查詢方法通過信息分級處理的方式,建立必要索引條件,再根據(jù)已存儲文檔的結(jié)構(gòu)類型,生成符合大數(shù)據(jù)分析需求的查詢語句。但該方法匹配的信息調(diào)取占用時間過長,針對此問題,設(shè)計基于區(qū)塊鏈技術(shù)的多維大數(shù)據(jù)交互式查詢方法。在NoSQL多維數(shù)據(jù)庫、Limit FIFO交互調(diào)度器等硬件設(shè)備結(jié)構(gòu)的支持下,配置必要的關(guān)聯(lián)查詢系數(shù),達到增強既定信息調(diào)取精準性的目的。
1 基于區(qū)塊鏈技術(shù)的多維大數(shù)據(jù)遷移調(diào)度
基于區(qū)塊鏈技術(shù)的多維大數(shù)據(jù)遷移調(diào)度包含NoSQL數(shù)據(jù)庫連接、遷移引擎設(shè)置和調(diào)度節(jié)點牽引3個必要步驟,具體操作及處理方法如下。
1.1 NoSQL多維數(shù)據(jù)庫
NoSQL多維數(shù)據(jù)庫是實現(xiàn)大數(shù)據(jù)交互式查詢的重要應用元件,由上層主機、中層多維數(shù)據(jù)結(jié)構(gòu)、下層處置設(shè)備共同組成。其中,NoSQL主機、區(qū)塊鏈主機作為頂層查詢指令生成設(shè)備,可按照多維大數(shù)據(jù)的實際傳輸需求,分布交互式節(jié)點所處位置,同時將區(qū)塊鏈信息參量傳輸至多維數(shù)據(jù)層結(jié)構(gòu)之中[3]。下層處置結(jié)構(gòu)包含數(shù)據(jù)交互設(shè)備、數(shù)據(jù)查詢設(shè)備、信息集成設(shè)備3類應用元件。在信息集成設(shè)備保持交互式傳輸行為的情況下,數(shù)據(jù)交互設(shè)備會自發(fā)建立與數(shù)據(jù)查詢設(shè)備的物理連接,從而縮短相鄰數(shù)據(jù)節(jié)點間的傳輸距離,縮短調(diào)取既定信息占用的時間[4-5]。
1.2 大數(shù)據(jù)遷移引擎
大數(shù)據(jù)遷移引擎是與NoSQL多維數(shù)據(jù)庫相匹配的區(qū)塊鏈應用元件,具有MyISAM、InnoDB、MEMORY、MERGE、NDB 5種常見型號。從常規(guī)存儲權(quán)限的角度來看,InnoDB遷移引擎的信息承載能力最弱,僅能達到64 TB;MERGE遷移引擎的信息承載能力最強,在實際查詢過程中有時可超過1 024 TB。NDB遷移引擎支持的多維大數(shù)據(jù)結(jié)構(gòu)體類型相對較少,設(shè)置多個獨立的交互式索引條件,僅允許區(qū)塊鏈信息在個別NoSQL數(shù)據(jù)庫空間內(nèi)自由連接[6-7]。表1反映了必要的大數(shù)據(jù)遷移引擎設(shè)置條件。
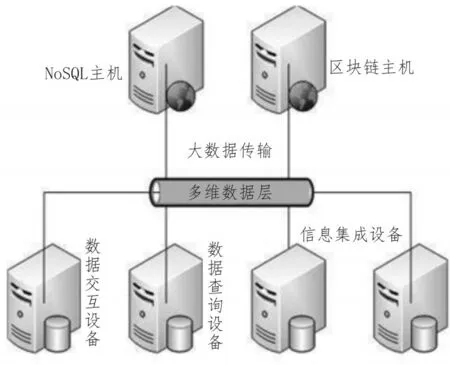
圖1 NoSQL多維數(shù)據(jù)庫連接原理

表1 大數(shù)據(jù)遷移引擎設(shè)置條件
1.3 區(qū)塊鏈調(diào)度節(jié)點牽引
在多維大數(shù)據(jù)環(huán)境下,區(qū)塊鏈調(diào)度牽引是實現(xiàn)查詢節(jié)點交互式協(xié)調(diào)的重要處理手段,能根據(jù)一個特定信息的基礎(chǔ)查詢效率,推斷完成既定信息調(diào)取的理想占用時長,從而實現(xiàn)對交互數(shù)據(jù)結(jié)構(gòu)的讀取與調(diào)用。節(jié)點牽引組織是一個相對獨立的區(qū)塊鏈數(shù)據(jù)結(jié)構(gòu),可按照多維數(shù)據(jù)庫中列表信息的排列順序,建立與交互式查詢行為相關(guān)的結(jié)構(gòu)主體,再根據(jù)區(qū)塊鏈存儲位置處的數(shù)值注明條件,轉(zhuǎn)存查詢處置所必須的大數(shù)據(jù)結(jié)構(gòu)信息,從而滿足既定信息的精準調(diào)取應用條件[8-9]。在不考慮其他調(diào)度節(jié)點牽引因素的情況下,設(shè)y代表大數(shù)據(jù)參量的多維計數(shù)條件,β代表區(qū)塊鏈組織所承載的大數(shù)據(jù)查詢調(diào)度系數(shù),聯(lián)立上述物理量,可將區(qū)塊鏈調(diào)度節(jié)點的牽引公式定義為:
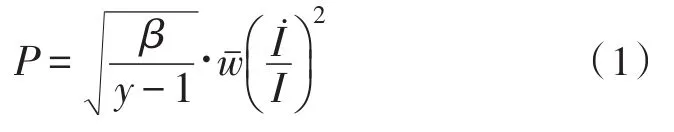
2 多維大數(shù)據(jù)交互式查詢方法
在區(qū)塊鏈技術(shù)原理的支持下,設(shè)置Limit FIFO交互調(diào)度器,通過多維大數(shù)據(jù)流集成、關(guān)聯(lián)查詢系數(shù)配置的處理流程,完成基于區(qū)塊鏈技術(shù)的多維大數(shù)據(jù)交互式查詢方法的搭建。
2.1 Limit FIFO交互調(diào)度器
Limit FIFO交互調(diào)度器可根據(jù)區(qū)塊鏈組織間的調(diào)度節(jié)點牽引關(guān)系,建立合理的大數(shù)據(jù)查詢集合[10]。在n個多維大數(shù)據(jù)源同時向Limit FIFO設(shè)備輸出待查詢信息的情況下,交互節(jié)點與調(diào)度節(jié)點會自發(fā)建立與數(shù)據(jù)交互層結(jié)構(gòu)和調(diào)度處理層結(jié)構(gòu)的物理連接,存在于兩個層級單元中的Job節(jié)點會根據(jù)信息參量的數(shù)量級水平,更改連接所處的具體位置條件,再通過協(xié)調(diào)相鄰節(jié)點間位移權(quán)限的方式,來滿足不同大數(shù)據(jù)信息的交互式查詢需求。完成交互調(diào)度處理后,Limit FIFO設(shè)備會以區(qū)塊鏈處置的方式,將多維信息轉(zhuǎn)化成大數(shù)據(jù)腳本,以供其他設(shè)備元件的調(diào)取與應用[11-12]。
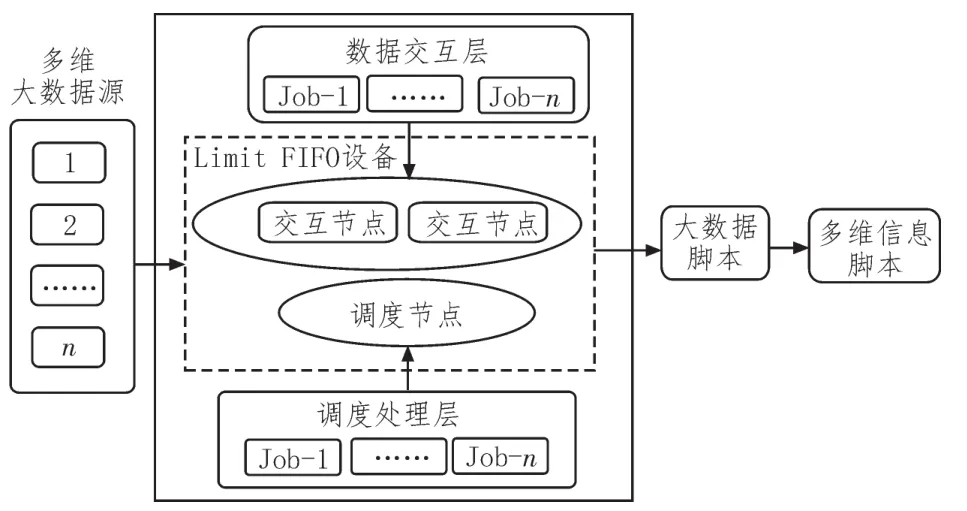
圖2 Limit FIFO交互調(diào)度器結(jié)構(gòu)圖
2.2 多維大數(shù)據(jù)流集成
多維大數(shù)據(jù)流集成可按照區(qū)塊鏈信息的連接方式,更改待查詢參量的排列行為,從而滿足交互式處置的基本應用需求。假設(shè)多維信息始終保持由起始位置指向結(jié)束位置的傳輸方向,則可將大數(shù)據(jù)流集成操作轉(zhuǎn)化為Table節(jié)點、External節(jié)點、Partition節(jié)點間的查詢關(guān)系已確定[13-14]。若區(qū)塊鏈組織的交互傳輸關(guān)系始終保持穩(wěn)定,Table節(jié)點可直接作為多維大數(shù)據(jù)的起始查詢位置,且在External節(jié)點的促進下,交互式查詢結(jié)構(gòu)會變更至Partition節(jié)點所在位置,并釋放暫存于其中的待處理參量信息,直至最終輸出的多維大數(shù)據(jù)能夠保持穩(wěn)定的柱狀流體狀態(tài)。圖3反映了完整的多維大數(shù)據(jù)流集成處理流程。
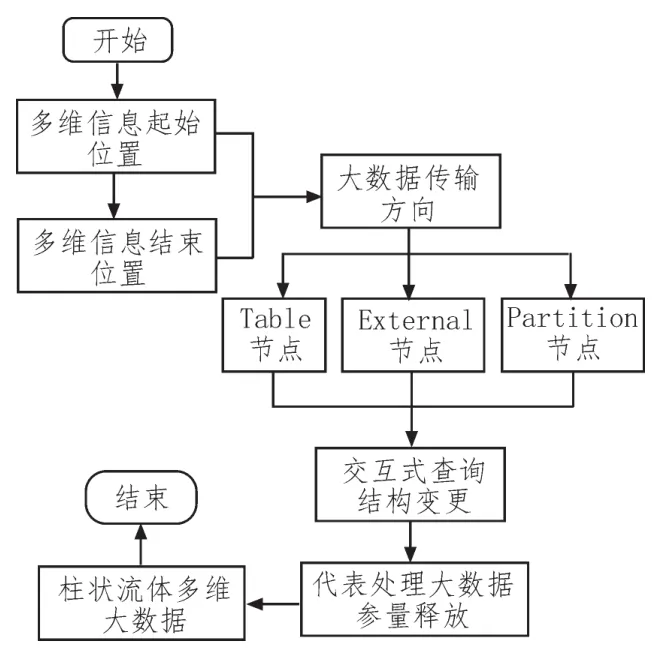
圖3 多維大數(shù)據(jù)流集成處理流程圖
2.3 關(guān)聯(lián)查詢系數(shù)配置
關(guān)聯(lián)查詢系數(shù)配置是多維大數(shù)據(jù)交互式查詢方法的末尾處理環(huán)節(jié),可在區(qū)塊鏈調(diào)度節(jié)點牽引關(guān)系的促進下,計算多級維度條件的最大和最小限定系數(shù)[15]。在不考慮既定信息集成作用的前提下,關(guān)聯(lián)查詢系數(shù)配置結(jié)果只受到大數(shù)據(jù)存儲總量及區(qū)塊鏈交互系數(shù)的直接影響[16]。區(qū)塊鏈交互系數(shù)常表示為f,在大數(shù)據(jù)查詢處理過程中,該項物理量的數(shù)值水平始終保持穩(wěn)定,且能夠促進交互式處理信息出現(xiàn)明顯的累積變化行為。聯(lián)立式(1),可將關(guān)聯(lián)查詢系數(shù)的配置結(jié)果表示為:
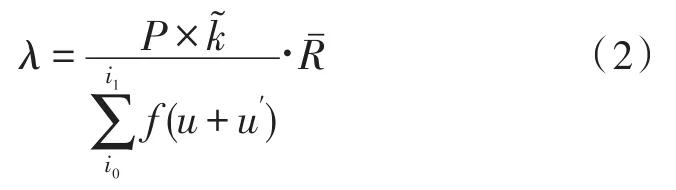
式(2)中,i0代表多維大數(shù)據(jù)的下限極值條件,i1代表多維大數(shù)據(jù)的上限極值條件,u代表大數(shù)據(jù)流的平均集成系數(shù),u′代表Limit FIFO交互調(diào)度器所承載的交互式查詢系數(shù),代表大數(shù)據(jù)遷移引擎的調(diào)度權(quán)限平均值。至此,完成基礎(chǔ)執(zhí)行環(huán)境建立及各項指標參數(shù)計算,在區(qū)塊鏈組織結(jié)構(gòu)的支持下,實現(xiàn)多維大數(shù)據(jù)交互式查詢方法的順利應用。
3 應用實效性檢測
為驗證基于區(qū)塊鏈技術(shù)多維大數(shù)據(jù)交互式查詢方法的實際應用價值,設(shè)計如下對比實驗。在海量數(shù)據(jù)存儲環(huán)境下,選取存儲波長完全相同的多維大數(shù)據(jù)作為實驗對象,分別以搭載交互式查詢方法和傳統(tǒng)MySQL數(shù)據(jù)庫查詢行為的檢測計算機作為實驗組、對照組數(shù)值記錄元件,在相同實驗環(huán)境下,根據(jù)實驗指標的具體變化情況,分析信息傳輸?shù)臏蚀_性、信息調(diào)取占用時間的實際表現(xiàn)行為。
3.1 實用環(huán)境搭建
以圖4所示數(shù)據(jù)生成主機作為海量數(shù)據(jù)提供元件,再借助傳輸導線,將多維信息參量導入圖5所示的查詢控制設(shè)備中,更改支配主機的數(shù)據(jù)查詢方法,分別獲取實驗組、對照組的實驗數(shù)據(jù)指標。

圖4 數(shù)據(jù)生成主機

圖5 查詢控制設(shè)備
3.2 信息傳輸準確性
以75 min作為實驗時長,分別記錄在該段時間內(nèi),實驗組、對照組信息傳輸準確性的數(shù)值變化情況,實驗詳情如圖6所示。
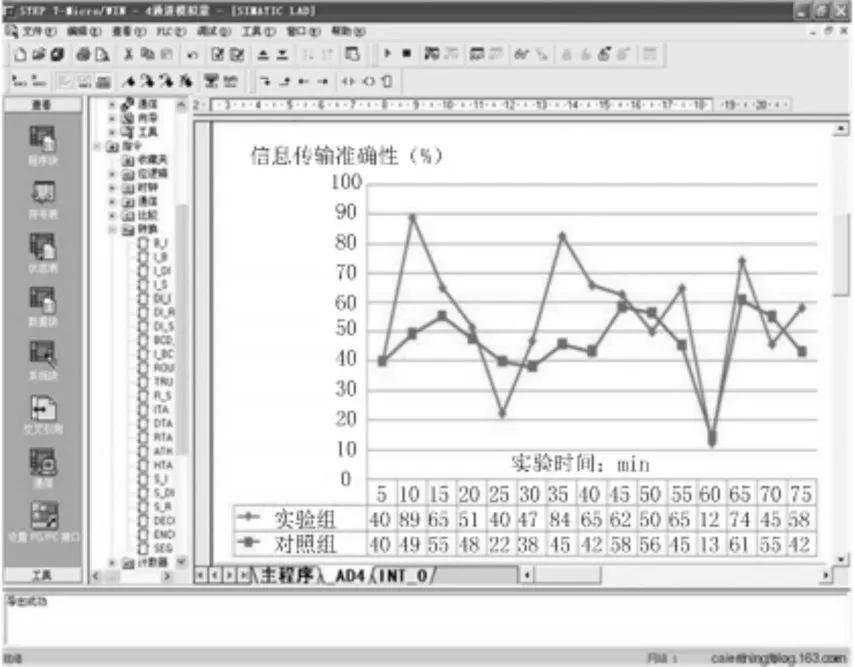
圖6 信息傳輸準確性對比圖
分析圖6可知,實驗組、對照組信息傳輸準確性均保持上升、下降交替出現(xiàn)的變化趨勢,從極大值角度來看,實驗組數(shù)值達到89%,而對照組數(shù)值僅達到58%,二者差值為31%;從平均值角度來看,實驗組數(shù)值接近55%,而對照組數(shù)值僅為45%,二者差值為10%。綜上可知,應用基于區(qū)塊鏈技術(shù)多維大數(shù)據(jù)交互式查詢方法,能夠在一定程度上提升信息傳輸?shù)臏蚀_性。
3.3 信息調(diào)取占用時間
分別記錄大數(shù)據(jù)總量處于1×109~9×109T時,信息調(diào)取占用時間的具體變化情況,實驗詳情如表2所示。
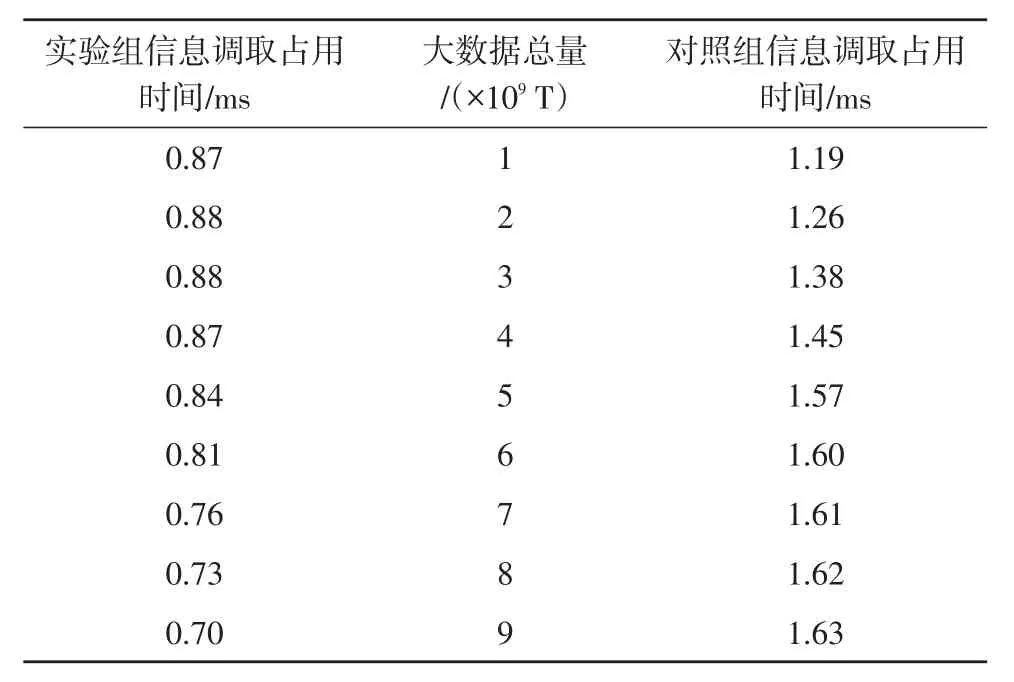
表2 信息調(diào)取占用時間對比表
分析表2可知,隨著大數(shù)據(jù)總量數(shù)值的增加,實驗組信息調(diào)取占用時間先小幅度波動、再持續(xù)下降,全局最大值僅達到0.88 ms;對照組信息調(diào)取占用時間則始終保持不斷上升的變化趨勢,全局最大值達到1.63 ms,遠高于實驗組極值水平。綜上可知,應用基于區(qū)塊鏈技術(shù)多維大數(shù)據(jù)交互式查詢方法,可有效降低信息調(diào)取所需的基礎(chǔ)占用時間。
4 結(jié)束語
在區(qū)塊鏈技術(shù)的支持下,多維大數(shù)據(jù)交互式查詢方法在傳統(tǒng)MySQL數(shù)據(jù)庫查詢行為的基礎(chǔ)上,聯(lián)合大數(shù)據(jù)遷移引擎、Limit FIFO調(diào)度器等執(zhí)行設(shè)備,同時實現(xiàn)數(shù)據(jù)流量的集成與節(jié)點組織的牽引。從實用角度來看,信息傳輸準確性與信息調(diào)取占用時間均向著理想化方向發(fā)展,海量數(shù)據(jù)存儲環(huán)境下,既定信息應用調(diào)取不精準的問題也得到了有效解決。
猜你喜歡
財經(jīng)(2017年15期)2017-07-03 22:40:49
中華手工(2017年2期)2017-06-06 23:00:31
財經(jīng)(2017年2期)2017-03-10 14:35:35
財經(jīng)(2016年15期)2016-06-03 07:38:02
財經(jīng)(2016年3期)2016-03-07 07:44:46
財經(jīng)(2016年6期)2016-02-24 07:41:51
中外會展(2014年4期)2014-11-27 07:46:46
財經(jīng)(2010年20期)2010-10-19 01:48:32
建筑創(chuàng)作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
