基于Hadoop技術(shù)的挖泥船大數(shù)據(jù)平臺架構(gòu)研究
2021-01-21 12:35:24朱逸峰蘇貞葉樹霞
電子設(shè)計(jì)工程 2021年1期
朱逸峰,蘇貞,葉樹霞
(江蘇科技大學(xué)電子信息學(xué)院,江蘇 鎮(zhèn)江 212003)
疏浚裝備越來越發(fā)展成為大國角力,是提升遠(yuǎn)海島礁建設(shè)、海洋維權(quán)、港口航道、填海造陸和海洋工程建設(shè)能力的國之重器,更是貫徹落實(shí)國家“交通強(qiáng)國”、“海洋強(qiáng)國戰(zhàn)略”和“一帶一路”倡議的重要保障[1]。疏浚裝備的升級使得挖泥船疏浚作業(yè)數(shù)據(jù)呈現(xiàn)爆炸式地增長,存儲在計(jì)算機(jī)內(nèi)的疏浚數(shù)據(jù)量日益龐大。來自船載服務(wù)器與岸端船舶管理平臺中存儲的海量歷史數(shù)據(jù),數(shù)據(jù)量可達(dá)數(shù)TB,甚至PB,如何高效存儲、提取和處理這些寶貴的疏浚數(shù)據(jù)成為了疏浚大數(shù)據(jù)分析亟待解決的問題,目前對于船舶大數(shù)據(jù)的應(yīng)用分析還在探索階段,海量施工數(shù)據(jù)沒有得到有效的分析和利用。我國作為疏浚大國,急需在疏浚大數(shù)據(jù)分析方面取得進(jìn)展,為安全、高效和智能的疏浚提供支持,通過搭建大數(shù)據(jù)平臺實(shí)現(xiàn)疏浚作業(yè)在線分析與決策,可有效解決因作業(yè)環(huán)境復(fù)雜和操耙手經(jīng)驗(yàn)不足導(dǎo)致的疏浚效率不高等問題。
1 現(xiàn)狀分析
疏浚行業(yè)飛速發(fā)展,挖泥船數(shù)據(jù)采集技術(shù)日益先進(jìn),使得挖泥船疏浚作業(yè)數(shù)據(jù)呈現(xiàn)爆炸式地增長。疏浚船舶上搭載的DTPM模塊、SCADA監(jiān)測模塊、AMS報警模塊、AIS識別模塊和電子海圖模塊,在每日挖泥船施工時所采集的數(shù)據(jù)量非常之大,類型非常之多;這些挖泥船所采集的數(shù)據(jù)存儲在挖泥船的船載服務(wù)器及各個航道局的服務(wù)器之中,這些服務(wù)器大多數(shù)仍使用傳統(tǒng)的關(guān)系型數(shù)據(jù)庫對數(shù)據(jù)進(jìn)行存儲[2]。面對海量的疏浚數(shù)據(jù),傳統(tǒng)的關(guān)系型數(shù)據(jù)庫對于如何存儲并處理疏浚大數(shù)據(jù)越來越力不從心;各個航道局的疏浚船舶相對的獨(dú)立運(yùn)行,使得海量的疏浚信息是相對封閉的,難以進(jìn)行共享交換,無法整合所有采集到的數(shù)據(jù)并從中快速挖掘出疏浚規(guī)律。
針對上述的疏浚船舶數(shù)據(jù)現(xiàn)狀,疏浚船舶大數(shù)據(jù)平臺建設(shè)需要滿足各個航道局存儲并分析處理海量結(jié)構(gòu)化疏浚數(shù)據(jù)的需求,同時遵循安全高效、高拓展性、低冗余性的原則,并且建立將各個航道局的疏浚數(shù)據(jù)進(jìn)行更新與共享機(jī)制。
隨著大數(shù)據(jù)技術(shù)的不斷發(fā)展,基于Hadoop分布式框架平臺的海量數(shù)據(jù)處理技術(shù)為解決疏浚船舶大數(shù)據(jù)處理提供了思路和方法[3]。Hadoop作為大規(guī)模分布式數(shù)據(jù)處理最廣泛使用的平臺,對于結(jié)構(gòu)化、半結(jié)構(gòu)化和非結(jié)構(gòu)化數(shù)據(jù)都提供了一套安全高效的解決方案[4]。如何借助大數(shù)據(jù)技術(shù)幫助疏浚行業(yè)從海量疏浚數(shù)據(jù)中挖掘出隱藏價值,是該文需要解決的問題。
2 挖泥船大數(shù)據(jù)平臺架構(gòu)設(shè)計(jì)
基于對大批量疏浚數(shù)據(jù)統(tǒng)計(jì)和分析處理的考慮,挖泥船大數(shù)據(jù)平臺有如下3個模塊,分別為疏浚數(shù)據(jù)采集模塊、疏浚數(shù)據(jù)存儲模塊和疏浚數(shù)據(jù)分析模塊;其中疏浚數(shù)據(jù)采集模塊用于對疏浚數(shù)據(jù)進(jìn)行采集與加工;疏浚數(shù)據(jù)存儲模塊用于對疏浚數(shù)據(jù)進(jìn)行存儲與處理;疏浚數(shù)據(jù)分析模塊用于對疏浚數(shù)據(jù)進(jìn)行分析計(jì)算。疏浚數(shù)據(jù)分析模塊分析處理過的數(shù)據(jù)系統(tǒng)會將其推送給不同的用戶終端,并將這些信息進(jìn)行匯總、整理,實(shí)現(xiàn)業(yè)務(wù)應(yīng)用層面的數(shù)據(jù)共享,并提供共享的數(shù)據(jù)接口服務(wù),從而實(shí)現(xiàn)疏浚數(shù)據(jù)的共享與服務(wù)。挖泥船大數(shù)據(jù)平臺架構(gòu)如圖1所示。
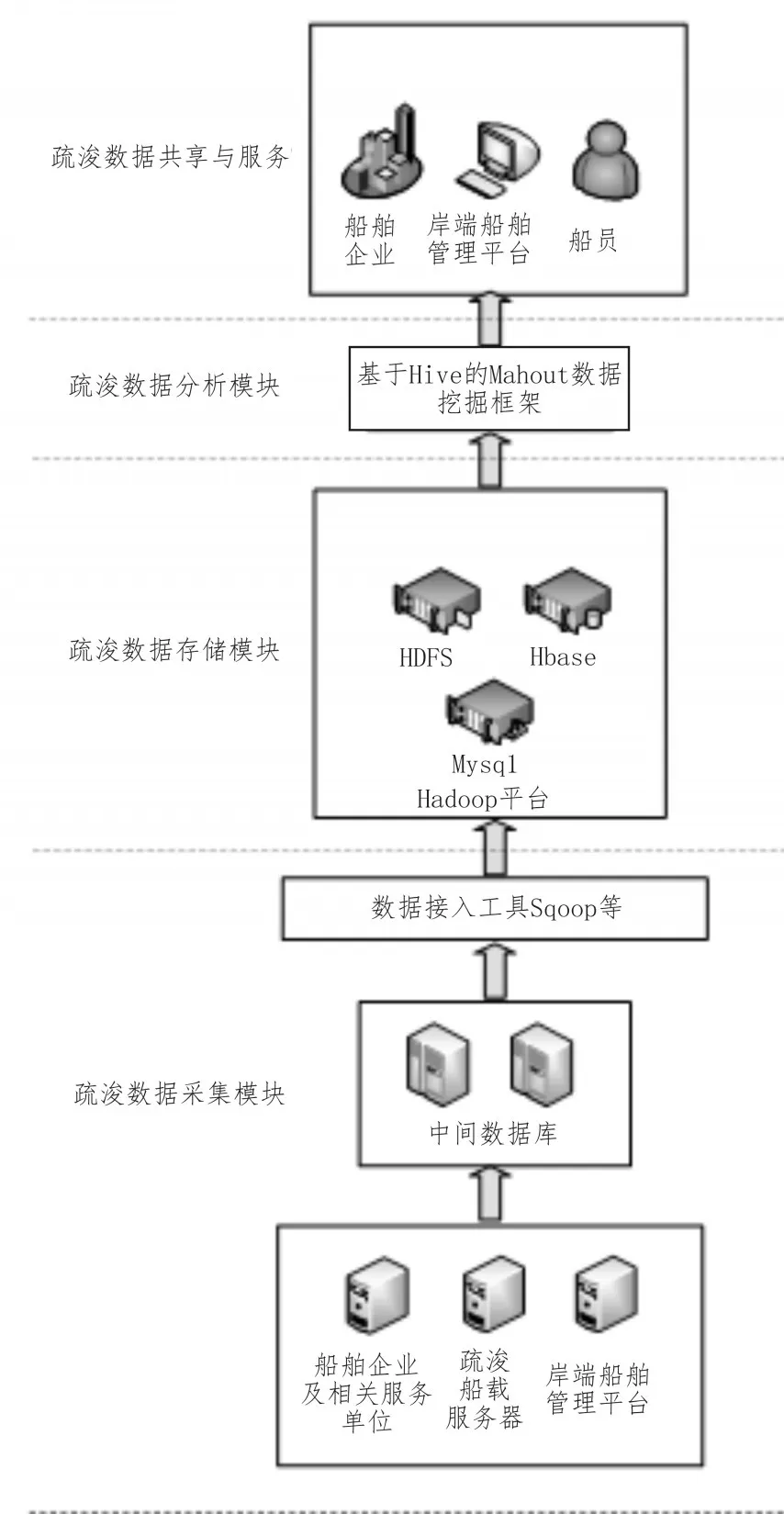
圖1 挖泥船大數(shù)據(jù)平臺架構(gòu)圖
3 挖泥船大數(shù)據(jù)平臺數(shù)據(jù)采集模塊
挖泥船大數(shù)據(jù)平臺數(shù)據(jù)采集模塊的任務(wù)是對挖泥船施工作業(yè)、航行等時刻的數(shù)據(jù)進(jìn)行采集,由兩個子模塊組成:挖泥船端數(shù)據(jù)采集模塊與異源數(shù)據(jù)庫采集模塊;挖泥船端數(shù)據(jù)采集模塊主要是船載服務(wù)器;異源數(shù)據(jù)庫采集模塊則負(fù)責(zé)采集各個航道局、船舶企業(yè)及相關(guān)單位服務(wù)器中的數(shù)據(jù),進(jìn)行實(shí)時或者定期的數(shù)據(jù)同步與交換。
3.1 船端大數(shù)據(jù)采集
在挖泥船進(jìn)行施工過程和航行過程中,數(shù)據(jù)采集系統(tǒng)會實(shí)時進(jìn)行數(shù)據(jù)采集。傳感器信號通過以太網(wǎng)絡(luò)將數(shù)據(jù)發(fā)送到船載服務(wù)器;船載服務(wù)器一方面在本地經(jīng)分析處理后存儲到本地數(shù)據(jù)庫[5],另一方面經(jīng)過篩選壓縮處理后的有效數(shù)據(jù)通過4G或衛(wèi)星通訊與云端服務(wù)器通訊連接,實(shí)時地將數(shù)據(jù)發(fā)送至云端服務(wù)器[6]。
3.2 異源數(shù)據(jù)庫采集
對于來源于分布在各地、各單位的異源數(shù)據(jù)庫中的海量數(shù)據(jù),需要進(jìn)行實(shí)時或者定期的數(shù)據(jù)同步與交換,然而這些異源數(shù)據(jù)庫任然是傳統(tǒng)的關(guān)系型數(shù)據(jù)庫RDBMS,需要用專門的數(shù)據(jù)接口進(jìn)行數(shù)據(jù)接入[7]。基于對上述原因的考慮,挖泥船大數(shù)據(jù)平臺數(shù)據(jù)采集模塊集成了Sqoop、Flume等數(shù)據(jù)接入工具對多源異構(gòu)數(shù)據(jù)進(jìn)行接入。Sqoop與Flume是基于Hadoop生態(tài)圈的數(shù)據(jù)接入工具,專門用于傳統(tǒng)數(shù)據(jù)庫和Hadoop之間傳輸數(shù)據(jù),通過數(shù)據(jù)庫技術(shù)描述數(shù)據(jù)架構(gòu),從而在關(guān)系數(shù)據(jù)庫、數(shù)據(jù)倉庫和Hadoop之間轉(zhuǎn)移數(shù)據(jù)[8]。
數(shù)據(jù)采集模塊設(shè)置有中間數(shù)據(jù)庫,在將海量數(shù)據(jù)從異源數(shù)據(jù)庫中接入之后,中間數(shù)據(jù)庫起到將所有數(shù)據(jù)從傳統(tǒng)數(shù)據(jù)庫導(dǎo)入到疏浚數(shù)據(jù)存儲模塊的過渡作用[9];疏浚數(shù)據(jù)采集模塊將分布的、異構(gòu)數(shù)源中的數(shù)據(jù)抽取到臨時中間層后進(jìn)行清洗、轉(zhuǎn)換、集成,最后加載到疏浚數(shù)據(jù)存儲模塊[10]。
4 挖泥船大數(shù)據(jù)平臺數(shù)據(jù)存儲模塊
疏浚數(shù)據(jù)存儲模塊對采集到的船舶自身信息、設(shè)備狀態(tài)信息、環(huán)境信息、工程管理信息等進(jìn)行存儲處理。疏浚數(shù)據(jù)存儲模塊具有高擴(kuò)展性的分布式存儲結(jié)構(gòu),存儲模塊以Hadoop分布式系統(tǒng)HDFS為底層存儲,是具有分布式可擴(kuò)展、高容錯、高吞吐量的體系結(jié)構(gòu),提供層次化的存儲和計(jì)算服務(wù)[11],可提高大數(shù)據(jù)管理平臺的可擴(kuò)展性和可靠性。此外,疏浚數(shù)據(jù)存儲模塊集成了分布式數(shù)據(jù)庫Hbase和數(shù)據(jù)倉庫Hive,具備了海量非結(jié)構(gòu)化數(shù)據(jù)存儲能力和結(jié)構(gòu)化數(shù)據(jù)挖掘能力[6]。疏浚數(shù)據(jù)存儲模塊使用mysql存儲用戶信息;利用高度容錯性能并且能提供高吞吐量的數(shù)據(jù)訪問,非常適合大規(guī)模數(shù)據(jù)集上的HDFS文件系統(tǒng)存儲文件;使用高可靠性、高性能、面向列、可伸縮的分布式數(shù)據(jù)庫HBase對不同數(shù)據(jù)類型的異構(gòu)數(shù)據(jù)進(jìn)行加載存儲[12],并用一種<key,value>形式處理不同數(shù)據(jù),并且高效解決數(shù)據(jù)后臺處理需求,同時集成分布式應(yīng)用程序協(xié)調(diào)服務(wù)Zookeeper為HBase提供了穩(wěn)定服務(wù)和失效轉(zhuǎn)移機(jī)制。
5 挖泥船大數(shù)據(jù)平臺數(shù)據(jù)分析模塊
疏浚大數(shù)據(jù)在經(jīng)過初步的ETL之后存儲到存儲模塊,此時分析模塊將對海量數(shù)據(jù)進(jìn)行分析計(jì)算與數(shù)據(jù)挖掘。基于對大批量數(shù)據(jù)統(tǒng)計(jì)和分析的考慮,選用建立在Hadoop生態(tài)圈上的Hive進(jìn)行離線分析[13]。分析任務(wù)大致有性能指標(biāo)計(jì)算、分區(qū)計(jì)算、標(biāo)準(zhǔn)化計(jì)算和工藝點(diǎn)提取等;經(jīng)過HIVE分析處理后提取出來的工藝點(diǎn)選用建立在Hadoop生態(tài)圈上的Mahout進(jìn)行數(shù)據(jù)挖掘,并基于KMeans算法進(jìn)行疏浚評估分析工作。
5.1 基于Hive的挖泥船大數(shù)據(jù)離線分析
Hive作為數(shù)據(jù)倉庫的同時,也提供了對于海量數(shù)據(jù)進(jìn)行統(tǒng)計(jì)分析的技術(shù)。Hive的核心機(jī)制是HQL語言,其原理類似于SQL語言,并將這些語言轉(zhuǎn)化為MapReduce程序,從而在分布式計(jì)算機(jī)集群上進(jìn)行執(zhí)行。因此,Hive十分適合對于海量數(shù)據(jù)集進(jìn)行統(tǒng)計(jì)計(jì)算。基于Hive的挖泥船大數(shù)據(jù)離線分析的步驟為:1)分區(qū)處理;2)產(chǎn)量指標(biāo)計(jì)算;3)工藝點(diǎn)提取;4)標(biāo)準(zhǔn)化計(jì)算。
5.1.1 數(shù)據(jù)分區(qū)處理
挖泥船在進(jìn)行疏浚作業(yè)的過程中,有兩個最重要的階段:裝艙階段和溢流階段[14]。這兩個階段的施工工藝不同,性能指標(biāo)不同,因而需要進(jìn)行分區(qū)處理,即分為裝艙區(qū)數(shù)據(jù)和溢流區(qū)數(shù)據(jù)。然而從挖泥船端采集來的數(shù)據(jù)是連續(xù)的,即挖泥船從開始挖泥到拋泥結(jié)束的全階段數(shù)據(jù),需要對存儲在平臺中的全階段數(shù)據(jù)進(jìn)行分區(qū)計(jì)算,并將數(shù)據(jù)分區(qū)之后再進(jìn)行下一步分析。
Hive提供了允許用戶擴(kuò)展HQL的強(qiáng)大功能,即用戶自定義函數(shù)(UDF)。用戶通過JAVA編寫用戶自定義函數(shù),從而滿足自身的需求。一旦將UDF加入到Hive的交互式界面,就可以和使用內(nèi)置函數(shù)一樣地使用用戶自定義函數(shù)。針對上述的分區(qū)需求,通過編寫用戶自定義函數(shù)來判斷溢流筒的位置,當(dāng)滿足溢流的條件時即判斷疏浚過程進(jìn)行到了溢流階段并將數(shù)據(jù)放入到溢流分區(qū)。Hive的分區(qū)表通過指定partition字段進(jìn)行分區(qū),在創(chuàng)建表的時候就創(chuàng)建了兩個分區(qū),即裝艙區(qū)和溢流區(qū)。經(jīng)過分區(qū)處理的數(shù)據(jù)以一種符合邏輯的方式進(jìn)行組織,并且也提高了查詢的性能,從而為進(jìn)一步分析及后面的數(shù)據(jù)挖掘做好了準(zhǔn)備。
5.1.2 產(chǎn)量指標(biāo)計(jì)算
經(jīng)過分區(qū)處理后的數(shù)據(jù)需要進(jìn)行產(chǎn)量指標(biāo)計(jì)算,用于后面基于Mahout的數(shù)據(jù)挖掘的聚類得到的簇評價分析、質(zhì)量評估等。產(chǎn)量指標(biāo)為干土噸生產(chǎn)率、泥沙存儲率、干土噸質(zhì)量比[15]。
根據(jù)上述的產(chǎn)量指標(biāo),通過JAVA編寫對應(yīng)的用戶自定義函數(shù),計(jì)算得到的指標(biāo)值作為新列存儲在原表中。
5.1.3 工藝點(diǎn)提取
依據(jù)疏浚作業(yè)判定,以分鐘為單位從分區(qū)表提取以下工藝點(diǎn)信息:船速、泥泵轉(zhuǎn)速、泥泵吸入真空、溢流筒高度和耙頭對地角度。通過HQL的Select查詢語句從分區(qū)表中獲取工藝點(diǎn)信息的字段并創(chuàng)建一張新表用于存儲工藝點(diǎn)。提取出的工藝點(diǎn)與原表中的數(shù)據(jù)分開存儲,從而提高后續(xù)基于Mahout數(shù)據(jù)挖掘時查詢與計(jì)算的效率。
5.1.4 歸一化處理
提取出來的工藝點(diǎn)在進(jìn)行數(shù)據(jù)挖掘之前需要進(jìn)行歸一化處理,從而消除工藝點(diǎn)信息之間的量綱影響,并解決數(shù)據(jù)指標(biāo)之間的可比性。原始工藝點(diǎn)數(shù)據(jù)經(jīng)過數(shù)據(jù)標(biāo)準(zhǔn)化處理后,各指標(biāo)處于同一數(shù)量級,適合進(jìn)行綜合對比評價[16]。以提取出的左泥泵壓力(bar)、左泥泵真空(bar)、左泥泵轉(zhuǎn)速(rpm)、左波浪補(bǔ)償器壓力(bar)、左耙頭對地角度(°)、右泥泵壓力(bar)、右泥泵真空(bar)、右泥泵轉(zhuǎn)速(rpm)、右波浪補(bǔ)償器壓力(bar)、右耙頭對地角度(°)為10個分析維度,使用Z分?jǐn)?shù)法進(jìn)行歸一化處理,處理后的數(shù)據(jù)格式如圖2所示。
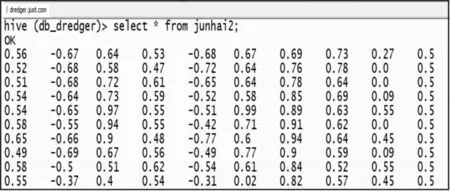
圖2 歸一化后的數(shù)據(jù)格式
5.2 基于Mahout的數(shù)據(jù)挖掘分析
Mahout是建立在Apache的Hadoop分布式計(jì)算上的一個分布式數(shù)據(jù)挖掘框架,它旨在當(dāng)所處理的數(shù)據(jù)規(guī)模遠(yuǎn)大于傳統(tǒng)數(shù)據(jù)分析軟件所能夠承受時,作為一種可選的機(jī)器學(xué)習(xí)工具。通過Mahout,可以實(shí)現(xiàn)許多數(shù)據(jù)挖掘領(lǐng)域的機(jī)器學(xué)習(xí)算法,如協(xié)同過濾、聚類和分類等,并且將其應(yīng)用在處理大數(shù)據(jù)的分布式集群之上。
5.2.1 Mahout的K-Means算法簡介
K-Means算法是數(shù)據(jù)挖掘領(lǐng)域的一個經(jīng)典聚類算法。K-Means算法的任務(wù)是將給定的n個點(diǎn)聚到k個簇中。K-Means算法首先從包含k個中心點(diǎn)的初始集合開始,通過多次迭代并不斷調(diào)整中心位置,直到符合算法的預(yù)期。
K-Means算法執(zhí)行步驟流程圖如圖3所示。
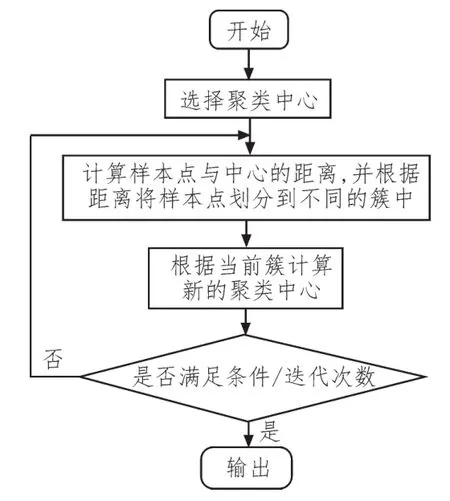
圖3 K-Means算法流程圖
因此,K-Means算法的核心可以歸納為:不斷地計(jì)算尋找聚類中心,并計(jì)算樣本點(diǎn)與聚類中心的距離,直到符合收斂條件時結(jié)束。其中距離是需要指定的,針對不同的數(shù)據(jù)類型選擇不同的距離計(jì)算方法才能提高聚類的質(zhì)量。下面以最常見的歐式距離為例,假設(shè)樣本為n維向量,聚類內(nèi)誤差如式(1)所示:
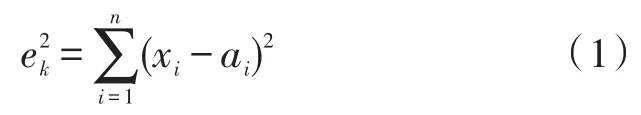
xi為第k個簇內(nèi)樣本點(diǎn)的第i維向量值,ai為中心點(diǎn)的第i維向量值,則整個K簇的聚類空間的收斂條件為:

當(dāng)E的值最小時,即滿足收斂條件,結(jié)束聚類。
5.2.2 基于K-Means算法的數(shù)據(jù)挖掘
在上述的基于Hive的離線分析部分中,挖泥船疏浚工藝點(diǎn)已經(jīng)被提取出來并且進(jìn)行了歸一化處理。此時數(shù)據(jù)存儲的格式是Hive默認(rèn)的TextFile格式,由于Mahout要求輸入的數(shù)據(jù)格式為向量格式,因此需要先對源文件進(jìn)行序列化,序列化后的數(shù)據(jù)格式為SequenceFile格式。
選用JavaAPI的方式進(jìn)行操作,具體步驟如下:
1)通過JDBC連接Hive數(shù)據(jù)庫,獲取歸一化后的工藝點(diǎn);
2)對工藝點(diǎn)序列化生成輸入向量SequenceFile;
3)將工藝點(diǎn)向量寫入HDFS文件系統(tǒng)輸入目錄;
4)寫入初始簇的中心;
5)運(yùn)行K-Means聚類作業(yè);
6)從輸出中讀取簇。
5.2.3 基于K-Means算法的聚類結(jié)果分析
在K-Means算法作業(yè)完成后,聚類結(jié)果輸出在result目錄下,其中每次迭代的結(jié)果也在輸出目錄中;聚類的最終結(jié)果是序列化文件,需要通過反序列化讀取聚類結(jié)果,如圖4所示。
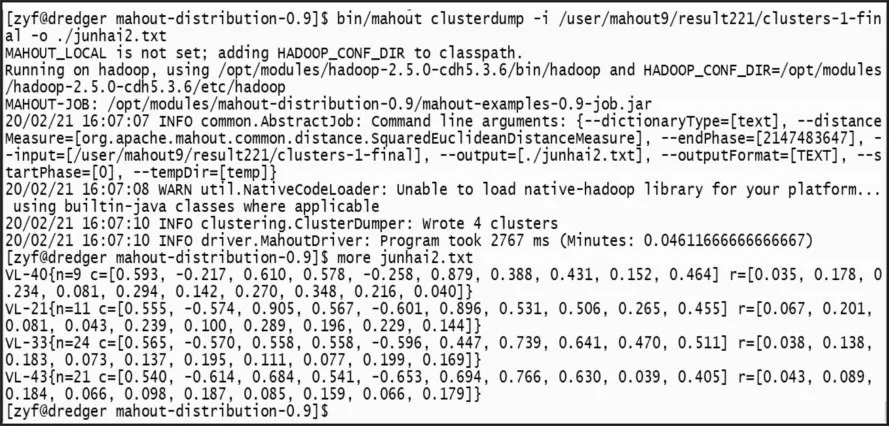
圖4 聚類結(jié)果
通過查看最終次迭代完成的結(jié)果,可以看到聚類完成的4個簇,其中VL-21的21表示該簇的ID;c=[…]表示該簇的中心點(diǎn);r=[…]表示該簇的半徑;進(jìn)一步查看各個簇及簇內(nèi)的聚類結(jié)果,如圖5所示。
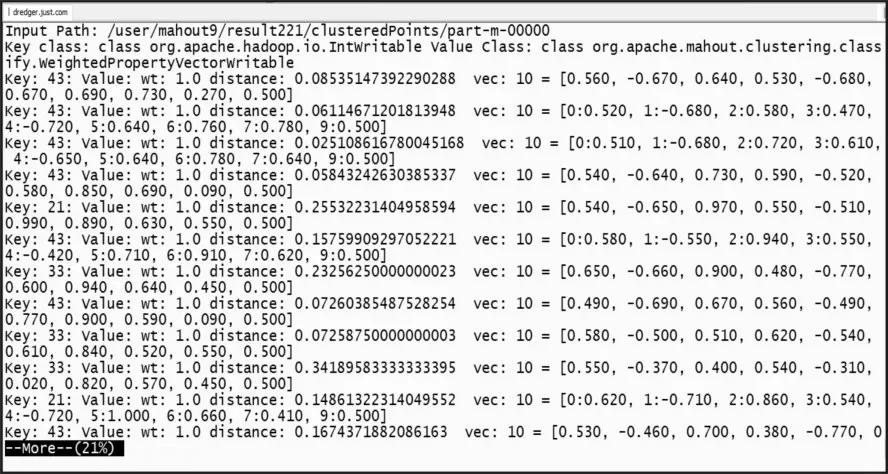
圖5 簇內(nèi)各點(diǎn)
聚類輸出進(jìn)行反歸一化后4個聚類簇的中心如表1所示。
由聚類結(jié)果的簇中心進(jìn)行分析,根據(jù)產(chǎn)量指標(biāo)計(jì)算將不同的簇分為優(yōu)、良、中、差。對所有數(shù)據(jù)進(jìn)行聚類完成后,其中在優(yōu)簇中的工藝點(diǎn)有17%,在良簇中的工藝點(diǎn)有32%,在中簇中的工藝點(diǎn)有37%,在差簇中的工藝點(diǎn)有14%。整理后的分簇工藝點(diǎn)分布如圖6所示。
根據(jù)聚類結(jié)果以及工藝點(diǎn)在優(yōu)良中差簇中的分布,對該船次疏浚性能評估按照多級分配權(quán)值方法進(jìn)行計(jì)算。計(jì)算得到的疏浚性能分將存儲在Hive表中。該表中記錄了歷史船次及其評分,并且將船次的評分進(jìn)行排序,通過HQL查詢語句可以將排名高的船次及評分展現(xiàn)出來,供操作人員參考。
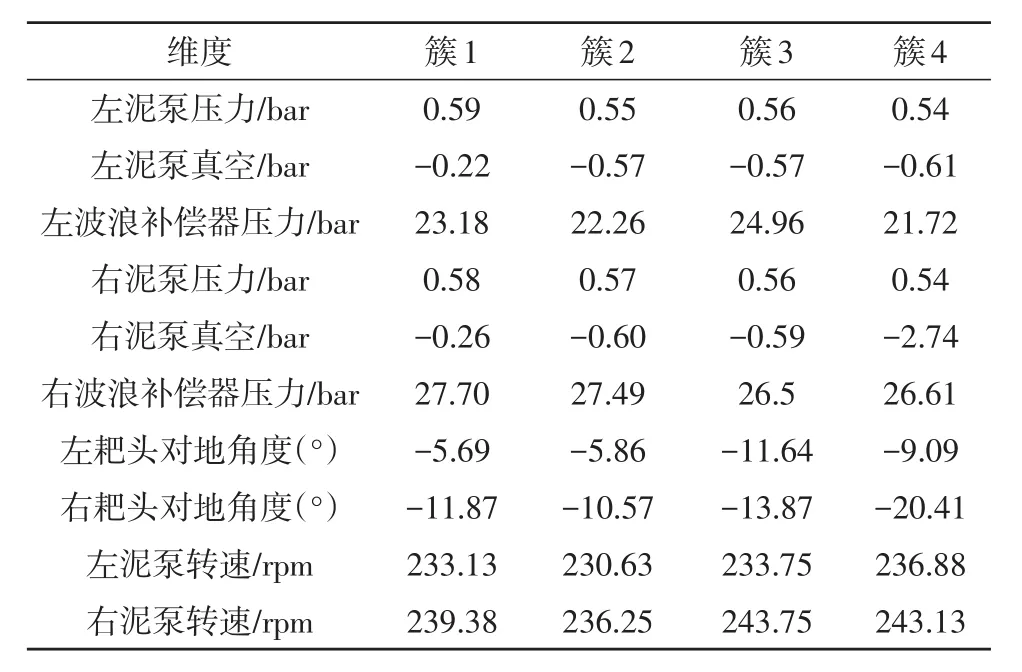
表1 疏浚工藝點(diǎn)聚類簇中心
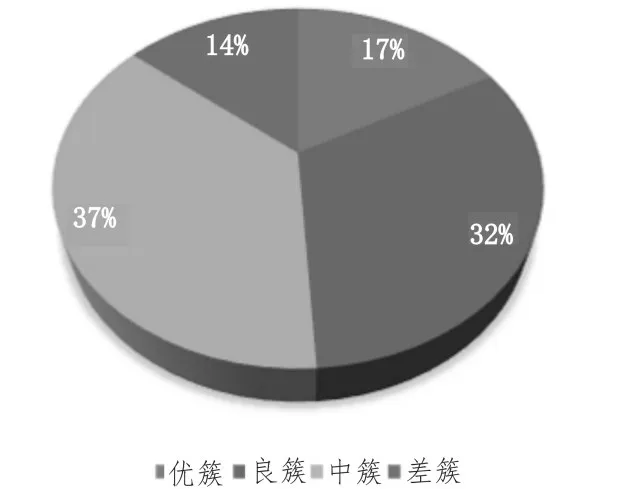
圖6 疏浚工藝點(diǎn)簇分布圖
6 結(jié)束語
文中基于Hadoop生態(tài)圈技術(shù)提出了一種挖泥船大數(shù)據(jù)平臺架構(gòu),并對于構(gòu)建挖泥船大數(shù)據(jù)平臺的采集模塊、存儲模塊與分析模塊進(jìn)行了研究。以工藝點(diǎn)聚類為例,實(shí)現(xiàn)了對挖泥船疏浚性能的分析評估。實(shí)驗(yàn)結(jié)果表明,基于Hadoop技術(shù)的挖泥船大數(shù)據(jù)平臺對于海量挖泥船疏浚歷史數(shù)據(jù)進(jìn)行高效存儲、提取和處理具有重要的現(xiàn)實(shí)意義。
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
山東冶金(2019年6期)2020-01-06 07:45:54
世界農(nóng)藥(2019年2期)2019-07-13 05:55:12
電力與能源(2017年6期)2017-05-14 06:19:37
財經(jīng)(2017年2期)2017-03-10 14:35:35
財經(jīng)(2016年15期)2016-06-03 07:38:02
財經(jīng)(2016年3期)2016-03-07 07:44:46
財經(jīng)(2016年6期)2016-02-24 07:41:51
銅業(yè)工程(2015年4期)2015-12-29 02:48:39
信息通信技術(shù)(2015年6期)2015-12-26 01:16:46
