基于監(jiān)控視頻的變電站運(yùn)動(dòng)目標(biāo)提取
2021-01-23 08:28:14胡旦華劉燕萍張宇晴
江西科學(xué) 2020年6期
胡旦華,劉燕萍,張宇晴
(1.中國電建集團(tuán)福建省電力勘測設(shè)計(jì)院有限公司,350003,福州;2.同濟(jì)大學(xué)浙江學(xué)院,314051,浙江,嘉興;3.福建師范大學(xué)數(shù)學(xué)與信息學(xué)院,350007,福州)
0 引言
隨著數(shù)字孿生技術(shù)的智能化,以及虛擬現(xiàn)實(shí)與可視化技術(shù)的飛速發(fā)展與應(yīng)用,人們開始通過數(shù)字模型信息表達(dá)現(xiàn)實(shí)世界,滿足對現(xiàn)實(shí)社會(huì)的深度感知。視頻監(jiān)控在當(dāng)今社會(huì)日常生活中發(fā)揮著關(guān)重要的作用,被廣泛應(yīng)用于城市安全發(fā)展的各個(gè)領(lǐng)域[1]。隨著相關(guān)軟硬件技術(shù)的發(fā)展,監(jiān)控處理技術(shù)也經(jīng)歷了多次變革。20世紀(jì)90年代初期主要以模擬監(jiān)控視頻信息處理技術(shù)為主,信息存儲(chǔ)與檢索不便,視頻信息的提取和檢索完全依靠人工處理。到20世紀(jì)90年代中期開始出現(xiàn)數(shù)字監(jiān)控技術(shù),模擬信號(hào)數(shù)字化使得存儲(chǔ)效率和處理能力大大提高,此時(shí)監(jiān)控圖形系統(tǒng)都是獨(dú)立的,缺乏信息共享和傳輸機(jī)制。近年來,隨著高速網(wǎng)絡(luò)技術(shù)的發(fā)展和普及,信息傳輸和共享都實(shí)現(xiàn)了數(shù)字化,存儲(chǔ)和處理變得更加方便。互聯(lián)網(wǎng)+時(shí)代和5G技術(shù)的發(fā)展更為監(jiān)控傳輸和處理技術(shù)提供了速度和質(zhì)量保證,基于高速傳輸?shù)木W(wǎng)絡(luò)通訊、數(shù)字圖像處理和人工智能技術(shù)使監(jiān)控系統(tǒng)智能化發(fā)展成為了可能。從日常生活和個(gè)人家庭到國家安全和社會(huì)治安,監(jiān)控系統(tǒng)為城市安全、社會(huì)管理等提供了不可或缺的安全保障。圖1所示為實(shí)時(shí)視頻監(jiān)控與虛擬三維場景的結(jié)合效果。

圖1 虛擬三維場景實(shí)況監(jiān)控投影
伴隨著越來越多的監(jiān)控系統(tǒng)組建和聯(lián)網(wǎng),隨之而來的是海量的視頻圖像數(shù)據(jù)處理。海量數(shù)據(jù)的分析給相關(guān)業(yè)內(nèi)人員帶來了較大檢索難度和工作強(qiáng)度。由于手工查找處理速度慢,且隨著工作強(qiáng)度和時(shí)間增長,容易導(dǎo)致信息的遺漏和錯(cuò)誤。計(jì)算機(jī)視覺影像處理技術(shù)在序列監(jiān)控視頻影像中的應(yīng)用成了研究的新動(dòng)向。通過圖像處理、模式識(shí)別、人工智能等技術(shù),對監(jiān)控系統(tǒng)中采集到視頻圖像進(jìn)行處理和分析,減少枯燥繁重的體力勞動(dòng),得到人們所需要的監(jiān)控信息[2]。
一般情況下在監(jiān)控影像視頻系統(tǒng)中主要關(guān)注和研究的對象是運(yùn)動(dòng)目標(biāo)提取和跟蹤,如行人分析、車輛提取和跟蹤等。通過圖像分割、變化檢測、模式識(shí)別等方法,提取目標(biāo)的顏色、形狀等梯度特征,協(xié)助分析識(shí)別分類目標(biāo)物體,指導(dǎo)做出準(zhǔn)確的規(guī)劃和判斷等。現(xiàn)階段的視頻監(jiān)控系統(tǒng)中,目標(biāo)檢測及運(yùn)動(dòng)分析主要應(yīng)用在公共安全場所、電廠電站企業(yè)的安全監(jiān)控、道路車輛違規(guī)檢測、交通路口車流和人流監(jiān)測,公安軍事等方面。對于變電站的安全監(jiān)控,通過提取運(yùn)動(dòng)目標(biāo),可對一線工人的作業(yè)路線、電網(wǎng)安全運(yùn)營等進(jìn)行安全預(yù)警,為國網(wǎng)安全運(yùn)營做出保障。對于軍事領(lǐng)域,隨著軍隊(duì)現(xiàn)代化建設(shè),目標(biāo)檢測與跟蹤已被應(yīng)用與無人機(jī)偵察、精確制導(dǎo)等方面。綜上所述,研究虛擬三維場景系統(tǒng)中的實(shí)況監(jiān)控投影及運(yùn)動(dòng)對象的檢測對于變電站的安全運(yùn)營具有重要的應(yīng)用價(jià)值。
1 國內(nèi)外研究現(xiàn)狀
基于視頻序列影像的運(yùn)動(dòng)目標(biāo)檢測即將運(yùn)動(dòng)物體從視頻幀序列中分割出來,通常情況下,除了進(jìn)行目標(biāo)前后景分割處理,還需對分割出來的前景區(qū)域進(jìn)一步進(jìn)行形態(tài)學(xué)分析,得到更加準(zhǔn)確的目標(biāo)區(qū)域。當(dāng)前常用的前后景分割算法有幀差法、光流法、減背景法。背景提取與更新主要分為非模型法和模型法兩類。非模型方法有時(shí)間差分法、時(shí)間中值濾波法等,即根據(jù)已有圖像序列,通過一定規(guī)則為每個(gè)像素設(shè)置一個(gè)背景值。模型方法包括線性預(yù)測法、混合高斯模型法、非參數(shù)模型法、基于紋理特征的方法等,即通過建立逐幀像素的對應(yīng)模型,根據(jù)其參數(shù)變化的影響分析實(shí)時(shí)更新背景圖像。Friedman and Russell[3]首先提出了基于混合高斯模型的方法,該模型用3個(gè)高斯分布混合表示背景、前景和陰影來表示每個(gè)像素點(diǎn),采用EM(Expectation Maximum)算法對相關(guān)參數(shù)進(jìn)行更新達(dá)到了圖像的分割。Stauffer[4]提出多個(gè)高斯分布混合建模處理復(fù)雜的背景變化,先用K均值法對每個(gè)像素建模,然后將所有K個(gè)分布按照各自的權(quán)重或者方差大小降序排列,選取滿足一定規(guī)則的前B個(gè)分布來表征背景分布,該方法執(zhí)行效率較低。Oliver[5]基于本征函數(shù)的方法取得了較好的效果,簡化了算法的復(fù)雜度,提高了算法執(zhí)行的效率。Elgammal[6]構(gòu)建了無參數(shù)的背景模型,建立了相應(yīng)的數(shù)學(xué)函數(shù)分析模型,提高了算法的穩(wěn)健性。Marko[7]提出了基于紋理特征建模的算法,建造級(jí)聯(lián)分類器進(jìn)行目標(biāo)識(shí)別,成功應(yīng)用于人臉檢測和監(jiān)視環(huán)境中行人的檢測。Kaewtrakulpong[8]提出了一種運(yùn)動(dòng)陰影檢測的自適應(yīng)混合模型,該方法可有效提取陰影區(qū)域的運(yùn)動(dòng)跟隨目標(biāo)。比較而言,非模型方法運(yùn)算簡單但背景圖像不準(zhǔn)確,模型方法背景準(zhǔn)確但運(yùn)算復(fù)雜。Papageogiou[9]采用類似于Haar小波的算子對圖像區(qū)域進(jìn)行密集編碼,使用不同方向、區(qū)域內(nèi)的Haar小波系數(shù)的絕對值進(jìn)行局部特征的描述,可以有效用于檢測行人和車輛。Shashua[10]則采用了SIFT 特征,使用Adaboost訓(xùn)練分類器進(jìn)行行人的檢測。Dalal and Triggs[11]提出HOG特征檢測算子用在圖片行人檢測中,并使用SVM支持向量機(jī)進(jìn)行訓(xùn)練和分類,其中每個(gè)圖片的HOG特征包含多個(gè)單元,每個(gè)單元累加特定方向的梯度值投票,計(jì)算出描述子后,在高維連續(xù)HOG向量上訓(xùn)練SVM分類器,此方法需要足夠的訓(xùn)練樣本。如圖2所示為HOG檢測算法實(shí)現(xiàn)的人員信息提取。

(a) (b) (c)
Maji[12]用不重疊的多分辨率的HOG描述子和基于Lazebnik[13]提出的空間金字塔匹配核的直方圖相交核SVM對這些最好的結(jié)果進(jìn)行了改進(jìn)。Jie[14]提出韋伯特征,通過視覺上的韋伯定理引用到圖像處理領(lǐng)域而來,由差分激勵(lì)和核方向2個(gè)部分組成,對明暗變化和噪聲干擾有一定提高。Wu[15]提出通過面向形狀的局部圖像特征,用于檢測和分割圖像中被遮擋的對象。隨著卷積神經(jīng)網(wǎng)絡(luò)[16]在ImageNet大型視覺識(shí)別挑戰(zhàn)上取得的成功,越來越多的研究人員將視覺提取類的算法應(yīng)用于圖像識(shí)別[17]、語音識(shí)別等各個(gè)應(yīng)用領(lǐng)域,其展現(xiàn)的效果和性能也達(dá)到了一定的目標(biāo)。
2 監(jiān)控視頻在虛擬場景中實(shí)時(shí)調(diào)用方法
2.1 配置SDK文件
不同系列的攝像系統(tǒng)具有不同的底層架構(gòu),相關(guān)攝像頭的開發(fā)與調(diào)用依賴于其SDK開發(fā)包,根據(jù)其介紹和功能,下載并配置SDK開發(fā)包。遍歷相關(guān)描述文件,并在Visual Studio 2017中打開或創(chuàng)建C++項(xiàng)目文件,在屬性管理器中配置C/C++包含目錄及鏈接器附加庫目錄,將目錄鏈接到SDK開發(fā)包的頭文件及庫文件對應(yīng)文件夾中。
2.2 SDK組件功能
網(wǎng)絡(luò)庫:基本通訊架構(gòu)之一,該庫主要支持不同端口設(shè)備之間的協(xié)議通訊,同時(shí)具有支持和協(xié)調(diào)遠(yuǎn)程調(diào)控,設(shè)置相關(guān)協(xié)議參數(shù)和碼流數(shù)據(jù)等功能。
RTSP庫:作為通訊協(xié)議代碼的基本支撐庫,通過RTSP掩碼可以有效支持傳輸協(xié)議的完成,當(dāng)需要對設(shè)備的影像進(jìn)行讀取、存檔、下載等操作時(shí),必須加載和設(shè)置RTSP掩碼進(jìn)行協(xié)議通訊。
轉(zhuǎn)封裝庫:可以完成2種不同意義上的工作。一類是通過轉(zhuǎn)封裝庫進(jìn)行碼流的轉(zhuǎn)換,將標(biāo)準(zhǔn)碼流轉(zhuǎn)換為設(shè)備可讀取的碼流格式;另一類是基于協(xié)議標(biāo)準(zhǔn),將標(biāo)準(zhǔn)碼流通過轉(zhuǎn)義封裝成為第3方格式碼流,通過RTSP協(xié)議讀取、下載等操作時(shí),必須通過轉(zhuǎn)封裝庫進(jìn)行不同格式碼流的轉(zhuǎn)換,以實(shí)現(xiàn)流運(yùn)算。
語音對講庫:用于語音對講時(shí)通過聲卡采集數(shù)據(jù)并按照指定的編碼格式編碼碼流或者解碼播放音頻碼流數(shù)據(jù)(不帶封裝格式的碼流數(shù)據(jù))。Windows64位或者Linux系統(tǒng)下無語音對講功能。
字符轉(zhuǎn)換庫:基本運(yùn)算轉(zhuǎn)義符操作支撐庫。主要用于字符集的轉(zhuǎn)換。根據(jù)SDK內(nèi)部字符的編碼標(biāo)準(zhǔn),根據(jù)協(xié)議需要,通過libiconv庫進(jìn)行不同字符集的轉(zhuǎn)換。轉(zhuǎn)換過程中,需要采用libiconv庫的編碼協(xié)議進(jìn)行接口設(shè)置,以便于SDK的字符處理。
幀分析庫:用于分析視音頻幀數(shù)據(jù),調(diào)用NET_DVR_SetESRealPlayCallBack、NET_DVR_SetPlayBackESCallBack設(shè)置裸碼流回調(diào)函數(shù)等接口時(shí),必須加載該庫文件。
播放庫:碼流運(yùn)算基本庫之一。基于一定的解碼和編碼原則對序列影像進(jìn)行逐幀記錄和編碼,同時(shí)采用句柄方式進(jìn)行碼流數(shù)據(jù)的索引和處理。
2.3 監(jiān)控實(shí)時(shí)顯示實(shí)現(xiàn)
在虛擬場景中實(shí)現(xiàn)即時(shí)場景的監(jiān)控?cái)?shù)據(jù)導(dǎo)入,首先需要初始化SDK開發(fā)包,根據(jù)其網(wǎng)絡(luò)通訊庫和RTSP通訊庫設(shè)置服務(wù)器的IP地址、消息回調(diào)函數(shù)和連接時(shí)間,實(shí)現(xiàn)虛擬場景和視頻影像的通訊。通過注冊用戶設(shè)備,可以實(shí)現(xiàn)視頻影像的預(yù)覽、回放和下載,同時(shí)基于相關(guān)調(diào)用機(jī)制實(shí)現(xiàn)視頻影像的處理和分析。SDK調(diào)用實(shí)現(xiàn)監(jiān)控視頻顯示及2次開發(fā)的主要流程如圖3所示。

圖3 SDK調(diào)用基本流程
從SDK調(diào)用的基本流程可以看出,實(shí)現(xiàn)視頻數(shù)據(jù)的即時(shí)通訊,必須進(jìn)行SDK的初始化,同時(shí)根據(jù)設(shè)備的RTSP進(jìn)行注冊,在完成相關(guān)的操作處理后,還需設(shè)備的注銷和相關(guān)SDK資源的釋放。在上述操作中,初始化是完成網(wǎng)絡(luò)資源的預(yù)分配,通過設(shè)置相關(guān)內(nèi)置時(shí)間參數(shù),可以完成相關(guān)連接超時(shí)和網(wǎng)絡(luò)超時(shí)檢測。同時(shí),由于SDK內(nèi)部架構(gòu)采用異步調(diào)用模式,通過設(shè)置異常消息的回調(diào)函數(shù),可以有效處理在此階段的異常信息。對于用戶注冊設(shè)備,主要是實(shí)現(xiàn)相關(guān)協(xié)議參數(shù)的核對,通過注冊可以調(diào)用SDK基本庫的所有功能模塊。對于其相關(guān)子模塊,本文只調(diào)用其預(yù)覽和下載模塊。從前端設(shè)備取實(shí)時(shí)碼流,解碼顯示以及播放控制等功能,同時(shí)支持軟解碼和解碼卡解碼,由啟動(dòng)預(yù)覽、實(shí)時(shí)流數(shù)據(jù)捕獲和錄像、停止預(yù)覽3個(gè)部分組成。通過設(shè)置預(yù)覽接口中預(yù)覽參數(shù)的播放窗口句柄為空值,并調(diào)用捕獲數(shù)據(jù)的接口(即設(shè)置NET_DVR_RealPlay_V40 接口中的回調(diào)函數(shù)或調(diào)用接口,獲取碼流數(shù)據(jù)進(jìn)行后續(xù)解碼播放處理)。
3 基于穩(wěn)健混合高斯模型的監(jiān)控人員信息分析
混合高斯模型,相對于單高斯模型只能描述單模態(tài)背景的缺陷,其對背景復(fù)雜且動(dòng)態(tài)變化的多模態(tài)形式能夠進(jìn)行更加準(zhǔn)確的描述,增加了其在實(shí)際應(yīng)用中的適用性和穩(wěn)健性。在真實(shí)世界的場景中,許多背景都是動(dòng)態(tài)的、復(fù)雜的、交互的,例如室外的光照變化、樹葉的擺動(dòng)等,這些背景都處于動(dòng)態(tài)的變化中。混合高斯背景模型通過對圖像中的每個(gè)像素點(diǎn)賦予一定的權(quán)重并建立k個(gè)高斯分布,采用k個(gè)高斯分布的加權(quán)和結(jié)果估計(jì)樣本的概率密度分布,該方法對運(yùn)動(dòng)物體的檢測和對背景模型的更新同時(shí)進(jìn)行,計(jì)算中利用新的圖像幀對背景進(jìn)行實(shí)時(shí)更新,使得其背景運(yùn)算模型更加接近真實(shí)場景。多維正態(tài)分布概率密度函數(shù)如公式(1)所示:
(1)
式中:∑表示模型協(xié)方差矩陣。混合高斯背景模型可寫成公式(2)形式:
(2)
式中:P(x)表示混合高斯模型;Ck表示混合高斯模型中第k個(gè)高斯分布的樣本,可以表示為(μk,θk);wk表示第k個(gè)高斯分布在該高斯模型中所占的權(quán)重比例;N(x|Ck)表示模型中第k個(gè)高斯分布。
假設(shè)某一像素的值的變化在一段時(shí)間內(nèi)是連續(xù)的,可有如下表示:
{X1,X2,…,Xt}={I(x0,y0,i):1≤i≤t}
式中:t時(shí)某像素可用Xi表示,I(x0,y0,i)表示此時(shí)圖像坐標(biāo)(x0,y0)處的像素值。對圖像中每一個(gè)像素建立k個(gè)高斯分布,k一般為3~5。混合高斯模型的公式如下所示:
(3)
式中:p(Xt)表示像素X的混合高斯模型;第i個(gè)高斯分布在時(shí)間t的權(quán)值、期望、模型協(xié)方差矩陣分別用ωi,t、μi,t、∑i表示;η(Xt,μi,t,∑i,t)為針對像素Xi的單高斯分布函數(shù)。
對于m×n的背景模型圖像分辨率,則其需要初始化的高斯分布數(shù)為m×n×k。并通過公式(4)對背景模型中各個(gè)高斯分布的權(quán)重、期望和方差進(jìn)行實(shí)時(shí)更新維護(hù)。
(4)
使用穩(wěn)健混合高斯模型進(jìn)行運(yùn)動(dòng)目標(biāo)檢測時(shí),需要計(jì)算各個(gè)高斯分布的方差并對其進(jìn)行降序排列,選擇排序靠前的幾個(gè)高斯分布作為真實(shí)背景模型的分布。在排序之后的k個(gè)高斯分布中選取前B個(gè)分布組成背景模型,其中B遵循公式(5):
(5)
式中T為預(yù)先設(shè)定的參數(shù)閾值用于判斷是否接受成為背景模型。本文計(jì)算中根據(jù)概率分布確定其取值范圍為0.7~0.75。檢測運(yùn)動(dòng)目標(biāo)時(shí),若圖像中某一個(gè)像素能滿足前B個(gè)分布中的任意一個(gè)高斯分布,則判定該像素屬于背景,否則屬于前景,即運(yùn)動(dòng)目標(biāo)。
4 實(shí)驗(yàn)分析與對比
本次實(shí)驗(yàn)的環(huán)境為Visual Studio 2017+OpenCV3.4.5,運(yùn)行計(jì)算機(jī)配置為Intel? CoreTMi7 CPU @ 3.70 GHz及16 GB內(nèi)存。實(shí)驗(yàn)所用視頻分辨率為960×540,幀速率為24.00 幀/s。在測試用環(huán)境變量中配置系統(tǒng)變量,添加OpenCV鏈接庫下的相關(guān)文件,然后將bin目錄下的dll動(dòng)態(tài)鏈接庫文件拷貝到系統(tǒng)目錄system32中。打開Visual Studio 2017并新建項(xiàng)目文件,在屬性管理器中配置VC++目錄中的包含目錄和庫目錄,并在鏈接器附加依賴項(xiàng)中添加lib文件名稱。
分別使用GMM和幀間差分法對同一段變電站工作區(qū)內(nèi)的監(jiān)控視頻做前后景分割測試。圖4為使用基于GMM的減背景法進(jìn)行前后景分割檢測并通過形態(tài)學(xué)處理分割結(jié)果,速度為18~20 幀/s。圖5為使用幀間差分法進(jìn)行前后景分割并通過形態(tài)學(xué)方法處理分割結(jié)果,速度為15~18 幀/s。圖6所示為針對相同幀不同方法的檢測結(jié)果對比。

(a)原始幀 (b)前景部分二值圖像

(a)原始幀 (b)幀差結(jié)果
從測試結(jié)果可知,2種方法處理視頻的速度均可滿足實(shí)時(shí)處理的需求。由圖4與圖5的算法提取分析可以得出:1)無論是GMM或幀間差分法,都能成功檢測到監(jiān)控視頻中的運(yùn)動(dòng)目標(biāo),而分割結(jié)果經(jīng)過形態(tài)學(xué)處理后,在填充空洞、凹陷及斷開粘連目標(biāo)上都有著明顯提高;2)對于較小的運(yùn)動(dòng)目標(biāo),2種方法均可準(zhǔn)確將其從背景中分割出來,而當(dāng)運(yùn)動(dòng)目標(biāo)為較大物體時(shí),幀間差分法則由于檢測的內(nèi)部空洞等原因?qū)⑼晃矬w分割為細(xì)小的碎塊,分割準(zhǔn)確度不如基于GMM的減背景法。圖6分析對比也驗(yàn)證了以上兩點(diǎn),同時(shí)幀間差分法存在當(dāng)幾個(gè)運(yùn)動(dòng)目標(biāo)之間距離近時(shí),存在被誤判為同一運(yùn)動(dòng)物體的可能。由實(shí)驗(yàn)結(jié)果可知,基于GMM的減背景法在前后景分割的實(shí)驗(yàn)中,分割結(jié)果的準(zhǔn)確性優(yōu)于幀間差分法,且檢測速率也滿足實(shí)時(shí)處理的需求,故可應(yīng)用于監(jiān)控視頻運(yùn)動(dòng)目標(biāo)實(shí)時(shí)檢測。

圖6 對比分析,左為基于GMM的減背景法,右為幀間差分法
使用基于GMM的減背景法進(jìn)行監(jiān)控視頻運(yùn)動(dòng)人員實(shí)時(shí)計(jì)數(shù)實(shí)驗(yàn),如圖7所示。此處選用非密集人流的道路監(jiān)控視頻,視頻共722幀,前50幀用于初始背景模型的訓(xùn)練,后672幀進(jìn)行計(jì)數(shù)并人工檢測和統(tǒng)計(jì)結(jié)果。
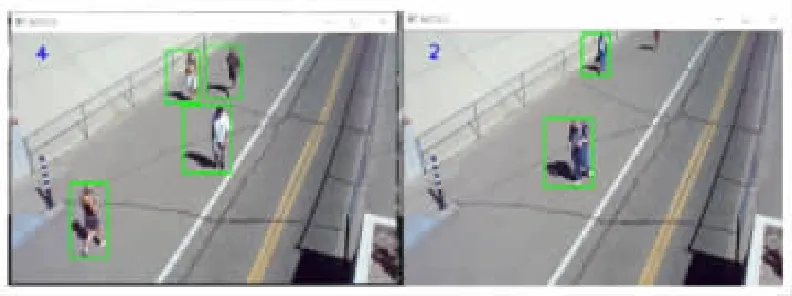
圖7 監(jiān)控視頻運(yùn)動(dòng)目標(biāo)實(shí)時(shí)統(tǒng)計(jì)
每2幀檢查一次并記錄,最終記錄數(shù)目翻倍來表示統(tǒng)計(jì)結(jié)果,如表1所示。可知完全統(tǒng)計(jì)正確的幀數(shù)為542幀,準(zhǔn)確率為80.6%,且在統(tǒng)計(jì)有誤的幀中,約有2/3人員計(jì)數(shù)誤差為±1人。

表1 運(yùn)動(dòng)人員實(shí)時(shí)計(jì)數(shù)實(shí)驗(yàn)結(jié)果
根據(jù)上述實(shí)驗(yàn),基于GMM的減背景法的運(yùn)動(dòng)目標(biāo)檢測與統(tǒng)計(jì)結(jié)果有著較好的準(zhǔn)確性與魯棒性,可應(yīng)用于背景變化較小、人員運(yùn)動(dòng)簡單的場景動(dòng)態(tài)人員檢測。
5 結(jié)束語
在虛擬場景中投影監(jiān)控視頻可以有效實(shí)現(xiàn)虛實(shí)結(jié)合,基于視頻信息的分析和提取是智能化安全保障的前提。如何對投影的監(jiān)控視頻進(jìn)行目標(biāo)信息提取是當(dāng)前研究的一個(gè)重點(diǎn),對特殊的場所如變電站、發(fā)電廠等具有重要的應(yīng)用價(jià)值。本文通過討論國內(nèi)外的研究現(xiàn)狀,詳細(xì)介紹了在三維虛擬場景中調(diào)用監(jiān)控視頻的方法,同時(shí)針對獲取的視頻監(jiān)控,通過采用混合高斯背景模型實(shí)現(xiàn)了視頻內(nèi)部運(yùn)動(dòng)目標(biāo)的準(zhǔn)確提取,通過和其他方法以及實(shí)際場景的比較,證實(shí)了GMM方法的準(zhǔn)確性和穩(wěn)健性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
汽車工程師(2021年12期)2022-01-17 02:29:54
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
當(dāng)代陜西(2020年14期)2021-01-08 09:30:42
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
貴州師范學(xué)院學(xué)報(bào)(2016年4期)2016-12-01 03:54:07
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
