利用深度學習對托福聽力部分進行機器理解
2021-01-28 03:35:42胡蓉田時宇
微型電腦應用 2021年1期
關鍵詞:模型
胡蓉, 田時宇
(湖南信息學院 通識教育學院, 湖南 長沙 410151)
0 引言
隨著共享視頻、社交網絡和在線課程等的普及,多媒體或音頻內容的數量增長速度遠遠快于人們可以觀看或收聽的內容。用戶可以輕松地瀏覽文本,但音頻內容則不是這樣,因為它們不能直接顯示在屏幕上,因此,訪問大量的多媒體或音頻內容對人類來說是困難和耗時的。因此,利用機器實現自動理解語音內容,并為人類提取甚至可視化關鍵信息是非常必要的。盡管文本和視覺內容的機器理解已經得到了廣泛的研究,但是口語內容的機器理解仍然是一個研究較少的問題[1-2]。因此本文對口語內容的機器理解進行了初步嘗試。
本文以托福考試為研究目標,針對托福考試中的聽力部分,利用深度學習進行機器理解。本研究提出了一種新的框架TAL,利用基于注意力的Tree-LSTM來構造考慮詞序的句子表示[3]。本文利用自然語言的層次結構和注意機制的選擇能力,證明了該模型優于樸素方法和其他基于神經網絡的模型。
1 對聽力的機器理解
1.1 系統架構
TAL網絡架構,如圖1所示。
由圖1可知,模型中有兩個關鍵模塊:第一個是Tree-LSTM[4],它將句子編碼成連續的表示形式,由依賴解析器提供層次結構,而不是簡單的順序結構,因此它利用了人類語言的內在屬性;第二個關鍵模塊是注意模塊(attention module)。在接下來的實驗中,發現將這兩個模塊結合在一起比以前僅使用Tree-LSTM和注意力機制(attention mechanism)更為出色。
模型不同組件的詳細信息如下所示。在圖1的左側,基于Tree-LSTM的句子表示模塊用于根據問題的單詞序列生成問題向量的表示;ASR系統轉錄音頻故事,圖1底部的故事模塊以ASR轉錄本為輸入,將轉錄本中的句子轉換成一個向量序列,每個向量代表一個短語或一個句子;注意力模塊在中間,注意機制可以應用多次。在圖的右側,這四個選項也由句子表示模塊表示為向量。最后,評估答案選擇的置信度得分,并生成答案。系統是端到端學習的,除了ASR模塊。
1.2 句子表征
句子表示模塊的目標是通過捕獲句子語義的向量來表示句子。輸入問題Q和選擇C都是一個單詞組成的序列。在句子表示模塊中,問題Q表示為向量VQ0,選擇C表示為VC。一個問題可以由多個句子Si組成,每個句子首先可以表示為VSi。那么問題向量VQ是問題中所有Si的VSi之和。使用遞歸神經網絡Tree-LSTM獲得句子表示。Tree-LSTM基于其子節點的向量表示為依賴樹中的每個節點生成向量表示。
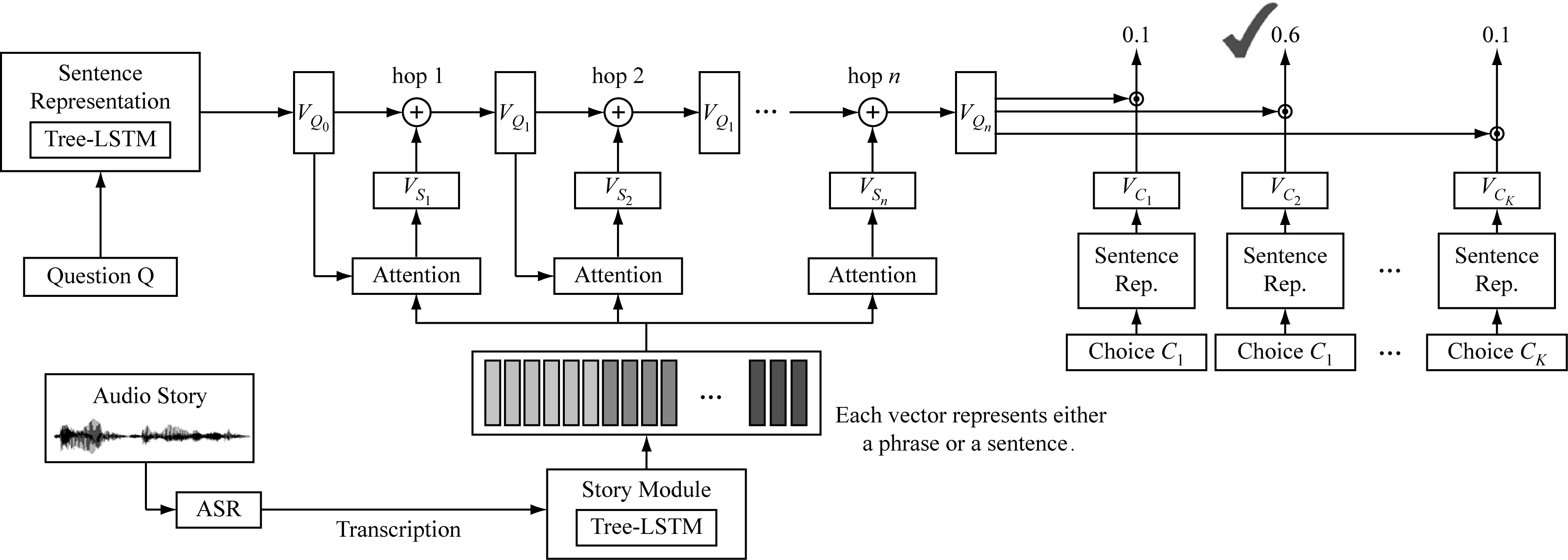
圖1 TAL網絡架構
1.3 故事表征
故事抄寫是一個很長的單詞序列,有很多句子。故事模塊的目標是將單詞序列表示為一組向量表示O={o1,o2,…,ot},其中ot表示Tree-LSTM的短語或句子。
短語層次:O={o1,o2,…,ot}中,每個ot是句子的Tree-LSTM中節點的隱藏狀態,或者每個ot表示一個短語。因此,t大于故事中的句子數。
句子層次:每一個ot是故事中某個句子上Tree-LSTM的根節點的隱藏狀態,或者每一個ot代表一個句子。在這種情況下,t等于句子數。
1.4 注意力機制
存儲模塊基于從故事模塊獲得的表示來提取故事中與問題VQ相關的信息。設O={o1,o2,…,ot}為故事的向量表示集。集合O中的向量首先由嵌入矩陣W(m)和W(c)轉換成記憶向量M={m1,m2,…,mt}和證據向量C={c1,c2,…,ct},如式(1)。
(1)
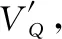
(2)
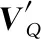
(3)
式中,⊙表示余弦相似性。每個注意權重αt對應于一個證據向量ct。故事向量Vs是以注意力為權重的證據向量ct的加權和,如式(4)。
(4)
式中,Vs可以看作是從音頻故事中提取的與查詢相關的信息。
1.5 多跳
在圖1的左側,首先使用句子表示模塊將輸入問題轉換為問題向量VQ0。該VQ0用于計算注意值αt以獲得故事向量VS1。然后將VQ0和VS1相加形成新的問題向量VQ1。在圖1中,該處理是第一跳(1跳)。第一跳VQ1的輸出可用于計算新的注意以獲得新的故事向量VS1。這可以被看作是機器再次遍歷故事,用一個新的問題向量重新聚焦故事。再次,VQ1和VS1相加形成VQ2(2跳)。在n跳(n是預定義的)之后,最后一跳VQn的輸出將用于下一小節中的答案選擇。
1.6 應答模塊
(5)
2 實驗與評估
2.1 實驗設置
對于聽力評估使用了預訓練的300維GloVe矢量模型[5],以獲得每個單詞的矢量表示。為了減少詞匯量,在這里使用了斯坦福大學自然語言處理小組[6]的工具來對問題選擇和故事抄寫中的單詞進行詞素化。在訓練之前,刪減了故事中的那些話語,這些話語的矢量表示與問題之間的余弦距離很遠,刪減話語的百分比由開發集上模型的性能決定。
2.2 結果與評估
對于前文描述的模型,前向和后向GRU網絡的隱藏層的大小都是128。為了避免過度擬合,模型中的所有雙向GRU網絡和樹LSTM共享同一組參數。使用RmsProp[7],初始學習率為1e-5,動量為0.9。輟學率為0.2。Tree-LSTM的隱藏層大小和內存模塊的嵌入大小均為75。使用AdaGrad[8],初始學習率為0.002。梯度裁剪的閾值為20,批量大小為40,使用開發集將跳數從1調整到3。
使用準確性(正確回答的問題的百分比)作為評估指標。在訓練集的故事和問題/答案的手動轉錄上對模型進行了訓練,并在測試集(Manual)和ASR轉錄(ASR)上進行了測試,為了進行公平的比較,統計了10次運行的平均準確度和標準差,如表1所示。
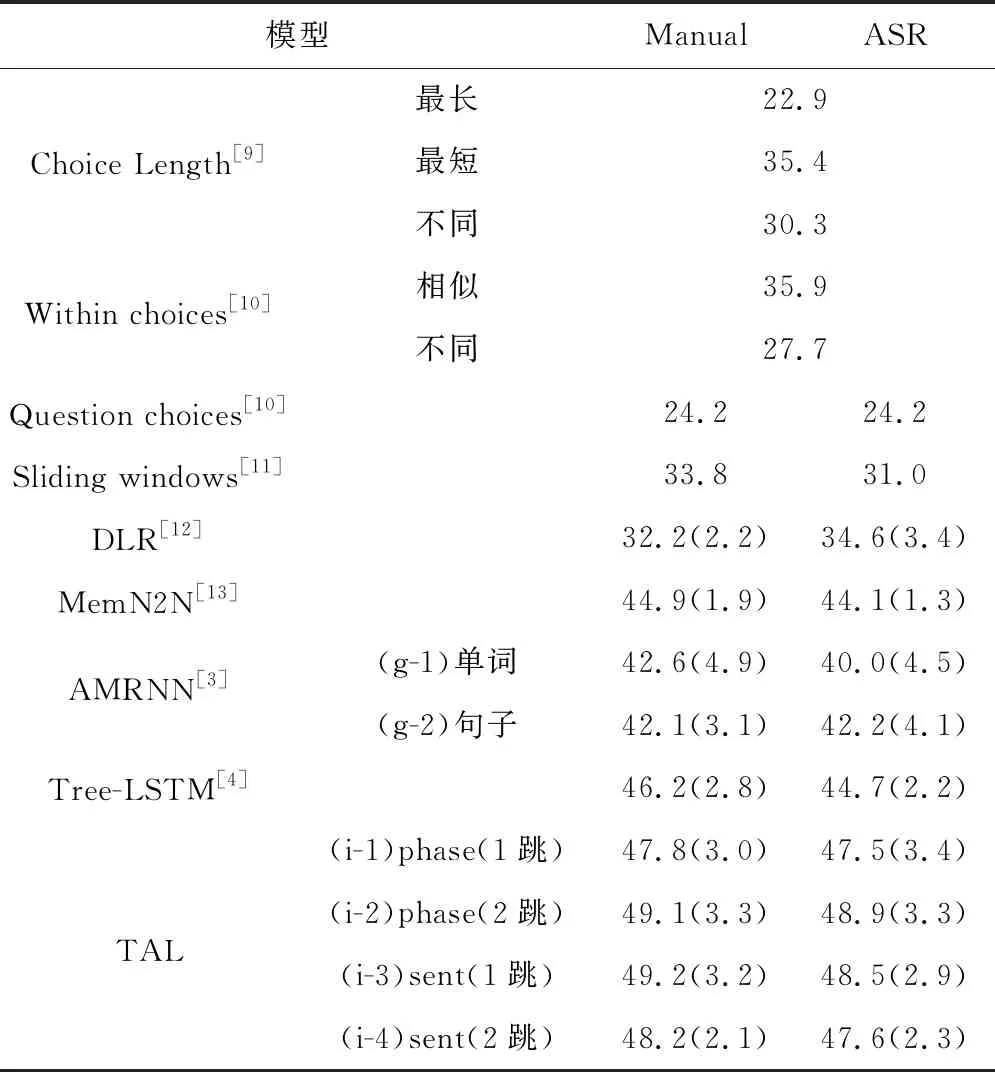
表1 不同方法比較結果
本文提出的TAL分別用于1跳和2跳的短語/句子級的注意力模型,其準確度比其他方法都要高很多。1跳句子級注意力模型在manual中的平均準確率最高,達到49.2%,顯著高于其他方法的結果;2跳短語級注意模型在ASR結果中的平均準確率最高,達到48.9%,僅略低于1跳。還可以觀察到,增加跳數會提高短語級注意的表現,但不會提高句子級注意的表現,這可能是因為對于短語級推理,模型首先在1跳中選擇關鍵短語,然后在2跳中根據這些關鍵短語改變其注意力。對于句子級推理,在1跳中只選擇了幾個關鍵句子,而更多的跳則無法找到額外的關鍵句子。
令人驚訝的是,ASR錯誤對聽力理解的影響很小。為了進一步分析結果,進行了額外的實驗。在測試階段,用一個概率為34.3%(與WER相同)的隨機詞替換了manual中的每個詞。結果顯示在標有隨機的列中。通過比較ASR和隨即兩欄的結果,我們發現ASR錯誤對聽力理解準確性的影響小于隨即替換,如表2所示。
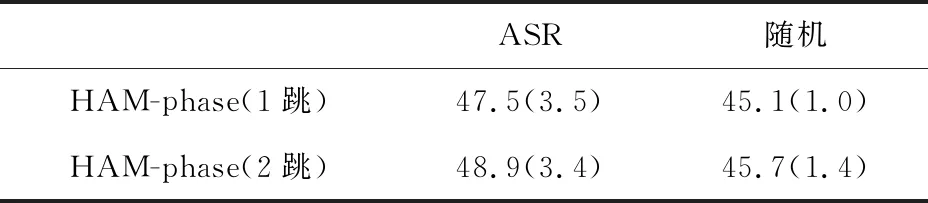
表2 ASR和隨機的結果
3 總結
在本文中,提出了兩個與語音內容的機器理解有關的目標——托福聽力和口語理解。在托福聽力理解中,提出的TAL框架在樹狀結構的LSTM網絡中結合了多跳注意力機制,其準確性為48.8%;在對口語理解中,利用CNN網絡改進現有的模型,證明了ASR錯誤會大大降低閱讀理解模型的性能,并建議使用不同種類的子字單元來減輕這些錯誤的影響。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
