基于深度學習的房產價值視覺評估
2021-01-28 03:35:42謝志偉
微型電腦應用 2021年1期
謝志偉
(東莞職業技術學院 計算機工程系, 廣東 東莞 523808)
0 引言
在現代房地產市場背景下,房屋評估是包括買賣雙方,貸款方和房地產經紀人在內的各方參與的必要步驟。傳統考察房屋的方式一般是人員實地勘察。但隨著網絡發展帶來的便利,以及新冠肺炎疫情的影響,網絡看房成為主流選擇。一般網上交易時,都是利用大量房屋照片吸引潛在買家并說服他們出價是一種常見的做法。要自動評估房屋價值,需要面臨這樣的問題:一個有經驗的人如何去評估房屋價值。基本上,發現以下幾個方面在評估房屋價值時最為重要:房屋的文字或視覺特征[1];與相似房產的比較[2];以及對周圍區域的評估[3]。但這些評估主要是基于人的主觀,所以難免會存在不公正現象,因此,解決以上問題,在此提出了一種有效的自動方法,基于文本和視覺特征(即視覺房屋評估)準確預測房屋價值,并命名為MDRR(Multi-instance Deep Ranking and Regression)。
1 多示例深度排序回歸網
1.1 深度排序與回歸網
考慮一組訓練樣本(xi,yi)其中xi表示示例包,而yi表示相關的連續標簽。在此的目標是學習可以將示例映射到目標標簽空間的預測函數gw(·)和可以根據其連續標簽對兩個示例進行排序的等級函數fw(·),w表示要從訓練數據中學習的參數。這項工作的目標是從多示例設置中從弱監督數據中學習gw(·)和fw(·)的深入表示。
因此引入一個多層神經網絡,稱為多示例深度排序和回歸網絡,來參數化預測函數gw(·)和排序函數fw(·)。MDRR的體系結構,如圖1所示。
輸入是一個包含房屋文本和圖像數據的示例,輸出是連續的標簽和等級。MDRR由3個子網組成。采用前饋神經網絡(FNN)和卷積神經網絡(CNN)分別對文本輸入和圖像輸入進行處理。這兩個網絡的最后一個隱藏層完全連接到一個融合層,如淺色框所示,它在兩個方面起作用。一方面,融合層的輸出激活完全連接到一個以fw(·)表示的輸出神經元,fw(·)的輸出用于根據連續標記對兩個示例進行排序,w表示MDRR的參數,但有濫用符號的情況。另一方面,融合層的激活進一步反饋給FNN,其輸出神經元(表示為gw(·))返回連續標簽。在下面的兩部分中,將推導出這兩個損失函數的數學定義。

圖1 MDRR網絡示意圖
1.2 多示例排名損失
函數fw(·)用于將示例映射到秩標量。為了學習最優fw(·),收集一組有序的包對,用(i,j)表示,其中包i的等級高于其他包j,并使用這些有序的包對來學習網絡參數w。讓xik表示第i個包的第k個示例。對于任何一對(i,j),函數fw(·)應該遵循多示例約束[4]:包i示例的最大秩應該高于包j中任何示例的秩。形式上,有一組約束,如式(1)。
(1)
它可以用來限制w的可行解,從而達到排序的目的。
因此,排名損失,如式(2)、式(3)。
(2)
(3)
式中,λ是一個常量參數,ξijl≥0,?k,l,?(i,j)。根據文獻[5],可以通過將xik重寫為包i中示例的凸組合來替換式(3)左側的最大算子。
1.3 多示例回歸損失
回歸函數gw(·)用于預測通過3個子網的輸入示例的連續標記。這里,gw(·)遵循傳統的多示例約束[6]:對于包中的所有示例,gw(·)的最大預測應等于僅對每個包可用的真實值,如式(4)。
(4)
或者,式(4)相當于式(5)。
yi=gw(xi,d(i)),受約束于gw(xi,d(i))≥gw(xik),?k
(5)
式中,d(i)索引具有最大預測gw(·)的包i的示例。MDRR網絡的回歸損失函數定義,如式(6)。
(6)
式(6)受約束于條件式(7)。
gw(xi,d(i))≥gw(xik)
(7)
為了最小化Q(·),可以使用替代優化策略。在d(i)固定的情況下,Q(·)是相對于權重參數w的二次凸函數。在目前的步驟中,w可以評估gw(·)以檢索d(i)。對于一個看不見的包,它的預測可以通過將它的所有示例通過MDRR網絡并找到gw(·)的最大預測來實現。
1.4 反向傳播學習
為了求解最優參數w,對式(2)和式(6)進行了轉換,轉化為無約束形式,利用反向傳播算法[7]迭代更新網絡參數w。在每次迭代中,計算關于w的損失函數的導數,并用反向傳播的梯度更新相應的參數。采用帶動量項的隨機梯度下降法。動量重量設為0.9,最小批量為32。在開始時將全局學習率設置為0.004,并在各個時期衰減。
2 MDRR算法實現
在本節中,討論了MDRR的實現,該實現可從文本和圖像數據中預測房價。假設有一組房屋,并且每個房屋都提供了一組文字特征和一組房屋照片。將每個房屋視為一包示例,每個示例都代表房屋照片以及房屋的文字特征(例如,大小,房間數量等)。房屋價值在包裝級別提供。在網上市場上,一所房子通常有20至50張照片,并用多種文字特征加以描述。
2.1 用語義意識對損失進行排名
式(3)中的約束是無意義的,如果兩張房子的照片不是同一類別。對花園和廚房室等進行排名毫無意義。因此,將所有房屋照片(例如,花園,浴室,客廳等)分類,并在等式中應用約束。僅適用于同一類別的照片對,讓cik表示圖像xik的類別,為排序目的定義了語義感知目標函數,如式(8)。
(8)
公式(8)受限于式(9)和式(10)。

(9)
ξijl≥0,?l,?(i,j)
(10)
為了給一對測試房屋(i,j)排序,可以通過MDRR網絡對它們的每個示例進行排序,并測試式(1)是否成立。
2.2 帶有啟發式約束的回歸損失
在此進一步引入了一組人類啟發式方法來規范回歸損失函數式(6)的學習。這些啟發式方法來源于常識性知識,人們在感知房價時廣泛使用這些知識。例如,有3個臥室的房子往往比有一個臥室的房子更貴;獨戶的房子比公寓的價值更高。盡管個別的約束可能很弱,但這些約束的集合可以提供有用的信息,幫助預測房價。
形式上,讓C表示房屋對的集合(i,j)∈C,根據常識類型,房屋i的價值低于房屋j的價值。在此修改式(6)中的回歸損失函數,如式(11)。
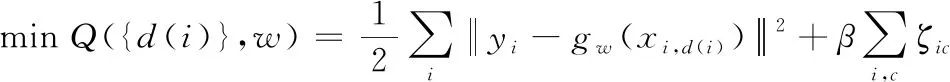
(11)
式中,受限于gw(xi,d(i))≥gw(xik),gw(xik)-gw(xcl)>1-ζic,?(i,c)∈C。
注意,根據不同的常識知識,C中的兩個房子可能有沖突的順序。式(11)簡單地利用這些常識作為軟約束來限制可行解空間。
2.3 照片分類
將所有的房屋照片分為11類:臥室、客廳、廚房、浴室、后院、餐廳、游泳池、車庫、儲藏室、鄰居和其他。收集了11個類別中每一個類別的200張照片,密集的作物子區域,并使用修剪的圖像來訓練具有分類損失的CNN網絡。為了對照片進行分類,在學習過的CNN網絡上進行轉發。預測將用于刪減式(8)中的無效約束。使用自動分類結果來減少人工操作。此外,在本研究中,每一個約束都被用作軟約束,并且沒有一個約束會支配訓練結果。
3 實驗
在這一部分中,將提出的MDRR方法應用于多模態房價預測問題,并將其與其他方法進行比較。
3.1 數據集
為了研究可視房屋評估問題,收集了一個包含文本特征、房屋照片和交易歷史的圖像數據集,數據集來自于美國房產的多重上市服務系統(Multiple Listing Service)。數據集包括約90萬張30 141棟房屋的照片。對于每套房子,使用最新的交易價格作為它的真實房價。
將數據集分成3個子集,分別用于培訓、驗證和測試,包括15 000,5 000和10 141個房屋。用11個類別對訓練/驗證圖像進行人工標注,并用它們訓練和評估CNN分類模型。
3.2 評估對象
該方法由3個子網絡和2個損失函數組成,利用文本特征和房屋照片預測房屋價值。
1.MDRR-1A是使用子網A處理文本特征的排名網絡。
2.MDRR-2A,使用子網工作A、子網C和回歸損失的回歸網絡。
3.MDRR-3A,一種使用子網A和子網C的聯合排序和回歸網絡。
4.MDRR-5A,一個聯合排序和回歸網絡。
3.3 評估指標
將上述方法應用于圖像數據集有兩個目的:房屋價值的回歸和房屋對的排序。為了回歸的目的,計算了每套房子的預測值與真實值之間的誤差,使用兩個誤差單位:(1)預測值與實際價格的絕對差;(2)誤差百分比,即實際房價的絕對誤差。對所有測試樣本的這兩個指標進行平均,并計算它們的標準偏差。為了排名的目的,只需計算測試樣本錯誤預測的百分比。同時為了更加客觀,也將結果與其他常用的回歸或排序方法進行了比較。
針對兩種設置評估上述算法:(1)在多示例設置中同時使用文本特征和照片;(2)僅使用文本特征并且多示例設置退化為監督設置。在這些算法中,NN和DR可以直接處理房屋照片。對于其他算法,在此將每一張照片通過訓練用于照片分類的CNN網絡,并使用最后一個隱藏層的輸出激活作為視覺特征向量。這種特征提取已經被廣泛應用于圖像相關的任務。為了獲得這些基線的最佳參數,在驗證子集上使用10倍交叉驗證過程,如圖2所示。

a 帶泳池的房屋
圖2顯示了MDRR-5A算法的運行結果。在每一子圖中展示了同一所房子的兩張照片。對于每一棟房子的照片,方框中為達到的最高價格預測gw(·)。最上面子圖中的上方是后院的照片,最下方是外景的照片。真正的房價標在每一個方框的頂部。可以觀察到,對房價的預測與人類的認知是一致的。特別是,圖2(a)的房屋中有舒適的家具、保養良好的植物、良好的天花板、巨大的泳池或其他附加條件,這些都比其他框上的房子有更高的房屋估價。所提出的方法能夠在訓練期間對這些視覺模式進行建模,并做出一致和準確的價格預測。三個房屋外觀示意圖,如圖3所示。

a
預測結果,如表1所示。

表1 預測結果
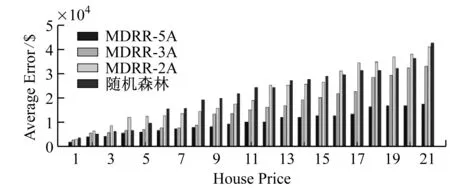
在這些房屋中,所提出的方法MDRR能夠準確地預測其值,而VGG-16和MDRR-3具有相對較大的估計誤差。這是因為MDRR-3只使用文本特征,VGG-16不使用排名損失。值得注意的是,MDRR-3和MDRR-5保留了這三所房子的相對順序,即A 各種回歸算法的平均誤差和標準差,如表2所示。 表2 回歸算法比較 不同價格區間的平均誤差,如圖4所示。 a 平均誤差 除了展示本研究的方法的結果外,還引入了隨機森林方法的結果。請注意,低價房的絕對誤差相對低于高價房的絕對誤差,這在直觀上是合理的。成對房屋排序的錯誤率,如表3所示。 表3 排序比較 從以上結果,可以得到以下觀察結果。(1)提出的MDRR網絡在兩個指標上都達到了最小的誤差。特別是,平均誤差小于5 000美元,考慮到房價在10萬至200萬美元之間變化,這在實踐中是令人鼓舞的;(2)利用MDRR-net、RF、NN或boosting等不同框架的房屋照片,可以減少評估誤差。以MDRR為例,MDRR-3A的平均誤差為15 700美元,如果另外訪問房屋照片,則可以減少到4 300美元;(3)聯合回歸和排名被證明是有效的,特別是對于提出的MDRR網絡。這可以通過MDRR-5A與其它的比較,或者MDRR-3A與MDRR-2A的比較來驗證;(4)提出的語義感知和常識知識可以進一步減少系統錯誤。此外,結果表明,提出的方法比最新的基于網絡的回歸方法能獲得更好的精度。雖然提出的方法也可以從先進的網絡結構中獲益,但是對所提出的框架和各種網絡結構的組合進行詳盡的測試超出了本文的研究范圍。在本研究的實驗設置中,MDRR-5使用房屋照片和房屋紋理特征作為學習回歸和排名網絡的輸入,而MDRR-3只使用文本房屋特征。考慮到數以千計的圖像數據可以為學習深度表示提供大量信息。更重要的是,基于VGG網絡的方法使用了一個完全監督的回歸損失,定義在房屋示例(即照片)和行李層標簽上,而不使用示例層標簽,預計不會有效。由于MDRR-5采用多示例公式,同時訓練回歸和排序損失,效果較好。 在這項工作中,研究了一種新穎的圖像任務,即房屋視覺評估,并將其表述為弱監督學習問題。主要工作有兩個方面。一方面,收集了一個綜合的圖像基準來研究視覺房屋評估問題,本研究實施了包括建議的回歸方法在內的多種回歸方法,并對建議的數據集進行了詳盡的評估。收集的數據集以及基線方法將被發布,以促進這一新方向的研究;另一方面,開發了一種用于視覺房屋評估的多示例學習方法,該方法可以利用文本數據和圖像數據共同訓練用于排名和回歸目的的深度表示。大量的比較實驗表明,本研究的方法可以高精度估計房屋價值。對單個組件的分析清楚地表明了所提出解決方案的技術可靠性。

4 總結
猜你喜歡
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
制造技術與機床(2019年10期)2019-10-26 02:48:08
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
電子制作(2018年18期)2018-11-14 01:48:06
兒童繪本(2018年5期)2018-04-12 16:45:32
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
