一種深度學(xué)習(xí)的網(wǎng)絡(luò)安全態(tài)勢(shì)評(píng)估方法
2021-01-29 04:22:42楊宏宇曾仁韻
西安電子科技大學(xué)學(xué)報(bào) 2021年1期
楊宏宇,曾仁韻
(中國(guó)民航大學(xué) 計(jì)算機(jī)科學(xué)與技術(shù)學(xué)院,天津 300300)
近年來,隨著互聯(lián)網(wǎng)的快速發(fā)展,通過互聯(lián)網(wǎng)進(jìn)行的攻擊問題越來越頻繁,帶來的危害也越來越嚴(yán)重。 我國(guó)互聯(lián)網(wǎng)態(tài)勢(shì)報(bào)告[1]中指出,在2019年上半年,我國(guó)網(wǎng)絡(luò)遭受了大量的、多樣的威脅攻擊,并針對(duì)此情況開展了網(wǎng)絡(luò)安全威脅治理工作;其中,采用的一個(gè)重要手段就是網(wǎng)絡(luò)安全態(tài)勢(shì)評(píng)估。網(wǎng)絡(luò)安全態(tài)勢(shì)評(píng)估是一種常用的、有效的解決方案。它綜合了影響網(wǎng)絡(luò)安全的指標(biāo),為網(wǎng)絡(luò)管理人員提供決策意見,從最大程度上降低網(wǎng)絡(luò)攻擊威脅產(chǎn)生的危害[2]。
文獻(xiàn)[3]提出了基于層次分析法和灰色關(guān)聯(lián)分析的多維系統(tǒng)安全評(píng)價(jià)方法,以系統(tǒng)安全評(píng)價(jià)模型構(gòu)建原則為指導(dǎo),構(gòu)建了環(huán)境安全、網(wǎng)絡(luò)安全、脆弱性安全的多維系統(tǒng)安全評(píng)價(jià)模型。文獻(xiàn)[4]將互聯(lián)網(wǎng)受到的網(wǎng)絡(luò)威脅作為態(tài)勢(shì)評(píng)估的重要指標(biāo),利用模糊邏輯推理系統(tǒng)改進(jìn)網(wǎng)絡(luò)安全威脅評(píng)估模型。然而,上述方式在面對(duì)新型的網(wǎng)絡(luò)威脅攻擊時(shí)不能做出及時(shí)反應(yīng)。
隨著神經(jīng)網(wǎng)絡(luò)、機(jī)器學(xué)習(xí)等信息技術(shù)在許多領(lǐng)域的成功應(yīng)用,在信息安全領(lǐng)域開始嘗試將這些技術(shù)融入網(wǎng)絡(luò)威脅態(tài)勢(shì)評(píng)估。文獻(xiàn)[5]引入動(dòng)量因子,對(duì)搜索算法進(jìn)行了優(yōu)化,提出了一種改進(jìn)反向傳播神經(jīng)網(wǎng)絡(luò)的網(wǎng)絡(luò)安全態(tài)勢(shì)定量評(píng)估方法。文獻(xiàn)[6]提出了結(jié)合樸素貝葉斯分類器的網(wǎng)絡(luò)安全態(tài)勢(shì)評(píng)估方法,從整體動(dòng)態(tài)上展示網(wǎng)絡(luò)當(dāng)前安全狀況。文獻(xiàn)[7]結(jié)合支持向量機(jī),并改良了布谷鳥算法預(yù)測(cè)網(wǎng)絡(luò)安全態(tài)勢(shì),該方法在KDD數(shù)據(jù)集上的性能達(dá)到了較高的精度。上述方法可以動(dòng)態(tài)評(píng)估網(wǎng)絡(luò)安全態(tài)勢(shì),但是面對(duì)如今的大量網(wǎng)絡(luò)威脅數(shù)據(jù),已經(jīng)不能滿足實(shí)時(shí)、直觀的評(píng)估需求。
在大數(shù)據(jù)背景下,結(jié)合深度神經(jīng)網(wǎng)絡(luò)的算法已經(jīng)應(yīng)用于海量威脅攻擊數(shù)據(jù)檢測(cè)。文獻(xiàn)[8]通過實(shí)驗(yàn)表明,相對(duì)于傳統(tǒng)的淺層網(wǎng)絡(luò)方法,深層網(wǎng)絡(luò)在檢測(cè)網(wǎng)絡(luò)威脅攻擊方面更加準(zhǔn)確和有效。文獻(xiàn)[9]應(yīng)用長(zhǎng)短期記憶網(wǎng)絡(luò)(Long-Short-Term Memory,LSTM)在CIDDS-001數(shù)據(jù)集上進(jìn)行訓(xùn)練和測(cè)試。盡管實(shí)驗(yàn)結(jié)果取得較高的準(zhǔn)確率,但是文中選擇的測(cè)試集是訓(xùn)練集的一部分,因此沒有表現(xiàn)出模型的泛化性。文獻(xiàn)[10]將自我學(xué)習(xí)(Self-Taught Learning,STL)與稀疏自動(dòng)編碼器(Sparse Auto Encoder,SAE)相結(jié)合,對(duì)NSL-KDD數(shù)據(jù)集的檢測(cè)準(zhǔn)確率有很大的提升。然而,該方法在訓(xùn)練過程中抑制了某些神經(jīng)元的傳播而且易出現(xiàn)不同數(shù)量的樣本檢測(cè)結(jié)果不平衡的現(xiàn)象。
針對(duì)上述方法的不足,筆者提出了基于深度學(xué)習(xí)的網(wǎng)絡(luò)安全態(tài)勢(shì)評(píng)估方法。為了解決數(shù)據(jù)集中不同類型攻擊的分類結(jié)果極度不平衡問題,提出一種欠過采樣加權(quán)(Under-Over Sampling Weighted,UOSW)算法對(duì)數(shù)據(jù)集進(jìn)行處理,結(jié)合深度自動(dòng)編碼器(Deep Auto Encoder,DAE)對(duì)網(wǎng)絡(luò)攻擊進(jìn)行分類。在得到網(wǎng)絡(luò)攻擊分類后,對(duì)每種攻擊類型進(jìn)行影響評(píng)估,并對(duì)網(wǎng)絡(luò)安全狀況進(jìn)行量化評(píng)估。通過實(shí)驗(yàn),證明文中方法可實(shí)現(xiàn)對(duì)網(wǎng)絡(luò)安全狀況的實(shí)時(shí)評(píng)估,評(píng)估效果更加高效、直觀,性能指標(biāo)優(yōu)于其他模型。
1 網(wǎng)絡(luò)安全態(tài)勢(shì)評(píng)估模型
筆者設(shè)計(jì)的網(wǎng)絡(luò)安全態(tài)勢(shì)評(píng)估模型包括態(tài)勢(shì)獲取、態(tài)勢(shì)分析和態(tài)勢(shì)評(píng)估3個(gè)部分。網(wǎng)絡(luò)安全態(tài)勢(shì)評(píng)估模型的結(jié)構(gòu)如圖1所示。

圖1 網(wǎng)絡(luò)安全態(tài)勢(shì)評(píng)估模型
(1) 態(tài)勢(shì)獲取
在此階段,獲取網(wǎng)絡(luò)中的流量數(shù)據(jù)。為了模擬網(wǎng)絡(luò)處理海量流量數(shù)據(jù)的情況,選取上述NSL-KDD數(shù)據(jù)集作為網(wǎng)絡(luò)流量。數(shù)據(jù)預(yù)處理后,輸入深度自編碼器進(jìn)行訓(xùn)練。
(2) 態(tài)勢(shì)分析
將測(cè)試 數(shù)據(jù)集輸入訓(xùn)練后的模型,記錄結(jié)果輸出的二分類結(jié)果和多分類結(jié)果,用于計(jì)算網(wǎng)絡(luò)安全態(tài)勢(shì)量化值。
(3) 態(tài)勢(shì)評(píng)估
根據(jù)測(cè)試的攻擊分類結(jié)果,計(jì)算網(wǎng)絡(luò)攻擊概率和各種網(wǎng)絡(luò)攻擊的影響值。另外,計(jì)算網(wǎng)絡(luò)安全態(tài)勢(shì)值并對(duì)網(wǎng)絡(luò)安全態(tài)勢(shì)進(jìn)行評(píng)估。詳細(xì)計(jì)算方法見下文。
2 深度自編碼器
2.1 深度自編碼器設(shè)計(jì)
2.1.1 模型結(jié)構(gòu)
自動(dòng)編碼器(Auto Encoder,AE)由編碼器和解碼器組成,主要應(yīng)用于數(shù)據(jù)降維和特征學(xué)習(xí)。輸入數(shù)據(jù)通過編碼器被映射到解碼器,解碼器可以用更精簡(jiǎn)的特征描述原始數(shù)據(jù)。深度自動(dòng)編碼器(Deep Auto Encoder,DAE)是一種改進(jìn)的自動(dòng)編碼器模型。文獻(xiàn)[11]深化了原有自動(dòng)編碼器的網(wǎng)絡(luò)結(jié)構(gòu),生成了DAE網(wǎng)絡(luò)。因?yàn)楹须[藏層更多,DAE的學(xué)習(xí)能力得到了提高,這使得它更有利于特征學(xué)習(xí)。
深度神經(jīng)網(wǎng)絡(luò)(Deep Neural Network,DNN)由于其準(zhǔn)確性和高效性,在入侵檢測(cè)中得到了廣泛的應(yīng)用。由于DNN包含了多個(gè)隱藏層,使得它的學(xué)習(xí)能力顯著提高。與傳統(tǒng)的機(jī)器學(xué)習(xí)分類器相比,DNN可以在更短的時(shí)間內(nèi)獲得更準(zhǔn)確的分類結(jié)果,因此,選擇DNN作為網(wǎng)絡(luò)攻擊數(shù)據(jù)的分類器,所提出的深度自編碼器模型(Deep Auto Encoder Deep Neural Network,DAEDNN)如圖2所示。

圖2 DAEDNN模型
由圖2可見,模型接收輸入數(shù)據(jù)后,先通過DAE網(wǎng)絡(luò)進(jìn)行特征學(xué)習(xí)并記錄學(xué)習(xí)結(jié)果,根據(jù)學(xué)習(xí)結(jié)果和DNN分類器,將輸入數(shù)據(jù)進(jìn)行分類,而后將其分類結(jié)果應(yīng)用于后續(xù)的網(wǎng)絡(luò)安全態(tài)勢(shì)量化評(píng)估過程。
DAEDNN模型不僅可以進(jìn)行二分類,也可以進(jìn)行多分類。在進(jìn)行二分類任務(wù)時(shí),模型的激活函數(shù)為sigmoid函數(shù),sigmoid函數(shù)將模型輸出值映射到0和1區(qū)間,其中,數(shù)值越靠近1,則越容易被判定為異常流量。sigmoid函數(shù)(Fsgm)的計(jì)算公式如下,
Fsgm(x)=(1+e-x)-1。
(1)
當(dāng)模型進(jìn)行多分類任務(wù)時(shí),模型的激活函數(shù)為softmax函數(shù),softmax也是將輸出映射到0和1區(qū)間,但是與sigmoid函數(shù)不同的是,各個(gè)類別的輸出值相加的值等于1,模型選擇輸出值最大的類別為預(yù)測(cè)的類別。softmax函數(shù)(Fsfm)的計(jì)算公式如下,
(2)
其中,K表示輸出可以被分為K個(gè)類,zi表示每一類所取得的值。
2.1.2 模型訓(xùn)練
在DAEDNN模型中,DAE模型進(jìn)行特征學(xué)習(xí)。為了讓DNN分類器充分學(xué)習(xí)DAE的特征提取結(jié)果和提高模型性能,減少模型過擬合的風(fēng)險(xiǎn),應(yīng)分次訓(xùn)練DAEDNN模型。
模型訓(xùn)練分為3個(gè)步驟:① 將訓(xùn)練數(shù)據(jù)輸入至DAE網(wǎng)絡(luò),進(jìn)行特征學(xué)習(xí),記錄訓(xùn)練完成的權(quán)重值。② DAE 模型訓(xùn)練結(jié)束后,組合DAE模型和DNN模型為DAEDNN模型,一起訓(xùn)練這兩個(gè)網(wǎng)絡(luò)。為了獲取DAE模型的訓(xùn)練結(jié)果,將DAEDNN模型中的DAE網(wǎng)絡(luò)的權(quán)重值設(shè)置為保留的權(quán)重值,并把DAE層的參數(shù)設(shè)置為不可訓(xùn)練,與DNN網(wǎng)絡(luò)一起進(jìn)行訓(xùn)練,此時(shí)網(wǎng)絡(luò)只會(huì)更新DNN網(wǎng)絡(luò)的參數(shù)。③ 將DAE層的參數(shù)設(shè)置為可訓(xùn)練,更新DAE網(wǎng)絡(luò)和DNN網(wǎng)絡(luò)的參數(shù)。訓(xùn)練過程中更新訓(xùn)練參數(shù),不僅可以獲取DAE層的特征學(xué)習(xí)結(jié)果,也提高了模型對(duì)數(shù)據(jù)的表征能力。
2.2 欠過采樣加權(quán)數(shù)據(jù)重采樣算法
2.2.1 數(shù)據(jù)集描述
選擇網(wǎng)絡(luò)安全領(lǐng)域相對(duì)權(quán)威的入侵檢測(cè)數(shù)據(jù)集NSL-KDD作為評(píng)估的數(shù)據(jù)源。NSL-KDD數(shù)據(jù)集改良于KDD99數(shù)據(jù)集,它刪除了重復(fù)的網(wǎng)絡(luò)流量數(shù)據(jù)記錄,這有助于分類器產(chǎn)生無偏差的結(jié)果[12]。NSL-KDD數(shù)據(jù)集包含41個(gè)特征和5種主要攻擊類型。文中使用的數(shù)據(jù)集信息如表1所示。

表1 KDD-NSL數(shù)據(jù)集信息
2.2.2 數(shù)據(jù)預(yù)處理
為了更方便、準(zhǔn)確地訓(xùn)練網(wǎng)絡(luò)模型,需要將數(shù)據(jù)集中的分類特征轉(zhuǎn)換為數(shù)字特征,并進(jìn)行數(shù)值歸一化。
(1) 特征數(shù)值化
NSL-KDD數(shù)據(jù)集有3個(gè)分類特征“protocol_type”、“service”和“flag”,分別包括3、64和10個(gè)類別。通過獨(dú)熱編碼技術(shù),將這3種分類特征轉(zhuǎn)化為只表示0和1的數(shù)據(jù)。對(duì)這3個(gè)分類特征進(jìn)行處理之后,數(shù)據(jù)集由41個(gè)特征維度變?yōu)?16個(gè)特征維度。
(2) 數(shù)值歸一化
數(shù)據(jù)集中某些特征的最小值與最大值之間存在顯著差異。為了減少不同數(shù)值水平對(duì)模型的負(fù)面影響,文中采用對(duì)數(shù)標(biāo)度法對(duì)特征值進(jìn)行標(biāo)度,使其歸一化到同一區(qū)間。數(shù)值歸一化的過程可以表示為
xnorm=(x-xmin)/(xmax-xmin) ,
(3)
其中,x表示特征原本的值,xmax和xmin為特征所取得的最大值和最小值。
2.2.3 欠過采樣加權(quán)數(shù)據(jù)重采樣算法
由表1可見,在訓(xùn)練數(shù)據(jù)集中,5類攻擊的數(shù)據(jù)量非常不均勻,其中,數(shù)據(jù)量最大的nomal類有67 343 條數(shù)據(jù),而DoS和U2R這兩種類型只包含52和995條數(shù)據(jù)。在訓(xùn)練深度學(xué)習(xí)模型的過程中,若訓(xùn)練數(shù)據(jù)較少,則會(huì)導(dǎo)致模型無法充分學(xué)習(xí)數(shù)據(jù)的特征,而若訓(xùn)練數(shù)據(jù)過多,則又可能導(dǎo)致模型過擬合,即模型學(xué)習(xí)到了數(shù)據(jù)本身以外的特征。因此,極不平衡的數(shù)據(jù)會(huì)導(dǎo)致模型的學(xué)習(xí)效果不佳,導(dǎo)致數(shù)據(jù)量大的類別識(shí)別準(zhǔn)確度較高,反之較小。
數(shù)據(jù)分析中的過采樣和欠采樣是用來調(diào)整數(shù)據(jù)集類分布的技術(shù),也稱為數(shù)據(jù)重采樣。欠采樣通常是刪除數(shù)據(jù)量過大的類別的些許樣本,而過采樣增加了數(shù)據(jù)中少數(shù)樣本的數(shù)據(jù)量,以達(dá)到數(shù)據(jù)平衡。為解決數(shù)據(jù)量分布不平衡的問題,提高模型檢測(cè)少數(shù)類的精度,筆者提出一種過采樣、欠采樣和加權(quán)相結(jié)合的欠過采樣加權(quán)(Under-Over Sampling Weighted,UOSW)算法。該算法步驟設(shè)計(jì)如下:
設(shè)原始數(shù)據(jù)集為S1,輸出的數(shù)據(jù)集為S2,需要進(jìn)行重采樣處理的數(shù)據(jù)類型為typei,其原始數(shù)據(jù)集和樣本數(shù)量為Si和xi。
步驟1 計(jì)算數(shù)據(jù)集中每種類型的權(quán)重wi。在網(wǎng)絡(luò)訓(xùn)練中,當(dāng)訓(xùn)練集中每個(gè)類別的數(shù)據(jù)量非常接近(達(dá)到平均值,以下用average代替)時(shí),網(wǎng)絡(luò)的識(shí)別準(zhǔn)確率會(huì)很高。因此,文中計(jì)算每種類型的實(shí)際樣本量與理想樣本量之間的差值作為權(quán)重,以達(dá)到每種類型的均衡值。
(4)
其中,n表示數(shù)據(jù)集包含n種類別。
步驟2 數(shù)據(jù)欠采樣。對(duì)于數(shù)據(jù)量過大的類型,進(jìn)行數(shù)據(jù)欠采樣,使處理后的數(shù)據(jù)樣本接近平均值(average)。使用Python中sklearn庫(kù)的“train_test_split”方法將數(shù)據(jù)集Si分為兩個(gè)數(shù)據(jù)集Si-train,Si-remain。將Si-train作為訓(xùn)練集,并加入S2,其中,Si-train的數(shù)據(jù)量大小si=xi×wi;Si-remain用于接下來的數(shù)據(jù)過采樣操作,將其加入數(shù)據(jù)集Sremain。
步驟 3 數(shù)據(jù)過采樣。應(yīng)用過采樣算法SMOTE[13]處理數(shù)據(jù)量很少的類別的樣本。SMOTE的核心是在現(xiàn)有少數(shù)類樣本的基礎(chǔ)上生成新的同類樣本。由于SMOTE算法最初是針對(duì)二分類問題,而本文研究中存在多分類問題,因此對(duì)算法進(jìn)行了以下改進(jìn):
(1) 合并其他類型數(shù)據(jù)。將步驟2中經(jīng)過欠采樣處理的數(shù)據(jù)集Sremain和原始數(shù)據(jù)集中的少量類型的數(shù)據(jù)集合并,表示為Sunion。
(2) 改變標(biāo)簽。經(jīng)過(1),Sunion中包含與n種類別的數(shù)據(jù)。由于SMOTE算法只針對(duì)于二分類,因此要將需要進(jìn)行過采樣的類型與其他類型區(qū)分開來。將數(shù)據(jù)集Sunion的標(biāo)簽更改為同一類型,但不同于typei。
(3) 確定數(shù)據(jù)量大小。為了平衡數(shù)據(jù)集,需要對(duì)少數(shù)類樣本進(jìn)行擴(kuò)展,設(shè)擴(kuò)展后的數(shù)據(jù)量大小為si其中,si=xi×wi,wi是數(shù)據(jù)類型typei的權(quán)重。
(4) 數(shù)據(jù)過采樣。使用Python中imblearn庫(kù)的SMOTE方法,結(jié)合其他類型的數(shù)據(jù)生成所需的數(shù)據(jù),將其加入S2。
重復(fù)(1)~(4),直到數(shù)據(jù)量少于平均值的類型全部完成過采樣操作。
3 網(wǎng)絡(luò)安全態(tài)勢(shì)評(píng)估
3.1 網(wǎng)絡(luò)攻擊影響值
NSL-KDD數(shù)據(jù)集包括5種類型的網(wǎng)絡(luò)數(shù)據(jù):Normal、DoS、U2R、R2L和Probe。上述攻擊的基本信息如表2所示。

表2 5種攻擊類型的基本情況
基于通用漏洞評(píng)分系統(tǒng)(CVSS)制定了攻擊影響值評(píng)定表[14]。機(jī)密性(C)、完整性(I)和可用性(A)得分如表3所示。

表3 攻擊影響值評(píng)定表
每種攻擊類型的影響值(Ii)計(jì)算公式如下:
Ii=Ci+Ii+Ai。
(5)
3.2 網(wǎng)絡(luò)安全態(tài)勢(shì)量化
量化網(wǎng)絡(luò)安全態(tài)勢(shì),可以更直觀地分析網(wǎng)絡(luò)整體狀況。本文的網(wǎng)絡(luò)安全態(tài)勢(shì)量化評(píng)估過程主要包括4個(gè)部分:攻擊分析、計(jì)算攻擊的影響、計(jì)算網(wǎng)絡(luò)安全態(tài)勢(shì)值和網(wǎng)絡(luò)安全態(tài)勢(shì)定量評(píng)估。每個(gè)部分的處理過程設(shè)計(jì)如下:
(1) 攻擊分析
從測(cè)試數(shù)據(jù)集中隨機(jī)選取若干組數(shù)據(jù),并將其輸入到DAEDNN模型中,對(duì)其進(jìn)行二進(jìn)制和多分類,記二分類中檢測(cè)到的攻擊比例記為攻擊概率(attack probability,p)。
(2) 計(jì)算攻擊的影響值
結(jié)合表2、表3確定每一類攻擊類型的C、I、A值,并根據(jù)式(5)確定綜合的攻擊影響值。
(3) 計(jì)算網(wǎng)絡(luò)安全態(tài)勢(shì)值
網(wǎng)絡(luò)安全態(tài)勢(shì)值綜合考慮了網(wǎng)絡(luò)受到的全部攻擊和每種攻擊會(huì)對(duì)網(wǎng)絡(luò)造成的危害程度。設(shè)網(wǎng)絡(luò)安全態(tài)勢(shì)值為
(6)
其中,p為式(1)中所得出的攻擊概率,n和N表示一共有n種類型的數(shù)據(jù)和N個(gè)樣本,Ii表示每種攻擊類型的影響值,ti表示每種攻擊的出現(xiàn)次數(shù),tn為normal類型出現(xiàn)的次數(shù)。由于normal類型是正常的網(wǎng)絡(luò)數(shù)據(jù)流,對(duì)網(wǎng)絡(luò)的機(jī)密性、完整性和可用性不會(huì)有影響,因此它的影響分?jǐn)?shù)為0,只需要計(jì)算n-1種攻擊類型的影響分值即可。
(4) 網(wǎng)絡(luò)安全態(tài)勢(shì)定量評(píng)估
參考《國(guó)家突發(fā)公共事件應(yīng)急預(yù)案》[15]對(duì)網(wǎng)絡(luò)安全形勢(shì)進(jìn)行分類。根據(jù)網(wǎng)絡(luò)安全態(tài)勢(shì)值0.00~0.20、0.21~0.40、0.41~0.60、0.61~0.80和0.81~1.00的5個(gè)區(qū)間,將網(wǎng)絡(luò)安全態(tài)勢(shì)嚴(yán)重程度劃分為安全、低風(fēng)險(xiǎn)、中等風(fēng)險(xiǎn)、高風(fēng)險(xiǎn)和超風(fēng)險(xiǎn)等5個(gè)級(jí)別。
4 實(shí)驗(yàn)結(jié)果與分析
實(shí)驗(yàn)的硬件環(huán)境為:Intel(R) Xeon(R) Silver處理器,顯卡為NVIDIA Quadro P2000,內(nèi)存為32 GB。訓(xùn)練和測(cè)試實(shí)驗(yàn)均在Windows 64位操作系統(tǒng)上進(jìn)行。使用的編程語(yǔ)言和機(jī)器學(xué)習(xí)庫(kù)為Python3.5和TensorFlow2.0。模型的訓(xùn)練和測(cè)試均使用GPU加速。
4.1 評(píng)價(jià)指標(biāo)
文中所用的評(píng)價(jià)指標(biāo)如下所示:
真陽(yáng)性(True Positive,TP):表示被模型預(yù)測(cè)為攻擊樣本而實(shí)際也是攻擊樣本的次數(shù)。
假陽(yáng)性(False Positive,F(xiàn)P):表示被模型預(yù)測(cè)為正常樣本而實(shí)際是攻擊樣本的次數(shù)。
真陰性(True Negative,TN):表示被模型預(yù)測(cè)為正常樣本而實(shí)際也是正常樣本的次數(shù)。
假陰性(False Negative,F(xiàn)N):表示被模型預(yù)測(cè)為攻擊樣本而實(shí)際是正常樣本的次數(shù)。
下列公式中,PT,PF,NT和NF分別表示真陽(yáng)性,假陽(yáng)性,真陰性和假陰性。
準(zhǔn)確率(Precision,P):表示模型預(yù)測(cè)正確的攻擊樣本頻率。準(zhǔn)確率越高,誤報(bào)率越低。它可以表示為
P=PT/(PT+PF) 。
(7)
召回率(Recall,R):表示被模型正確分類的攻擊樣本與實(shí)際攻擊樣本的百分比。它可以表示為
R=PT/(PT+NF) 。
(8)
F1值(F1-score,F(xiàn)):表示綜合考慮了模型的準(zhǔn)確率和召回率。它可以表示為
F=2PR/(P+R) 。
(9)
4.2 模型二分類結(jié)果
在二分類任務(wù)時(shí),選擇ROC曲線和AUC面積來反映分類模型的性能。ROC曲線表示不同閾值設(shè)置下分類模型的性能;AUC面積為ROC曲線下的面積。面積越大,表示模型的性能越好;通過面積可以直觀地對(duì)比各個(gè)模型。
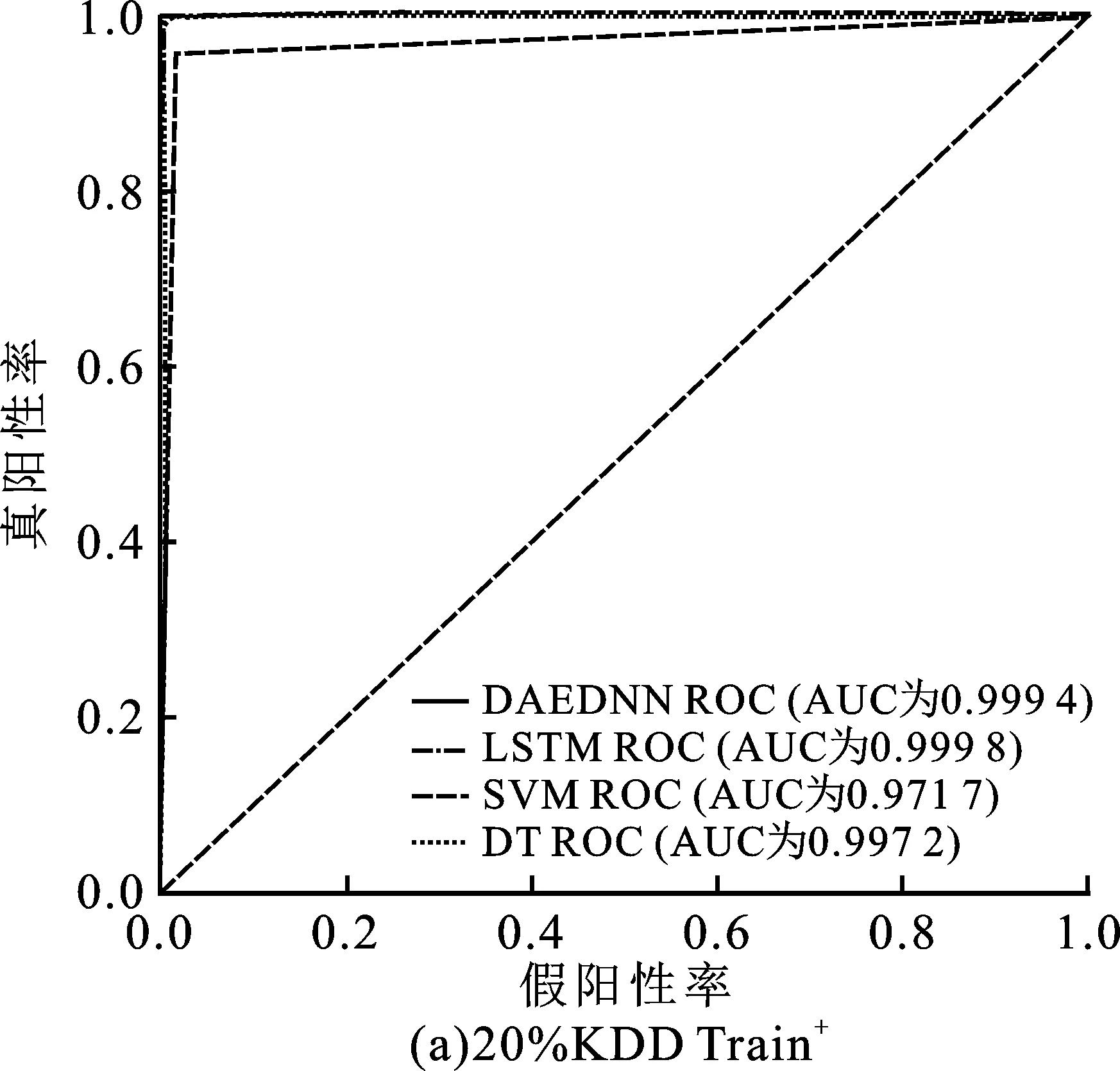
在二值分類任務(wù)中,模型只需要區(qū)分?jǐn)?shù)據(jù)是攻擊數(shù)據(jù)還是正常數(shù)據(jù)。為了檢驗(yàn)文中模型的有效性,將筆者提出的DAEDNN與決策樹(Decision Tree,DT)[8]、支持向量機(jī)(Support Vector Machine,SVM)[8]和長(zhǎng)短期記憶網(wǎng)絡(luò)(Long Short-Term Memory,LSTM)[9]等模型進(jìn)行了比較。為了驗(yàn)證文中模型的泛化性,使用KDDTrain+的80%數(shù)據(jù)進(jìn)行訓(xùn)練,分別對(duì)剩下的20%和KDDTest+進(jìn)行測(cè)試。4種模型的二分類結(jié)果如圖3所示。
從圖3(a)可以看出,在使用20% KDDTrain+對(duì)4種模型進(jìn)行測(cè)試時(shí),4種模型均表現(xiàn)出較好的準(zhǔn)確性和泛化能力。這是由于訓(xùn)練集和測(cè)試集來源于同一集合,模型學(xué)習(xí)到的特征可以完全應(yīng)用于測(cè)試數(shù)據(jù)集,所以能得到理想的結(jié)果。然而,從圖3(b)可見,如果使用KDDTest+數(shù)據(jù)集作為測(cè)試數(shù)據(jù)集,4個(gè)模型的準(zhǔn)確性則會(huì)降低。這是因?yàn)闇y(cè)試訓(xùn)練集中存在一些與訓(xùn)練數(shù)據(jù)集數(shù)據(jù)格式不同的樣本,這種情況與真實(shí)的網(wǎng)絡(luò)情況一致,即模型面臨眾多未知攻擊類型。從圖3(b)可見,在使用KDDTest+數(shù)據(jù)集進(jìn)行模型測(cè)試的情況下,DAEDNN模型的準(zhǔn)確率明顯優(yōu)于其他3個(gè)模型,分別比DT、SVM和LSTM高出近13.35%、16.17%和2.72%,說明DAEDNN模型的學(xué)習(xí)能力更強(qiáng),具有較好的泛化性。
4.3 模型五分類結(jié)果
使用KDDTest+數(shù)據(jù)集對(duì)DT、SVM、LSTM、DAEDNN和應(yīng)用UOSW算法的DAENDD這5種模型進(jìn)行檢驗(yàn),并選取準(zhǔn)確率、召回率和F1值作為評(píng)價(jià)指標(biāo),對(duì)各種模型進(jìn)行比較分析。不同模型的指標(biāo)得分如圖4所示,圖中的縱坐標(biāo)表示評(píng)價(jià)指標(biāo)的百分?jǐn)?shù),數(shù)值越高,模型性能越好。
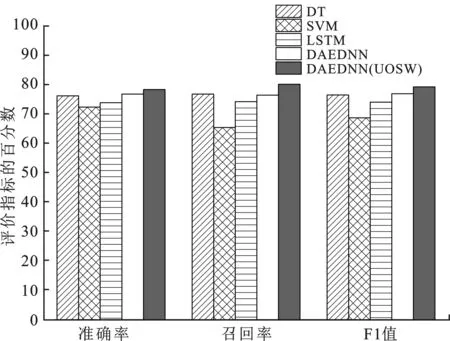
圖4 不同模型的各類指標(biāo)得分
從圖4可見,DAEDNN(UOSW)模型在準(zhǔn)確率、召回率和F1值等方面都優(yōu)于其他4種模型。實(shí)驗(yàn)結(jié)果表明,DAEDNN(UOSW)提高了少數(shù)訓(xùn)練數(shù)據(jù)樣本的攻擊類型的召回率和準(zhǔn)確率,而對(duì)擁有大量訓(xùn)練樣本的攻擊檢測(cè)性能并沒有降低。
值得注意的是,結(jié)合文中的UOSW算法后,DAEDNN的準(zhǔn)確率和召回率更高,泛化能力更強(qiáng)。與DT、SVM和LSTM模型相比,DAEDNN(UOSW)的F1值分別提高了約2.77%、10.5%和5.2%。
4.4 網(wǎng)絡(luò)安全態(tài)勢(shì)量化評(píng)估
從測(cè)試數(shù)據(jù)集中隨機(jī)選取相同數(shù)量的測(cè)試樣本,對(duì)網(wǎng)絡(luò)安全狀況進(jìn)行了量化評(píng)估,并對(duì)于分別用不同的模型計(jì)算網(wǎng)絡(luò)安全態(tài)勢(shì)值,其中20組測(cè)試的網(wǎng)絡(luò)安全態(tài)勢(shì)值如圖5所示。

圖5 20組測(cè)試的網(wǎng)絡(luò)安全態(tài)勢(shì)值
由圖5可見,基于DAEDNN模型計(jì)算出的網(wǎng)絡(luò)安全態(tài)勢(shì)值最貼合樣本的實(shí)際安全態(tài)勢(shì)值,相比于SVM和DT這兩類傳統(tǒng)的機(jī)器學(xué)習(xí)模型,DAEDNN和LSTM這兩類深度學(xué)習(xí)的方法更能表示數(shù)據(jù)的真實(shí)情況。其他3種模型的態(tài)勢(shì)值與實(shí)際態(tài)勢(shì)值相差較大的原因是,訓(xùn)練樣本中存在樣本量極少的攻擊類型,導(dǎo)致模型無法充分學(xué)習(xí)到這類攻擊的特征。而DAEDNN模型應(yīng)用了UOSW算法,提高了模型檢測(cè)少樣本攻擊類型的準(zhǔn)確率。所提出模型計(jì)算出的態(tài)勢(shì)值與實(shí)際態(tài)勢(shì)值之間存在些許差異,但大多數(shù)態(tài)勢(shì)值都落在了相同的區(qū)域內(nèi),根據(jù)3.2節(jié)定義的網(wǎng)絡(luò)安全態(tài)勢(shì)嚴(yán)重程度和實(shí)際情況相符。
5 結(jié)束語(yǔ)
筆者針對(duì)傳統(tǒng)網(wǎng)絡(luò)安全態(tài)勢(shì)評(píng)估方法在處理大量網(wǎng)絡(luò)數(shù)據(jù)時(shí)效率低的缺點(diǎn),提出一種深度學(xué)習(xí)的網(wǎng)絡(luò)安全態(tài)勢(shì)評(píng)估方法。該方法首先結(jié)合了自動(dòng)編碼器和深度神經(jīng)網(wǎng)絡(luò)組成DAEDNN模型,用于對(duì)網(wǎng)絡(luò)攻擊進(jìn)行識(shí)別。根據(jù)識(shí)別的結(jié)果,計(jì)算攻擊概率和攻擊影響值,從而得出網(wǎng)絡(luò)安全態(tài)勢(shì)量化值。通過安全態(tài)勢(shì)量化值,可以更直觀地反映網(wǎng)絡(luò)安全態(tài)勢(shì)。實(shí)驗(yàn)結(jié)果表明,筆者提出的模型在二分類和多分類的攻擊檢測(cè)方面優(yōu)于其他模型。此外,在進(jìn)行多種攻擊類型檢測(cè)時(shí),結(jié)合所提出的UOSW算法,可以提高模型對(duì)擁有少量訓(xùn)練樣本的攻擊的檢測(cè)準(zhǔn)確率,從而可以更準(zhǔn)確地評(píng)估網(wǎng)絡(luò)安全態(tài)勢(shì)。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中國(guó)生殖健康(2019年10期)2019-01-07 01:21:04
信息安全研究(2018年12期)2018-12-29 11:01:46
小學(xué)生必讀(中年級(jí)版)(2018年4期)2018-07-05 06:00:48
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
