雙流融合的動作識別方法研究
2021-02-04 06:53:16
軟件導刊 2021年1期
(安慶師范大學計算機與信息學院,安徽安慶 246133)
0 引言
動作識別在各種領域應用廣泛,如公共場所安全、醫療服務和教育教學等[1]。人體動作識別中的數據獲取大都依賴視覺傳感器(如相機)或者可穿戴慣性傳感器,通過構建合適的網絡模型對數據中的特征進行學習,實現動作分類[2-3]。大規模人體動作數據集[3-4]的建立和多種檢測方法[5-7]的引入,加快了人體動作識別領域的發展。目前,在面部動作及常見肢體動作如行走、跳躍等方面實現了較高的識別精度。
深度學習(Deep Learning)通過網絡擬合方式自動挖掘數據中的信息特征,成為動作識別領域的新方向。對于數據集而言,基于深度學習的動作識別方法可以分為基于視頻數據(Video-based)的識別方法與基于骨骼數據(Skele?ton-based)的識別方法。
傳統基于視頻數據的動作分類方法根據視頻幀中的空間信息和時間域上的信息表示進行建模。Simonyan 等[2]提出雙流(Two-Stream)的識別方法,對視頻圖像和密集光流(Optical flow)分別訓練卷積神經網絡(Convolutional Neu?ral Network,CNN),再對輸出的概率求均值并輸出最終識別率;Donahue 等[8]使用遞歸神經網絡(Recurrent Neural Network,RNN)替代基于流的設計;Wang 等[9]通過稀疏采樣,使用加權平均方法處理時間/空間流特征圖,提升算法準確性。雙流方法既可以學習視頻圖片的色彩輪廓信息,又可以學習動作的短時時序信息,但對于動作的長時時序信息網絡無法較好處理。
三維卷積神經網絡(3D Convolutional Neural Network,3D CNN)對若干連續幀的視頻圖像建立模型,可以較好地處理時間序列信息。如Tran 等[10]引入3D CNN 作為特征提取器,使用反卷積解釋模型;王永雄等[11]將3D CNN 融入殘差網絡,提取動作的時空特征,實現了較好結果。3D CNN 既可以通過網絡模型學習視頻數據單幀圖像的位置輪廓信息,又可以學習連續幀之間的時間信息。但是網絡參數量巨大,訓練速度較慢。
目前,通過在視頻圖像中添加注意力機制,一些方法也達到了較好分類結果。Sharma 等[12]使用帶有注意力模塊的CNN 網絡作為圖像編碼器,對編碼過的圖像信息使用三層長短時記憶網絡(Long Short-Term Memory,LSTM)學習圖像在時序上的變化,最終達到較好動作識別效果;Yao等[13]使用3D CNN 和RNN 結合的網絡作為編碼/解碼器,引入注意力機制學習全局上下文信息;Sudhakaran 等[14]使用添加注意力機制的網絡自發關注手部運動,再利用卷積長短時記憶網絡(convolutional Long Short-Term Memory,conv LSTM)學習時間序列信息,達到較好效果;曹晉其等[15]使用CNN 與LSTM 相結合的方式,在CNN 中添加注意力機制,達到較好識別效果。注意力機制在一定程度上讓網絡模型的參數聚焦于某些關鍵像素,更好地學習視頻圖像的色彩信息和輪廓信息。但網絡過度關注某一區域也會導致全局信息缺失。
視頻數據有良好的色彩信息和輪廓信息,通過網絡模型可以充分地學習到這些信息。并且,視頻數據采集方便,構建大規模數據集也相對容易。但是視頻數據通過相機采集,只存在二維平面的位置特征。對于視頻圖像,目前大部分網絡模型只能學習人員的色彩輪廓信息,信息豐富度較低,這也是此類方法識別精度較低的原因。
基于骨骼數據的識別方法通過構建可以學習關節點坐標的空間位置信息和關節點在時序上變化信息的網絡模型,實現分類效果。Du 等[16]根據人體結構將骨骼分為5個部分,然后分別將它們輸入到分層遞歸神經網絡(Bidi?rectional Recurrent Neural Network,BRNN)中以識別動作;Song 等[5]使用3 層LSTM 網絡,并在空間和時間上加入At?tention 機制,使網絡關注重要的關節點和時間點,達到較好識別效果;胡立樟[17]提出一種綜合LSTM 與最大池化的設計,能夠學習不定時間跨度的上下文特征;Li 等[18]提出分層CNN 網絡,學習聯合共現和時間演化的表示形式。通過將人體關節點的三維坐標作為輸入,可以學習更豐富的空間位置信息;而以LSTM 處理時間序列信息,可以讓網絡模型學習更長時間。但只是簡單地將人體關節的三維坐標作為一個整體輸入到網絡模型中,并未充分考慮人體關節點之間的連接關系。
圖卷積(GraphConvolutional Network,GCN)在動作識別領域的應用讓這一領域有了新的發展。Yan 等[7]首次將GCN 引入動作識別領域,使識別結果有了較大突破。Si等[19]應用圖神經網絡捕獲空間結構信息,使用LSTM 建模時間動態;Si 等[6]在已有基礎上引入Attention 機制,使用LSTM 網絡學習時間特征,獲得NTU RGB+D 數據集[3]的較好分類結果。該方法通過圖卷積,讓網絡模型學習人體關節點之間的相對位置關系,豐富空間位置信息內容。
骨骼數據具有空間三維信息,可以直接體現人體運動的空間變換。但由于缺乏圖像的輪廓信息,對于差異度較小的動作,只使用骨骼數據,網絡往往難以區分。同時,采集人體關節點數據需要專業設備,在某些情況下并沒有采集數據的條件。
以上方法均是對單一類型數據進行建模,各有利弊。本文分別對兩種數據建立不同的網絡模型,并對兩種模型輸出結果進行概率融合。該方法在一定程度上結合了兩種數據的優點,較為有效地實現了兩種數據的信息融合。
1 相關原理
1.1 圖卷積原理
圖卷積是對于輸入數據首先構建圖拓撲結構,再使用類似卷積運算的方式處理這些數據。對于基于骨骼數據的動作識別,通過圖卷積可以很好地學習骨骼關節點之間的空間位置關系,從而對動作進行較好地分類識別。
圖卷積與傳統卷積類似之處便在于,圖卷積的計算過程也是一個先采樣再加權求和的過程。圖卷積的采樣方式與傳統卷積類似,傳統卷積對中心像素點及周圍像素點進行采樣后輸入卷積網絡,而圖卷積則對中心節點及鄰居節點進行采樣后輸入網絡。本文方法只對中心節點及周圍一階鄰居點進行采樣,對于與中心節點相連節點個數不足3 個的,會補上節點信息為空的啞節點。兩者卷積參數有不同定義,傳統卷積參數完全由網絡反向傳播計算,而圖卷積參數是通過添加拉普拉斯矩陣后反向傳播并訓練得到[20]。對于任意圖結構,在已知節點所包含的初始特征信息后都可以通過圖卷積的方式計算聚合后的信息F:
其中,D 表示采樣后圖結構的度矩陣(Degree Matrix),A 表示采樣后圖結構的鄰接矩陣(Adjacency Matrix),X 表示鄰居節點所包含的信息,ω表示網絡參數。通過合適的網絡訓練參數ω,可以將周圍節點的信息聚合到中心節點,從而構建更豐富的節點信息。再對這些信息使用分類器分類,可以實現較好的動作分類效果。
1.2 注意力機制原理
卷積神經網絡對圖像進行卷積計算并不斷凝煉圖像像素特征,其網絡最后一層的輸出包含豐富的信息。而將這些信息輸入全連接層時訓練得到的參數客觀上反映了最后特征圖有哪些區域應該值得關注。通過對所有通道的結果求和,輸出注意力熱圖(見圖1)[21],這樣的模塊稱之為注意力模塊。注意力參數α可以表示為:
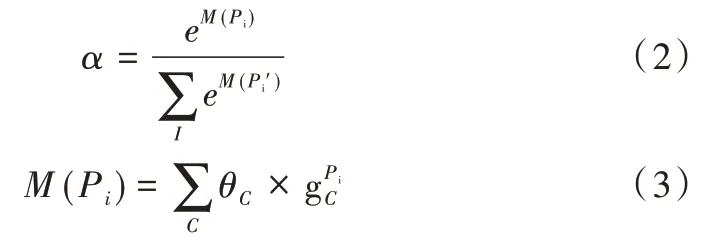

其中,?表示元素乘法(Hadamard Product)。
通過這種方法可以使網絡模型自發關注重要部位,從而有利于后續動作分類。
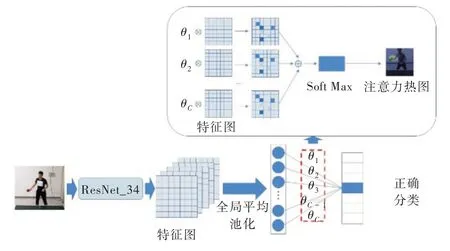
Fig.1 Attention heat map generation圖1 注意力熱圖生成
2 本文方法
2.1 基于骨骼數據的動作識別方法
在具有N個關節點和T幀的骨骼序列上構造空間無向圖結構G=(V,E)。其中,節點集合V={vti|t=1,…,T,i=1,…,N}包括了骨骼序列的所有節點。作為網絡輸入,節點vti上的特征向量X(vti)由第t幀第i個關節點的三維坐標向量組成。根據人體結構的連通性將一幀內的關節用邊連接,每個關節將在連續的幀中連接到同一關節點。而邊的集合E由兩個子集組成:第1 個子集ES={vtivtj|(i,j)∈H}表示每一幀的骨骼連接,其中H是人體關節點的總數;第2 個子集EF={vtiv(t+1)i}表示連續幀中相連的關節點(見圖2)。
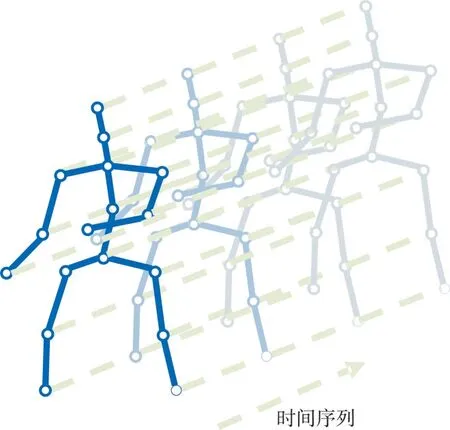
Fig.2 Visual structure of input data圖2 輸入數據可視化結構
對于輸入數據,先使用圖卷積編碼關節點在空間中的位置關系。在單幀的人體關節點連接結構中,在關節點vti的鄰居集上定義采樣函數。其中,表示到vti的任意路徑的最小長度。設置D=1,即只選取節點vti的一階鄰居節點,這一步稱之為采樣。同時,保證每次采樣N=4 個關節點,對不滿足這一條件的采樣通過添加節點信息為空的啞節點予以解決。結合式(1),單幀視頻的單個節點vti通過圖卷積聚合后的特征輸出可表示為:
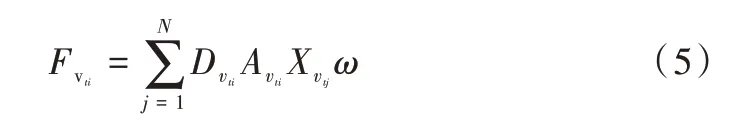
而對于時間維度的關節點連接則簡單得多。本文對時間維度按照完全相同的時間間隔采樣,因此時間維度的關節連接是規則的,可按照傳統卷積方法計算。對于時間維度的關節點連接結構,設計一個大小為3×1 的卷積核,在時序上以步長為1 的方式移動。對所有時間序列進行卷積處理,構建更豐富的信息。這樣的模塊被稱為TCN 模塊。
本文方法對于空間維度和時間維度兩個不同維度的處理是交替進行的,本文人體動作識別網絡結構如圖3 所示。
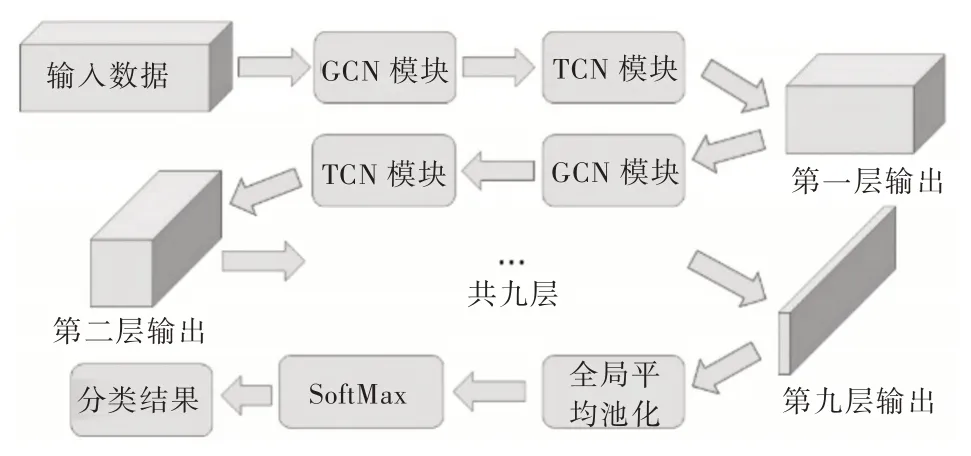
Fig.3 Human action recognition network based on skeleton data圖3 基于骨骼數據的人體動作識別網絡
2.2 基于視頻數據的動作識別方法
基于視頻數據的動作識別方法在識別效果上會受到視頻背景信息的影響,因此,本文首先對輸入的視頻數據進行處理,手動裁剪出人員所在區域,并將這些區域的圖片作為數據輸入識別網絡。
將處理過的視頻數據按時間序列逐幀輸入殘差網絡[22](ResNet),通過殘差網絡編碼視頻幀所包含的色彩信息和輪廓信息,并將添加注意力機制的已編碼數據輸入conv LSTM[23](對時間序列信息進行編碼)。整體網絡結構如圖4 所示。
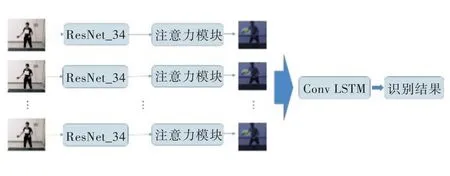
Fig.4 Action recognition network based on video data圖4 基于視頻數據的動作識別網絡
2.3 雙流融合的動作識別方法
基于視頻數據的雙流融合方法會先提取出視頻數據的密集光流,使用CNN 同時處理視頻數據和光流數據。將使用CNN 編碼過后的特征信息輸入SoftMax 分類器,該分類器會對每一組用于測試的數據進行分類,并輸出該組數據屬于某種類別的概率。對兩種數據流的輸出概率求均值,實現信息融合,信息融合后的綜合識別率往往高于單個數據流的識別率。
本文借鑒這種信息融合方法,分別使用時空圖卷積框架下的人體動作識別網絡和基于視頻數據的人體動作識別網絡,并對網絡進行訓練。使用收斂后的參數進行測試,將每個視頻片段的分類概率以矩陣形式保存。對兩種數據流輸出概率求均值后輸出最終分類結果,如圖5 所示。
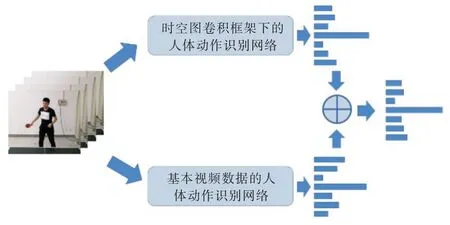
Fig.5 Two-stream fusion method圖5 雙流融合方法
3 實驗結果與分析
使用NTU RGB+D 數據集[3]測試本文方法有效性。該數據集是目前較大的公開動作識別數據集,該數據集由56 880 個動作樣本組成,包括40 名人員的60 種日常單人/雙人動作(如喝水、脫衣服、鍵盤打字與走向某人等)。該數據集通過Kinect v2.0 采集包含25 個關節點的三維坐標的骨骼數據,并通過相機采集視頻數據。
對于基于骨骼數據的動作識別網絡,設置初始學習率為0.1,并且每10 個epochs 學習率縮小為原來的10%。網絡訓練共80 個epochs,使用標準交叉熵損失函數進行反向傳播。
對于基于視頻數據的動作識別完成后,設置初始學習率為0.001。網絡訓練300 個epochs,使用標準交叉熵損失函數進行反向傳播。

Table 1 NTU RGB+D data set recognition results表1 NTU RGB+D 數據集識別結果
本文方法識別率達83.76%,比H-RNN、STA-LSTM、ST-GCN 方法的識別率均有不同程度的提升,對比結果如表1 所示。通過多人動作注意力熱圖可視化(見圖6)結果可以發現,對于數據集中的雙人動作,注意力熱圖往往只能關注其中一人,而對另一人關注度不足,導致該識別方法對動作分辨能力不佳,從而影響最終識別精度。

Fig.6 Multi-person action attention heat map visualization圖6 多人動作注意力熱圖可視化
4 結語
本文提出一種針對動作識別的結合骨骼數據與視頻數據的雙流融合方法。該方法通過對人體動作的骨骼數據和視頻數據分別建立網絡模型,并對兩種網絡分類器的輸出概率進行融合,有效地實現了骨骼數據與視頻數據的信息融合,提高了人體動作識別率。
下一步計劃是提出更好的信息融合方式,充分發揮不同類項數據優點,實現信息互補,進一步提高識別率。
猜你喜歡
動漫界·幼教365(大班)(2021年4期)2021-05-23 21:33:16
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
中華手工(2017年2期)2017-06-06 23:00:31
作文周刊·小學一年級版(2016年28期)2017-06-03 00:28:49
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
少兒科學周刊·少年版(2015年4期)2015-07-07 20:56:37
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
