面向超級計算機(jī)系統(tǒng)的大規(guī)模圖遍歷優(yōu)化
2021-02-21 02:57:02甘新標(biāo)肖調(diào)杰陳旭光雷書夢
西安電子科技大學(xué)學(xué)報 2021年6期
譚 雯,甘新標(biāo),白 皓,肖調(diào)杰,陳旭光,雷書夢,劉 杰
(1.國防科技大學(xué) 計算機(jī)學(xué)院,湖南 長沙,410073;2.湖南信息學(xué)院 通識教育學(xué)院,湖南 長沙,410217)
圖在生物信息、社交網(wǎng)絡(luò)、交通運(yùn)輸、天體物理等領(lǐng)域得到廣泛應(yīng)用,是大數(shù)據(jù)浪潮中的主要數(shù)據(jù)結(jié)構(gòu)之一。許多現(xiàn)實(shí)問題可以抽象為圖結(jié)構(gòu)。隨著大數(shù)據(jù)應(yīng)用的發(fā)展,其問題的規(guī)模不斷增長,對超級計算機(jī)平臺的圖存儲運(yùn)算能力產(chǎn)生了廣泛需求。這些抽象圖中的頂點(diǎn)數(shù)和相連的邊數(shù)有時可以達(dá)到萬億級的規(guī)模,使得超級計算機(jī)系統(tǒng)被期望擁有更高的大數(shù)據(jù)存儲和運(yùn)算能力[1]。
為了評測超級計算機(jī)系統(tǒng)對大數(shù)據(jù)應(yīng)用的運(yùn)行能力,Graph500測試基準(zhǔn)被提出,成為數(shù)據(jù)密集型計算機(jī)系統(tǒng)的評測工具。這一基準(zhǔn)以圖論來分析超級計算機(jī)在模擬生物、安全、社會以及類似復(fù)雜問題的吞吐量,成為超級計算機(jī)測試領(lǐng)域的一個新的主流測試基準(zhǔn)。
大數(shù)據(jù)問題通常具有數(shù)據(jù)規(guī)模極大、數(shù)據(jù)密集度高、計算復(fù)雜性低、分布不均衡等特征。當(dāng)將現(xiàn)實(shí)世界中的大數(shù)據(jù)問題抽象為圖時,這些特征表現(xiàn)為圖數(shù)據(jù)的小世界性(small-world)[2]和無尺度性(scale-free)[3]。小世界性是指在圖的所有頂點(diǎn)中,任意兩個圖頂點(diǎn)的最短路徑上的頂點(diǎn)數(shù)遠(yuǎn)少于圖中頂點(diǎn)總數(shù);無尺度性是指圖中大部分頂點(diǎn)僅與少量頂點(diǎn)之間直接關(guān)聯(lián),即圖中大部分頂點(diǎn)的度數(shù)較低。同時,存在少數(shù)頂點(diǎn)和數(shù)量龐大的頂點(diǎn)之間直接關(guān)聯(lián)關(guān)系,即圖中存在小部分度數(shù)非常高的頂點(diǎn),這些頂點(diǎn)被稱作高度數(shù)頂點(diǎn)。
為了應(yīng)對現(xiàn)實(shí)世界中的大數(shù)據(jù)問題,高效地處理大規(guī)模圖數(shù)據(jù),基于圖結(jié)構(gòu)的小世界性和無尺度性的特征,筆者提出一種以頂點(diǎn)排序和優(yōu)先緩存策略為基礎(chǔ)的大規(guī)模圖遍歷優(yōu)化方法。這一方法通過優(yōu)化圖結(jié)構(gòu)的空間局部性來減少無效訪存,提高訪存帶寬利用率。筆者的優(yōu)化工作基于Graph500測試程序開展,并在天河超級計算機(jī)系統(tǒng)測試平臺上進(jìn)行測試,以檢測并發(fā)揮天河超級計算機(jī)實(shí)驗(yàn)平臺的圖處理能力。
筆者的主要貢獻(xiàn)如下:
(1)提出了以頂點(diǎn)排序和優(yōu)先緩存策略為基礎(chǔ)的大規(guī)模圖遍歷優(yōu)化方法。這一方法將圖中頂點(diǎn)按度數(shù)從高到低排序。在圖遍歷階段,優(yōu)先訪問度數(shù)高的頂點(diǎn);當(dāng)條件滿足時,及時中斷訪問,提升了擊中概率,減少了進(jìn)程間的無效通信,最大限度地避免了無效訪存。同時將部分關(guān)鍵高度數(shù)頂點(diǎn)緩存至天河系統(tǒng)核組內(nèi)的高速緩存中,使訪問效率得到明顯提升。
(2)將這一大規(guī)模圖遍歷優(yōu)化方法應(yīng)用于Graph500基準(zhǔn)評測程序,在天河超級計算機(jī)系統(tǒng)測試平臺上開展測試,通過全系統(tǒng)可用的904個節(jié)點(diǎn),達(dá)到了2 547.13 GTEPS的穩(wěn)定測試性能,超過Graph500國際榜單上排名第7名所達(dá)到的2 061.48 GTEPS的成績。
1 相關(guān)工作
寬度優(yōu)先遍歷算法(BFS)是一種經(jīng)典的圖遍歷算法。在Graph500測試基準(zhǔn)中,寬度優(yōu)先遍歷算法是用于評測超算性能的核心遍歷算法。這一算法以訪存通信操作為主,能有效地發(fā)掘現(xiàn)實(shí)問題的抽象圖結(jié)構(gòu)中海量數(shù)據(jù)間的關(guān)聯(lián)與延展,更好地模擬大規(guī)模圖結(jié)構(gòu)數(shù)據(jù)的數(shù)據(jù)密集型負(fù)載,對大數(shù)據(jù)應(yīng)用問題的遍歷搜尋更具備針對性。多年來,針對寬度優(yōu)化搜索算法的優(yōu)化,國內(nèi)外的研究機(jī)構(gòu)提出了一系列方案,并取得了長足進(jìn)展。
AGARWAL等[4]提出采用位圖結(jié)構(gòu)來表示寬度優(yōu)先遍歷算法中的訪問情況記錄數(shù)組visit,大幅提升了單字節(jié)可表示的頂點(diǎn)訪問信息數(shù)目,擴(kuò)大了單個緩存行的有效數(shù)據(jù)量。UENO等[5]提出頂點(diǎn)按度數(shù)重新降序排序的優(yōu)化策略,降低了查詢時間,提高了cache命中率。BEAMER等[6]開創(chuàng)性地提出了一種方向優(yōu)化的混合遍歷優(yōu)化算法,以盡可能地減少非必要遍歷,大幅降低了訪存通信開銷。YASUI和FUJISAWA等研究者提出了度數(shù)感知優(yōu)化策略,按度數(shù)拆分了頂點(diǎn)的鄰接列表,對高度數(shù)頂點(diǎn)和非高度數(shù)頂點(diǎn)分開處理,并綜合了前人的優(yōu)化技術(shù),大幅提高了Bottom-up算法的擊中效率,有效地降低了通信次數(shù)[6]。UENO等[7]結(jié)合特定網(wǎng)絡(luò)結(jié)構(gòu)的特點(diǎn),在通信方面開展優(yōu)化,同時引入了數(shù)據(jù)壓縮、混合搜索、頂點(diǎn)重排序等技術(shù),達(dá)到了38 621.4 GTEPS的良好性能。
上述研究主要關(guān)注算法層面的優(yōu)化。而在算法與體系結(jié)構(gòu)的協(xié)同優(yōu)化方面,BADER等[8]基于Cray MTA-2多節(jié)點(diǎn)平臺,利用其提供的細(xì)粒度、低開銷的同步操作支持,實(shí)現(xiàn)了多線程并行的寬度優(yōu)先遍歷優(yōu)化算法,利用多線程來隱藏訪存延遲,取得了較高的性能加速。清華大學(xué)的LIN等[9-10]面向“神威太湖之光”平臺,通過模塊流水映射、無競爭的數(shù)據(jù)混洗,基于組消息的批處理等關(guān)鍵技術(shù)的提出和應(yīng)用,發(fā)揮了神威的硬件優(yōu)勢,在Graph500測試基準(zhǔn)中獲得了23 755.7 GTEPS的性能,并且在前述研究的基礎(chǔ)上,應(yīng)用了超節(jié)點(diǎn)路由、片上排序、度數(shù)敏感型通信等技術(shù),進(jìn)一步提出了通用圖處理框架——“神圖”結(jié)構(gòu)。PENG等[11]和WOMBLE等[12]研究者,在Top500排名第2的Summit平臺上,通過對Graph500標(biāo)準(zhǔn)程序應(yīng)用數(shù)據(jù)壓縮、混合搜索、度數(shù)排序、拓?fù)渲亟M等技術(shù),測試得到的結(jié)果處于世界先進(jìn)水平。UENO等[7]基于日本“京”及其 “富岳”系統(tǒng)開發(fā)的Graph500優(yōu)化程序,主要采用了數(shù)據(jù)壓縮、混合搜索、頂點(diǎn)重排序、負(fù)載均衡以及基于Tofu網(wǎng)絡(luò)結(jié)構(gòu)的通信優(yōu)化等技術(shù),其性能表現(xiàn)多次登臨Graph500基準(zhǔn)榜首。而多位研究者面向天河二號平臺,采用數(shù)據(jù)壓縮、混合搜索、數(shù)據(jù)預(yù)取以及匯編優(yōu)化等技術(shù),以提升Graph500測試性能[13-14]。張承龍等[15]則面向高通量計算機(jī)系統(tǒng),應(yīng)用度數(shù)感知、頂點(diǎn)重排序、靜態(tài)shuffle、基于快查找的位圖訪問等策略,取得了更高的處理能效。日本的研究者們基于富岳超級計算機(jī)系統(tǒng)的處理器結(jié)構(gòu)和高性能網(wǎng)絡(luò),提出了針對性的通信優(yōu)化策略,并對其性能表現(xiàn)進(jìn)行了評估對比[16-18]。甘新標(biāo)等[19-21]面向天河超算實(shí)驗(yàn)系統(tǒng),應(yīng)用圖結(jié)構(gòu)優(yōu)化策略,在Matrix2000 CPU上使用SVE進(jìn)行矢量化搜索,在專有互連網(wǎng)絡(luò)上進(jìn)行群組通信,以有效地發(fā)揮天河系統(tǒng)的圖處理性能。
上述優(yōu)化技術(shù)與相應(yīng)研究,對超算平臺上圖遍歷程序的優(yōu)化研究具有重要的指導(dǎo)和借鑒意義。
2 Graph500
Graph500是評測超級計算機(jī)圖處理能力的重要國際基準(zhǔn),它以每秒遍歷的邊數(shù)(Traversed Edges Per Second,TEPS)為性能指標(biāo),衡量超級計算機(jī)處理數(shù)據(jù)密集型應(yīng)用的能力[22]。
2.1 基本流程
Graph500的基本流程如圖1如示。
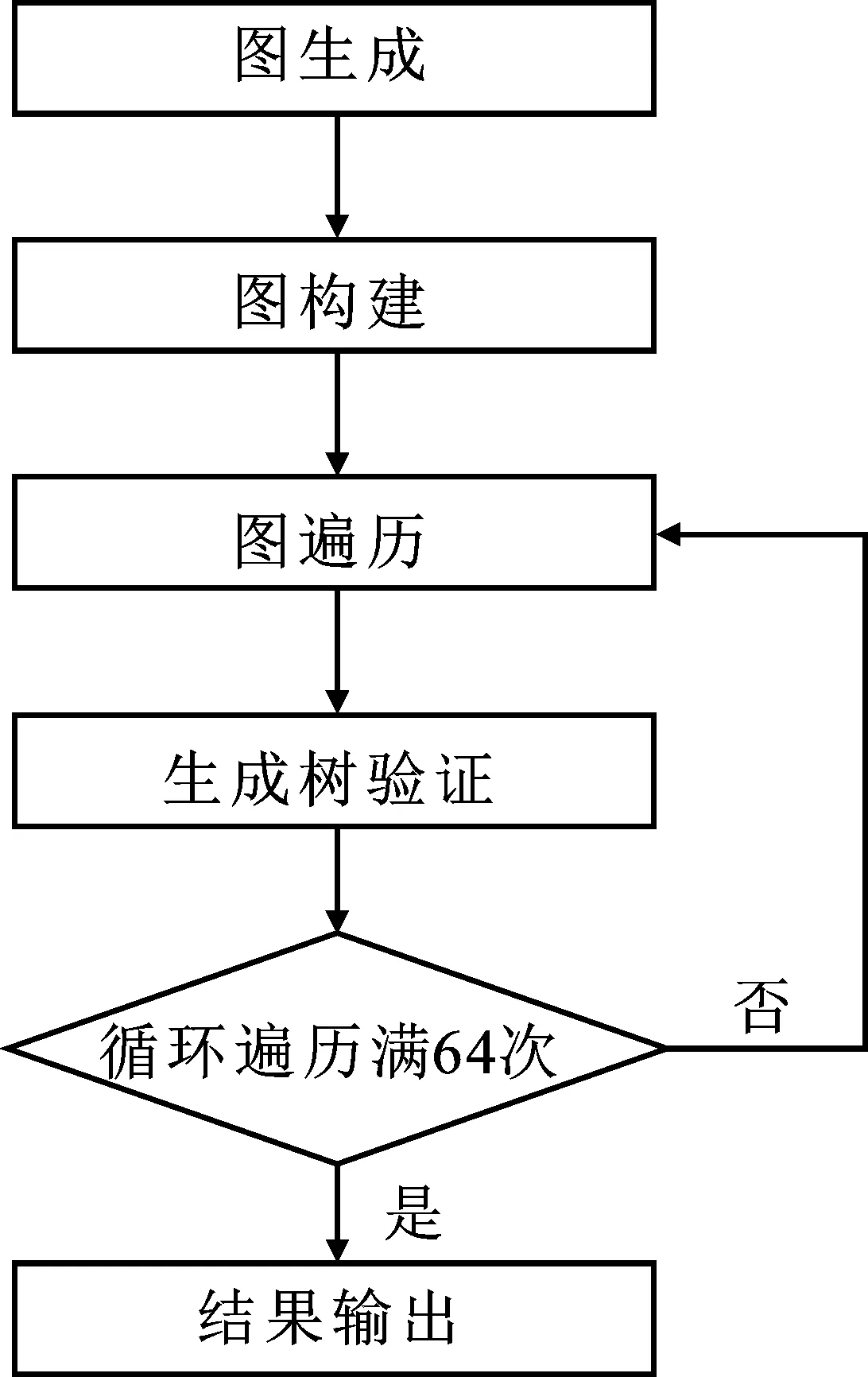
圖1 Graph500流程圖
圖生成階段,Graph500基準(zhǔn)測試程序采用Kronecker生成器生成圖數(shù)據(jù)。為了模擬現(xiàn)實(shí)問題的圖結(jié)構(gòu),通過大量的統(tǒng)計分析驗(yàn)證,Graph500內(nèi)置的Kronecker圖生成器抽象了現(xiàn)實(shí)圖的小世界性和無尺度性特征,其生成圖的頂點(diǎn)分布呈現(xiàn)“長尾”現(xiàn)象。此階段生成的圖信息將以邊元組列表形式存儲,通常以鄰接矩陣表示。Kronecker生成器有兩個輸入?yún)?shù),分別是圖規(guī)模因子Fscale和邊因子Fedgefactor。Fscale表示生成圖的規(guī)模為2Fscale,F(xiàn)edgefactor表示每個圖頂點(diǎn)的平均度數(shù)。默認(rèn)情況下,Graph500的邊因子Fedgefactor=16。假定Fscale=n,F(xiàn)edgefactor=m,則生成圖具有2n個頂點(diǎn)和m×2n條無向邊[22]。
圖構(gòu)建階段,生成圖將進(jìn)行重新構(gòu)建,將邊元組列表轉(zhuǎn)化為特定的圖結(jié)構(gòu)表示。
圖遍歷階段,Graph500提供了寬度優(yōu)先遍歷算法(Breadth First Search,BFS)和單元最短路徑算法(Single Source Shortest Path,SSSP)兩種遍歷算法。其中,寬度優(yōu)先遍歷算法是一種更為經(jīng)典的圖遍歷算法,能夠有效地發(fā)掘現(xiàn)實(shí)問題的抽象圖結(jié)構(gòu)中海量數(shù)據(jù)間的關(guān)聯(lián)與延展,更好地模擬大規(guī)模圖結(jié)構(gòu)數(shù)據(jù)的數(shù)據(jù)密集型負(fù)載,是筆者的主要研究目標(biāo)。
圖驗(yàn)證階段,程序?qū)匆欢ǖ囊?guī)則,對圖遍歷階段得到的生成樹進(jìn)行驗(yàn)證。如果驗(yàn)證有誤,則中止程序。
Graph500中包含多個計時模塊,僅將其中圖遍歷階段的計時結(jié)果納入最終性能指標(biāo)Pteps的計算。假定Graph500在圖遍歷階段的有效計時時間為t,F(xiàn)scale=n,F(xiàn)edgefactor=m,則Graph500評測性能為
Pteps=m×2n/t。
(1)
Pteps的單位為遍歷的邊數(shù)每秒(TEPS),由圖規(guī)模和搜索時間共同決定。圖規(guī)模是Pteps的關(guān)鍵影響因素,但其主要取決于系統(tǒng)內(nèi)存規(guī)模和圖結(jié)構(gòu)存儲表示方法。筆者的優(yōu)化研究重點(diǎn)關(guān)注影響Pteps的另一個關(guān)鍵因素,即寬度優(yōu)先遍歷算法的遍歷時間。
2.2 生成圖的冪律分布
圖2為Fscale=30時的生成圖的頂點(diǎn)度數(shù)分布圖,得到圖結(jié)構(gòu)中的頂點(diǎn)度數(shù)近似符合冪律分布。
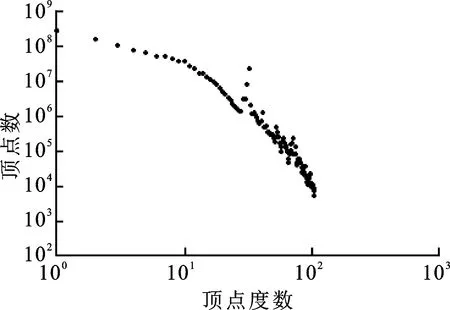
圖2 頂點(diǎn)度數(shù)冪律分布圖(Fscale=30)
圖G=(V,E)包含頂點(diǎn)集合V和邊集合E,通常使用vi表示圖中編號為i的頂點(diǎn),使用頂點(diǎn)對(vi,vj)表示頂點(diǎn)i到頂點(diǎn)j的邊。(vi,vj)∈E,0≤i≤Nv-1,0≤j≤Nv-1,Nv為V中頂點(diǎn)個數(shù)。G通常用鄰接矩陣A表示,如圖3所示。圖G的現(xiàn)實(shí)連接表示如圖3(a)所示,圖G的鄰接矩陣表示如圖3(b)所示。A中第i行第j列的元素Aij表示邊(vi,vj)。Aij=1,表示vi與vj間存在相鄰邊;Aij=0,表示vi與vj間不存在相鄰邊。
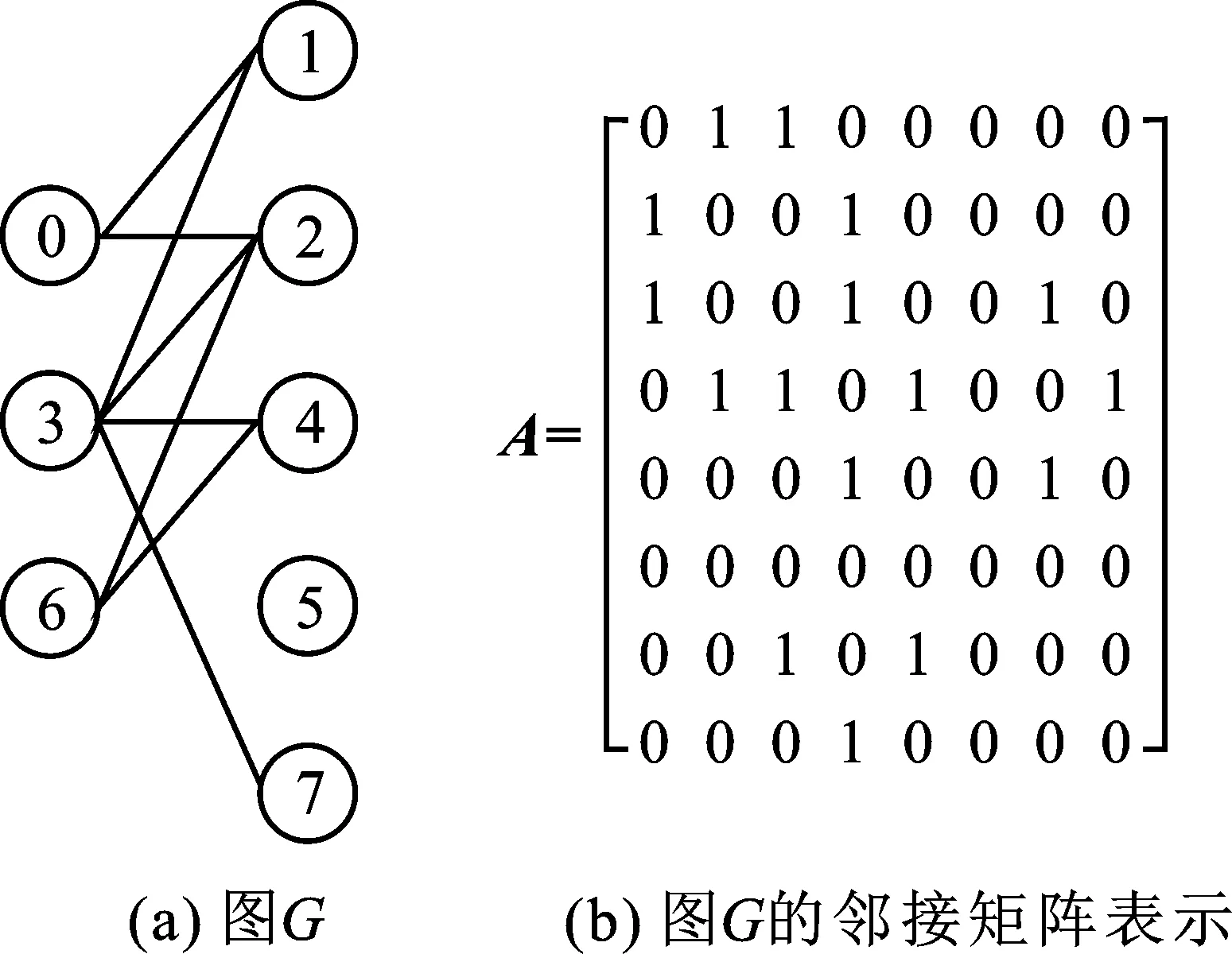
圖3 圖的鄰接矩陣表示
2.3 并行寬度優(yōu)先遍歷模塊
基本的順序?qū)挾葍?yōu)先遍歷算法描述如下:
(1)使用先進(jìn)先出的隊列Q管理頂點(diǎn)。vc表示當(dāng)前頂點(diǎn),vu表示待訪問的vc的關(guān)聯(lián)頂點(diǎn),visited標(biāo)識每個頂點(diǎn)的訪問信息。visited[vu]=0,表示vu未被訪問;visited[vu]=1,則表示vu已被其他頂點(diǎn)訪問。
(2)使用一個隊列表示頂點(diǎn)集合。每次迭代之初,從隊首取出vc,并將本輪新訪問的鄰接頂點(diǎn)vu加入隊尾,而后進(jìn)行下一輪迭代。
(3)由于(2)中的迭代算法不利于并行化,因此考慮使用兩個隊列Q1,Q2。Q1用來保存當(dāng)前迭代中用來拓展寬度優(yōu)先遍歷算法生成樹的頂點(diǎn),即上一輪迭代中訪問到的頂點(diǎn)。Q2用來存儲本輪迭代中訪問并刷新狀態(tài)的Q1中頂點(diǎn)的鄰接頂點(diǎn)。等到Q1中頂點(diǎn)的所有鄰接頂點(diǎn)全部訪問完畢后,再將Q1與Q2進(jìn)行交換,開展下一輪迭代搜索。如上,每輪的迭代相對獨(dú)立,便于對同一層的頂點(diǎn)的寬度優(yōu)先遍歷進(jìn)行并行化處理。
在Graph500基準(zhǔn)測試程序的圖遍歷階段,采用的并行化的寬度優(yōu)先遍歷算法描述如下:
(1)采用變量Fcur表示當(dāng)前待搜索的頂點(diǎn)集合,F(xiàn)next表示下一層頂點(diǎn)搜索的頂點(diǎn)集合(即Fcur中頂點(diǎn)的所有鄰接頂點(diǎn))。
(2)開展檢索之初,將根頂點(diǎn)vroot加入Fcur。
(3)從Fcur中的所有頂點(diǎn)開展遍歷,取當(dāng)前頂點(diǎn)vc的關(guān)聯(lián)頂點(diǎn)vu進(jìn)行判定。若該關(guān)聯(lián)頂點(diǎn)此前未被訪問,則更新其訪問信息,并將該頂點(diǎn)加入Fnext集合。
(4)每輪迭代結(jié)束時,將Fnext賦給Fcur并將Fnext清空,再循環(huán)執(zhí)行迭代,直至待搜索頂點(diǎn)集合Fcur為空。
代碼1并行寬度優(yōu)先遍歷算法的偽代碼。
輸入:G(V,E),vroot
輸出:
①Fcur←?
②Fnext←?
③ for allvc∈V parallel do
④ visited[vc]=0
⑤ end for
⑥ visited[vroot]=1
⑦Fcur←vroot
⑧ whileFcur≠? do
⑨ for eachvc∈Fcurparallel do
⑩ outputvc
在這一樸素的并行寬度優(yōu)先遍歷算法中,遍歷仍處于盲目的完全搜索模式,如代碼1的第11行for eachvu∈G.Adj[vc]parallel do中,程序需要逐一訪問G中的頂點(diǎn)vu,來判定vu與頂點(diǎn)vc是否存在邊關(guān)聯(lián),以確定頂點(diǎn)vc的關(guān)聯(lián)頂點(diǎn)集合。即使某個頂點(diǎn)在一定條件下不存在未訪問邊,上述樸素算法仍需要通過例行訪存來進(jìn)行判定。考慮生成圖的冪律分布特點(diǎn),會存在相當(dāng)多的無效訪存。
3 以頂點(diǎn)排序和優(yōu)先緩存策略為基礎(chǔ)的大規(guī)模圖遍歷優(yōu)化方法
從現(xiàn)實(shí)世界的大數(shù)據(jù)問題中抽象得到的圖結(jié)構(gòu)通常具有小世界性和無尺度性,并呈現(xiàn)出長尾效應(yīng)。這種長尾效應(yīng)的原因在于,現(xiàn)實(shí)世界得到的圖數(shù)據(jù)中,頂點(diǎn)間度數(shù)差別很大,高度數(shù)頂點(diǎn)的計算、通信、存儲的需求大,而低度數(shù)頂點(diǎn)的計算、通信、存儲的需求小。基于長尾效應(yīng)的存在,為了高效地處理大規(guī)模圖數(shù)據(jù),筆者充分利用度數(shù)高的關(guān)鍵頂點(diǎn)與其他頂點(diǎn)關(guān)聯(lián)概率高的特性,對圖中所有頂點(diǎn)按照度數(shù)高低從大到小進(jìn)行排序,并對度數(shù)高于設(shè)定閾值的關(guān)鍵頂點(diǎn)進(jìn)行優(yōu)先緩存,最大可能地減少不必要的訪存和對外通信,優(yōu)化訪存效率。
3.1 頂點(diǎn)排序算法
排序算法是高性能計算機(jī)體系結(jié)構(gòu)的經(jīng)典算法,應(yīng)用廣泛。常用的排序算法有冒泡排序、快速排序和歸并排序等。為了能夠更好地發(fā)揮國產(chǎn)飛騰眾核處理器的計算性能,經(jīng)前期理論分析和實(shí)驗(yàn)比較分析,歸并排序既能充分發(fā)揮國產(chǎn)飛騰眾核處理器的性能,又能大幅提升Graph500在天河超級計算機(jī)系統(tǒng)上的測試性能,適宜應(yīng)用于本文中的優(yōu)化程序。
歸并排序是采用分治的策略先將待排序序列分成若干小的子序列,將各個子序列排序后,利用歸并操作將各子序列逐步歸并成有序序列。對于長度為N的序列,歸并算法的時間復(fù)雜度為O(NlogN),空間復(fù)雜度為O(N)。歸并排序由于思想簡單,速度較快,易于并行,常應(yīng)用于眾核加速[23]。
為了滿足大規(guī)模科學(xué)工程計算與大數(shù)據(jù)處理等應(yīng)用領(lǐng)域?qū)Ω咝阅苡嬎闫脚_的需求,天河超級計算機(jī)系統(tǒng)設(shè)計了國產(chǎn)通用眾核處理器,如圖4所示。該眾核處理器支持可變寬度的向量指令擴(kuò)展。
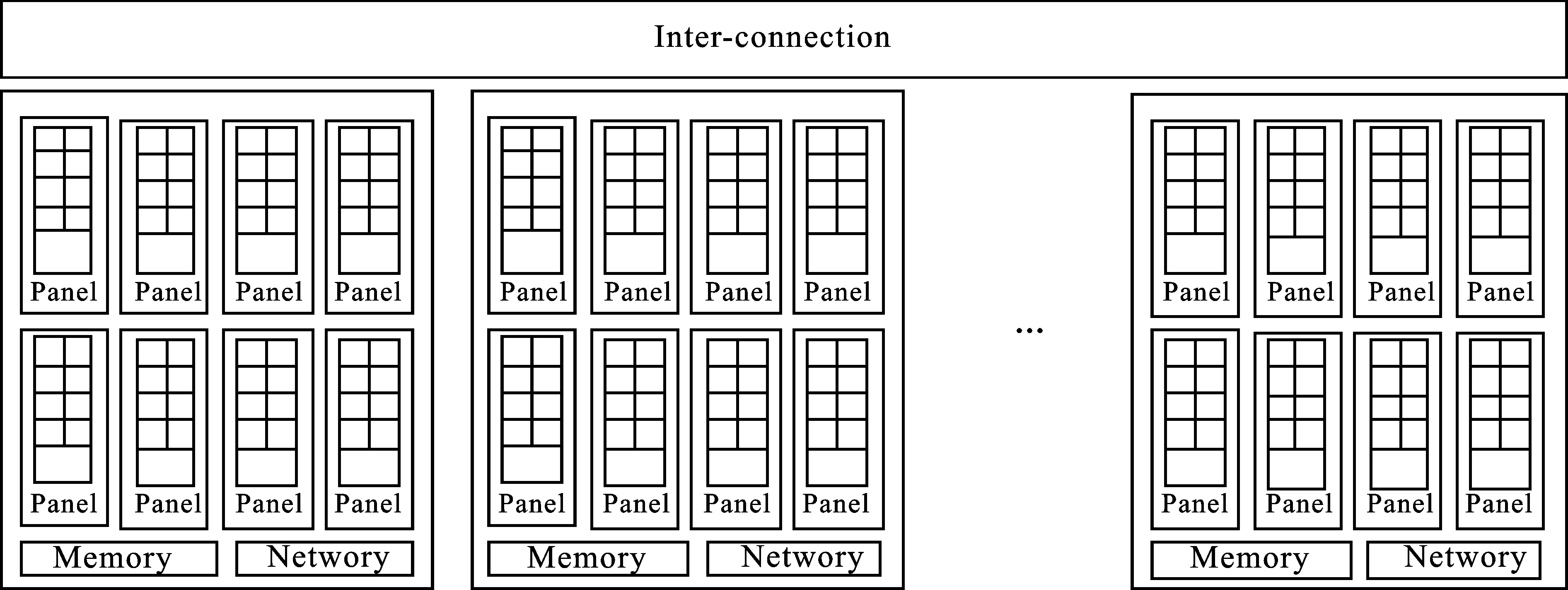
圖4 國產(chǎn)通用眾核處理器體系結(jié)構(gòu)
通用眾核處理器全芯片由多個區(qū)域互連組成,每一個區(qū)域具有私有的處理器核心、高速緩存、外部存儲接口和高速通信接口,可以看成是一個功能獨(dú)立的處理器。多個區(qū)域通過互連,構(gòu)成一顆處理器芯片。區(qū)域內(nèi)部由多個核組通過區(qū)域內(nèi)的互連接口組成,每個核組內(nèi)包括多個處理器核心和共享的高速緩存,每個處理器核心為一組向量處理單元(Vector Processing Element,VPE)。通用眾核集成外部存儲接口和高速通信接口,為處理器核心的高性能計算處理提供相匹配的訪存和通信能力。此外,片上還集成有PCI Express等標(biāo)準(zhǔn)IO接口,可直接連接標(biāo)準(zhǔn)外部設(shè)備,降低系統(tǒng)設(shè)計的復(fù)雜度。
為了將歸并排序算法高效映射到國產(chǎn)通用眾核處理器,筆者采用深度平衡歸并策略[23]將每次歸并排序優(yōu)化映射分布到大量向量處理單元以完成向量并行加速。向量并行加速在第k級(最底層為第0級)將待排序的頂點(diǎn)劃分為2個子序列,每個子序列劃分成2k組,分別布置給2k個向量處理單元完成操作,最后各向量處理單元獨(dú)立完成各自數(shù)據(jù)的歸并。
3.2 頂點(diǎn)排序優(yōu)化策略
基于頂點(diǎn)歸并排序的VS-Graph500的測試流程包括如下步驟:圖生成、圖構(gòu)建、基于頂點(diǎn)度數(shù)的預(yù)處理、基于頂點(diǎn)歸并排序的并行寬度優(yōu)先遍歷、生成樹驗(yàn)證、結(jié)果輸出等。其中,與基于頂點(diǎn)排序的并行圖遍歷優(yōu)化相關(guān)的流程步驟主要有:基于頂點(diǎn)度數(shù)的預(yù)處理、基于頂點(diǎn)重排序的并行寬度優(yōu)先遍歷優(yōu)化。
基于頂點(diǎn)度數(shù)的預(yù)處理主要包括以下兩個關(guān)鍵步驟:
步驟1 遍歷圖G=(V,E)中每個頂點(diǎn),并記錄每個頂點(diǎn)的度數(shù),得到頂點(diǎn)度數(shù)集合D,D中第i個元素deg(vi)表示頂點(diǎn)vi的度數(shù),即有deg(vi)個頂點(diǎn)與頂點(diǎn)vi之間存在相連邊。
步驟2 采用歸并排序算法,對D中的元素進(jìn)行降序排序,得到排序后的頂點(diǎn)度數(shù)二元組集合D2如下:
D2=(〈v0,deg(v0)〉,〈v1,deg(v1)〉,…,〈vi,deg(vi)〉,…) ,
其中,D2中第i個元素〈vi,deg(vi)〉表示頂點(diǎn)vi的度數(shù)為deg(vi)且滿足deg(v0)>deg(v1)>deg(vi)。將V中的頂點(diǎn)根據(jù)D2進(jìn)行降序排序,得到排序后的頂點(diǎn)集合為(v0,v1,…,vi,…),其中第1個元素v0對應(yīng)頂點(diǎn)度數(shù)最大的頂點(diǎn),第2個元素v1對應(yīng)頂點(diǎn)度數(shù)僅小于或等于度數(shù)最大的頂點(diǎn),度數(shù)相同的頂點(diǎn)并列重復(fù)列出。
基于頂點(diǎn)歸并排序的寬度優(yōu)先遍歷算法的主要流程結(jié)構(gòu)如圖5所示。
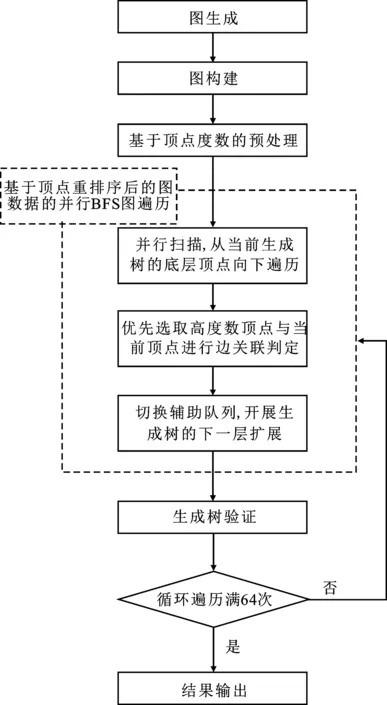
圖5 基于頂點(diǎn)歸并排序的BFS圖遍歷流程圖
基于代碼1的并行BFS偽代碼,該策略在第9行的for eachvc∈Fcurparallel do后引入頂點(diǎn)度數(shù) deg(vc),先從高度數(shù)頂點(diǎn)vc開展遍歷。考慮高度數(shù)頂點(diǎn)存在邊關(guān)聯(lián)概率高的特性,在代碼1中第11行for eachvu∈G.Adj[vc]parallel do中,優(yōu)先高度數(shù)頂點(diǎn)vu,判斷其是否與vc相關(guān)聯(lián),是否可以加入生成樹。
這一策略基于高度數(shù)頂點(diǎn)存在邊關(guān)聯(lián)概率高的特點(diǎn)。首先,引入了頂點(diǎn)度數(shù)deg(vc)。在遍歷時,當(dāng)累積存在deg(vc)個頂點(diǎn)vu與當(dāng)前頂點(diǎn)vc存在邊關(guān)聯(lián),可確定vc的關(guān)聯(lián)頂點(diǎn)已全部遍歷,會提前終止后續(xù)訪存操作。其次,由于頂點(diǎn)vu度數(shù)高,與vc之間存在邊關(guān)聯(lián)的可能性也高,因此,該訪存關(guān)聯(lián)判定成功的概率較高,在提前終止后續(xù)訪存操作前,較大限度地避免了盲目搜索情形的出現(xiàn)。最后,在自下向上寬度優(yōu)先遍歷算法階段,鑒于高度數(shù)頂點(diǎn)的關(guān)聯(lián)概率高、擊中概率大的特點(diǎn),更能高效查找并確定頂點(diǎn)vc的父頂點(diǎn),繼而終止頂點(diǎn)關(guān)聯(lián)訪存判斷,以減少無效訪存。
基于頂點(diǎn)排序的并行寬度優(yōu)先遍歷算法的具體實(shí)現(xiàn)偽代碼見代碼2,其算法描述如下:
(1)采用變量Fcur表示當(dāng)前待搜索的頂點(diǎn)集合,F(xiàn)next表示下一層頂點(diǎn)搜索的頂點(diǎn)集合(即Fcur中頂點(diǎn)的所有鄰接頂點(diǎn))。
(2)開展檢索之初,將根頂點(diǎn)vroot加入Fcur。
(3)引入當(dāng)前頂點(diǎn)vc的度數(shù)deg(vc)。在遍歷階段,基于已經(jīng)排序完成的頂點(diǎn)列表,按度數(shù)由高到低,取頂點(diǎn)vc的關(guān)聯(lián)頂點(diǎn)vu進(jìn)行訪問。若頂點(diǎn)vu此前未被訪問過,則更新其訪問信息,并將該鄰接頂點(diǎn)加入Fnext集合。
(4)如果當(dāng)前頂點(diǎn)vc的已訪問關(guān)聯(lián)頂點(diǎn)vu的數(shù)目大于等于deg(vc),則退出此次對vc關(guān)聯(lián)頂點(diǎn)vu的循環(huán)遍歷,在Fcur中取下一個頂點(diǎn)vc開展訪問。
(5)每輪迭代結(jié)束時,將Fnext賦給Fcur并將Fnext清空,再循環(huán)執(zhí)行迭代,直至待搜索頂點(diǎn)集合Fcur為空。
代碼2基于頂點(diǎn)排序的并行寬度優(yōu)先遍歷算法的偽代碼。
輸入:G(V,E),vroot。
輸出:
①Fcur←?
②Fnext←?
③ for allvc∈V parallel do
④ visited[vc]=0
⑤ end for
⑥ visited[vroot]=1
⑦Fcur←vroot
⑧ whileFcur≠? do
⑨ for eachvc∈Fcurparallel do
⑩ get deg(vc)
3.3 關(guān)鍵頂點(diǎn)優(yōu)先緩存策略
關(guān)鍵頂點(diǎn),即在圖結(jié)構(gòu)中與大部分頂點(diǎn)存在邊關(guān)聯(lián)的高度數(shù)頂點(diǎn)。優(yōu)先緩存關(guān)鍵頂點(diǎn),就是將部分高度數(shù)頂點(diǎn)緩存在天河系統(tǒng)區(qū)域內(nèi)部的核組中的高速緩存中,對緩存的關(guān)鍵頂點(diǎn)進(jìn)行優(yōu)先訪問。
對關(guān)鍵頂點(diǎn)進(jìn)行優(yōu)先緩存,既可以簡化關(guān)聯(lián)頂點(diǎn)之間的通信路徑,減少頂點(diǎn)間的跨節(jié)點(diǎn)通信,又可同時提高頂點(diǎn)的訪問命中率。但是,待緩存的關(guān)鍵頂點(diǎn)集合應(yīng)結(jié)合機(jī)器特征和工程經(jīng)驗(yàn)確定,需要考慮以下因素:
(1)高度數(shù)頂點(diǎn)應(yīng)盡可能優(yōu)先緩存;
(2)應(yīng)結(jié)合節(jié)點(diǎn)內(nèi)存效率考慮,在盡可能多地緩存高度頂點(diǎn)時,盡可能減小節(jié)點(diǎn)內(nèi)存耗用量。
通過頂點(diǎn)排序統(tǒng)計分析,Kronecker圖生成器生成的頂點(diǎn)度數(shù)分布中,度數(shù)大于1 000的頂點(diǎn)占比小于0.5%,度數(shù)大于100且小于1 000的頂點(diǎn)占比約5%,度數(shù)大于10且小于100的頂點(diǎn)占比大于20%。由于度數(shù)大于100的范圍區(qū)間屬于高度數(shù)頂點(diǎn)集中區(qū)域,占比合適,便于采用分布式共享存儲模式緩存,因此,在VS-Graph500中,選擇對度數(shù)大于100的頂點(diǎn)進(jìn)行優(yōu)先緩存。這樣,一來能夠緩存較高比例的高度數(shù)頂點(diǎn),便于開展算法層面上的優(yōu)化;二來每個節(jié)點(diǎn)分?jǐn)偟膬?nèi)存大小也在可接受限度內(nèi),不會明顯降低節(jié)點(diǎn)的內(nèi)存效率。
4 實(shí)驗(yàn)與討論
為了驗(yàn)證天河超級計算機(jī)系統(tǒng)的數(shù)據(jù)密集型應(yīng)用處理能力,筆者提出了以頂點(diǎn)排序和優(yōu)先緩存策略為基礎(chǔ)的大規(guī)模圖遍歷優(yōu)化方法,并將該方法應(yīng)用于天河超級計算機(jī)系統(tǒng)的Graph500測試中,形成了面向天河超級計算機(jī)系統(tǒng)Graph500測試版本VS-Graph500。
4.1 實(shí)驗(yàn)配置
與Graph500測試密切相關(guān)的系統(tǒng)參數(shù)如表1所示。
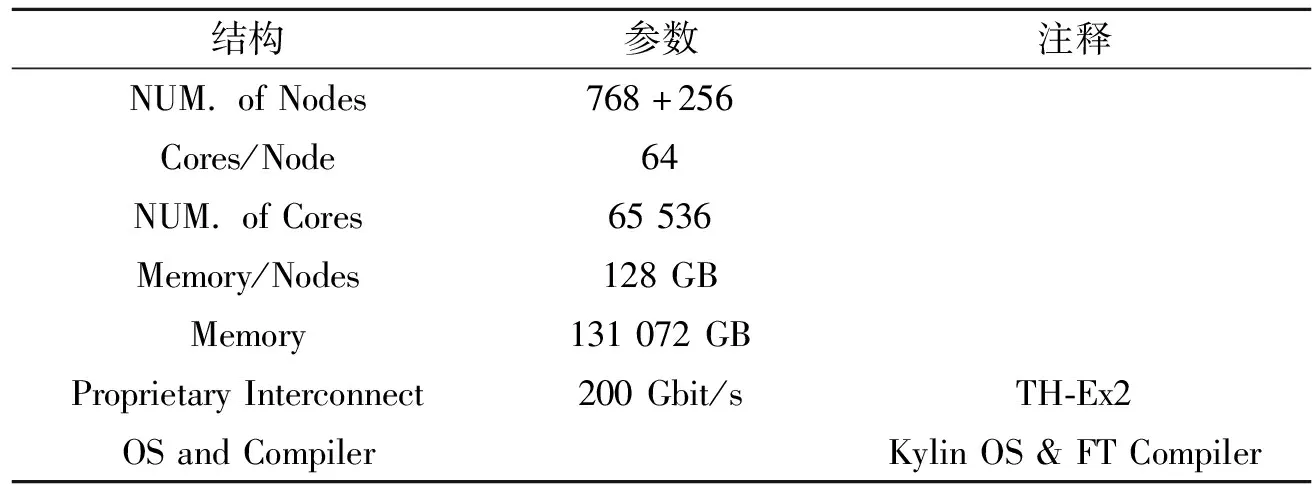
表1 面向Graph500的系統(tǒng)配置
實(shí)驗(yàn)平臺的功能結(jié)構(gòu)組成如圖6所示。該天河超級計算機(jī)系統(tǒng)實(shí)驗(yàn)平臺按系統(tǒng)功能分為智能計算、存儲、互連、服務(wù)、監(jiān)控管理幾大模塊,總共包含8個機(jī)柜。每個柜包含2個互連交換插框,3個計算插框,1個存儲插框。全系統(tǒng)包含768個計算節(jié)點(diǎn)(每個計算節(jié)點(diǎn)包含一顆眾核處理器),256個存儲節(jié)點(diǎn),1組高速互連網(wǎng)絡(luò),1組監(jiān)控管理網(wǎng)絡(luò),1組基礎(chǔ)架構(gòu)。
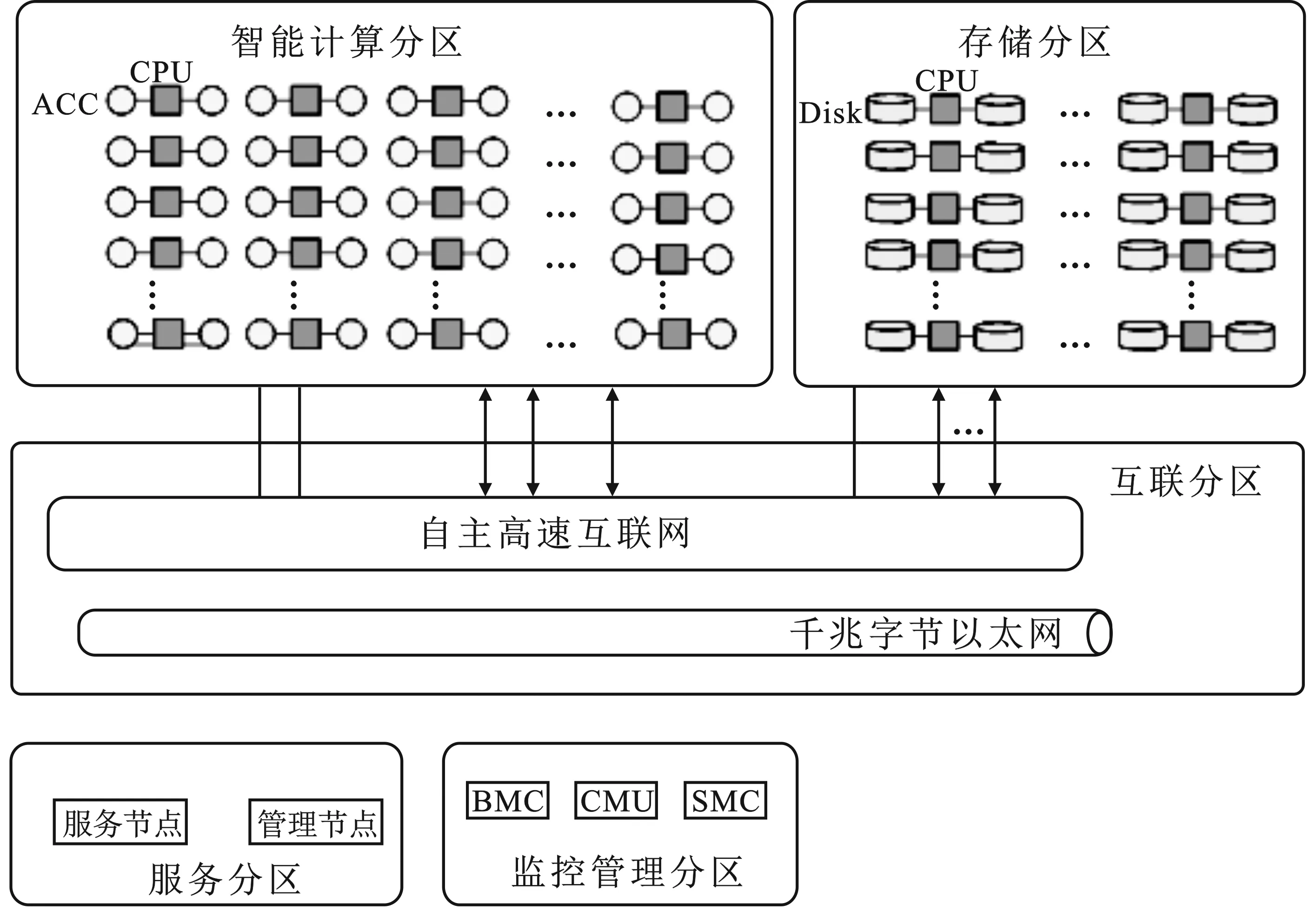
圖6 VS-Graph500測試系統(tǒng)體系結(jié)構(gòu)
該天河超級計算機(jī)系統(tǒng)實(shí)驗(yàn)平臺的總節(jié)點(diǎn)數(shù)為1 024個,單節(jié)點(diǎn)核數(shù)為64,總核數(shù)為65 536個,單節(jié)點(diǎn)內(nèi)存為128 GB,平臺總內(nèi)存為131 072 GB,帶寬為200 Gbit/s,搭載麒麟系統(tǒng)及飛騰處理器。
為了驗(yàn)證以頂點(diǎn)排序和優(yōu)先緩存策略為基礎(chǔ)的大規(guī)模圖遍歷優(yōu)化方法的有效性,對以頂點(diǎn)排序和優(yōu)先緩存策略為基礎(chǔ)的大規(guī)模圖遍歷方法優(yōu)化后的VS-Graph500進(jìn)行了詳細(xì)測試,并選用Graph500官方基準(zhǔn)測試程序、面向天河二號的Graph500程序TH-2A、面向“K”系統(tǒng)的Graph500測試程序,與VS-Graph500展開了對比分析。
4.2 基于頂點(diǎn)歸并排序的大規(guī)模圖遍歷性能分析
排序算法是高性能計算機(jī)體系結(jié)構(gòu)的經(jīng)典算法,應(yīng)用廣泛。常用的排序算法有冒泡排序、快速排序和歸并排序等。冒泡排序簡單易實(shí)現(xiàn),但時空復(fù)雜度較高;快速排序雖然空間復(fù)雜度較低,但時間復(fù)雜度較高;歸并排序時空復(fù)雜度均較低,并且歸并排序易于并行、易于向量化,能夠很好地發(fā)揮國產(chǎn)飛騰眾核處理器的計算性能。
面向天河超級計算機(jī)系統(tǒng)的Graph500測試版本VS-Graph500在天河二號平臺上開展優(yōu)化。為了準(zhǔn)確地評估基于頂點(diǎn)歸并排序方法對VS-Graph500的性能,程序中配置了各種獨(dú)立的頂點(diǎn)排序優(yōu)化模塊,主要包括頂點(diǎn)度數(shù)排序、向量化排序優(yōu)化以及孤立頂點(diǎn)剪枝優(yōu)化等。詳細(xì)評測性能如圖7所示。
由圖7可知,在加入頂點(diǎn)排序優(yōu)化模塊后的VS-Graph500程序中,圖遍歷性能提升顯著,相比無排序時的Graph500基準(zhǔn)測試程序的數(shù)據(jù),其圖遍歷性能提升2倍以上。
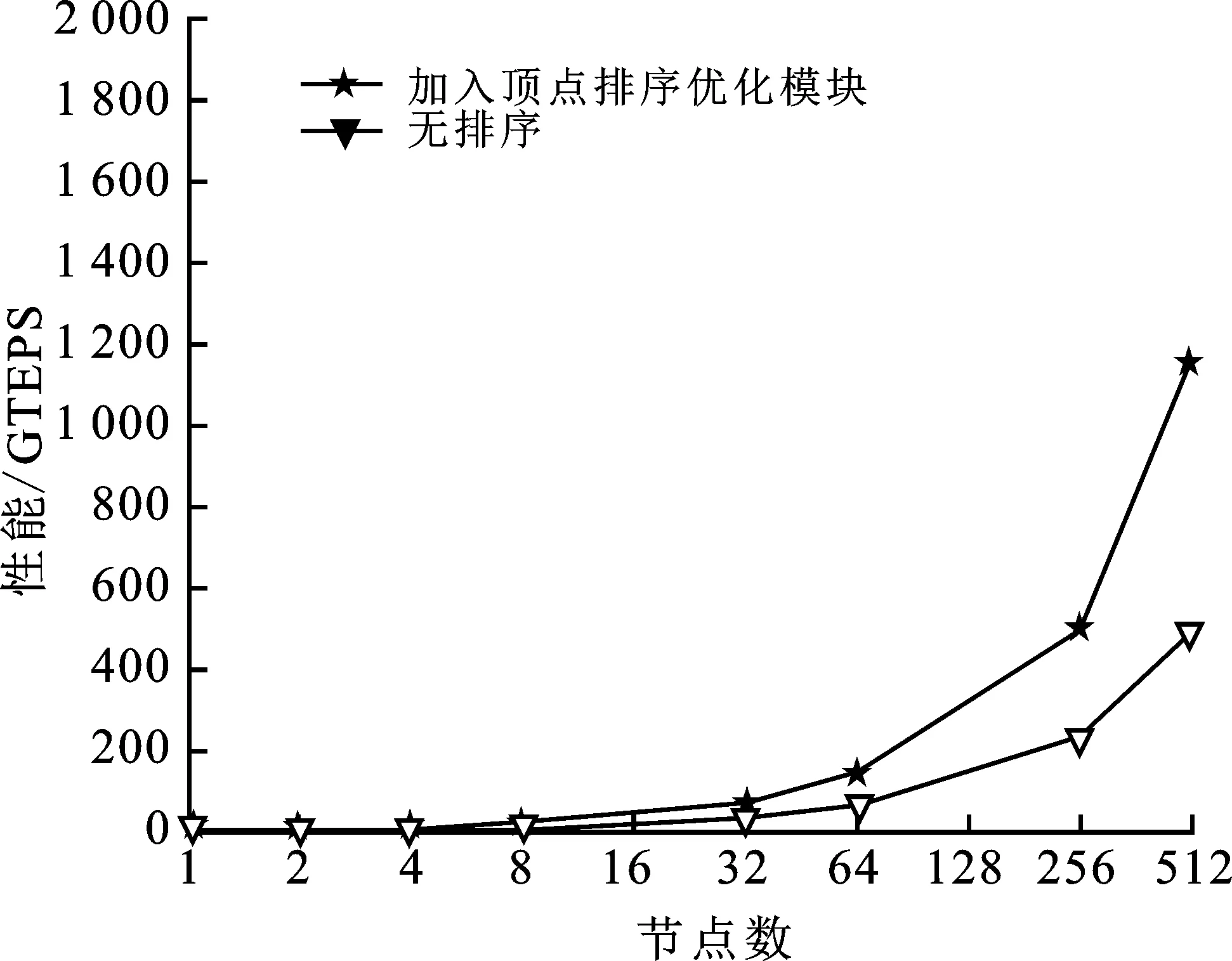
圖7 頂點(diǎn)排序優(yōu)化性能評測圖
VS-Graph500程序中的頂點(diǎn)排序優(yōu)化模塊主要配置了歸并排序(Merge Sorting)、快速排序(Quik Sorting)、冒泡排序(Bubble Sorting)以及無排序(without Sorting)等優(yōu)化選項(xiàng),應(yīng)用各類排序算法后的VS-Graph500在天河超級計算機(jī)實(shí)驗(yàn)平臺上的性能表現(xiàn)如圖8所示。
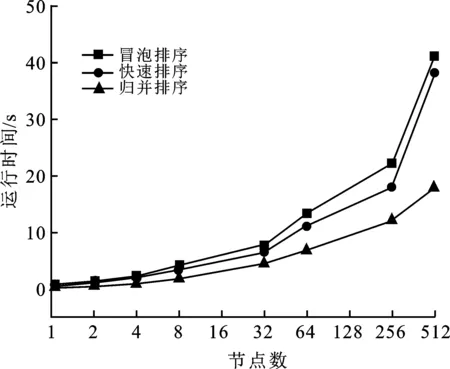
圖8 采用不同排序方法的頂點(diǎn)重排序階段的耗時評估圖
鑒于節(jié)點(diǎn)規(guī)模跨度大,小規(guī)模節(jié)點(diǎn)下可以支持的最高Fscale不能在大規(guī)模節(jié)點(diǎn)上有效展現(xiàn)各類排序方法帶來的耗時差異,該參數(shù)不適宜確定為常量。因此,在不同節(jié)點(diǎn)規(guī)模下,本實(shí)驗(yàn)?zāi)J(rèn)采用當(dāng)前平臺的最大可支持Fscale為參數(shù),生成圖并投入VS-Graph500程序中開展測試。因此,在圖8中,隨著節(jié)點(diǎn)規(guī)模的擴(kuò)大,生成圖Fscale增長,節(jié)點(diǎn)間的通信開銷顯著上升,使得頂點(diǎn)重排序階段的耗時明顯增加。
如圖8所示,由于歸并排序的時空復(fù)雜度均較低,易于并行化、向量化,能夠更好地發(fā)揮國產(chǎn)飛騰眾核處理器的性能,采用歸并排序選項(xiàng)的VS-Graph500在頂點(diǎn)重排序階段的時間開銷明顯優(yōu)于采用快速排序和冒泡排序的版本,而配置快速排序的VS-Graph500略優(yōu)于冒泡排序版本。
隨著運(yùn)行規(guī)模的增大,歸并優(yōu)化表現(xiàn)的性能優(yōu)勢越來越明顯,同時其性能加速效果穩(wěn)定,表現(xiàn)出良好的可擴(kuò)展性。但是,當(dāng)VS-Graph500在小規(guī)模節(jié)點(diǎn)上運(yùn)行時,并未像在大規(guī)模節(jié)點(diǎn)上運(yùn)行時一樣表現(xiàn)出良好的性能優(yōu)勢。主要原因在于,當(dāng)Fscale較小時,圖數(shù)據(jù)的小世界性和無尺度性特征以及頂點(diǎn)度數(shù)分布的“長尾”現(xiàn)象表現(xiàn)得并不明顯,且采用歸并排序進(jìn)行優(yōu)化時的邏輯分支開銷大。
詳細(xì)的性能收益代價評估測試如圖9所示。
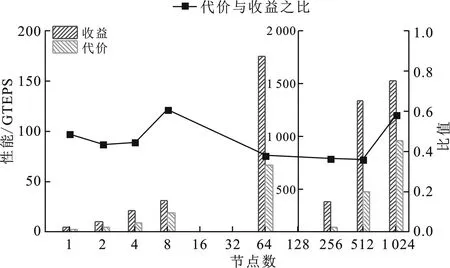
圖9 歸并優(yōu)化的代價收益評估圖
在圖9中,收益對應(yīng)于引入歸并排序優(yōu)化后的VS-Graph500程序的圖遍歷性能,代價對應(yīng)于未引入歸并排序優(yōu)化的標(biāo)準(zhǔn)Graph500程序的圖遍歷性能。實(shí)驗(yàn)數(shù)據(jù)以128個節(jié)點(diǎn)為界分為兩組,當(dāng)節(jié)點(diǎn)數(shù)<128時,縱軸的取值范圍為0~200;當(dāng)節(jié)點(diǎn)數(shù)≥128時,縱軸的取值范圍為0~2 000;以便清晰呈現(xiàn)不同節(jié)點(diǎn)規(guī)模上的收益代價數(shù)據(jù)。
由圖9可知,隨著VS-Graph500運(yùn)行規(guī)模的增大,在8節(jié)點(diǎn)時,歸并優(yōu)化代價收益比最大。這是因?yàn)閳D輸入規(guī)模較小,圖數(shù)據(jù)的小世界性和無尺度性特征以及頂點(diǎn)度數(shù)分布的“長尾”現(xiàn)象表現(xiàn)不明顯。而隨著測試規(guī)模的進(jìn)一步增大,歸并優(yōu)化的代價收益比逐步減小并趨于穩(wěn)定。在全系統(tǒng)測試時,歸并優(yōu)化的代價收益比突然增大,這是因?yàn)殡S著測試規(guī)模的增大,大規(guī)模圖數(shù)據(jù)的特征越來越趨于真實(shí)數(shù)據(jù)集,“長尾”現(xiàn)象表現(xiàn)也越來越明顯。當(dāng)“長尾”現(xiàn)象趨于穩(wěn)定后,節(jié)點(diǎn)間的歸并通信開銷成為關(guān)注點(diǎn)。
需要說明的是,為了簡化分析,筆者將由頂點(diǎn)歸并排序優(yōu)化延伸的向量并行優(yōu)化以及孤立點(diǎn)剪枝優(yōu)化帶來的性能提升,統(tǒng)一歸集于頂點(diǎn)歸并優(yōu)化的性能提升。
綜上所述,基于頂點(diǎn)歸并排序的大規(guī)模圖遍歷算法,其性能表現(xiàn)優(yōu)異,并具有良好的可擴(kuò)展性。
4.3 關(guān)鍵頂點(diǎn)優(yōu)先緩存性能分析
在不同圖測試規(guī)模下的圖頂點(diǎn)分布不同,而關(guān)鍵頂點(diǎn)在所有圖頂點(diǎn)中的占比基本恒定在5%左右。關(guān)鍵頂點(diǎn)的優(yōu)先緩存,是將排序后的高度數(shù)頂點(diǎn)緩存在天河系統(tǒng)核組內(nèi)的高速緩存中,其緩存策略需要結(jié)合機(jī)器特征和工程經(jīng)驗(yàn)確定。VS-Graph500主要選取度數(shù)大于等于100的圖頂點(diǎn)組成關(guān)鍵頂點(diǎn)集合,在不同規(guī)模下配置關(guān)鍵頂點(diǎn)優(yōu)先緩存策略后,其性能測試數(shù)據(jù)如圖10所示。
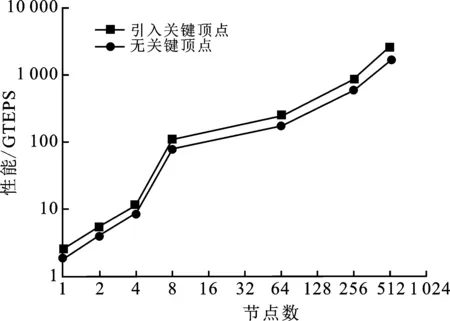
圖10 關(guān)鍵頂點(diǎn)優(yōu)先緩存策略的性能評測圖
由圖10可知,在歸并排序的基礎(chǔ)上引入關(guān)鍵頂點(diǎn)排序后,VS-Graph500的測試性能進(jìn)一步提升。與僅配置歸并排序、無關(guān)鍵頂點(diǎn)優(yōu)先緩存策略時的程序測試結(jié)果相比,優(yōu)先緩存關(guān)鍵頂點(diǎn)后的VS-Graph500性能提升可達(dá)30%。這是因?yàn)椋瑢㈥P(guān)鍵頂點(diǎn)優(yōu)先緩存至核組內(nèi)的高速緩存后,大量的訪問請求將發(fā)送至高速緩存內(nèi),與原先的普通存儲模式相比,有效地提升了遍歷階段的訪問效率。
同時,隨著Graph500測試規(guī)模的增大,應(yīng)用關(guān)鍵頂點(diǎn)優(yōu)先緩存技術(shù)后的圖遍歷性能同步提升,表明該程序的可擴(kuò)展性佳。
4.4 VS-Graph500性能分析
面向天河超級計算機(jī)智能應(yīng)用場景,應(yīng)用頂點(diǎn)排序和優(yōu)先緩存優(yōu)化定制的VS-Graph500全系統(tǒng)性能測試如圖11所示,其展現(xiàn)的圖遍歷性能數(shù)據(jù)均基于對應(yīng)節(jié)點(diǎn)規(guī)模下能夠穩(wěn)定測試的最大圖規(guī)模。其中,面向“K”系統(tǒng)的Graph500在相關(guān)公開文獻(xiàn)及相關(guān)資料的基礎(chǔ)上集成開發(fā),并不代表其實(shí)際能力。
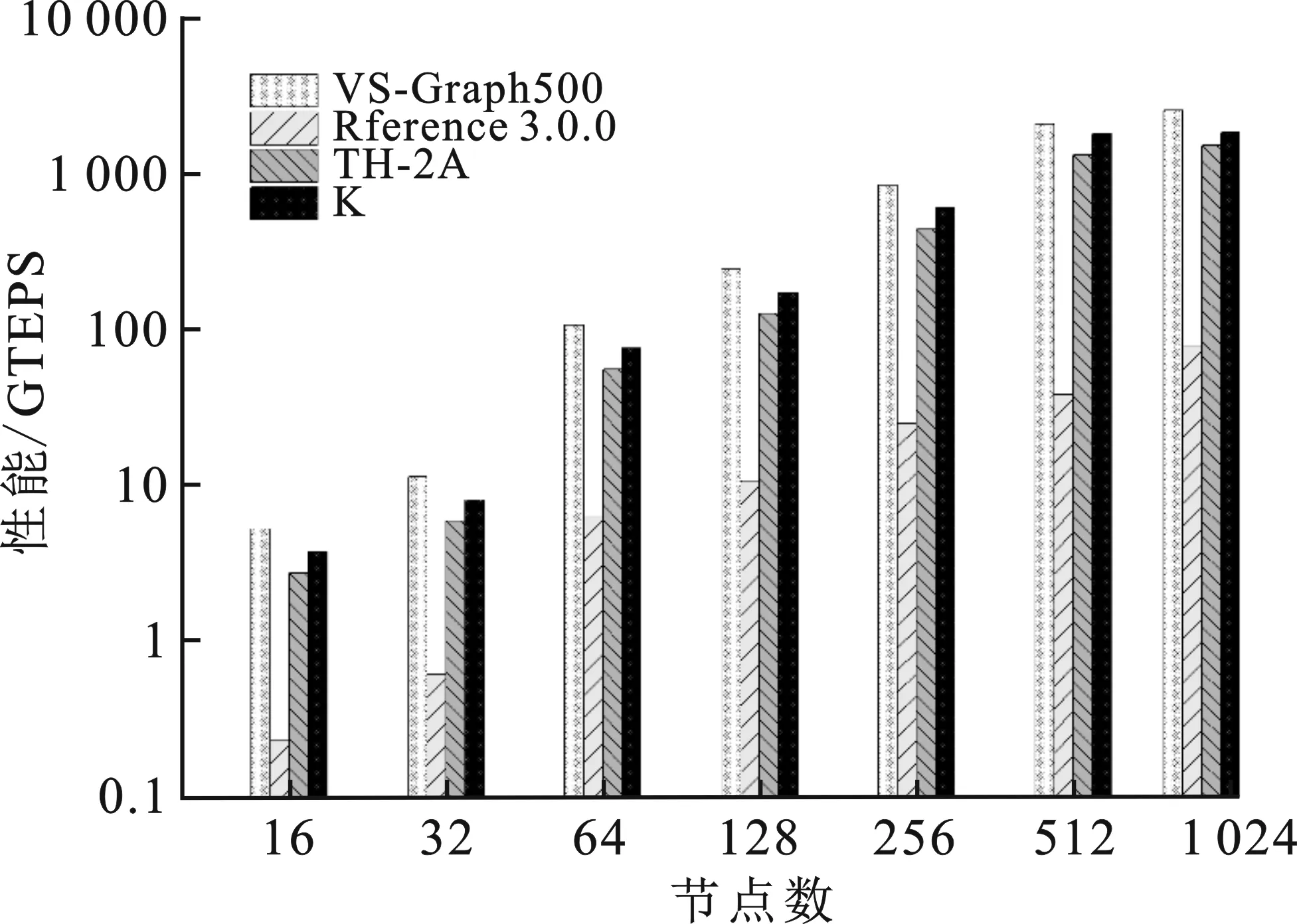
圖11 基于天河超級計算機(jī)的VS-Graph500性能測試
基于度數(shù)高的關(guān)鍵頂點(diǎn)與其他頂點(diǎn)關(guān)聯(lián)概率高的特性,在頂點(diǎn)排序優(yōu)化策略中,圖中所有頂點(diǎn)按照度數(shù)高低從大到小進(jìn)行重排序,便于提前中止冗余訪存,最大可能地減少了不必要的訪存和對外通信。而在關(guān)鍵頂點(diǎn)優(yōu)先緩存策略中,圖中各個頂點(diǎn)對緩存在buffer中的關(guān)鍵頂點(diǎn)進(jìn)行優(yōu)先訪問,能夠有效地提升圖遍歷時的訪問效率。
由圖11可知,面向天河超級計算機(jī)測試系統(tǒng)開發(fā)的 VS-Graph500 的性能與各個版本的Graph500測試程序相比,其性能提升顯著。在全系統(tǒng)為1 024個節(jié)點(diǎn)、但有效可用節(jié)點(diǎn)數(shù)最多為904個,而圖測試規(guī)模Fscale=37時,VS-Graph500的穩(wěn)定測試性能為2 547.13 GTEPS,已超過2020年11月Graph500排行榜第7名的 2 061.48 GTEPS。同時,隨著系統(tǒng)測試規(guī)模和圖測試規(guī)模的增大,VS-Graph500程序的性能測試數(shù)據(jù)也隨之增長,可擴(kuò)展性好。
需要說明的是,904個節(jié)點(diǎn)上的VS-Graph500的測試性能并不能表明在數(shù)萬節(jié)點(diǎn)甚至更大規(guī)模上VS-Graph500的性能表現(xiàn)能同比增長,因?yàn)橄到y(tǒng)規(guī)模越大,Graph500的性能影響因素會更多,因此更復(fù)雜。
5 總 結(jié)
大規(guī)模圖處理是評測超級計算機(jī)系統(tǒng)處理數(shù)據(jù)密集型應(yīng)用能力的重要手段。天河超級計算機(jī)系統(tǒng)將面向大科學(xué)、大工程計算,兼顧海量信息,大數(shù)據(jù)智能處理,拓寬應(yīng)用領(lǐng)域。為此,面向天河超級計算機(jī)系統(tǒng),利用大規(guī)模圖數(shù)據(jù)的小世界性和無尺度性等特征,以及圖數(shù)據(jù)頂點(diǎn)度數(shù)分布呈現(xiàn)的“長尾”現(xiàn)象,筆者提出了基于頂點(diǎn)歸并排序和關(guān)鍵頂點(diǎn)優(yōu)先緩存策略的大規(guī)模圖遍歷優(yōu)化方法。應(yīng)用優(yōu)化程序VS-Graph500,在天河超級計算機(jī)系統(tǒng)實(shí)驗(yàn)平臺上驗(yàn)證了上述優(yōu)化方法的有效性和良好的可擴(kuò)展性。在天河超級計算機(jī)系統(tǒng)實(shí)驗(yàn)平臺全系統(tǒng)最多可用的904個節(jié)點(diǎn)上,VS-Graph500程序的實(shí)測性能為2 547.13 GTEPS,超過Graph500排行榜第7名。
猜你喜歡
兒童時代·幸福寶寶(2022年12期)2022-12-09 11:24:14
房地產(chǎn)導(dǎo)刊(2022年5期)2022-06-01 06:20:14
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2022年11期)2022-02-14 07:14:12
建材發(fā)展導(dǎo)向(2021年12期)2021-07-22 08:06:48
建材發(fā)展導(dǎo)向(2021年7期)2021-07-16 07:07:52
中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年12期)2021-04-26 07:43:48
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年12期)2021-03-08 01:28:50
科普童話·學(xué)霸日記(2020年1期)2020-05-08 16:45:11
小天使·一年級語數(shù)英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
