基于灰狼優化算法的車牌字符識別研究
2021-02-25 13:29:52陳科全吳耀光陳一銘穆協樂張鐵異
物聯網技術 2021年2期
陳科全,吳耀光,陳一銘,穆協樂,張鐵異
(廣西大學 機械工程學院,廣西 南寧 530004)
0 引 言
為了便于機動車的管理,車牌識別系統的完善變得越來越重要。車牌識別系統中主要包含了圖像提取、車牌定位、字符分割和字符識別四大模塊[1]。字符識別作為識別系統中的最后一個環節,對車牌識別的成功與否起到了決定性的作用,識別方法主要包括模板匹配、特征提取識別、支持向量機(SVM),以及卷積神經網絡等。模板匹配[2]識別通過模板匹配函數計算待識別字符與模板字符之間的相似度來實現,字符模板的質量對字符識別的準確率影響較大,待識別字符如果有一定角度的傾斜會造成識別錯誤。特征提取識別[3]利用字符特征的相似度進行字符識別,根據提取的字符特征進行判別和匹配,字符特征的選擇決定了識別正確率。采用支持向量機[4]分類時,懲罰系數C和核參數g的選取會對字符的分類結果造成影響。陳政等采用粒子群優化算法對SVM的參數進行尋優,一定程度上提高了SVM的識別準確率[5]。隨著深度學習的發展,CNN[6]被廣泛應用于字符識別中,該方法通過監督學習自動進行圖像提取和識別,具有較強的魯棒性,但需要大量的樣本進行網絡訓練,而且對硬件要求高。
基于以上分析,提出一種基于灰狼優化車牌字符識別方法,優化SVM參數,建立識別模型,提高字符識別準確率。
1 車牌字符的識別流程及理論基礎
文中主要針對車牌識別系統四大模塊中的最后一個模塊—字符識別展開研究,其他模塊此處不再贅述。為保證識別數據與訓練數據集的格式相同,首先對分割后的圖像進行歸一化處理,并設定每種字符圖片的標簽信息,然后提取車牌字符的HOG[7]特征,建立SVM字符分類模型,利用改進收斂因子的GWO[8]對SVM參數C和高斯核函數參數g進行尋優,建立IGWO-SVM模型,獲取車牌字符識別結果。
1.1 灰狼優化算法
灰狼優化算法(GWO)是一種啟發式優化算法,由Mirjalili.S[9]等人提出,該算法所需設置的參數較少,原理簡單,速度快,全局搜索能力強。灰狼種群等級分為四類,其中α狼為取得最優解的搜索個體,自適應度最優,β狼和δ狼分別為次優解和第三優解的搜索個體,自適應度同理,ω狼的等級最低,為其他候選解的搜索個體。
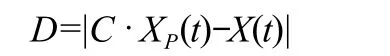
式中:D代表狼群個體與目標獵物之間的距離;C=2r1代表對獵物的擾動,r1為[0,1]之間的隨機數;t代表迭代次數;XP為目標所在位置;X為狼群個體位置。
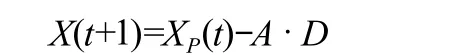
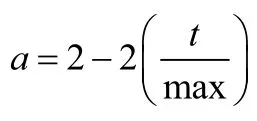
指導狼群靠近獵物,如圖1所示。尋優過程:
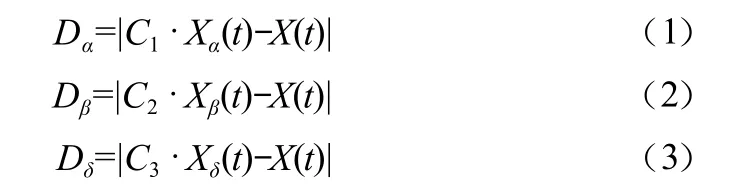
Xα,Xβ,Xδ分別代表α狼,β狼和δ狼的當前位置。
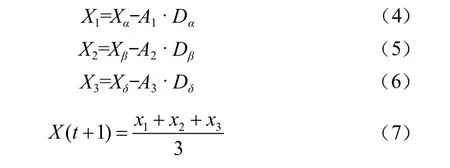
式中:X1,X2,X3分別代表α狼,β狼和δ狼對ω狼指導后的位置;X(t+1)為子代灰狼的最終位置。
為了防止GWO算法陷入局部最優,采用改進收斂因子a的GWO算法[10],將原始的線性收斂因子改為非線性:
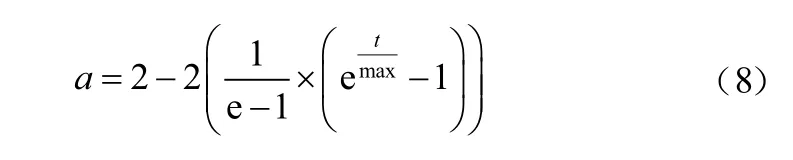
改進后的a將從2非線性遞減到0,可降低衰減速度,更利于尋找全局最優解。
1.2 支持向量機(SVM)
SVM是一種非常高效的分類算法,通過降低結構化風險系數來提高分類模型的泛化能力,可以在樣本數量較少時獲得良好的分類效果。
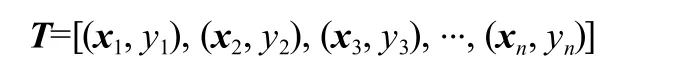
式中:xi∈Rn,i=1, 2, ...,n,表示第i個特征向量,yi={+1, -1},表示特征標簽,yi=+1時,xi為正樣本,反之,xi為負樣本,SVM通過在正負樣本之間建立一個超平面,將樣本分為兩類。通過最大化正負樣本的分類間隔,提高模型的泛化能力:
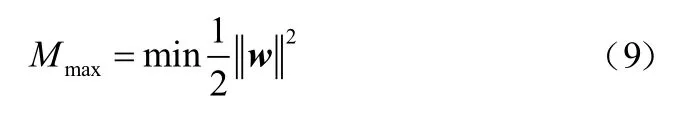
式中,w表示分離超平面的法向量,方向指向正樣本。
除了線性可分問題外,SVM也適用于非線性分類問題,需引入松弛變量ξ≥0和懲罰因子C≥0,保證容錯性:

構造拉格朗日函數,并求解對偶問題:
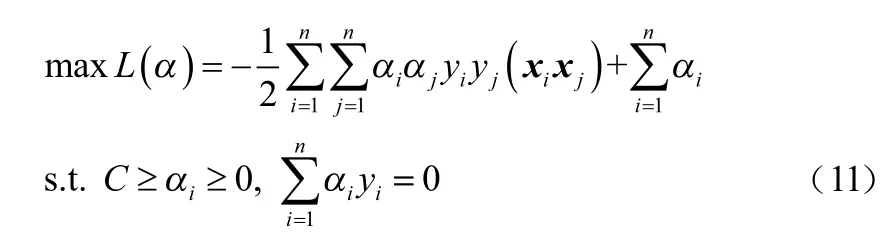
引入核函數K(xi,xj)將低維數據映射到高維空間,并通過核函數的內積運算將高維的復雜運算轉化為低維的簡單運算,簡化線性不可分問題。
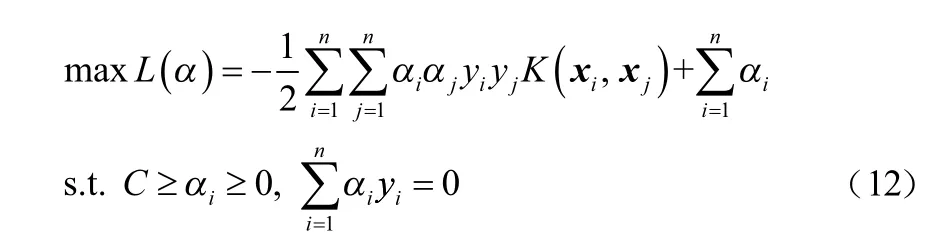
式中,αi、αj為拉格朗日系數。
分離超平面:
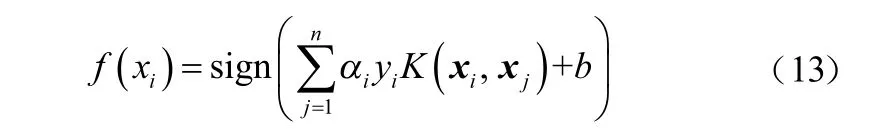
式中,b表示截距。
由于高斯核函數對不同的數據類型具有良好的適應性,且參數少,即選用高斯核函數:
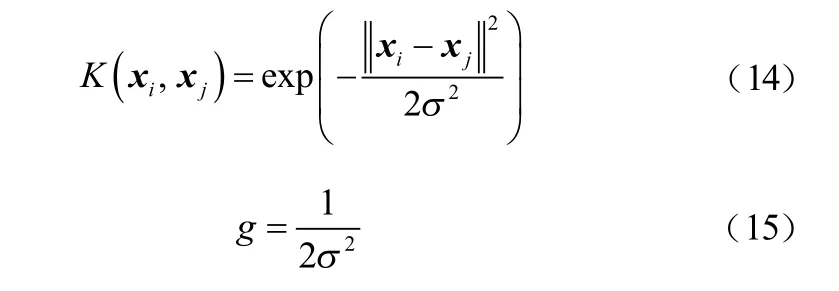
SVM常用于處理二分類問題[11],車牌字符分類屬于多分類問題,組合多個二分類SVM可以構建一個多分類SVM。本文組合構建兩個分類器,分別用于漢字字符、字母和數字字符分類。考慮到字符的標簽多樣性,故采用字符的錯誤率作為自適應函數。
1.3 HOG特征提取
方向梯度直方圖(Histogram of Oriented Gradient, HOG)是圖像處理中常用的圖像特征描述子。提取HOG特征時,先要對圖像進行灰度化處理,對顏色空間進行歸一化處理,然后將圖像劃分為多個cell單元,其中2×2個cell單元組成一個block塊,由式(16)~式(19)計算每個block中cell單元的梯度信息,最后將所有HOG特征進行歸一化處理,得到圖像的HOG特征。
X方向梯度:

Y方向梯度:
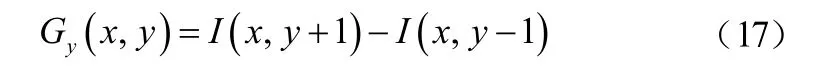
像素點梯度的幅度:
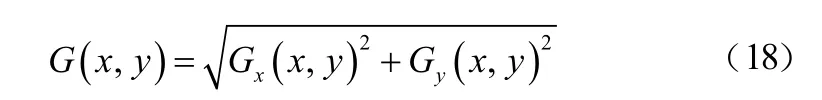
像素點梯度方向:
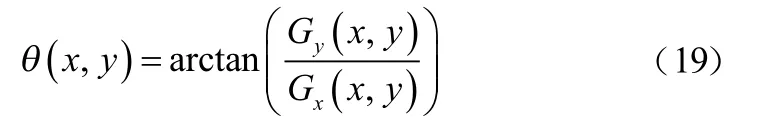
式中,I(x,y)表示圖像中像素點(x,y)處的水平方向和豎直方向的像素值。
2 改進灰狼優化算法的SVM分類模型研究
GWO優化的SVM模型流程如圖2所示。初始化參數時需對狼群數量、迭代次數、尋優參數上下界、優化參數的個數,根據設置的參數生成隨機的懲罰系數C和核函數參數g的向量,每次循環取一組數據訓練SVM,并得到自適應函數值。采用改進收斂因子的GWO算法優化SVM,以測試集分類錯誤的個數作為自適應函數,最小化錯誤率,求得自適應函數值,根據自適應度值更新α狼、β狼和δ狼的位置,然后在三種狼的指導下根據式(1)~式(7)更新其他狼群的位置,完成迭代,獲得最優參數,訓練SVM模型。
3 尋優算法實驗對比分析
本文選取了13 033張車牌字符進行模型訓練,其中漢字字符2 470張,數字和字母2 470張;3 439張車牌字符作為測試樣本,其中漢字字符2 601張,數字和字母838張;拍攝650張車牌用于驗證各算法的準確率,并進行實驗分析。漢字SVM各優化算法對比見表1所列,字母和數字SVM各優化算法對比見表2所列。
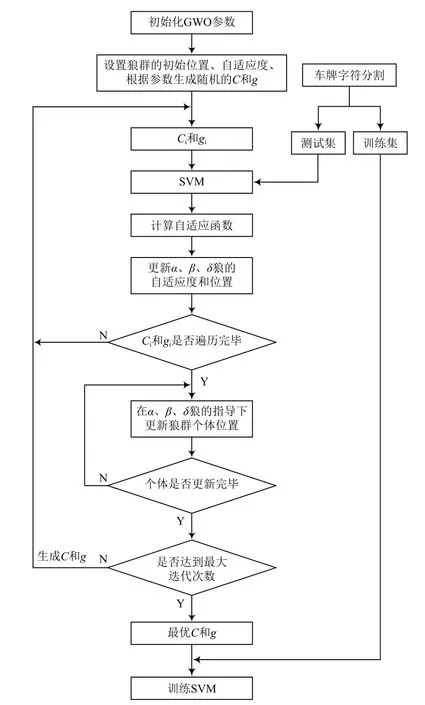
圖2 基于GWO優化的SVM模型流程
PSO-SVM的粒子群數為50,最大迭代次數為20,慣性因子ω=0.8,局部學習因子c1=2,全局學習因子c2=2,參數值的上界為20,下界為0.01;GA-SVM種群數為50,最大迭代次數為20,染色體數為20,基因長度為20,交叉概率閾值pc=0.6,變異概率閾值pm=0.01;GWO-SVM與IGWOSVM的狼群數量為20,最大迭代次數為20,參數值的上界為20,下界為0.01。
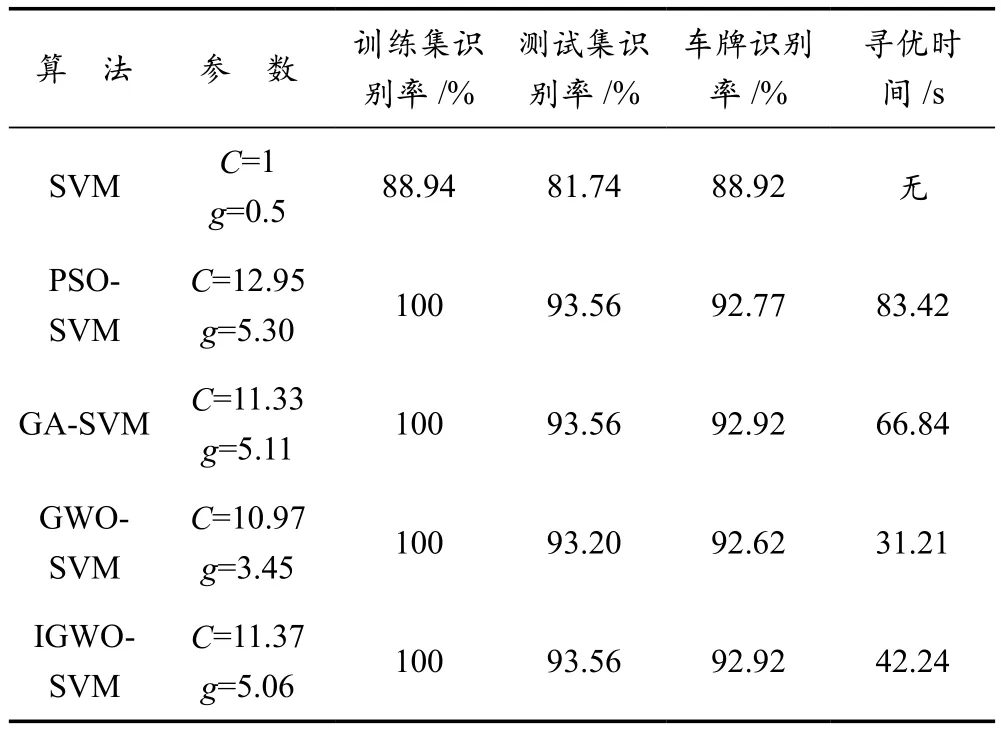
表1 漢字SVM各優化算法對比
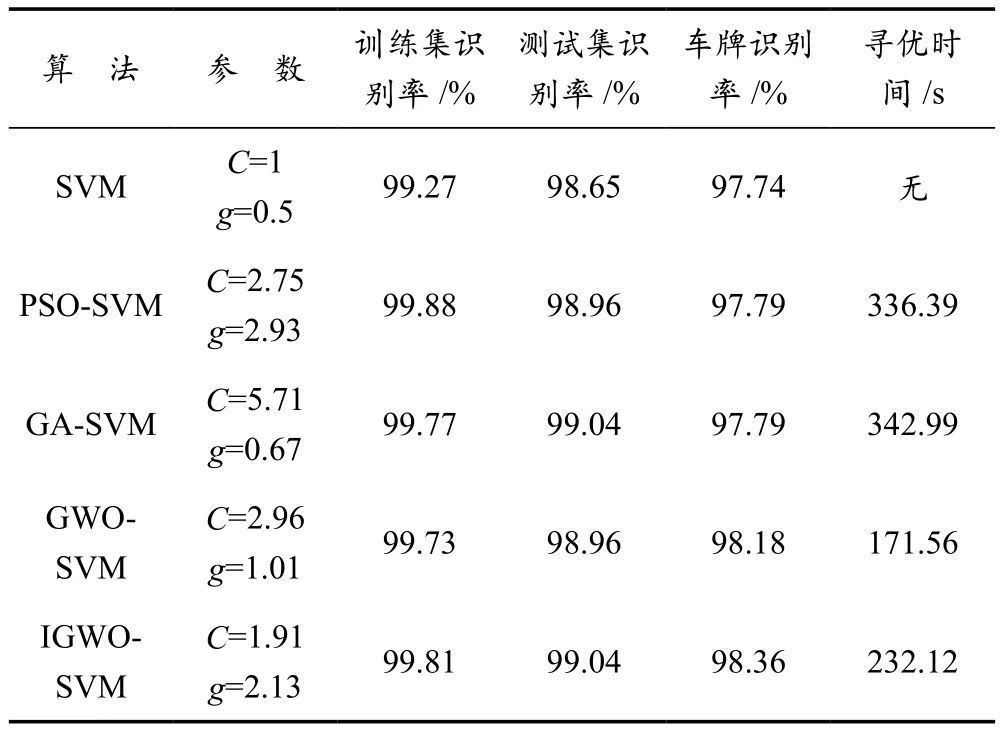
表2 字母和數字SVM各優化算法對比
從表1和表2的數據可以看出,在測試向量集中,四種尋優算法對訓練集和測試集的識別準確率差別不大。文中提出的IGWO-SVM在車牌字符識別中綜合效果更好,其中漢字SVM中IGWO-SVM與未優化的SVM相比,車牌識別準確率提高了4%,與GA-SVM識別率相同,高達92.92%,在尋優時間方面,改進GWO算法比GA算法縮短了近37%;在字母和數字SVM中,IGWO-SVM準確率比未優化的SVM提高了0.62%,比PSO-SVM和GA-SVM高出0.57%,尋優時間縮短了31%和32%,優勢明顯。
4 結 語
針對車牌字符識別的問題,提出了應用改進收斂因子的灰狼優化算法對SVM的懲罰系數C和高斯核參數g進行尋優,建立SVM模型,并與其他方法建立的SVM模型對比。文中提出的方法與粒子群和遺傳算法優化后的SVM分類準確率相當甚至更佳,但是在模型訓練時間上幾乎只用后兩者的二分之一,實際應用過程中,在保證準確率的同時可以極大降低時間成本,綜合表現優勢明顯。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
