基于改進決策樹的電力通信設備狀態預測算法研究*
2021-02-25 06:27:40吳海洋繆巍巍丁士長
計算機與數字工程 2021年1期
關鍵詞:設備
吳海洋 繆巍巍 郭 波 丁士長
(國網江蘇省電力公司信息通信分公司 南京 210024)
1 引言
隨著我國智能電網規模的持續擴展,作為承載經營管理和生產調度業務的電力通信網絡,其通信設備數量和網絡覆蓋范圍都得到了快速增長,電力通信作為電網綜合服務基礎支撐的作用愈發凸顯。因此,進一步提升電力通信網絡的運維水平和保障質量,對于電力通信網以及智能電網的安全運行至關重要[1~2]。
當前,電力通信網絡的運維主要還是針對通信設備的實時告警信息進行故障的事后處置,這種被動響應式的運維模式已遠遠無法滿足通信網絡在線、智能的創新發展需要,難以有效支撐和促進智能電網的蓬勃發展。為提高通信生產運行維護效率,實現電力通信網絡的精益化管理,有必要借助信息化手段,綜合歷史缺陷與檢修、當前性能值與狀態值等海量歷史和實時數據,利用數據挖掘技術實現基于運行狀態的通信設備壽命預測分析,為通信網絡提供主動維護技術手段,解決運維人員短缺與網絡覆蓋范圍和設備數量不斷擴大的問題。
通過多種數據挖掘技術進行設備運行狀態的預測分析已成為網絡運維研究的發展趨勢。決策樹學習算法具有分類速度快、算法實現簡單等優點,已成為最廣泛的狀態預測算法之一。然而在實際應用場景中,經典決策樹學習算法存在著諸如內在多值偏向、計算效率低下等不足之處,需要進一步改進決策樹學習算法,使其能夠更適應電力通信網絡的實際應用要求[3~6]。本文在對 ID3 決策樹算法深入研究的基礎上,借助粗糙集理論對決策表屬性進行約簡、求核、泛化等處理,進而構造出簡潔、高效的多變量決策樹,從而可以有效避免ID3 算法決策樹存在的先天缺陷,有效降低了計算復雜度,提高了預測分析效率,具有較大的實用價值和應用前景。
2 決策樹基本原理
作為數據挖掘分支中最常用的一種經典算法,決策樹學習算法通常用于對未知數據進行分類和預測。自20 世紀60 年代以來,決策樹學習在規則提取、數據分類、預測分析等領域有著廣泛應用,特別是J.R.Quinlan在引入基于香農的信息論中熵的概念后,提出的ID3(Iterative Dichotomiser 3)算法,因其簡潔、高效的決策選擇過程使得決策樹學習算法在不同新興應用領域得到了持續應用及巨大發展[7~9]。
在ID3 決策樹算法中不需要重復遍歷已選的測試屬性,而是采用了貪婪算法和深度優先策略自頂向下的搜索遍歷所有的測試屬性,從而構造出整個決策樹。其核心思想是在決策樹的各層級節點選擇上,以最大信息熵降作為當前節點測試屬性的劃分標準,即當節點上如果有尚未被劃分的、具有最高信息增益的測試屬性,則將其作為劃分標準。通過不斷的搜索遍歷,直到獲取能夠完美分類訓練樣例的決策樹[10~15]。其主要算法如下。
設樣本數據集合S,其可劃分為不同類別Ci(i=1,2,…,n),其中si為類別Ci的樣本數量,則集合S劃分為n個類別對應的信息熵為
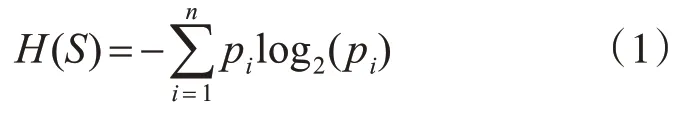
式(1)中,pi表示集合S 中屬于第i 類別Ci的概率,即
假定測試屬性A 中所有互斥值的集合為XA,Sν為樣本數據集合 S 中由測試屬性 A 為 v 的樣本子集,即Sν={s∈S|As=ν},在選擇測試屬性A 后的每一個分枝節點上,對該節點的樣本集Sν分類的熵為H(Sν)。選擇測試屬性A 導致的信息熵定義為每個子集Sν熵的加權平均值,權值為屬于Sν的樣本占原始樣本S的比例由于已知測試屬性A而得到的信息熵為

式(2)中,H(Sν)為樣本子集Sν的信息熵。
測試屬性A 對于數據集合S 的信息增益Gain(S,V)為

Gain(S,V)是指已知測試屬性A 值后所導致的信息熵期望值的減少量。若Gain(S,V)值越大,則說明測試屬性A 的選擇對樣本數據集的分類可提供的信息量越大,其分類效果也會越好。
與其他統計模型、神經網絡、遺傳算法等分類算法相比,ID3 決策樹學習算法以實例為基礎進行歸納學習,具有實現簡單直觀、分類速度快、平均深度最小等特點。但同時也存在著生成樹效率較低、內在多值偏置、只能檢驗單一屬性等不足。在電力通信網絡中,不同通信設備之間的運行狀態值可能會存在著強相關性或弱相關性,同時網絡拓撲結構比較復雜,因此針對電力通信網絡實際的運維管理需要,本文嘗試對傳統算法進行改進,將其運用到電力通信設備的狀態預測分析中,從而為電力通信網絡的運行維護提供一種事前狀態的預測方法。
3 改進的決策樹算法
針對ID3 決策樹學習算法存在的缺陷,本文嘗試利用粗糙集理論對傳統算法進行改進,即將最小粗糙度作為決策樹分枝的校驗屬性,通過對決策表的一系列處理過程,最終構造出電力通信設備狀態預測決策樹。
定義一個決策表信息系統S=(U,R,V,F),其中論域U 為一個非空有限對象的集合,R 為所有屬性集合,可分為測試屬性集A 和決策屬性集D,即是屬性R 的值域,信息函數F:U×R→V。
在傳統算法中一般采用遞歸方式構造出決策樹,本文提出的改進決策樹算法則從測試屬性集A相對決策屬性集D的核開始,逐步構建出整個決策樹。其主要算法過程如下:
1)根據樣本數據集構造出決策表。
2)計算測試屬性集A 相對決策屬性集D 的核,記為careD={a1,a2,…,ak} ,若careD=? ,則轉到步驟3,否則到步驟4)。
3)采用ID3 決策樹算法,選擇一個最佳屬性,以此作為該節點的檢驗屬性。
4)給出合取范式形式P=a1∧a2∧…∧ak,計算P相對決策屬性D的泛化GEND(P),并將其作為決策樹根節點的檢驗屬性。
5)在當前樣本數據集中計算剩下的條件屬性集合A/careD(A)A中每個屬性對決策屬性集D的粗糙度,從中選擇出粗糙度最小的屬性作為該結點檢驗屬性的最優解。其粗糙度計算公式如下:

利用粗糙度計算方法對傳統的ID3 決策樹學習算法進行改進,將原來信息熵降替換成最小粗糙度來確定分類的檢驗屬性,有效增強了不同屬性之間的結構關聯,改善了生成的決策樹結構。
因此,在電力通信設備運行狀態屬性取值之間關聯度較強,無沖突數據的狀態預測分析時,運用改進的決策樹算法可以得到更優化的解,且計算工作量相對較小。
4 算例分析
4.1 數據來源
為對電力通信設備的未來狀態進行事前評判,在構造用于預測分析的決策樹時,需要盡可能收集設備相關的樣本數據以供學習。如圖1 所示,與通信設備運行狀態有相關性的信息包括設備的履歷信息、設備的檢修信息、設備的缺陷信息等,通過數據抽取、清洗后存放到數據庫中,以便后續對這些信息進行數據挖掘。
本文通過對電力通信設備的歷史運行與維護信息進行抽取,挖掘設備異常情況下的特征值,分析設備的關聯參數值以及它們之間的相關性,結合當前實時監測采集到的設備運行數據,對可能存在的故障隱患進行預測與判斷,最終提供給運維人員進行事前檢修。

圖1 數據來源與處理示意圖
電力通信網絡作為一種復雜系統,其設備自身的特征值(如光功率、抖動、飄移、誤碼率、誤碼秒、信噪比等),以及運行環境的特征值(如機房溫度、機房供電等)對通信設備的運行狀態有著或多或少的影響。通過數據挖掘與分析,構建出多變量數的預測分析決策樹,當設備的運行狀態值有逼近標準定義異常狀態的趨勢時,則可對潛在故障或隱患實現事前預測。
4.2 算法實現
首先,依據收集的電力通信設備相關運行狀態的試驗數據樣本,利用改進的決策樹算法構建決策表,如表1所示。
1.2.1 分組 采用隨機數字法將90例擬行無痛分娩產婦均分為3組,A組采用生理鹽水復合0.10%羅哌卡因硬膜外麻醉、B組采用0.25 mg/L舒芬太尼0.1 mL復合0.10%羅哌卡因5 mL硬膜外麻醉、C組采用0.50 mg/L舒芬太尼0.1 mL復合0.10%羅哌卡因5 mL硬膜外麻醉。

表1 通信設備狀態對應的決策表
其中,論域U 對應于收集到的試驗數據樣本集合為{1,2,…,8}。測試屬性A 對應于試驗數據樣本中的 7 類測試特征集合為{A1,A2,…,A7}。決策屬性D 對應的試驗數據樣本異常類型集合為{Ⅰ,Ⅱ,…,Ⅷ}。
其次,計算測試屬性A 對應的決策屬性D 的核。定義posIND(A)(D)={1,2,3,4,5,6,7,8}=U。
1)判斷測試屬性Ai(i=1,2,…,7)在測試屬性A 中 對 于 決 策 屬 性 D 的 重 要 性 。 若posIND(A-Ai)(D)=posIND(A)(D),則表示該Ai為非必要的,否則表示該Ai為必要的。
2)根據表1計算得知,A2,A3,A4,A5在測試屬性A 中對于決策屬性D 是非必要的,而A1,A6,A7在測試屬性A 中對于決策屬性D 是必要的。即coreD(A)={A1,A6,A7} 。
然后,設定合取范式形式P=A1∧A6∧A7,計算出P 對決策屬性D 的泛化在論域U 上的等價類劃 分 ,可 以 得 到U/IND(P)={{1},{3},{4},{5},{7},{8},{2,6}}。由于構成的泛化GEND(P)將測試屬性A 和決策屬性D 可劃分成惟一的等價映射關系,因此可將GEND(P)作為本決策樹的根節點。
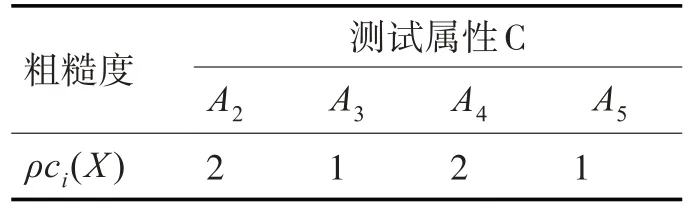
表2 決策屬性D′的粗糙表
由表2 可知,最小粗糙度為ρA3(X)=ρA5(X)=1,因此測試屬性A3和A5可作為D′的校驗屬性。
以粗糙度最小的屬性作為判定依據,不斷從剩余的測試屬性集中篩選出各層級節點的校驗屬性,最終可得到的基于改進決策樹結構如圖2所示。

圖2 基于改進決策樹的結構圖
利用粗糙度的計算進而確定分類檢驗屬性的方法有效改進了傳統決策樹學習算法的不足,能夠對數據不確實、多變量以及數據不完整等分類問題給予妥善處置,優化和簡化了決策樹結構。
5 結語
電力通信網絡中設備運行狀態異常的表現多種各樣,其發生機理也是復雜多變,本文提出的改進決策樹可從樣本數據中學習規則,具有自組織和自適應性。隨著實際環境中運行狀態信息的不斷收集,使得可用的樣本數據不斷增多,錯誤樣本將逐漸“淹沒”在海量的正確樣本中,使得決策樹的構建越來越準確。同時,粗糙集理論的引入,能夠較好地處理實際生產環境中獲取的連續量、數值量等不同特征值的樣本數據,實現了一種簡略、快捷的預測分析分類方法。
本文提出的改進決策樹算法對電力通信設備狀態的預測分析具有一定的借鑒意義,其實用性需要建立在海量、完備的樣本數據基礎上,通過自學習不斷修正自身的判定規則,使得預測分析決策樹不斷趨于真實表現。后續工作中,將加大運行狀態數據采集的范圍與深度,從而使得改進算法對設備狀態預測分析更具可行性。
猜你喜歡
中國特種設備安全(2022年6期)2022-09-20 02:52:28
當代工人(2020年13期)2020-09-27 23:04:20
經濟技術協作信息(2018年22期)2019-01-19 03:00:18
電子制作(2018年11期)2018-08-04 03:26:08
電子制作(2018年10期)2018-08-04 03:24:48
家庭影院技術(2017年11期)2017-12-20 08:10:57
工業設計(2016年12期)2016-04-16 02:52:00
IT時代周刊(2015年8期)2015-11-11 05:50:37
汽車維修與保養(2015年1期)2015-04-17 03:25:28
設備管理與維修(2015年12期)2015-04-09 06:57:00
