基于多視圖的半監督集成學習方法*
2021-02-25 06:27:58張振良劉君強
計算機與數字工程 2021年1期
張振良 劉君強 黃 亮 張 曦
(1.鄂爾多斯應用技術學院 鄂爾多斯 017000)(2.南京航空航天大學民航學院 南京 211100)
1 引言
在機器學習和數據挖掘應用程序中,我們尋找很多方法來提高分類器的性能。集成學習是一種機器學習方法,最初,集成學習的提出是由于Schapire 證明了多個弱分類器可以形成一個強分類器,所謂的弱分類器是指分類效果很差的模型,集成學習的目的是通過組合多個分類器的輸出來構造多個不同的分類器[1]。所謂“集成”是專家的混合體,用以防止過度擬合以及減少所有基礎學習器的誤差,而如何結合多種學習器的輸出結果和提高基分類器的多樣性來提高分類器的精度是重點[2]。
集成分類器的關鍵是根據所有基分類器的預測來量化未標記樣本的置信度,而精度也隨分類器的數量增加而增加,而且對所有的訓練集以及算法沒有要求,避免了大量交叉驗證[3]。
現有的算法大多只使用標記數據來構造分類器,而且在很多情況下,標記數據的數量通常不足以訓練出魯棒性很強的分類器,同時大多數情況下,標簽數據的獲取成本很高,而未標記的數據則很容易獲得而且數量更多。基于這個原因,半監督學習獲得了越來越多的關注,它致力于從未標記樣本中獲得信息,尋找大量的未標記數據中的規律,再利用少部分已標記數據的信息,做出預測。大多數現有的SSL(Semi-supervised learning)技術主要是在未標記數據的信息獲取方式上加以區別。
將半監督學習方法引入到集成學習中,鄔[4]提出三重訓練的思想,訓練生成三個分類器,而且無需滿足苛刻的獨立條件,然后使用其他兩個分類器同意的未標記數據對另一個分類器進行改進,由于未標記數據的分類誤差估計比較困難,因此,在未標記數據與標記數據具有相同分布的前提下,僅對標記數據進行分類誤差計算。三次訓練過程的學習一直持續到誤差停止減小為止,這意味著已經達到了最大的泛化效果。在一定的理論證明限制下,將一致的未標記樣本逐步加入到標記數據中,用于細化相應的分類器,直到沒有一個分類器的預測誤差進一步減小,一旦學習過程完成,就可以用兩個或多個成員分類器一致同意的標簽來預測未標記或看不見的數據[5]。三重訓練方法很有吸引力,因為它在原始的共同訓練方法中成功地解除了對兩個條件獨立視圖的要求,而沒有經歷過實踐中提出的耗時的交叉驗證過程。
王立國[6]提出改進的三重訓練算法,先選取信息量最大的未標記樣本,利用差分進化算法產生新樣本,再利用這些新樣本繼續迭代[2]。楊印衛、王國鋒[1]選取了支持向量機(SVM)、隱馬爾科夫模型(HMM)以及徑向基神經網絡(RBF)這三個單分類器作為異構集成學習模型的基分類器,同時采用了majority voting和stacking兩種集成結果整合策略來選擇最優組合,證明異構集成學習模型的泛化能力相比于以往單分類模型得到了改善,同時模型復雜度降低。傅向華、馮博琴[7]等提出一種異構神經網絡集成協同構造算法,利用進化規劃同時進化網絡拓撲結構和連接權值,連續學習生成多個異構最優網絡,然后對異構網絡進行組合。在構造神經網絡集成的過程中通過協同合作,保持各網絡間的負相關,從而在提高成員網絡精度的同時增加各成員網絡之間的差異度。
這些算法的優點在于不要求用于分類的屬性由多個獨立視圖描述,從而大大擴展了基于共同訓練的半監督學習的適用性。但是,這些算法的一個潛在弱點是,因為初始分類器是由Boosting 算法進行自舉采樣,基分類器差異性被樣本多樣性局限,算法的成功在很大程度上取決于原始集合分類的多樣性
本文將從采用多個視圖以及不同的特征降維方法和學習模型來創建更加多樣化的基學習器,未標記的數據通過集合成員的簡單多數表決來預測,而不是復雜測量方法,以期有效地提高以最小的開銷成本預測未標記樣本的標記的準確性,其次所提出的方法預測具有特定標簽的數據的概率,然后可以使用該方法選擇最可靠的預測的未標記數據以添加到標記數據。相比之下,其他算法隨機選擇池中的一定數量的未標記數據用以訓練。鑒于這些屬性,基于多視圖的半監督集成學習算法能夠可靠地應用于各種分類問題。
2 相關工作
2.1 多視圖方法(Multi-View,MV)
所謂視圖其實就是特征集,在具體的分類過程中,由于訓練集可能有著多種多樣的特征屬性,如果全部輸入到網絡中進行學習不但數據龐大難以學習,而且特征之間也無主次,影響精度。我們以垃圾郵件的分類為例[8],在諸如公共垃圾郵件數據集之類的研究中,如主題長度,信息大小,附件大小和圖片數量等特征都在分類垃圾電子郵件時有所幫助。基于以上特點,本文總結了上述14 個特征如表1 所示,并且采用兩個視圖也就是數據集來表示電子郵件。這種特殊的數據構建方法使我們的工作與大多數現有工作不同。在實際部署中,我們確定可以通過當前的電子郵件技術(即路線跟蹤和內容記錄)輕松捕獲和計算上述特征。

表1 視圖示例
為了更好地描述本文方法,使用ɑ 和b 表示兩個視圖的所有特征,已標記樣本用(<ɑ,b>,c)表示,其中 ɑ∈ A 和 b∈ B 是示例的兩個部分,c 是標簽,0表示負類,1 表示正類。假設在A 和B 上有兩個函數f1和f2,使得f1(ɑ)=f2(b)=c。這意味著每個標簽都與兩個視圖相關聯,其中每個視圖都包含足夠的信息來確定示例的標簽。因此,如果給出k 個例子,可以給出具有標記的數據集 L:(<ɑk,bk>,ck)(k=1,2,…,ck是已知的)。設 U=(<ɑi,bi>,ci)(i=1,2,…,ci未知)表示大量未標記數據,我們的任務是訓練一個分類器來分類新的例子。
2.2 多特征降維方法(Multi-Feature)
由上可知,采用多個視圖描述兩組特征,但為了構建用于解決分類問題的可靠模型,期望特征應包含盡可能多的有用信息,并且特征的數量盡可能小[9]。但是,由于關于數據集的先驗知識通常很少,因此難以區分哪些特征是相關的哪些特征不相關。因此,通常需要考慮大量功能,包括許多不相關和冗余的功能。不幸的是,不相關和冗余的特征不僅會降低學習效率,而且會對因此訓練的機器學習的性能產生負面影響,從優化的角度而言,特征選擇是一個組合優化問題。首先,由于特征子集的大小不是先驗已知的,因此決策空間的維度是不可簡化的。其次,因為功能可能彼此之間具有互補或相互矛盾的相互作用,決策空間是不可分離的。因此,給定m 維特征集,所有可能的特征子集的數量都大到2m,這使得用傳統的窮舉搜索方法解決它的可能性很小[10]。
現有的特征降維方法有獨立成分分析(ICA)、主成分分析法(PCA)、粒子群優化算法(PSO)以及競爭群優化算法(CSO)等。ICA的基本思想即在線性變換的基礎上,使用訓練樣本找到一組相互獨立的投影軸,利用其獨立成份作為樣本數據。PCA利用去除了樣本二階統計意義的相關性信息,ICA則利用去基于訓練樣本的二階統計信息。使樣本的各階統計意義下的信息都得到了充分利用。PCA 基于訓練樣本的二階統計信息,因而其忽視了高階統計意義下的信息。在PSO中,每個粒子在n 維搜索空間中保持位置和速度,表示候選解決方案和可能更好的解決方案的方向。為了搜索全局最優的位置,每個粒子按公式迭代更新,但當優化問題具有高維度和復雜的搜索空間時,其性能仍然有限,為了提高PSO 的性能,已經提出了許多PSO變體,包括基于參數自適應的變體,基于結構的拓撲變體等。在CSO中[11],粒子從隨機選擇的競爭者中學習,而不是從全球或個人最佳位置學習。在每次迭代中,將群體隨機分成兩組,并在每組的粒子之間進行成對競爭。在每次比賽之后,獲勝者粒子將直接傳遞到下一次迭代,而輸家粒子將通過從獲勝者粒子中學習來更新其位置和速度。
3 基于多視圖的半監督集成學習方法
3.1 基于多視圖的未標記樣本篩選
半監督學習算法的關鍵步驟是估計標簽置信度,以選擇適當的未標記樣本進行標記。這對于普通的分類而言很簡單,只需要隨機選擇未標記樣本即可,但由于有著大量的未標記樣本,有些未標記樣本可能對于學習沒有幫助甚至會起到反作用,所以對未標記樣本的篩選是很有必要的,很多文獻[12]忽略了這一點。
為了解決這個問題,通過評估未標記樣本的標記對現有標記數據的影響來估計標記置信度是可行的,但是基于假設標記數據上的回歸量的誤差應該減少最多,如果使用最可信的未標記樣品在每次迭代中重復評估模型將導致高計算復雜性。基于這些原因,提出了一種基于分歧的篩選算法。借用Tri-Training[13]的想法,使用基于三個視圖訓練的三個回歸量來確定如何選擇合適的未標記樣品進行標記。對于任何回歸量,我們通過利用其他兩個回歸量的均勻性來估計標記置信度。如果其他兩個回歸量的估計值之間的差異較小,則未標記的樣本獲得較高的標記置信度。使用此方案,不再需要評估模型。在每次迭代中,我們選擇具有最小估計差異的未標記樣本以擴展標記數據。
然而,僅考慮估計差異將導致所選未標記樣本的分布偏差。原因是較小的估計差異傾向于有利于具有較低估計值的未標記樣本。例如,如果樣本A 和 B 的估計變量值約為 30 和 300,則樣本 A 更容易獲得較小的估計差異。這個問題會導致模型傾向于僅從樣本空間的一部分學習知識,從而降低模型的泛化。為了緩解這個問題,在每次迭代中,我們按照它們的估計值對未標記的樣本進行排序,并將它們分成幾個具有相同數量的未標記樣本的區間,然后分別為每個區域選擇未標記的樣本。
在學習步驟中,它應用學習模型根據當前標記數據從三個視圖重新訓練學習模型,并且用以對未標記樣本U1預測,在選擇步驟中,對于每個視圖,它首先通過使用式(1)計算估計差異Δy,其次,它根據候選樣本集進行排序估計并將其分成具有相同數量樣本的β部分。最后,它分別選擇每個部分中具有最小估計差異的α%樣本篩選出來得到U用以下面的算法。

3.2 構造基學習器
構造差異性更好的基學習器是我們的目的,從而促進半監督以及集成學習的泛化性能。值得一提的是,為了盡可能獨立地創建視圖,模型應盡可能地不同。例如,線性判別分析(LDA)和線性支持向量機(LSVM)都具有線性超平面,因此,它們創建的“模型”不太獨立。相比之下,LDA 和k-近鄰(kNN)更可能會創建不同的視圖,因為KNN具有與LDA 不同的離散超平面。假如我們根據特征的多少我們構建了兩種視圖,選取了獨立成分分析(ICA)、主成分分析法(PCA)、粒子群優化算法(PSO)以及競爭群優化算法(CSO)四種特征降維方法,模型上采用樸素貝葉斯分類器(NB)、J48 決策樹(J48)以及KNN(k=5)3 種模型。則我們可以提供2*4*3=24 種不同的訓練方式,再通過重抽樣方法提高訓練集的多樣性,提供具有穩定差異性的基分類器。
通過上述步驟,可以生成大量的基分類器。但由于基分類器的數量可能很大,所以其他所有分類器都不太可能就未標記數據達成一致。該問題的解決方案是引入投票機制來預測標簽,與給出確定性標簽的三訓練算法不同,所提出的方法預測具有特定標簽的數據的概率。然后可以使用該概率來選擇最合適的未標記樣本。這不會增加太多計算復雜度,因為基于來自每個基礎分類器的置信度輸出而不是如在共同學習算法中使用交叉驗證來計算置信水平。
3.3 基學習器集成算法步驟
首先定義已標記樣本L 及篩選后的未標記樣本集U,重抽樣算法[14]B(x),排序函數S
1)根據上述方法構造24 種學習模型P=<V,F(x),H(x)> ,其中 V 為視圖,F 為特征降維方法,H 為基本模型,同時對L 進行重抽樣,依照重抽樣后的樣本以及學習模型訓練24 種基分類器hi=P<B(L)>,其中B為重抽樣算法。
2)使用第i個分類器hi預測未標記樣本xk,得到其分類結果hi(xk)=yi,同時使用其余23 個分類器進行預測得到分類結果hj(xk)=yj,(j≠i,i,j=1,2,…,24),若有ni個預測結果與hi預測結果相同,則得到xk在置信度為
相比于其他算法,本算法優點有:
1)通過增加多視圖以及特征降維方法增加基學習器差異性。
2)通過對未標記樣本的篩選,增加半監督學習的穩定性。
3)集成方式在運算中調整各分類器權值,進行增量式學習,進一步提升分類器性能。
4 仿真實例
4.1 UCI數據集實驗
為了比較所提算法與其他算法的性能,我們對來自UCI 機器學習庫的8 個數據集進行了一系列實驗[15]。數據集的屬性總結如表2。

表2 UCI分類數據屬性
對于每個數據集,使用數據集中的25%樣本作為測試數據,其余75%用于訓練。在我們測試SSL 算法時,并非所有訓練數據都與標簽一起使用,盡管所有數據都已標記。我們人為地將20%的數據設置為標記其余80%未標記。例如,假設有一個包含1000個實例的數據集,250個實例用作測試數據,750個實例用作訓練數據,其中750個實例中的150 個被視為已標記,其余600 個被視為未標記,訓練和測試集的選擇是隨機的,同時保留所有集合中正負類的原始比率。
本文使用n 倍交叉驗證的平均錯誤率(用n =3)在標記數據上作為CSO的適應度函數,以降低選擇特征子集中過度擬合的風險。CSO 算法中的其他參數設置如下。種群大小為30,最大迭代次數為100,φ為0.1。在第一次在[0,1]之間隨機初始化粒子,閾值參數λ為0.5。PCA 轉換中涵蓋的方差設置為0.95。每個算法獨立運行25次,
4.2 實驗結果
計算各分類器絕對誤差后的具體結果見表3~表6,其中“MT”表示采用多種學習模型,“MF”表示多種特征降維方法,“MV”表示多視圖方法,“3M”表示所提算法,“ST”表示單視圖方法,“TT”表示三重訓練方法,具體的特征降維以及學習模型的字母表示在3.2 節中已有描述。在表3 中,我們發現J48決策樹在這些特定數據集上比其他學習模型有著更好的性能,而其他模型在相同數據集上產生更大的誤差。因此在MT算法中由于其他模型會降低整體集成,因為他們給出了更多的錯誤決策,即便如此,MT 方法仍然具有與J48 方法極其相近的誤差。我們可以得出結論,直接使用原始的學習模型,不經過其他方法的調整,MT方法并沒有展現出自身的優勢,因為他集合多種模型優勢的同時也吸收了其劣勢。
表4~5 為使用多種特征降維方法以及多視圖方法對分類器泛化能力的提升,可以看到無論對于單一的學習模型,還是MT方法,多視圖以及多特征降維方法都可以極大提升分類器的精度,單一的特征操作方法誤差都與MF 方法相差甚遠,多視圖方法對TT 學習模型也有著巨大的改進。同樣的,在有其他算法的調整下,無論是特征降維還是多視圖方法,MT算法都展現出了優于單一分類器的性能,此時集成學習能夠更好吸收多種學習模型的優勢,展現出對單一分類器模型的巨大優勢。

表3 MT算法誤差比較
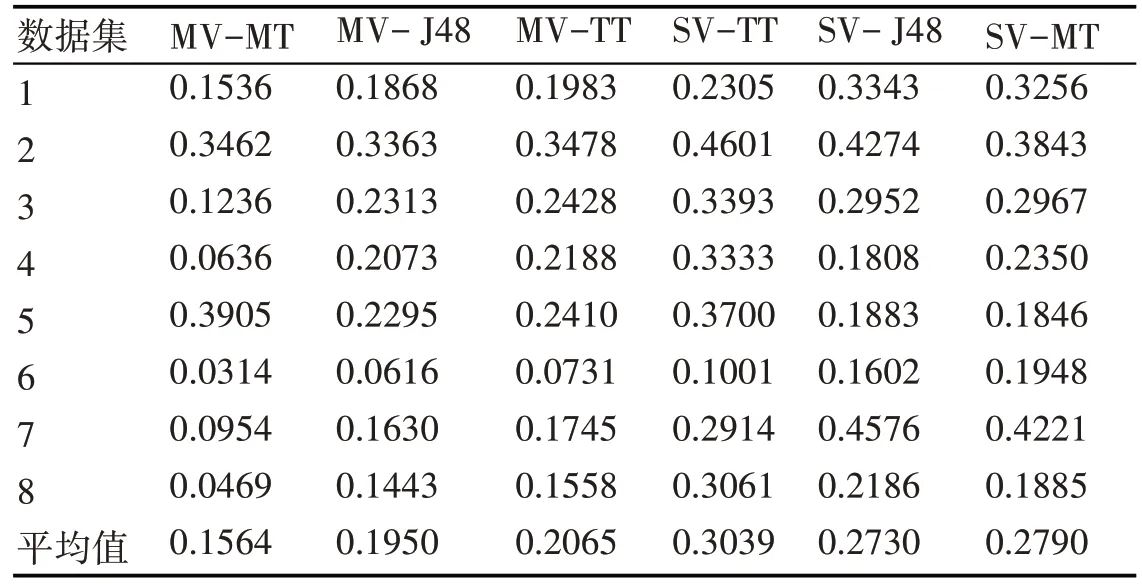
表5 MV算法誤差比較

表6 3M算法誤差比較
在最后一組實驗中最后我們同時采用MT、MF以及MV 方法來構造分類器,調查包含更多基礎學習器是否能夠進一步提高泛化能力。在這項工作中進行的最后一組實驗是比較使用前3 組實證研究中使用的設置組合生成的集合。具體結果如表6,3M 通過結合使用三種不同的特征操作方法和四種不同的分類器模型來創建多樣性,從而產生24種不同的基學習器。 MF-MT,MV-MT,MV-MF-TT,MF-TT 和 MV-TT 分別有著 12,6,6,4,2 種基分類器,其錯誤率也隨基分類器數量的減少而增加。所以我們可以得出結論,所提方法通過增加基分類器的多樣性來提升集成學習的泛化性能。
4.3 垃圾郵件分類實驗
在本節中,我們使用真實郵件數據集并在真實的網絡環境中評估我們提出3M分類模型。其中包含58 個屬性和總共4601 封電子郵件(813 封垃圾郵件和688 封合法電子郵件)[16]。為了評估基于分歧的半監督學習算法,我們將該數據集分為兩部分:標記數據和未標記數據,其中未標記數據由從原始數據集中隨機選擇的600個實例組成,進行60次迭代測試,然后計算預測率后與其他分類器模型相比較。
圖1為ROC曲線圖,是用于比較各種分類器性能的重要度量。它代表了作為單個標量的預期性能,其中曲線下面積越大,表示分類器性能實驗越好,可以看出,即便在考慮原樣本中正負樣本比例的情況下,3M算法仍然展現了良好的性能。
圖2 為在學習過程中分類器的精度變化,可以看出在少量訓練樣本時相較于其他算法由于3M算法可以吸收未標記樣本的從而有著良好的預測性能,與普通的半監督算法相比,它有著多種模型用以及時糾正半監督算法中的錯誤。
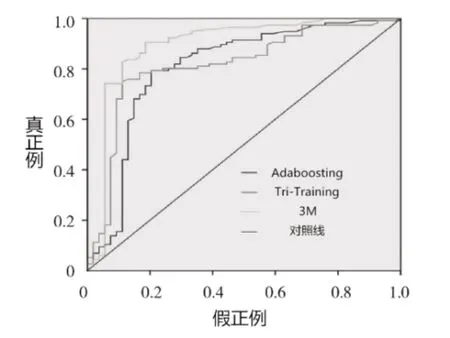
圖1 ROC曲線圖

圖2 預測精度變化圖

圖3 參數β對算法的影響
圖3~圖4 為篩選未標記樣本時參數的設置對誤差的影響,當β=1 時,算法根本無法達到其最優性能。也就是直接選用全部的未標記樣本根本無法窮盡半監督算法的性能,當β=3 時,多視圖半監督回歸算法可以很快最優性能。
其次,所提出算法在每組中選擇ɑ%樣本用以學習。為了研究參數ɑ的影響,我們確定β=3,并將ɑ從1 增加到9。結果顯示在圖4。如果我們為ɑ(ɑ≤1)指定一個太小的值,則多視圖半監督回歸算法在幾次迭代中無法達到其最佳性能。它表明,ɑ可以加速半監督學習過程。但是,如果我們為ɑ(ɑ ≥7)設置了太大的值,則在多次迭代后RMSE 將顯示不穩定的上升和下降趨勢。它表明在一次迭代中選擇太多未標記的樣本往往會帶來噪音。最終在ɑ=3時半監督效果較好。

圖4 參數α對算法的影響
5 結語
本文提出了一種新型的集成分類器,使用多種視圖、特征降維方法和學習模型來構造更多的基分類器來提高集成性能,篩選無標記樣本加入到學習中,最后在將其與Tri-Training 和非SSL 學習模型進行比較,表明所提出的3M 模型優于比較算法。與原始單視圖數據相比,更好的性能可歸因于多個視圖配合不同的特征操縱方法帶來的多樣性。此外,通過使用集成方法,改善了未標記數據的預測準確度,因此能夠降低半監督學習未標記數據的風險。我們的結果證實,由不同類型的基礎模型組成并使用不同特征的異構集成學習具有優異的泛化性能。
將來我們將研究此種方法在差異性方面的更多發展以及在故障預測方面的應用。并將其應用于民用航空故障診斷或分類中,更好地提升安全性以及降低維修成本。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
