基于稀疏子集分析的軌跡聚類發(fā)現(xiàn)*
2021-02-25 06:27:58陳平華
計(jì)算機(jī)與數(shù)字工程 2021年1期
關(guān)鍵詞:檢測(cè)
薛 璇 陳平華
(廣東工業(yè)大學(xué)計(jì)算機(jī)學(xué)院 廣州 510006)
1 引言
隨著現(xiàn)如今人們?cè)谏鐓^(qū)間的軌跡日漸增多,通過軌跡來(lái)檢測(cè)社區(qū)對(duì)于社會(huì)行為分析和推薦服務(wù)都成為關(guān)注熱點(diǎn),所以對(duì)檢測(cè)社區(qū)的精確度要求越來(lái)越高。現(xiàn)有的研究側(cè)重于社會(huì)聯(lián)系和圖分區(qū)中的社區(qū)檢測(cè),但在實(shí)踐中,由于隱私問題,現(xiàn)實(shí)生活中的生活聯(lián)系很難被捕捉。不過,我們可以利用Wi-Fi 和 GPS 設(shè)備捕捉人類行為軌跡[1~2]。為了更好地檢測(cè)軌跡中可能存在的社區(qū),對(duì)檢測(cè)的精確度要求越來(lái)越高。一般地,社區(qū)檢測(cè)通常通過聚類來(lái)實(shí)現(xiàn),軌跡聚類的目的是從一組運(yùn)動(dòng)物體的軌跡中識(shí)別聚類,其中特定聚類中的軌跡在一個(gè)或多個(gè)運(yùn)動(dòng)相關(guān)特征中表現(xiàn)出相似性[3]。軌跡數(shù)據(jù)的示例包括車輛位置數(shù)據(jù),動(dòng)物移動(dòng)數(shù)據(jù)和人類行為跟蹤數(shù)據(jù)。 因此,對(duì)于軌跡數(shù)據(jù)集執(zhí)行數(shù)據(jù)挖掘和行為分析的研究越來(lái)越受歡迎[4]。
現(xiàn)有研究通過將共享位置視為社區(qū)關(guān)系的唯一決定因素,可能錯(cuò)過真實(shí)關(guān)系或者可能錯(cuò)誤地識(shí)別不存在的社區(qū)。在社交圖社區(qū)檢測(cè)文獻(xiàn)[5]中,社區(qū)通常定義在基于鏈接的圖上,捕獲直接的成對(duì)交互;由于隱私問題或技術(shù)限制,這種明確的交互標(biāo)記顯然難以在許多實(shí)際環(huán)境中直接獲得。Zhou等[1]對(duì)物理世界中的三種人類行為軌跡集進(jìn)行分析,提出基于軌跡多源擴(kuò)散模型社區(qū)檢測(cè)(Trajectory-based community detection by diffusion modeling on multiple information sources,TODMIS)算法,通過對(duì)軌跡數(shù)據(jù)集四個(gè)維度(語(yǔ)義、空間、時(shí)間、速度)的建模,將附加信息與原始軌跡數(shù)據(jù)相結(jié)合,并在多個(gè)相似性度量上構(gòu)建擴(kuò)散過程,在耦合的多圖上發(fā)現(xiàn)不同社區(qū)的集合(包括社區(qū)大小),并使用不同的真實(shí)數(shù)據(jù)集進(jìn)行評(píng)估,實(shí)驗(yàn)結(jié)果證明了該方法的有效性。
2 相關(guān)工作
TODMIS[2]使用稠密子圖檢測(cè)方法來(lái)檢測(cè)社區(qū),該方法表示一個(gè)概率聚類的頂點(diǎn)集合,它是標(biāo)準(zhǔn)單形空間中的單位向量,然后引入二次函數(shù)來(lái)測(cè)量它們之間的平均邊緣權(quán)重,并且顯性集被定義為具有最大平均邊緣權(quán)重的子圖,其中圖中頂點(diǎn)表示軌跡,頂點(diǎn)間的權(quán)重代表軌跡間的相似度。目標(biāo)是對(duì)頂點(diǎn)集進(jìn)行迭代,每一次都能處理檢測(cè)到一個(gè)具有最大平均邊緣權(quán)重的子圖,該子圖就是所要獲取的社區(qū)。然后刪除已經(jīng)構(gòu)建子圖的頂點(diǎn),再次優(yōu)化過程,直至頂點(diǎn)集為空。
對(duì)于社區(qū)檢測(cè)的聚類問題,TODMIS 算法只在每次迭代中檢測(cè)現(xiàn)有軌跡集中最大相關(guān)性的軌跡集,并沒有考慮到迭代過程中可能存在的多個(gè)相關(guān)性較大的軌跡集,忽略最大相關(guān)性軌跡集與其他軌跡集的關(guān)系,從而陷入局部最優(yōu)。其次,在每次迭代過程中,一些與社區(qū)相關(guān)性較大的軌跡被當(dāng)作為異常值處理而被忽略,從而降低了社區(qū)檢測(cè)的精確度。因此選擇合適的方法對(duì)提高軌跡集聚類分析和社區(qū)檢測(cè)至關(guān)重要。
為了克服現(xiàn)有技術(shù)的缺點(diǎn)與不足,提高軌跡數(shù)據(jù)集聚類精確度,解決算法魯棒性和全局最優(yōu)等問題,本文提供一種基于稀疏子集聚類分析的社區(qū)檢測(cè)方法,這可以避免陷入局部最優(yōu),在確定軌跡集的情況下,無(wú)需進(jìn)行算法迭代和多次計(jì)算,提高檢測(cè)社區(qū)的效率。
3 基于稀疏子集分析的聚類算法
給定一軌跡集,我們的目標(biāo)是發(fā)現(xiàn)軌跡集中存在具有相似性的軌跡組,定義為表示集或樣例。當(dāng)在空間的度量下進(jìn)行評(píng)估時(shí),某個(gè)社區(qū)的軌跡表現(xiàn)出類似的行為。算法框架如圖1。
首先,對(duì)軌跡數(shù)據(jù)集進(jìn)行預(yù)處理,構(gòu)建軌跡相似度矩陣,由空間關(guān)系特征矩陣定義。通過全局對(duì)齊核(GAK-IP)[6]來(lái)測(cè)量?jī)蓚€(gè)軌跡之間的空間相似度,構(gòu)建軌跡集的空間關(guān)系矩陣。其次,將軌跡相似度矩陣轉(zhuǎn)化成不相似度矩陣,對(duì)不相似度矩陣進(jìn)行稀疏子集選擇(DS3)[7]得到多個(gè)聚類簇;同時(shí)對(duì)每個(gè)聚類簇設(shè)置一個(gè)標(biāo)簽,在軌跡數(shù)據(jù)集上構(gòu)建圖,將標(biāo)簽擴(kuò)散到所有軌跡。

圖1 算法模型框架
3.1 構(gòu)建特征矩陣
用戶的軌跡反映用戶的行為特征,用戶的移動(dòng)路線可以用時(shí)間序列片段來(lái)表示。對(duì)于兩個(gè)用戶的軌跡,定義時(shí)間序列如下:

xa和xb表示第 ɑ 個(gè)用戶和第 b 個(gè)用戶的所有運(yùn)動(dòng)軌跡的時(shí)間序列表,長(zhǎng)度分別為m 和n,xa(1 )表示在第一個(gè)時(shí)間用戶ɑ 所在的經(jīng)緯度。由于每個(gè)用戶在相同時(shí)間內(nèi)的軌跡移動(dòng)長(zhǎng)度不同,所以,當(dāng)m=n時(shí),用戶ɑ和b的軌跡相似性度量可以用歐式距離表示,即

當(dāng)m≠n時(shí),需要采用動(dòng)態(tài)規(guī)劃法對(duì)齊時(shí)間序列,運(yùn)用已有的DTW動(dòng)態(tài)時(shí)間歸整算法構(gòu)造一個(gè)m×n的矩陣網(wǎng)格S,如圖2 所示。矩陣元素d(i,j)表示xa(i)和xb(j)兩個(gè)點(diǎn)的歐式距離,即序列xa的每一個(gè)點(diǎn)和xb的每一個(gè)點(diǎn)之間的相似度,距離越小則相似度越高。在矩陣網(wǎng)格S 中尋找一條通過此網(wǎng)格中若干點(diǎn)的路徑,路徑通過的格點(diǎn)即為兩個(gè)序列進(jìn)行計(jì)算對(duì)齊的點(diǎn)。

圖2 網(wǎng)格S
由于用戶軌跡長(zhǎng)度不同,不能使用歐式距離進(jìn)行匹配,需要在網(wǎng)格S中找到每個(gè)連續(xù)的點(diǎn)構(gòu)成路徑,但是必須保證曲線中從初始點(diǎn)d(1 ,1) 開始到終點(diǎn)d(m,n)結(jié)束,這是就要找出代價(jià)最小的那條路徑,定義為R:
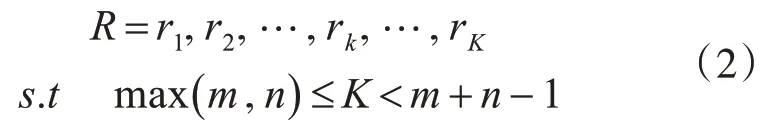
其中R的第k個(gè)元素定義為rk=(i,j)k,定義了序列xa和xb的映射。
路徑不是隨意選擇的,需要滿足兩個(gè)約束條件:1)任何一條軌跡的移動(dòng)速度快慢都可能變化,但是其各部分的先后次序不可能改變,因此多選的路徑必定經(jīng)過d(1 ,1) 和d(m,n)兩點(diǎn),在網(wǎng)格S中從左下角出發(fā),到右上角結(jié)束。2)如果當(dāng)前路徑節(jié)點(diǎn)為Rk-1(i,j),那對(duì)于路徑下一個(gè)節(jié)點(diǎn)Rk(i',j' )必須滿足 0 ≤ (i' -i)≤1 和 0 ≤ (j'-j)≤1,在匹配路徑時(shí),當(dāng)前匹配的節(jié)點(diǎn)k-1的下一個(gè)節(jié)點(diǎn)k必須是k-1節(jié)點(diǎn)的相鄰節(jié)點(diǎn),并且R 中的節(jié)點(diǎn)隨著時(shí)間單調(diào)進(jìn)行匹配,以此保證xa和xb中每個(gè)坐標(biāo)都在R 中出現(xiàn),實(shí)現(xiàn)路徑的完整性。根據(jù)約束條件每個(gè)節(jié)點(diǎn)的路徑只有三個(gè)方向,當(dāng)路徑已經(jīng)通過了節(jié)點(diǎn)(i,j),那么下一個(gè)通過的節(jié)點(diǎn)只可能是(i+ 1,j),(i,j+1)或(i+ 1,j+1) 。所以匹配兩條軌跡代價(jià)最小的路徑:

K主要是用來(lái)對(duì)不同的長(zhǎng)度的匹配路徑做補(bǔ)償。
定義一個(gè)累加距離c,從網(wǎng)格S中(1 ,1) 點(diǎn)開始匹配這兩個(gè)序列xa和xb,每經(jīng)過一個(gè)節(jié)點(diǎn),之前所有的節(jié)點(diǎn)幾點(diǎn)的距離都會(huì)累加,到達(dá)終點(diǎn)(m,n)后,累積之前經(jīng)過節(jié)點(diǎn)的總距離,即為序列xa和xb的相似度。累積距離c(i,j)為當(dāng)前節(jié)點(diǎn)距離d(i,j),即點(diǎn)xa(i)和xb(j)的歐式距離與可以到達(dá)該點(diǎn)的最小鄰近節(jié)點(diǎn)的累積距離之和:
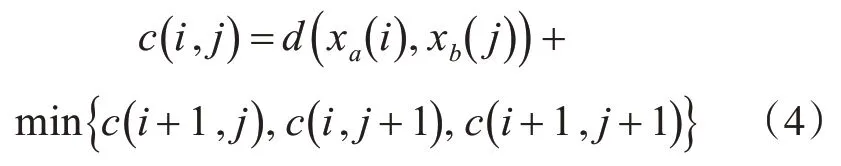
所以xa和xb的相似度cab=c(m,n)。
給定N條軌跡,構(gòu)建N×N相似度矩陣D,

其中d(p,q)表示第p 條軌跡和第q 條軌跡的相似度,即d(p,q)=cpq,d(p,p)=0 表示軌跡 p 與自身最小距離為0。
3.2 稀疏子集分析
從大規(guī)模的數(shù)據(jù)集或模板中找出有信息量、代表性的子集是一個(gè)重要的問題。對(duì)于數(shù)量繁多復(fù)雜的軌跡集,給予一對(duì)原集和目標(biāo)集的元素之間的不相似度,從原集中找到一個(gè)子集,稱為樣例或表示,使得其可以有效地描述目標(biāo)集,運(yùn)用解決行稀疏約束的跡最小化問題的算法[7],對(duì)特定環(huán)境下的軌跡集進(jìn)行行為分析。
給定一個(gè)原集A={a1,a2,...am} 和一個(gè)目標(biāo)集B={b1,b2,...bn} ,分別包含 m 和 n 個(gè)數(shù)據(jù)。構(gòu)建不相似度矩陣矩陣S,兩個(gè)數(shù)據(jù)集之間每一對(duì)元素的不相似度{sij} ,每一個(gè){sij} 表示一個(gè)ai能表示bj的程度,sij的值越小,ai能越好地表示bj。一般地,相似度{dij} 和不相似度{sij} 可以通過sij=-dij來(lái)設(shè)置。
給定不相似度矩陣S,目標(biāo)是選擇一個(gè)原集A使得可以有效的表示目標(biāo)集B,定義稀疏矩陣C:M×N,關(guān)聯(lián)不相似度sij,ci是C的第i 行,且ci∈{0 ,1} ,表示ai是否可以表示bj。如果ai是bj的表示,ci=1。為了確保每一個(gè)bj能被一個(gè)ai表示,必須滿足
選擇一部分A的元素,根據(jù)不相似度,能夠很好地編碼,運(yùn)用基于稀疏矩陣的行稀疏約束的跡最小化問題,實(shí)現(xiàn)兩個(gè)目標(biāo):1)如果ai被用于表示bj,其表示的代價(jià)sijcij∈{0 ,sij} ,則整個(gè)原集A表示bj的代價(jià)是并且用A編碼整個(gè)目標(biāo)集B的代價(jià)是;2)當(dāng)a是目標(biāo)集B i的某一些元素的表示時(shí),有ci≠0,即C的第i行非零,所以希望使用盡可能少的數(shù)據(jù)來(lái)表示,有較少的表示對(duì)應(yīng)著有較少的非零行在C中。結(jié)合以上兩種情況,優(yōu)化問題的目標(biāo)函數(shù)如下:

其中f(·) 表示一個(gè)指示函數(shù),如果其參數(shù)為0,其值為0;否則,值為1。目標(biāo)函數(shù)的第一項(xiàng)對(duì)應(yīng)表示的數(shù)量,第二項(xiàng)表示編碼目標(biāo)集B的總代價(jià)。約束參數(shù)w>0 權(quán)衡兩項(xiàng)的大小,對(duì)于小的w值,優(yōu)化時(shí)更關(guān)注原集A能更好的編碼目標(biāo)集B,能獲得更多的表示的數(shù)量。在極限的情況下w趨近于0時(shí),目標(biāo)集B中的每一個(gè)元素都由其對(duì)應(yīng)的原集A中的距離最近元素表示,即其中另一方面,如果w的值過大,優(yōu)化時(shí)更關(guān)注于矩陣C的行稀疏性,選擇數(shù)量較少的表示,對(duì)于一個(gè)充分大的w,目標(biāo)集B只從原集A中選擇一個(gè)元素來(lái)表達(dá)。考慮到另一種情況,當(dāng)原集A和目標(biāo)集B相同的情況下,即A=B,當(dāng)約束參數(shù)變得足夠小的時(shí)候,每一個(gè)數(shù)據(jù)點(diǎn)都由其自身來(lái)表示,即當(dāng)sjj<sij對(duì)任意的j和i≠j時(shí),cii=1。
3.3 軌跡聚類
目標(biāo)函數(shù)的最優(yōu)解C*不僅表示原集A中的元素被選擇用做表示,也包含了目標(biāo)集B中的元素的表示成員信息表,即

對(duì)應(yīng)著概率向量Bj被原集A中的每一個(gè)元素表示,用優(yōu)化的最終解得到了目標(biāo)集B的聚類。定義集合{A?1,A?2, ...,A?T}代表一個(gè)原集表示目標(biāo)集,可以賦予Bj被Aδj表示,根據(jù)如下公式

可將目標(biāo)集B分開至T個(gè)組,對(duì)應(yīng)T個(gè)表示。
4 實(shí)驗(yàn)結(jié)果分析
4.1 實(shí)驗(yàn)數(shù)據(jù)
在實(shí)驗(yàn)中,選取的數(shù)據(jù)集來(lái)自于微軟T-Drive項(xiàng)目[18~19],T-Drive軌跡數(shù)據(jù)集包含2008年2月2日至 2 月 8 日期間北京內(nèi) 10,357 輛出租車的 GPS 軌跡。該數(shù)據(jù)集包含了1500 萬(wàn)個(gè)坐標(biāo)點(diǎn),軌跡的總距離達(dá)到900多萬(wàn)公里。
為了降低數(shù)據(jù)的復(fù)雜性,本文選取在2008年2月2日至2008年2月8日一周內(nèi)的每天相同時(shí)間片段幾組不同的100 個(gè)出租車司機(jī)移動(dòng)的軌跡,并且原始的數(shù)據(jù)集數(shù)據(jù)表達(dá)是經(jīng)度緯度,為了方便計(jì)算,將經(jīng)緯度映射到二維坐標(biāo)上,橫軸為經(jīng)度,縱軸為緯度。在時(shí)間片段相同的情況下,計(jì)算軌跡之間的相似性更為準(zhǔn)確。
4.2 實(shí)驗(yàn)結(jié)果與分析
由于實(shí)驗(yàn)是在一個(gè)原集上聚類,即目標(biāo)集是當(dāng)前原集,選取約束參數(shù)w兩組不同的值(0.2,0.8)對(duì)100 組軌跡集進(jìn)行稀疏子集分析,比較原集在約束參數(shù)不同的情況下,生成表示或樣例的個(gè)數(shù)。實(shí)驗(yàn)結(jié)果如圖3和圖4所示。
如圖3所示,當(dāng)w=0.2時(shí),100個(gè)軌跡集中有聚類中心T有6 個(gè),分別是{1 2,32,54,66,85,90} ,圖中顏色越深代表此聚簇所包含的信息量越重要,原集中的元素越能很好的表示目標(biāo)集。
如圖4 所示,當(dāng)w=0.8 時(shí),數(shù)據(jù)集中的聚類中心T只有3 個(gè),分別是{9 ,32,71} ,當(dāng)w越大時(shí),原集中可以表示目標(biāo)集的元素越來(lái)越少,可用來(lái)表示的信息量數(shù)量較少。

圖3 約束參數(shù)w=0.2 聚類結(jié)果

圖4 約束參數(shù)w=0.8 聚類結(jié)果
綜上所述,在稀疏子集聚類時(shí),需要找到合適的約束參數(shù)進(jìn)行對(duì)比,從原集中找出能表示重要信息的樣例來(lái)表示目標(biāo)集。本文算法在保持?jǐn)?shù)據(jù)集的完整性的前提下對(duì)軌跡數(shù)據(jù)進(jìn)行了有效的聚類分析,得到原集中有信息量的樣例。
5 結(jié)語(yǔ)
本文針對(duì)現(xiàn)實(shí)環(huán)境下的出租車軌跡進(jìn)行數(shù)分析和聚類,研究相同時(shí)間片段內(nèi)一個(gè)城市中出租車移動(dòng)的軌跡特征,運(yùn)用稀疏子集分析密集復(fù)雜的數(shù)據(jù)集,充分利用原集自身表示的特點(diǎn),降低計(jì)算的復(fù)雜度,提高聚類檢測(cè)的效率。
但是,我們的工作還存在一些需要改進(jìn)的地方,比如考慮多個(gè)維度的特征向量來(lái)更精確地表示數(shù)據(jù)集,將實(shí)驗(yàn)運(yùn)用到不同環(huán)境下的物理軌跡數(shù)據(jù)集,因?yàn)槌鲎廛囆旭傑壽E比較密集和復(fù)雜,路線的規(guī)劃一般由運(yùn)營(yíng)公司規(guī)劃,缺少靈活性,增加原集與目標(biāo)集的對(duì)比和表示,提高稀疏子集分析的正確率。
猜你喜歡
中國(guó)設(shè)備工程(2022年12期)2022-07-11 04:33:00
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年9期)2019-11-25 07:34:36
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年9期)2019-11-25 07:34:34
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年12期)2019-05-21 02:53:50
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年12期)2019-05-21 02:53:48
