基于WSN 的數據挖掘技術在海洋預測中的應用*
2021-02-25 06:28:00翟維
計算機與數字工程 2021年1期
翟 維
(西安航空學院電子工程學院 西安 710077)
1 引言
無線傳感器網絡(WSN)自20世紀90年代末誕生以來,已經發展成為一個能夠收集和處理目標信息,并將處理后的信息傳遞給用戶的協作網絡。多年來,該網絡已應用于環境監測、交通管理、風險監測、野生動物跟蹤、安全監測等多個領域。
特別是WSN 的普及,改變了對水資源的監測。通過WSN 可以靈活地調整監測任務,實現對水資源的實時監測。無線傳感器網絡具有以下優點,尤其適用于監測大型水體的水質。首先,網絡節點可以在監控區域內自動形成網絡;其次,無線傳感器網絡具有廣泛的監控范圍;第三,網絡對環境的影響較小[3~4]。
因此,本文基于無線傳感器網絡和計算機技術,設計了一種能夠有效收集海洋水文數據的在線監測方案。然后,利用支持向量回歸算法處理由傳感器網絡收集的數據。為了獲得算法中最重要的參數,引入粒子群優化算法,通過粒子間的競爭找到全局最優解。之后,根據紐約港的水文情況,建立了海洋水文數據采集與觀測系統。然后,利用傳統的支持向量回歸和所提出的方法,基于水溫、鹽度等指標預測海洋動態。結果表明,該算法提高了無線傳感器網絡的數據利用率,實現了較好的預測精度。
2 海洋水文無線傳感器網絡
2.1 基本概念
海水檢測系統的硬件結構由傳感器節點、網關節點和中央計算機系統組成。無線傳感器節點分布在待檢測的海域中,并且完成數據收集、簡單處理以及與匯聚節點的通信。收集的數據沿傳感器節點逐步傳輸,并在多跳后在匯聚節點處收集。它通過通用分組無線業務(GPRS)網絡傳輸到控制中心,成為專家研究的第一手資料。同時,管理員可以通過GPRS 網絡傳感器網絡節點,實現雙向通信。本文簡要介紹了無線傳感器網絡中的傳感器節點和聚合節點。
傳感器節點處于數據采集的前沿。它負責環境參數的采集,然后將信息傳遞給用戶。其結構如圖1所示。

圖1 傳感器節點系統架構
傳感單元收集待檢測對象的特征信號。通常,每個傳感器單元都包含多個同時工作的傳感器。單片機是傳感器節點的控制核心,負責控制數據采集和傳輸,以及與節點的通信。聚合節點是系統的控制中心,主要由無線通信模塊、單片機、電源模塊、鍵盤和液晶顯示器(LCD)組成。系統結構如圖2所示。
節點通過無線通信模塊控制無線傳感器節點的數據采集。然后,收集的數據通過串行數據總線傳輸到主機上,在主機上提供友好的監控界面。它是海洋水文監測和分析系統的核心部分。

圖2 匯聚節點圖
2.2 海洋水文實時監測分析系統
海洋觀測的最終目的是了解海洋規律的現狀,預測海洋規律的未來,這需要更精確的數據。針對這一需求,我們開發了一個數據質量控制平臺,該平臺在海洋水文觀測實時數據管理系統中發揮著非常重要的作用。提高數據質量是其它工作的基礎,如果數據質量不高,即使有更好的模型和方法,我們的預測也是不準確的。數據質量控制平臺是可擴展的,可以通過添加新的數據質量控制方法來實現。圖3顯示了海洋水文實時數據管理系統。

圖3 海洋水文實時數據管理系統
3 粒子群優化SVM算法
首先介紹粒子群算法的原理和改進。有一個樣本集:T=(xi,yi),1,2,…,n,其中xi為n 維樣本集的第i個輸入值,yi為第i個輸出值。基于粒子群優化SVM 算法的學習過程,它可以解釋為輸入和輸出之間的解f(·) 。對于任意T=(xi,yi) 1,2,…,n,它使得f(xi)=yi成立。一般情況下,f(·)可以表示為

式(1)中,w為權值,b 為閾值。φ的功能是將低維輸入向量映射到高維特征空間。為了提高港口附近水位的預測精度,獲得合適的參數,使結構風險最小化,我們可以構造經驗風險函數,如式(2)所示

其中L稱為損失函數,其表達式為

其中“ε> 0”。當研究樣本較小時,用經驗值代替實際風險值是不合適的,因此粒子群優化SVM算法考慮了稱為SRM 標準的泛化風險,即SRM 準則。然后根據SRM準則,選取非線性回歸函數:

根據粒子群優化SVM 最大區間的原理,將非線性回歸問題轉化為以下函數規劃問題:
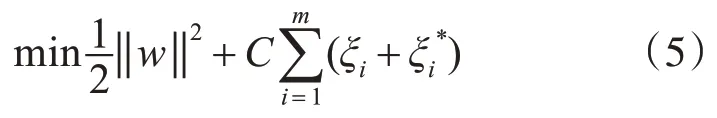
滿足式(6)的約束:

在上面的公式中,參數ξi和為松弛變量,C為容量因子。一般將式(6)轉化為拉格朗日對偶問題求解:

其中αi是拉格朗日乘數,K(·)稱為滿足以下公式的核函數:

本文將高斯核函數作為支持向量機的核函數。那就是:

本文在實踐過程中采用了一種改進的PSO 算法。利用粒子群優化算法,通過粒子間的相互協作和競爭,尋找全局最優解。每個粒子代表一個可能的解向量。對于SVM,可以使粒子的當前位置為參數向量的當前值:

然后,優化過程得到的最優位置就是向量中各元素的最優解,即對應SVM的最優參數。改進PSO的基本原理可以表示為


式(12)中,wmax被認為是初始權重,wmin為最終權重,k為當前迭代次數,kmax是迭代的最大次數。
接下來,我們將介紹SVM 算法中使用PSO 優化懲罰參數和核函數參數的方法和步驟。
4 仿真實驗與結果分析
4.1 相關數據的準備和描述
首先,在紐約港口和河流、河口上游建立了一組無線傳感器(WSN)網絡節點,為港口的海洋水文環境構建了觀測預報系統。該系統結合了定點數據采集、數據擬合和預測模型,實現了利用水文指標預測港口附近水位的目的。
其次,我們在圖4中給出了2018年10月1日當地時間0:00 紅鉤附近紐約港的水位圖。從圖4 可以看出,城市港口外的水位相對較低,而港口的水位相對較高。水位的實時控制有利于提高港口附近的安全水平。
第三,闡述了海洋環境水文指標。海洋環境觀測的實時水文要素數據主要包括海水溫度、鹽度、密度、波浪、水流、海冰、水色、透明度等。

圖4 紅鉤附近紐約港的水位
1)水溫是海洋的基本物理因素之一,海面溫度取決于太陽輻射,因此,低緯度海水溫度高,高緯度海溫低。
2)海水鹽度是海洋中另一個重要的物理因素。除了不同海域的鹽度不一樣外,鹽線性的垂直分布也是不同的。冷海表面的鹽度較低,海水的鹽度隨深度增加而增加。
3)影響海水溫度和鹽度的因素都會影響海水的密度。海水的密度分布復雜,隨地理、海洋深度和時間而變化。海水密度與溫度、海水密度和鹽度之間存在一定的關系。遵循以下原則,鹽度越高,密度越高,溫度越高,密度越低。
綜上所述,選取鹽度、大氣溫度和海面溫度作為樣本數據集,將其放入本文建立的改進SVM 預測模型中。
最后,根據本文建立的WSN,我們收集到2018年10 月1 日至10 月31 日城市港口的海洋水文數據。WSN 每四分鐘收集一次數據集,共包含2,400條數據。然后將數據作為樣本數據集,具體情況如圖5、6、7所示。

圖5 紐約港附近地表水溫度
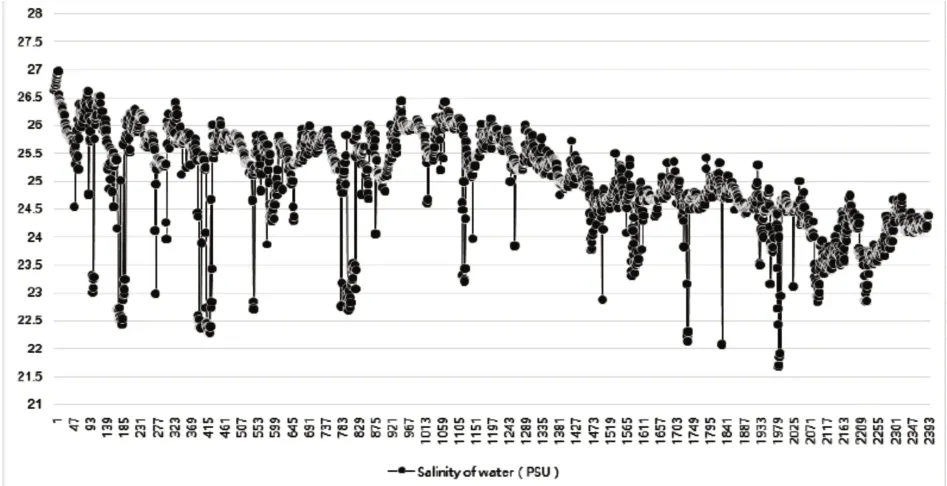
圖6 紐約港附近海水的鹽度
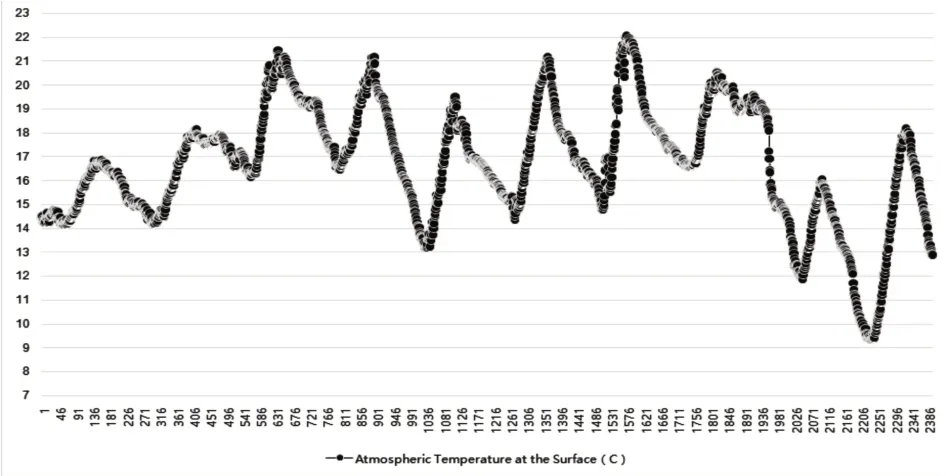
圖7 紐約港附近的大氣表面溫度
4.2 實驗步驟及結果分析
本文以 2018 年 10 月 1 日至 10 月 10 日紐約港的數據為樣本數據集,然后使用支持向量機算法和本文提出的改進的粒子群優化算法預測未來港口附近的水位。接下來,我們將介紹實驗的步驟,并與實驗結果進行了比較,使用改進的PSO優化SVM算法進行分類預測。
參數準備:
初始學習因子c1:初始值為2,用于控制PSO參數的局部搜索能力;
初始學習因子c2:初始值為2,用于控制PSO參數的全局搜索能力;
maxgen:初始值為100,用于控制進化的最大數目;
sizepop:初始值為20,用于控制種群的最大數量;
K:初值為0.6,用于控制速度與x的關系;
nertia weight w:初始值是 1,wmin為 0.8,wmax為1.2,為速度更新公式中的彈性系數;
懲罰參數Cmax:初始值為100,用于控制SVM參數C的最大值;
懲罰參數Cmin:初始值為0.1,用于控制支持向量機參數C的最小值;
Gamma 參數 gmax:初始值為 100,用于控制SVM參數g的最大值;
Gamma 參數 gmin:初始值為 0.01,用于控制SVM參數g的最小值;
兩種方法的實驗結果如圖8所示。
圖8 為兩種不同方法對紐約港紅鉤附近水位的預測結果,以及計算值與實測值的對比結果。從2400 個節點可以看出,該方法的預測誤差最小。此外,它還表明數據的使用有好有壞,不僅與WSN有關,而且與數據挖掘技術密切相關。
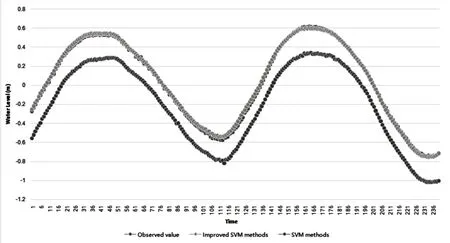
圖8 預測結果對比
5 結語
本文提出了一種利用無線傳感器網絡和計算機技術進行水文數據收集并監測的方案。本文采用支持向量回歸的方法對無線傳感器采集的數據進行處理,利用粒子群算法通過粒子間的合作與競爭來尋找全局最優解。在模擬實驗中,根據紐約港附近的水文情況,構建了紐約港采集觀測系統。采用傳統的支持向量回歸方法和改進的方法進行對比,即利用水溫、鹽度和溫度來預測水位的變化。實驗結果表明,該算法能夠提高無線傳感器網絡的數據利用率,具有良好的預測精度。
