淺談基于神經網絡的新聞評論情感分析
2021-02-27 09:17:24
科學與信息化 2021年1期
中國人民解放軍陸軍工程大學通信工程學院 江蘇 南京 210046
引言
截至2020年3月,我國網絡新聞用戶規模達7.31億,手機網絡新聞用戶規模達7.26億,占手機網民的81.0%。大多數網民在瀏覽新聞的同時,通過發表評論來分享個人的意見看法、情感表達,這些由網民發表的評論通常包含著許多個人情感信息、立場傾向,通過收集這些評論信息加以分析,可以初步了解民眾對特定事項的觀點與看法,從而進一步提煉出輿論走向。
情感分析是指對人們關于某一特定話題的輿論所蘊含的情緒加以分析,而基于新聞評論文本信息的情感分析可以有效地梳理民眾針對新聞報道的輿論走向,用于應對突發事件和異常情況檢測,有助于網絡輿情體系的完善。此外,新聞評論情感分析還廣泛地應用于心理學、金融學、社會學等相關領域。
新聞評論情感分析的相關方法,可歸納為三個步驟:新聞評論語料庫的預處理、新聞評論情感特征的提取和新聞評論情感分類。新聞評論語料的預處理主要包含過濾文本中的停用詞、標注分詞詞性、分析文本語法等;新聞評論情感特征的提取是根據上一步預處理的結果,遵循一定挖掘規則提取出新聞評論中蘊含的情感特征;最終通過機器學習形成分類樹,根據新聞評論的情感特征將其歸類,實現新聞評論文本的自動聚類。
1 新聞評論語料的預處理
新聞評論語料庫的預處理是新聞評論情感極性分析的首要階段,包括分詞、刪除停用詞、詞性標注和句法分析等步驟,將日常人們習慣用語文本數據轉換為計算機可以識別的結構化文本數據。分詞處理是將語料庫中的文本劃分成單個詞語,相比于英文語句中空格可以直接作為切分的依據,中文語句的分詞更為復雜,需要通過將語句與詞典中的詞語相匹配等方法來進行分詞處理,也有利用隱馬爾科夫模型(HMM,Hidden Markov Model,)、條件隨機場(CRF,CanditionalRandom Field)、互信息(MI,Mutual Information)等概率統計模型的分詞方法,也可以引入語義和句法分析的分詞方法[1]。分詞處理之后,需要對每個劃分出來的詞語進行詞性的判斷,比如動名詞、副詞、形容詞、介詞、語氣詞等等,并刪除不包含情感信息的介詞、代詞、停用詞等,最后再根據句子的語法區分新聞評論文本的主謂賓,總結歸納出句法結構,具體預處理過程如圖1所示。
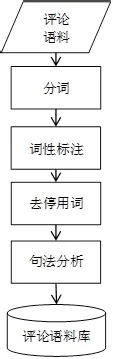
圖1 新聞評論語料庫的預處理
2 新聞評論文本情感特征的提取
用計算機處理文本的情感特征提取,首先需要將原本的文本數據轉化成計算機可識別的機器語言,目前最常用的分類模型為向量空間模型(VSM,Vector Space Model),即將文本特征與相應的特征權重相結合形成有極性的特征向量。
2.1 基于情感詞典的特征的抽取
首先作為比對的依據需要構建情感詞典,根據情感詞典一一判斷上一步中劃分出的詞語所具有的極性,對于詞典中未注冊單詞,可以使用Word2Vec、Doc2Vec等通過語義相似度轉化為同義詞來確定單詞的極性。采用類似方法做過研究的如王曉東等人在文獻[2]中提出的Ontology模型,通過構建情感Ontology將語句中有代表性的情感特征詞語抽離出來,根據該特征詞語的情感極性判斷原文本所具有的情感極性。還有王素格等人在文獻[3]中提出的判別近義詞詞匯情感傾向的方法,這一方法不同的是在建立情感分析詞典時,認為同義詞之間在情感分析上具有同樣的傾向性。從以上的分析不難看出這一情感分析方法的關鍵在于建立完善的情感詞典,但隨著時代、網絡的發展,人們在發表新聞評論時涉及的新鮮詞匯也逐漸豐富,一時間難以窮盡,這給情感詞典的構建帶來了不小的挑戰。
2.2 基于大規模語料的統計特征
當涉及的語料庫數據規模較大時,需要通過數據挖掘的方法抽取一般的語法特征,總結規律,可運用機器學習算法對文本進行處理,實現情感分類。類似的處理方法如文獻[4]通過分析二元語法的情感傾向建立互信息特征模型,而后利用機器學習算法獲得情感分類器,對語料庫中的文本進行情感判斷與分類。
2.3 基于表情符號的特征
現在的網絡用語及快餐文化,經常會包含一些表情符號,用戶在發表評論時也常常會夾雜著表情來表達觀點和情緒,常見的表情符號如圖2所示,這些表情符也可以輔助我們有效地為文本做出情感分類。文獻[5]所提出的情感分析方法是多維的,通過深度學習,在文本的多維特征中引入表情特征,提高了情感分類的效率與準確度。

圖2 常見表情符號
3 基于神經網絡的新聞評論情感分類
機器學習是建立情感詞典的重要算法,而深度學習是其重點研究的領域,其中最常用作情感極性分析的兩種模型工具就是卷積神經網絡(CNN)和遞歸神經網絡(RNN)。
3.1 以卷積神經網絡(CNN)分類模型
卷積神經網絡(CNN)是一類包含卷積計算且具有深度結構的神經網絡,主要由輸入層、卷積層、池化層和輸出層構成如圖4。其中卷積結構有效降低了深層網絡占用的內存量,減少了卷積神經網絡的參數總量,提高了網絡結構的穩定性和泛化能力,緩解模型的過擬合問題。Kim等人在文獻[6]提出了一種模型可運用CNN對新聞評論進行文本分類,將預先訓練好的詞向量矩陣作為卷積神經網絡的輸入層,訓練出神經網絡模型,進而實現數據類別的預測。
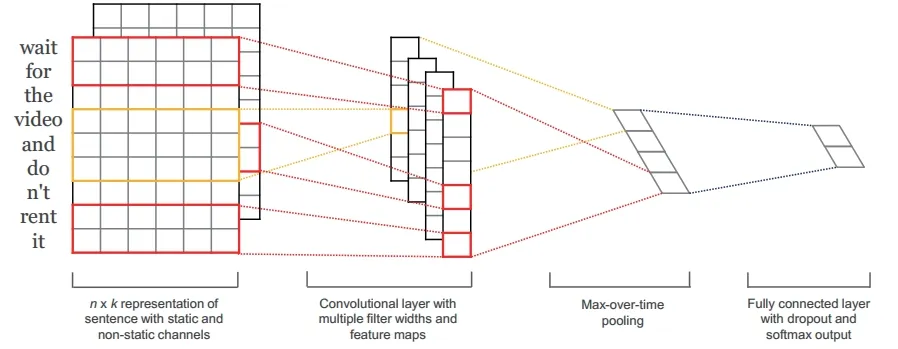
圖3 CNN文本分類模型結構圖
3.2 循環神經網絡(RNN)分類模型
與卷積神經網絡相比,循環神經網絡(RNN)沒有固定大小的卷積核窗口,沒有煩瑣的用來調節卷積核大小的參數,他是一類以序列數據為輸入的遞歸神經網絡,是深度學習領域中所有節點按照鏈式連接的神經網絡,其最大的特點就是循環單元在某一時刻的輸出可以作為輸入再次輸入到循環單元,有效避免了普通神經網絡輸入輸出相互獨立的缺陷,通常用于處理包含時間序列的數據。圖4給出了循環神經網絡的網絡結構,其中ht為輸出層,A為隱藏層,xt為輸入層,前一時刻的網絡狀態可以通過隱藏層上的鏈式連接傳遞給當前時刻,同理,當前時刻的狀態也可以傳遞給下一時刻,保持了數據中的依賴關系。
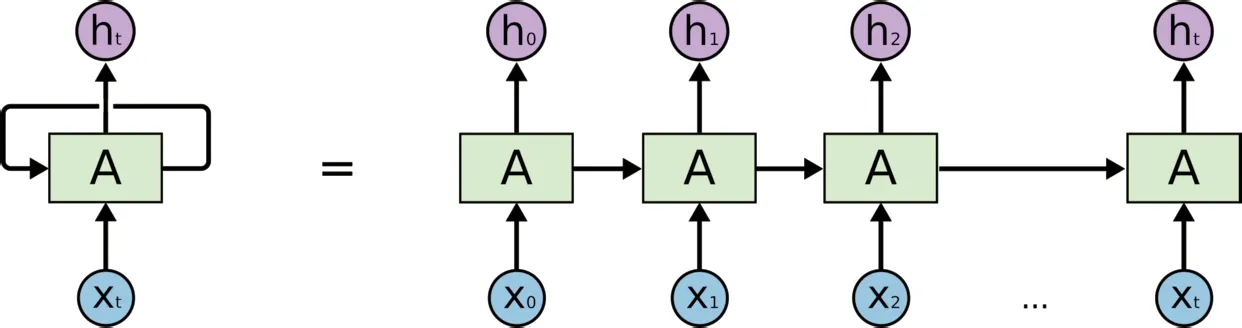
圖4 RNN網絡結構圖
3.3 長短期記憶網絡分類模型
長短期記憶網絡(LongShort-TermMemoryNetwork,LSTM)[7]在1997年由Hochreiter等人提出,在語音識別、語言建模、機器翻譯等多領域都得到了廣泛的應用。它是一種常見的循環神經網絡,其優勢主要體現在處理和預測時間序列中間隔和延遲非常長的重要事件。LSTM含有一個“門”結構用來對決定細胞狀態中輸入的信息是否要被記住或是輸出,由此更新每一層的隱藏狀態,鑒于其可以改進一般RNN模型訓練中可能出現的梯度消失問題,LSTM通常可作為非線性模型用于文本建模、連續手寫識別、自主語音識別等,其結構圖如圖5所示。
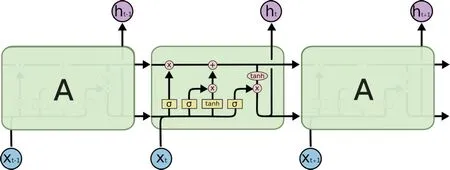
圖5 LSTM結構圖
然而上述提到的幾種神經網絡雖有各自的優勢,但本質上都是將單個句子或文本作為神經單元的輸入,通過形成深度神經網絡,提取相關特征信息并將原數據分類。這使得句與句之間的關聯性信息丟失,上下文之間的局部信息難以體現。針對這一點,文獻[8]提出了LSTM與注意力機制相結合的新型神經網絡LSTM-Attention,該神經網絡主要包含六個部分:文本向量化層、詞語信息特征提取層、詞語Attention層、句子信息特征提取層、句子Attention層、文本分類層,旨在提取學習分層次網格結構的文本信息的基礎上,還可以實現對重要的詞語和句子的特征提取。該神經網絡模型整體框架如圖6所示。
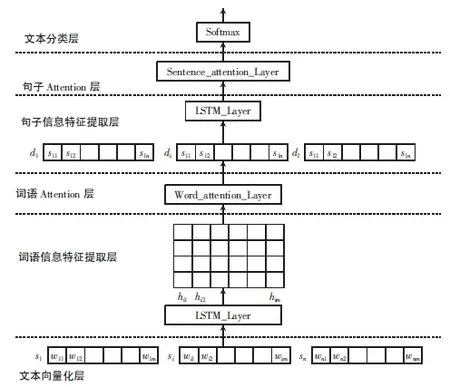
圖6 LSTM Attention神經網絡整體框圖
利用LSTM-Attention對新聞評論進行文本分類,主要經過6層操作。詞語構成句子,句子構成評論文本,這六層的操作可分別作用于詞語和句子層面,通過分別提取相應特征對整個新聞評論進行分析。
綜上所述,卷積神經網絡模型仿造生物的視知覺機制,注重全局感知,忽視了詞句之間的關聯性,而長短期記憶神經網絡可以體現更多的文本間信息的長期依賴性,彌補模型訓練中的不足,在引入注意力機制后,可通過調整權重系數進一步確定對不同文本的關注度,使得預測與分析更加全面,有效提高了輿情走向判斷的準確率。
4 結束語
隨著大數據時代的到來,世界信息的儲備量日益倍增,利用機器學習對海量評論信息的分析處理可以得到很多有意義的信息,關于文本的情感分析也有著重要的科研和實際生活應用。
本文對文本情感分析的常用方法進行了簡要的歸納介紹,其中深度學習領域處于這些方法的核心手段,有進一步深入研究學習的必要性,當前也有許多新興算法結構在被提出,不斷地改進文本情感分析的處理方式以得到更優的結果,這也是我們下一步需要考慮的關鍵所在。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
