CAE-P:基于ADMM剪枝的圖像壓縮自編碼器
2021-02-28 05:40:04趙海萌
中國科技教育 2021年10期
趙海萌
前言
圖像壓縮自編碼器CAE,亦即編碼器E及解碼器D,其訓練過程可以轉化為一個優化問題,即對圖像失真率及圖像編碼比特數的最小化。有損圖像壓縮面臨著失真率及壓縮率的權衡問題,因此可以將上述優化問題表述為:
minE,Dd+βR
其中d表示重構圖像與原圖像之間的差距,R表示圖像編碼比特數,而β>0則控制上述兩個因素之間的平衡。解決這個優化問題的過程中會遇到許多困難,其中最為重要的一個是如何表征圖像編碼比特數R。因此,本項目針對R的優化,提出利用ADMM(AlternatingDirectionMethodofMultipliers)算法對CAE的表示層進行剪枝,即直接減小R,避開了額外訓練信息熵估計器的麻煩,并遵循訓練、剪枝、重訓練的順序,迭代地對CAE進行訓練(優化d)和剪枝(優化R),直至達到目標要求。
本文提出了CAE-P(CompressiveAutoEncoderwithPruning)模型,相較于現有的CAE模型,CAE-P模型顯得更為簡單直接,更易實現且參數量更小。實驗中,CAE-P模型在MS-SSIM(Multi-scaleStructuralSimilarityIndex)、SSIM等指標下均超越了現有的圖像壓縮算法。
CAE-P模型
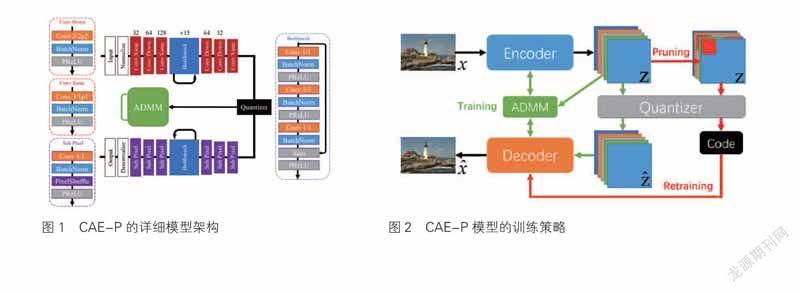
一個基本的圖像壓縮自編碼器CAE由3部分組成:編碼器E、解碼器D和量化器Q。圖1為CAE-P的詳細模型架構,“Convk/spP”表示卷積核大小為k×k、步長為s,并采用大小為P的鏡像Padding的卷積層,“ConvDown”表示將寬和高減半的卷積層。
在對編碼器E、解碼器D、量化器Q進行選擇及構造,并解決優化問題后,我們便得到了基于ADMM剪枝的圖像壓縮自編碼器CAE-P,它的基本結構及運作方式如圖2所示。
原始圖像x經過由卷積殘差塊構成的編碼器E編碼,轉化為一組潛在表示形式z。在ADMM訓練階段,黑色和綠色通路激活,特征圖z經量化器Q量化后得到,輸入同樣由卷積殘差塊構成的解碼器D,解碼器D從中重構出圖像,ADMM算法迭代地最小化重構失真率d(x,),并對z剪枝,迫使其稀疏化。ADMM訓練階段結束后,綠色通路關閉,紅色通路開啟,進入重訓練階段。此時由于ADMM算法并不能保證z中僅剩余小于等于?個非零元素,只能使其他元素接近于零,因此需要對z中的近零元素強制剪除,再經量化器Q量化后,得到最終編碼形式,并將此最終編碼形式輸入解碼器D中,得到重構圖像。為了減小強制剪除對重構圖像的影響,此時的重訓練便只需優化minE,Dd(x,)。遵循訓練、剪枝、重訓練的步驟反復訓練,可以得到同時具有高圖像重構質量及高壓縮率的圖像編碼。這便是本文所提出的CAE-P模型的基本架構及訓練方法。
圖2為CAE-P模型的訓練策略圖。其中,Encoder和Decoder均采用基于CNN的殘差塊構建,Code為最終的壓縮后編碼。ADMM訓練過程中,黑色和綠色通路激活,ADMM算法在最小化重構失真率的同時對z剪枝,迫使其稀疏化。ADMM訓練結束后,黑色和紅色通路激活,對z中的近零元素強制剪除,開始重訓練。
實驗過程
模型架構
CAE-P模型由基于CNN和殘差塊的編碼器、解碼器組成。原始圖像首先經過3次下采樣,每次包含下采樣卷積、批歸一化BN層和PReLU激活函數;接下來經過15層Bottleneck殘差塊,其中每次卷積后均連接BN層和PReLU;最后再經過2層下采樣卷積,得到z。
接下來經過量化器得到,量化器的梯度如下,設置為1。
量化后的編碼進入解碼器,解碼器的架構與編碼器基本鏡像。編碼首先通過2層上卷積Sub-Pix層,每層包含卷積、BN層、PixelShuffle和PReLU激活函數;然后經過15層Bottleneck殘差塊,內部結構與編碼器中的相同;最后再經過2層上卷積Sub-Pix層,最后通過Tanh激活函數,使激活值限制在(-1,1)之間,最后將其線性映射至(0,1)之間。
目標函數d的選擇
目前,常用的d的選擇包括MSE、MS-SSIM等。我們嘗試了多種設計后,最終選擇d(x,)=100·(1-MSSSIM(x,))+100·(1-SSIM(x,))+(45-PSNR(x,))+MSE(x,)。所有模型均以此為目標函數d訓練。
模型訓練
研究采用Adam作為優化器,BatchSize設置為32,對ADMM優化問題的第一步進行優化。初始學習率設置為4·10-3,并隨著訓練過程動態衰減:每出現10個Epoch平均損失函數不下降,學習率減半。WeightDecay設置為一個較小值1·10-10。每經過20個Epoch,執行1次ADMM算法的第2步和第3步,第2步中的保留元素比例設置為10%。對于不同bpp的模型,修改編碼器的最后一層及解碼器的第1層的結構,進行fine-tune。所有代碼在PyTorch框架下實現,每個模型在4塊NVIDIAGeForceGTX1080TiGPU上并行化訓練了300個Epoch,并在GitHub上開源。
數據集及其預處理
實驗選擇BSDS500作為訓練數據集,包含500張481×321的圖片。每次輸入網絡時圖像首先被隨機裁剪出一塊128×128大小的Crop,隨機進行水平和豎直翻轉,最后歸一化至(0,1)。對于測試集,實驗采用圖像壓縮領域內通用的測試數據集KodakPhotoCD2,包含24張768×512的照片。
實驗結論
研究提出了CAE-P模型,避開了額外訓練熵編碼器的繁瑣與優化的不直接,引入ADMM算法對編碼層剪枝,優化更為直接,更易實現且參數量更小。在現有的使用熵編碼器的方法之外開辟并探索了一條新的道路:利用剪枝方法。實驗表明,實驗模型在多項指標下均超越了現有的圖像壓縮算法。
研究意義
本研究致力于改進圖像有損壓縮算法的壓縮率與圖像重構質量,首次將最先進的神經網絡架構搜索技術遷移于其中,實現了超越現有圖像壓縮算法的性能,為圖像更高效地存儲與傳輸提供了基礎。
創新點
本研究提出了CAE-P模型,首次在圖像壓縮領域中引入剪枝方法,在使用熵估計器的方法之外開辟并探索了應用架構搜索方法(剪枝)的可能性,為未來引入更多更精巧的架構搜索方法作了鋪墊。實驗表明,該模型在多項指標下均超越了現有的圖像壓縮算法,尤其是研究改進對象CAE。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
