基于Highway-BiLSTM網絡的漢語謂語中心詞識別研究
2021-02-28 04:46:10黃瑞章靳文繁陳艷平秦永彬鄭慶華
通信學報 2021年1期
黃瑞章,靳文繁,陳艷平,秦永彬,鄭慶華
(1.貴州大學計算機科學與技術學院,貴州 貴陽 550025;2.貴州省公共大數據重點實驗室,貴州 貴陽 550025;3.西安交通大學計算機科學與技術學院,陜西 西安 710049)
1 引言
謂語中心詞是句子的焦點,是支配和關聯句子其他語法成分的關鍵語法單元。在以謂語為中心的句法成分分析中,需要根據謂語中心詞來解析句子結構。識別謂語中心詞是正確理解句子的前提。正確識別謂語中心詞可以解析句子結構、獲取句子的語義信息,進一步支撐淺層句法分析的研究,從而支撐機器翻譯、信息檢索、情感分析等自然語言處理應用。
一個動詞在句子中是否是謂語中心詞既與它本身的語法屬性有關,也與它的上下文環境有關。動詞本身的語法屬性稱為靜態特征,與識別謂語中心詞有關的上下文環境稱為動態特征。由于漢語句子結構松散,傳統觀點認為漢語句子沒有形式上的謂語中心詞。
此外,謂語中心詞的識別還需要克服以下幾個問題。1) 漢語是一種古老的象形文字,缺少分詞信息。比如,《現代漢語規范詞典》沒有收錄“撞向”為動詞,但收錄了“通向”“流向”等詞為動詞。類似的情況有“下雨”被收錄為詞,而“下雪”沒有。無法正確分詞給謂語中心詞的識別帶來困難。2) 漢語句子結構松散。漢語句子通常包含幾個動詞,它們中的每一個都可以作為謂語中心詞或狀語短語來處理,很難識別句子中單詞之間的依賴關系。3) 漢語單詞中的兼義現象非常嚴重,存在很多名詞、形容詞動詞化的用法,但沒有形態特征來表示它們的動詞用法,使區分它們之間的句法作用變得困難。4) 謂語中心詞是句子的中心,識別謂語中心詞需要對句子的高階依賴關系進行建模。當前的序列模型難以捕獲句子中的高階依賴關系。在漢語謂語中心詞識別方面,現有的序列標注模型還存在不足之處。例如長短時記憶(LSTM,long-short term memory)模型理論上能記憶長距離信息,但是在實際使用中,LSTM 對長實體的識別性能較低。
本文主要的研究工作如下。
1) 針對漢語謂語中心詞的特點,提出了一種基于深層雙向長短時記憶(BiLSTM,bi-directional LSTM)的漢語謂語中心詞識別模型。該模型利用4 層BiLSTM 結構獲取句子的抽象語義特征和上下文語義依賴關系。與傳統序列標注模型相比,深層BiLSTM模型能更好地獲取句子內部不同粒度抽象語義信息,在漢語謂語中心詞數據集上有更好的表現。
2) 利用Highway 連接緩解深層模型的梯度消失的問題。隨著深度網絡層數的不斷增加,輸入信息在通過網絡層到達網絡的末端時,可能出現梯度消失的情況。本文通過Highway 網絡的引入有效地緩解了訓練深層模型時梯度消失的情況。
3) 漢語謂語中心詞的唯一性問題。單個句子中通常只有一個謂語中心詞,但可以有多個動詞。為了解決這個問題,本文在模型的輸出中加入約束層,通過約束函數對輸出路徑進行約束,確保謂語中心詞的輸出唯一性。
2 相關工作
謂語中心詞在句中起到組織句法或者語義信息的中心作用,如主語、時間、原因和形式等。識別謂語中心詞是理解句子的關鍵。然而,在漢語自然語言處理領域,關于謂語中心詞識別的研究工作卻很少。現有工作主要采用基于規則的方法、基于統計學習的方法和規則與統計相結合的方法。
在基于規則的方法中,Luo 等[1]從各種詞性的詞作為謂語時的語法特點出發,討論謂語的識別策略,通過規則的方法來判別和確定句子的中心謂語及其相應邊界。Li 等[2]提出了一種利用句子的主語和謂語之間的句法關系來識別謂語中心詞的方法。該方法除了利用謂語中心詞候選項的靜態語法特征和動態語法特征外,還加入了對規則間相互影響的考慮,較之前的方法從更高的句法層次上進行了分析。但是特征的應用過程相對復雜,計算量較大,對于一些特殊的句型可能產生錯誤的結果。Sui 等[3-4]出了一種折中的漢語句子分析方法——骨架依存分析法,利用句子級對齊的雙語語料庫中英漢謂語中心詞的對應來尋找漢語句子的謂語中心詞。但是其僅對例句集中的漢語單句識別了謂語中心詞,沒有從大規模已標注的謂語中心詞的漢語例句中實現謂語中心詞自動抽取。
在基于統計學習的方法中,陳小荷等[5]采用統計的方法對50 萬字的語料庫識別了核心謂語。Wang 等[6]組合謂語動詞的多個特征,并使用最大熵分類器對謂語中心詞進行自動識別。諶志群[7]提出了一種基于統計學原理的漢語句子謂語自動識別概率模型,通過對語料庫中句子的謂語所處上下文環境的細致分析,選擇影響謂語出現的語境特征,在此基礎上通過構建統計模型來計算謂語出現的概率,識別漢語句子的謂語。
在規則與統計學習相結合的方法中,Gong 等[8]將整個謂語識別的過程分為語片捆綁、謂語粗篩選和謂語精篩選3 個階段。首先,在識別之前加入語片捆綁的預處理工作,有效排除了一些準謂語;然后,用規則的方法進行粗篩選,降低了精篩選的復雜度;最后,利用特征學習的方法進行謂語精篩選,有效解決了規則的不完備和特征重要度排序的問題。但是,該方法還存在一些謂語誤識的情況,對于復雜結構的漢語句子不能完全正確識別。另外,Han 等[9]提出一種融合詞法與句法特征、結合C4.5機器學習和規則進行謂語識別的方法。該方法表明句法特征能有效提升謂語識別效果。李琳等[10]利用大規模的藏語語料庫訓練得到藏語詞向量,其結果表明詞向量特征可顯著提高藏語謂語動詞短語的識別效果。目前,謂語中心詞識別的研究大部分還是使用傳統方法,難以建模高階依賴信息。
在漢語信息抽取領域,與謂語中心詞識別相關的任務還有命名實體識別和語義角色標注。其中,命名實體識別通常采用序列標注模型進行識別,如隱馬爾可夫模型(HMM,hidden Markov model)[11]、條件隨機場(CRF,conditional random field)[12]和LSTM[13]。近年來,基于深度學習模型的實體識別得到了廣泛研究。比如,Li 等[14]采用雙向LSTM-CRF 結構,在生物醫學實體識別上取得了良好的效果。與命名實體識別相比,謂語中心詞識別更強調謂語中心詞作為句子中心的語法功能,在識別上需要依賴句子的整體結構和語義特征,在輸出路徑中需要保證標注實體的單一性。
語義角色標注(SRL,semantic role labeling)[15]是淺層語義分析中的一種主要實現方式。該方法主要是對給定句子中存在的每個謂語進行分析,并標注其相應的語義成分。傳統的SRL 方法采用基于句法特征的統計機器學習方法,通常將語義角色標注任務轉換為有監督的分類問題,主要分為基于短語結構句法分析以及基于依存句法分析2 種語義角色標注方法。比如,Koomen 等[16]和Tackstrom 等[17]采用線性規劃或動態規劃的方式獲得句子的全局約束。隨著深度學習的興起,研究者將基于BiLSTM模型用于語義角色標注任務。比如,Zhou 等[18]使用深度BiLSTM 模型對英文語義角色標注進行了研究。Guo 等[19]重點關注句法路徑信息并使用BiLSTM 對其進行建模,從而提高了SRL 系統的性能。王瑞波等[20]使用多特征融合的神經網絡結構來構建漢語框架語義角色識別模型。Strubell 等[21]提出了一種基于語言信息的自我注意神經網絡模型,它將多頭自我注意與多任務學習相結合,包括依賴分析、詞性標注、謂語檢測和SRL。
3 模型構建
本文的Highway-BiLSTM 網絡結構如圖1 所示。自底向上描述如下。1)使用預訓練的維基百科字向量將輸入的文本序列映射為向量,作為當前詞的特征向量表示;2)經過4 層BiLSTM[22]獲取句子內部不同粒度抽象語義信息的直接依賴關系;3)為了防止訓練深層BiLSTM 模型時出現梯度消失的問題,層與層之間使用Highway 網絡連接;4)通過一個Softmax 層進行歸一化處理;5)通過約束層保證謂語中心詞的唯一性,得到最優標注序列。句子中包含的謂語中心詞用標簽{B,I}表示,其中謂語中心詞的開始用標簽B標記,其余部分用標簽I標記。在模型的輸出部分,使用P表示預測的句子,模型預測出的謂語中心詞使用標簽B-V標記,句子中的其他成分使用標簽O標記。

圖1 Highway-BiLSTM 網絡結構
3.1 深度雙向長短時記憶模型
一方面,傳統的循環神經網絡(RNN,recurrent neural network)在處理長序列數據時容易出現梯度消失或梯度爆炸問題。另一方面,對于基本的RNN來說,它能夠處理一定的短期依賴,但是無法處理長期依賴問題。而LSTM 通過引入門結構解決了RNN 的長期依賴問題。由于漢語謂語中心詞缺少形態特征、句子結構松散且形式多樣、單個句子可能存在多個動詞等情況,傳統的序列標注模型無法很好地建模句子的高階依賴特征,獲取句子的全局信息。針對上述問題,本文提出利用多層堆疊的BiLSTM構建謂語中心詞識別模型。LSTM 通過3 個不同的門來調節單元狀態中的信息流,即輸入門、遺忘門、輸出門控制著信息流的更新與利用。本文設輸入的信息流為xl,t,表示第l層和t時刻到LSTM 的輸入;細胞狀態為cl,t;LSTM 在t時刻的輸出信息為hl,t;激活函數為σ;權重矩陣為W;偏置向量為b。
首先,決定從細胞狀態中丟棄什么信息。這個決策是通過一個稱為“遺忘門”的層來完成的。該門會讀取hl,t和xl,t,使用sigmoid 函數輸出一個0~1的數值,輸出狀態cl,t中每個細胞的數值,1 表示完全保留,0 表示完全舍棄。

然后,確定什么樣的新信息被存放在細胞狀態中。信息包含兩部分:一部分是sigmoid 函數,稱為“輸入門”,決定更新什么值;另一部分是tanh 函數,用于創建一個新的候選值向量,該向量會被加入狀態中。這樣就能用這2 個信息產生對狀態的更新。

最后,運行一個sigmoid 函數來確定輸出細胞狀態的哪個部分,通過tanh 處理細胞狀態,并與sigmoid 門的輸出相乘,僅輸出確定輸出的那部分。

其中,δ l為1 或?1,表示LSTM 在第l層的方向性。在實驗中根據Zhou 等[23]的方法以交織模式堆疊LSTM,設每層的特定輸入xl,t和方向性δl分別為

3.2 Highway 連接
本文在實驗中使用了4 層的BiLSTM(即8 層LSTM)堆疊模型取得了較好的效果,其中一個關鍵要素是使用封閉的“Highway 連接”[23-24]。相比于RNN,LSTM 能夠在一定程度上緩解梯度消失的問題。理論和經驗表明,神經網絡的深度是其成功的關鍵。然而,隨著網絡層數的不斷增加,訓練變得更加困難,在網絡傳輸中會出現一個問題:當輸入的信息通過許多層,到達網絡的末端(或起點)時,信息可能會“消失”。這里的“消失”實際是由于鏈式法則下多個小于1 的數值相乘導致的。針對這個問題,本文使用Highway 連接各層BiLSTM,使特征信息能夠在多個層面上傳輸。Highway 網絡受到LSTM 網絡的啟發,同樣使用自適應門控單元來調節信息流。典型的神經網絡是一個仿射變換加一個非線性函數,即y=H(x,WH)。在深層模型的層間連接中,為每一個層的輸出添加轉換門和進位門,形成Highway 網絡。其定義為
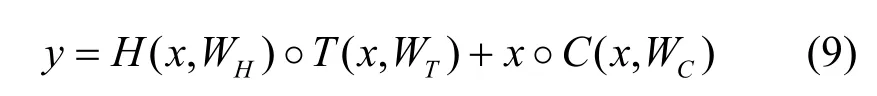
Highway 網絡的本質是通過shortcut 機制實現深層網絡的訓練。如圖2 所示,shortcut 機制選擇合適的層進行轉換,通過該機制可以使信息在許多層之間流動而不會衰減,即使在深層模型中,使用Highway 連接也可以通過簡單的梯度下降直接進行訓練。本文實驗通過轉換門rt來控制層與層之間線性和非線性變換的權重。
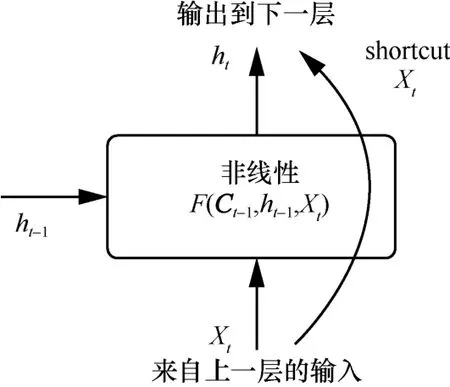
圖2 Highway 連接
最后,輸出hl,t改為
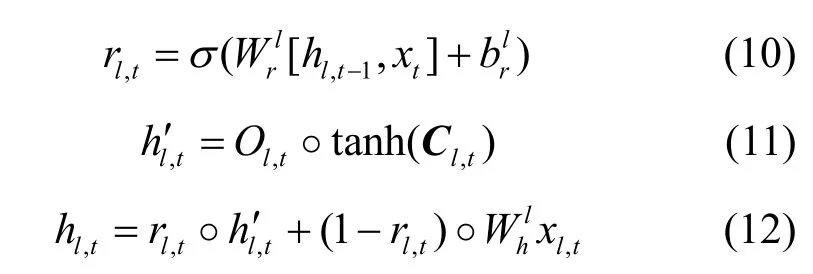
3.3 Dropout 機制
在訓練樣本一定的情況下,模型的復雜性越高,就會有越多的參數,訓練出的模型越容易產生過擬合的現象。為了避免過擬合,在本文的模型中使用Gal 等[25]所描述的Dropout 機制,通過Dropout提高了模型的泛化能力。定義為
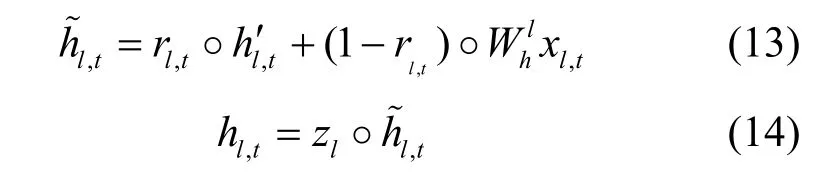
其中,zl在l層上跨時間步共享,以免沿序列放大噪聲。
3.4 謂語中心詞的唯一性
通常,識別任務是給定一個句子作為輸入預測一個序列y,每個yi∈y都屬于一個離散的標簽集合T。句子中包含的謂語中心詞用標簽{B,I}表示,其中謂語中心詞的開始用標簽B標記,其余部分用標簽I標記。為了避免在單個句子中謂語中心詞數量大于一個的現象,本文在模型全連接層之后使用Softmax 層進行歸一化處理,并通過約束層對謂語中心詞的輸出路徑進行約束。對于每一個句子,預測它的謂語中心詞結構,在所有可能的解空間Y中找到得分最高的標簽序列。其約束函數定義為

其中,y∈Y,得分函數f(y)的輸入條件為。為了加入額外的信息,比如,結構一致性、語法輸入等,在實驗中利用懲罰項來增加得分函數,即

其中,給定輸入w和長度t的前綴y1:t,每個函數c都應用非負懲罰。
4 實驗
4.1 數據集
本文的實驗使用漢語謂語中心詞數據集。該數據來源于“中國裁判文書網”中的762 篇法院刑事判決書。與李婷等[26]的標注規范相同,在標注規范中,把謂語中心詞分為以下幾種模式。
模式1單個謂語中心詞
由于漢語單詞之間沒有分隔符,在詞的劃分上存在歧義,因此本文的單個謂語中心詞,以詞典的收錄為準。例如,“取得”在字典中被收錄為詞,“取出”卻沒有。那么只有“取得”屬于模式1,標注為單個謂語中心詞。
模式2復合結構的謂語中心詞
漢語句子結構中經常使用重復的表達式來構成復合結構的詞,如“跑一跑”“洗洗手”等。
模式3同義并列的謂語中心詞
同義動詞通常同時使用來作為謂語中心詞,如“驅車/行駛”“開發/建設”“抓捕/歸案”等。此外,連續的動詞表達相反的語義,但屬于偏正關系的,如“進進出出”也被標記為一個謂語中心詞。
模式4帶修飾或帶補語的謂語中心詞
當句子中的動詞帶有時態標記、補語或修飾符時,將謂語中心詞標注在括號中,如“王某取出一把尖刀”,標記為“王某[(取)出]一把尖刀”。
模式5其他特殊表達的謂語中心詞
當句子中存在名詞做動詞、形容詞做動詞,以及諺語和成語或典故等時,如“張某[心生不滿]”,成語“心生不滿”如果切分,則會引起歧義,所以單獨標為謂語中心詞。該模式還可以用于處理主語?謂語從句,其形式為名詞(代詞)+動詞(形容詞)。例如,“我[開心]”等。
通過上述5 種標注模式,本文共標注7 022 條句子,標記7 022 個謂語中心詞,其中,模式1 有4 959 個,模式2 有24 個,模式3 有272 個,模式4 有1 651 個,模式5 有116 個。
4.2 實驗參數設置
本文的模型由8 個LSTM 層(4 個正向LSTM層和4 個反向LSTM 層)和一個用于預測輸出分布的Softmax 層組成,層與層之間使用Highway 連接。根據文獻[27],本文模型中所有權重矩陣都用隨機標準正交矩陣初始化。模型參數設置如表1 所示。
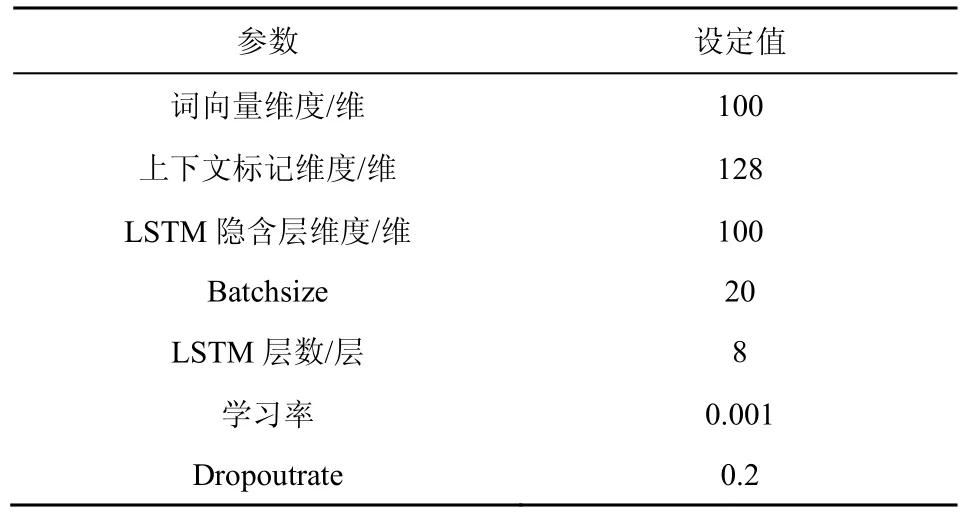
表1 參數設置
在實驗訓練階段使用了預訓練的漢語維基百科字向量字嵌入初始化,每個字經過預訓練后的維度都是100 維,并且在訓練期間進行更新。維基百科未覆蓋的字將替換為隨機初始化的
從表 2 的實驗結果可以看出,Highway+BiLSTM+Softmax 模型取得了最好的效果。第一組實驗使用的是傳統的序列標注模型CRF。CRF 通過特征模板掃描整個句子,它更多考慮的是整個句子局部特征的線性加權組合。CRF 計算的是一種聯合概率,優化的是整個序列,而不是將每個時刻的最優結果拼接起來。第二組實驗加入了BiLSTM,BiLSTM 的優勢是可以同時捕捉正反2 個方向的長距離信息,建模上下文的依賴關系。通過實驗對比可以看到,BiLSTM 在CRF 的基礎上有了較大的提升。但是BiLSTM 只能學習到某個特定維度的特征。第三組實驗是李婷等[26]最近的工作,在第二組實驗的基礎上加入了Attention 機制,Attention 機制可以獲取全局與局部的聯系,不會像RNN 模型那樣對長期依賴的捕捉受到序列長度的影響。在謂語中心詞約束部分,文獻[26]使用卷積神經網絡對序列標注結果進行二分類,得到最終的識別結果。第三組實驗使用了多層BiLSTM 疊加獲取句子的全局信息,其中層與層之間使用殘差模塊連接[29],性能較第二組實驗有近3%的提升。第四組實驗中在使用多層BiLSTM 模型堆疊的同時,利用Highway 連接來緩解梯度消失的問題。通過實驗結果可以看出,Highway 連接比殘差模塊有1%的性能提升。與文獻[26]所做的工作相比,本文的模型是端到端的,不需要分步實驗就能得到最終的序列標注結果。
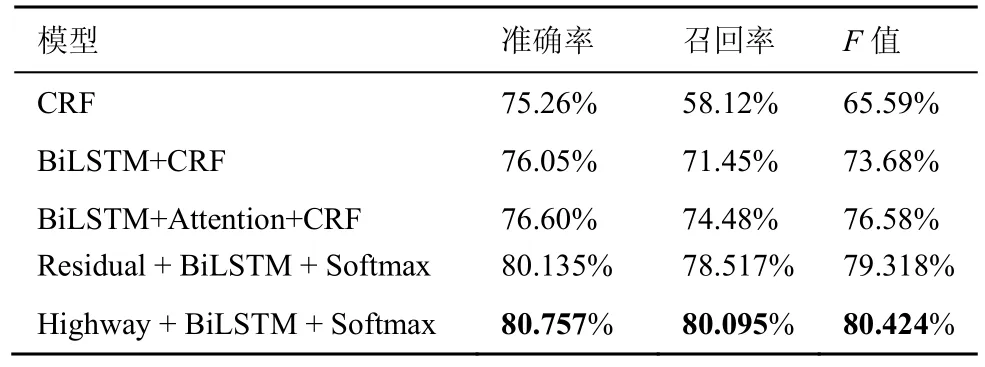
表2 實驗結果
4.3 實驗結果分析
4.3.1 句子長度對預測結果的影響
本文在實驗中比較了不同的句子長度對實驗結果的影響,如表3 所示。隨著句子長度的增加,準確率、召回率、F值均呈下降趨勢。這也充分說明了模型在長距離語義依賴中的表現略差,長距離語義建模成為限制模型性能的一大因素。
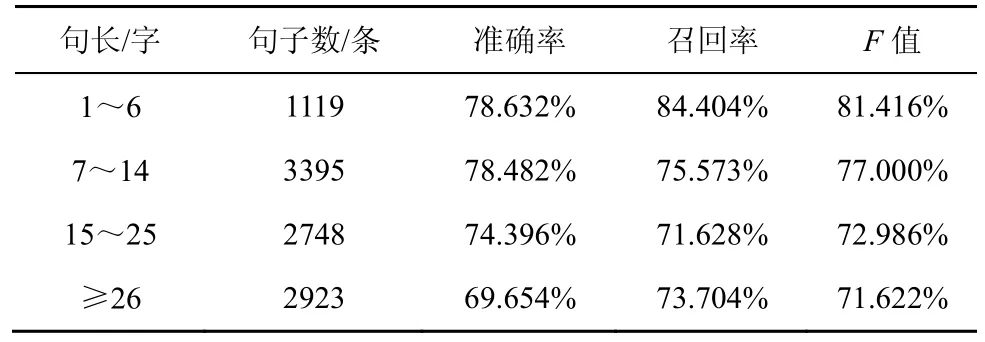
表3 不同句長下的實驗結果
4.3.2 詞向量分析
本文使用漢語維基百科語料為預訓練詞向量,得到約38 萬個字的字向量,可以覆蓋99%的訓練集和驗證集。在查找表中不能找到的詞被映射為

表4 不同詞向量的實驗結果
如圖3 所示,采用不同的詞向量后F值隨著迭代次數的增加而上升,在每一輪迭代中采用預訓練的詞向量的模型效果都優于隨機初始化的模型。預訓練的詞向量能夠更好地表達每個字的特征表示。

圖3 不同詞向量對F值的影響
4.3.3 層間連接分析
本節實驗選取Wiki-100 initialized 詞向量的模型進行實驗,對比了無連接、殘差連接與Highway連接的表現,如表5 所示。
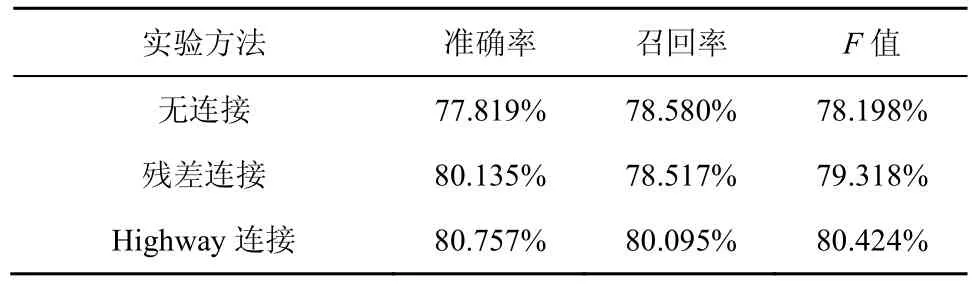
表5 有無Highway 連接的實驗結果
Highway 連接與殘差連接具有一個相同的特性,即過shortcut 機制來實現深度網絡的訓練。從表5 可以看出,Highway 連接有更好的表現,其原因是Highway連接比殘差連接對跳轉連接有更多的控制,Highway 連接啟發于LSTM 的門控機制,它的轉換門和進位門門控結構允許信息在跳轉層和使用之間有一個學習的平衡。通過實驗結果可以看出,Highway 連接比殘差連接有1%的性能提升。
通過Highway連接可以緩解訓練深層模型時梯度消失的情況,同時說明Highway 連接在本文模型中是有效的。為了進一步說明Highway 連接對深層模型的重要性,本文在實驗中改變了層與層之間的連接方式,使用殘差連接代替Highway 連接。如圖4所示,當迭代次數不斷增加時,使用殘差連接的模型準確率會先上升然后達到飽和,迭代次數繼續增加準確率會下降,而使用Highway 連接的模型準確率隨著迭代次數的增加而不斷上升,最終在100 次迭代后達到飽和。

圖4 不同層連接方式對F值的影響
4.3.4 比較層數對模型性能的影響
本節選取了Wiki-100 詞向量的模型進行實驗,探究模型層數對模型性能的影響。在使用4 層的BiLSTM 疊加后實驗效果達到最佳。如表6所示,4 層模型比2 層模型提升了近1.3%的F值。從實驗結果可以看出,深層神經網絡的特征提取能力更強,在序列標注任務上優于淺層神經網絡。

表6 不同層數在驗證集上的實驗結果
如圖5 所示,不同層數的模型訓練時的損失值下降速率也不同。從圖5 可以看出,設置模型層數為4 層時收斂速度達到最快。

圖5 不同層數對訓練集損失的影響
5 結束語
本文針對漢語謂語中心詞進行識別研究,使用深層神經網絡模型對句子進行建模,在漢語謂語中心詞數據集上進行實驗,F值達到80.424%,并且通過輸出路徑的約束解決了中心詞的唯一性問題。在未來的研究中,需要利用更深層的神經網絡模型來獲取句子的結構信息,以進一步提升識別性能。此外,下一階段工作將研究模型與輸出路徑間的高階依賴問題,通過在神經網絡模型中加入全局約束條件以及構建知識庫規則,使模型在訓練過程中能夠自動學習句子的結構特點,以支撐與謂語中心詞相關的研究工作。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
現代語文(2016年21期)2016-05-25 13:13:44
