基于多傳感融合的有軌電車在途障礙物檢測方法研究
2021-02-28 09:34:46楊崢嶺
現代城市軌道交通 2021年2期
張 勇,王 磊,楊崢嶺,徐 夢
(1.通號萬全信號設備有限公司自動化研究院,北京 310008;2.通號萬全信號設備有限公司項目中心,北京 310008)
1 研究背景
有軌電車一般采用混合路權的形式,在一定程度上增加了安全事故發生的風險。有軌電車的安全保障除依賴于信號系統、軋道車軌道巡檢外,還依靠行車司機的在途確認,當交通發生擁堵、車流較大、天氣惡劣、突發狀況或司機疲勞時,極易產生安全事故或疏漏。因此,在加強司機安全意識、規范司機行車的同時,更需要可靠的、智能的技術手段輔助司機駕駛,為行車安全提供保障。
在途列車障礙物檢測技術是目前列車安全駕駛的輔助技術手段之一,其功能在于檢測列車軌行區域內是否存在行人、社會車輛、異物等,并在危險時對司機發出警示,以減少列車發生碰撞造成安全事故的風險。其實現依賴于視覺傳感器、激光雷達、毫米波雷達、紅外傳感器等檢測元器件以及相應的檢測算法,如深度學習、支持向量機(SVM)分類器、卡爾曼濾波算法等。一般情況下,使用多傳感融合的方式,即采用2種或多種技術手段共同對軌行區進行檢測,可達到優勢互補、提升識別效率的目的。
2 在途障礙物檢測方法發展現狀
在眾多常見的障礙物檢測手段中,基于深度學習的視覺傳感器檢測、識別方法使用日趨廣泛。其中,基于單定點多邊框檢測器(SSD)算法的卷積神經網絡模型通過使用自適應感受野特征回歸的方式,實現了準確度與速率的平衡優化;該優化使得SSD卷積神經網絡模型可以更好地完成有軌電車在途障礙物檢測工作,在準確提取障礙物特征的同時,做到實時更新在途信息,為司機行車做出有效輔助。
激光雷達在軌道交通行業亦有較為廣泛的應用。視覺傳感器受天氣、光線條件影響較大,而激光雷達可以克服這些因素對檢測結果的影響。在正常情況下,視覺傳感器結合神經網絡算法的檢測能力強于激光雷達的檢測識別能力,故而激光雷達和視覺傳感器形成了非常有效的互補。
因此,為發揮視覺傳感器及激光雷達檢測的自身優勢,達到更為優異的檢測效果,本文旨在以SSD卷積神經網絡為基礎,結合視覺傳感器以及激光雷達的技術特點,提出一種基于多傳感融合的有軌電車在途障礙物檢測方法。
3 在途障礙物檢測方法
3.1 SSD卷積神經網絡介紹
SSD保留了傳統卷積神經網絡框架,同時以候選框機制為基礎對其識別方式進行優化。在目標檢測、識別過程中,該網絡依據默認配置,在識別圖片上生成多個不同大小的識別框,通過采樣對每個識別框需要的偏移量以及置信度進行計算,以確認目標的種類及位置。SSD官方給出的檢測速率為59 F/s,平均全類別識別準確率(mAP)為74.3%,是一種兼顧識別速率和準確率的卷積神經網絡。其原始網絡結構如圖1所示。
3.2 激光雷達檢測障礙物原理
激光雷達內部包含一組掃描線(激光器),其線數一般為16線、32線或更多。掃描線在激光雷達內部按照垂直方向均勻分布。同時,激光雷達內配有一臺橫向旋轉電機,帶動激光器360°水平旋轉,向周邊射出激光束進行掃描,并根據反射回的激光束相位、時間等信息構建周圍環境的點云圖,同時保存相關距離和位置信息。
在有軌電車行進過程中,一般采用直角坐標系評價車輛與障礙物之間的關系,而激光雷達得到的點云信息實質上是激光束的水平、垂直旋轉角信息,以及在該方向上的距離信息,即球坐標系。通過對比實際點位在2種坐標系下的位置信息關系,對激光雷達采集的數據進行校定,從而得到有軌電車障礙物的位置信息。
3.3 傳感融合
激光雷達的點云數據轉換為列車所用的直角坐標后,通過對其掃描范圍進行標定的方式使其與視覺傳感器采集回的信息做“一一對應”。此時,視覺傳感器采集到的環境信息不僅包含物體的顏色、輪廓信息,還包含相應的距離信息。同時,激光雷達自有的障礙物檢測功能,還可以為基于視覺傳感器的檢測方法提供一定的輔助,尤其是在可見度嚴重不足時,該功能便顯得尤為重要。當獲得一組包含視覺傳感器及激光雷達檢測信息的數據時,分別使用SSD卷積神經網絡檢測算法和激光雷達檢測算法對其進行障礙物檢測,若僅是單一方法檢測到障礙物,則僅對司機做出提示;若是2種方法同時檢測到障礙物,且距離小于有軌電車的安全制動距離(一般選定為50 m),則發出報警提示司機注意。其具體流程如圖2所示。
另外,視覺傳感器和激光雷達的采集速率存在較大差異,為防止信息不同步的現象產生,需要對2種傳感器采集到的數據做融合處理,但由于視覺傳感器的采集周期大于激光雷達,因此對激光雷達的采集信息進行緩存,并通過隊列的方式與視覺傳感器采集到的圖片信息共同保存。具體步驟如下:
(1)開辟2片緩存區域,即緩存a和緩存b;
(2)激光雷達實時采集周圍環境信息,保存在緩存 a中,并覆蓋原有數據信息;
(3)視覺傳感器在采集到1幀圖片后,從緩存a中讀取數據,打上時間戳后共同保存至緩存b;

圖1 SSD原始網絡結構

圖2 視覺傳感器及激光雷達融合后的障礙物報警提示流程
(4)不斷檢查緩存b,若緩存b為空,則不進行任何操作;若緩存b不為空,則清空該片緩存,并依據圖 2所示的步驟對其進行檢測。
該方法可以保證緩存b中永遠保存當前時刻采集到的最新數據,以確保數據的同步性和實時性。同時,由于檢測流程所需時間小于視覺傳感器采集1幀圖片的時間,故而在流程完成后,若沒有新的數據采入則不做任何操作,以節約資源。
4 實驗驗證
4.1 數據集準備
在測試過程中,使用10 000幀采集自甘肅天水有軌電車現場的車輛運行視頻作為訓練集,其中包含社會車輛和信號機樣本圖片各5 000張,并使用SSD卷積神經網絡對其進行學習。訓練過程中設置單次抓取樣本個數(batch_size)為24個,特征圖尺度范圍(anchor_size_bounds)為[0.15,0.90],為防止過擬合迭代,將次數設置為20 000次。同時,收集1 000組視頻樣本圖片及其對應點云圖作為測試集,以驗證該方法的檢測效果。
4.2 實驗結果
將采用單一視覺傳感器配合SSD卷積神經網絡的障礙物檢測方法(簡稱為“SSD”)與多傳感融合后的障礙物檢測方法(簡稱為“R+SSD”)做對比測試,測試結果如表1所示。
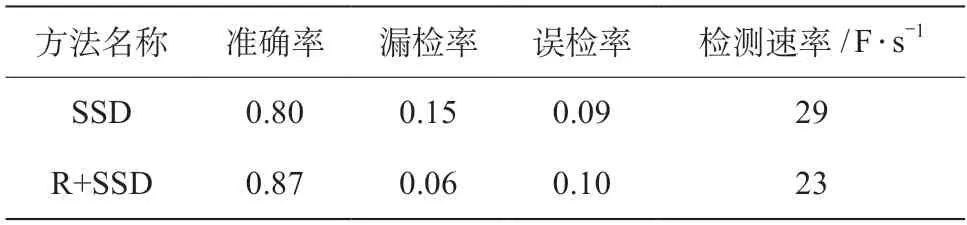
表1 SSD與R+SSD識別準確率對照
R+SSD識別效果如圖3所示。
由表1和圖3可得,SSD方法整體識別率約80%,除網絡本身識別能力因素外,還與現場視覺傳感器采集到的樣本清晰度有關,若樣本圖像清晰度不夠,在一定程度上制約了算法的識別能力,尤其是當目標較遠、特征較小時尤為明顯。R+SSD方法在誤檢率上雖然沒有明顯提升,但漏檢率遠低于SSD方法,主要是由于激光雷達本身并不具備目標識別能力,但對于軌行區域的障礙物,尤其是對中遠距離障礙物有著很好的檢測效果。因此,當視覺檢測手段發生漏檢時,激光雷達檢測手段提供了一定的補足,提升了整體識別準確率。

圖3 多傳感融合后的障礙物識別效果
另外,激光雷達采集速率約為15 F/s,視覺傳感器采集速率約為10~20 F/s,而R+SSD方法的檢測速率約為23 F/s,大于2種傳感器的采集速率,故而認為其可以做到對采集數據的實時檢測。同時,在R+SSD檢測方法中,視覺檢測方法與激光雷達檢測方法之間的融合率即二者同時檢測到某一障礙物的概率為69%,考慮到視頻清晰度不足、視覺檢測方法目前可識別目標種類不多等因素,其看作一個可接受的融合率。后期,可通過優化激光雷達檢測算法、提升視頻清晰度、增加學習樣本目標類別等方式予以提升。
5 結語
本文以SSD卷積神經網絡為基礎,通過多傳感融合的方式,將視覺傳感器障礙物檢測與激光雷達檢測相結合,提出了一種在途列車障礙物檢測方法,并對其檢測效果進行了驗證。實驗表明,該方法對于有軌電車在途障礙物檢測有較強的適用性。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
中華手工(2017年2期)2017-06-06 23:00:31
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中外會展(2014年4期)2014-11-27 07:46:46
