面向DRAM和NVM異構混合內存架構的排序連接算法優化*
2021-03-01 03:33:34金培權
計算機工程與科學 2021年2期
關鍵詞:排序
楊 柳,金培權
(中國科學技術大學計算機科學與技術學院,安徽 合肥 230027)
1 引言
在傳統的存儲體系結構中,存儲系統借助易失性內存DRAM提供高性能的數據訪問,利用性能較差但價格低廉的固態硬盤SSD(Solid State Disk)或者硬盤HDD(Hard Disk Drive)保證數據的持久性。相變存儲器PCM(Phase Change Memory)、自旋矩傳輸磁性存儲器STT-RAM(Spin Transfer Torque RAM)和可變電阻式存儲器RRAM(Resistive RAM)等非易失內存NVM(Non-Volatile Memory)引入到計算機系統后,對現有的存儲體系結構帶來了極大的影響[1-3]。與SSD相比,NVM支持按位尋址,讀寫延遲低,而且可以直接被CPU存取,因此可以作為內存使用;與DRAM相比,NVM掉電數據不丟失,且存儲密度更高,因此能夠支持海量的數據存儲。目前,NVM離實用場景越來越近。2019年4月,DIMM接口的NVM(傲騰DCPMM)已正式投放市場,單片容量可達512 GB且單機可支持高達8 TB的NVM容量(https://www.intel.cn/content/www/cn/zh/architecture-and-technology/optane-dc-persistent-memory.html)。
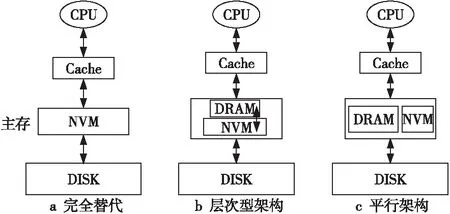
Figure 1 Possible architecture involving NVM
理論上,在內存架構中引入NVM后可能形成3種架構(如圖1所示)。第1種用NVM完全替代DRAM,如圖1a所示。但是,由于NVM與DRAM相比具有訪問時延高、寫次數有限和寫功耗大等缺點[4],完全用NVM替代DRAM從目前看不是最佳選擇。第2種是層次型架構,如圖1b所示。這種架構需要把DRAM作為NVM的緩存,而NVM則作為DRAM的第2級內存。這一架構主要存在2個方面的問題:首先,由于DRAM只是作為NVM的緩存,因此系統可見的內存僅為NVM的空間,在內存空間使用上不合算;其次,這一架構只是利用了NVM比DRAM容量大的優點,操作系統的數據訪問依然還是通過DRAM,沒有充分利用NVM的非易失性特點。第3種架構是平行架構,即NVM和DRAM同時作為同一層次的主存使用,如圖1c所示。在這種架構下,系統可用的內存空間等于DRAM的容量和NVM的容量之和,而且操作系統可以感知2類內存的特性,可以充分利用DRAM和NVM各自的優點。從目前DRAM和NVM的發展趨勢來看,DRAM和NVM并存的異構混合內存架構更具有可行性和發展前景。無論采用哪種混合內存架構,出發點都是要盡可能地同時發揮DRAM和NVM的優勢。
在未來理想的情況下,隨著NVM容量的逐步增加和成本的下降,在異構混合內存架構中,我們可以只使用DRAM和NVM來構建內存數據庫系統,以支持高性能的在線處理與存儲,而磁盤(DISK)則成為離線的歸檔存儲設備。這種情況下,主存和DISK之間的I/O操作就不再是決定系統性能的主要因素,這對傳統的數據庫管理系統提出了新的挑戰。因為傳統的數據庫管理系統以DRAM+DISK的架構為基礎,絕大部分的數據結構和算法都以減少DRAM和DISK之間的I/O操作為主要目標,因此不適合基于DRAM和NVM的異構混合內存架構。
基于上述背景,本文重點研究傳統數據庫管理系統中的排序連接算法在異構混合內存架構上的優化問題。傳統的排序連接算法如果直接移植到異構混合內存架構上不能充分發揮DRAM和NVM的特性,因此必須針對架構的特性進行重新設計。本文詳細分析了異構混合內存架構對排序連接算法帶來的挑戰,提出了基于鍵值分離和鍵值去重的C-Join算法,并進一步提出了C-Join算法的3種實現方式。最后的實驗結果表明,本文提出的C-Join算法在異構混合內存架構上的性能明顯優于傳統排序連接算法,并且有效降低了DRAM的使用代價。總體而言,本文的主要工作和貢獻可總結為如下幾個方面:
(1)針對NVM可字節尋址和低延遲的特性,采用鍵值分離策略重新實現了傳統的排序連接算法。從目前文獻看,本文提出的鍵值分離的混合內存排序連接策略具有一定的新意。
(2)在鍵值分離策略的基礎上,進一步提出了面向異構混合內存架構的新的排序連接算法C-Join和鍵值去重機制,通過減少連接中重復的鍵值來降低連接過程的內存開銷,從而減少CPU需要處理的數據量,最終提升連接算法的時間性能。
(3)討論了C-Join算法的不同實現方式,提出了3種可能的策略,并進行了對比實驗。結果表明,鍵值分離策略可以有效減少DRAM的使用,同時提高了算法的性能,而C-Join算法的幾種實現方式均能夠在保證時間性能的前提下保持較高的內存空間利用率。
2 相關工作
2.1 非易失內存技術
非易失內存是一種新型的存儲介質,它不同于存儲器和磁盤,屬于存儲級內存,既具有磁盤的特點,又具有內存的特點。與傳統的DRAM和SRAM不同,新興的非易失性內存,如相變存儲器(PCM)、電阻式記憶體(ReRAM)和鐵電存儲器(FRAM),使用電阻存儲器來存儲具有更高密度和近零泄漏功率的信息。因此,NVM有希望成為構建下一代主存和緩存的有主要技術[1-5]。
這些非易失性內存雖然制作材料和制作工藝不同,但卻有著相似的特性,如表1所示,以PCM為例,與DRAM、機械硬盤和固態硬盤進行比較。(1)它們具有高密度和低延遲的特點;(2)它們可以字節訪問并持久化數據;(3)它們都具有讀寫固有的不對稱特性[4,5],寫延遲比讀延遲大得多,并且寫操作相比讀操作會消耗更多的能量;(4)NVM通常具有有限的寫耐久性。因此,在使用NVM時,有必要減少甚至避免寫操作。
2.2 排序連接算法
排序連接算法一般指排序歸并連接算法。為了將2個輸入表數據按照連接鍵進行排序,算法先對輸入進行劃分,然后對每個劃分進行排序后多路歸并得到最終的排序結果,最后遍歷2個排序后的表得到最終的連接結果[6]。排序歸并連接的時間代價主要集中在排序過程中,在此過程中算法會對磁盤進行大量的讀寫操作。通常來說排序連接算法的時間性能會比哈希連接算法差,但是排序連接的通用性更好,因為哈希連接一般只能解決等值連接問題,而排序連接可以處理非等值連接問題。當遇到選擇度為M∶N的連接問題時,哈希連接更是無能為力,而排序連接則可以完美地解決這類問題。另外,當數據庫中關于連接問題的表數據已經按照連接鍵排好序時,采取排序連接算法也能獲得非常好的性能。
2.3 連接算法優化
自20世紀70年代以來,數據庫連接算法得到了廣泛的研究。目前對連接算法的研究主要集中在硬件優化、并發執行等方面。Li等人[7]提出了面向閃存的DigestJoin算法,利用固態硬盤高速的隨機讀能力減少了中間結果和數據處理量。Balkesen等人[8]通過對不同算法和體系結構的實驗分析比較發現,對硬件進行優化和參數調優仍然很重要,具有硬件意識的連接算法比硬件無關的算法性能更好。Albutiu等人[9]設計了一個新的基于部分分區排序的大規模并行排序歸并MPSM(Massively Parallel Sort-Merge)連接算法,證明了MPSM在具有數十億對象的大型內存數據庫上的競爭性能。Viglas[10]提出了Segment Sort、Hybrid Sort和LazySort等算法,通過將寫多讀少和寫少讀多的排序算法結合在一起使用,采用以讀換寫的方式使得總體的讀寫代價達到最小,在整體性能可觀的同時減少了對NVM的寫操作。
一些研究者針對面向NVM的連接算法優化開展了研究。文獻[11]中研究者提出了數據庫虛擬分區連接算法,該算法通過虛擬分區的方式,避免了數據庫分區時的拷貝過程,大大減少了數據庫連接算法執行過程中對NVM的寫操作。文獻[12]則研究了多關系連接算法在NVM內存環境中的優化方法,作者提出的NVjoin算法利用抽樣估計得到中間結果數最小的連接次序,該連接次序使得對多個關系執行連接時,使用最少的內存空間,并且連接過程中對NVM讀寫總數最少。但是,這些方法都是針對NVM Only的架構,不同于本文所針對的異構混合內存架構。
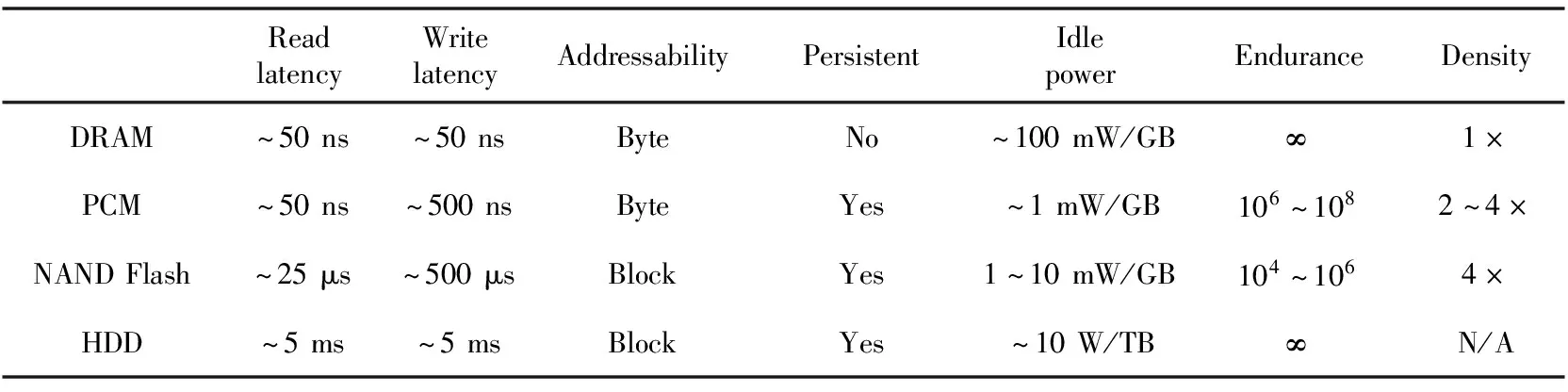
Table 1 Comparison of several storage medias
在面向DRAM和NVM異構混合內存架構的連接算法方面,Yang等人[13]在2019年提出了一種新的Hash連接算法BF-Join。BF-Join重新設計了Hash分區的數據結構,使用NVM在Hash連接過程中存儲構建表和探測表的數據,以避免向NVM寫入數據。BF-Join還引入了布隆過濾器來加速連接過程,并將布隆過濾器設計為一個Cacheline的大小,從而減少BF-Join連接過程中的緩存丟失。從現有文獻看,目前還沒有直接針對基于DRAM和NVM異構混合內存架構排序連接算法的優化工作。
3 C-Join算法
本節介紹面向異構混合內存架構的新型排序連接算法C-Join。C-Join的主要設計思想包括2個方面,即鍵值分離和鍵值去重,下面分別加以討論。
3.1 鍵值分離策略
DRAM和NVM是2種各有特點的存儲設備,它們的優勢和缺點也都很明顯。DRAM的讀寫性能非常好,但是受限于容量和能耗;NVM的容量能耗可觀,并且讀寫性能與DRAM相當,但是讀寫不對稱且寫耐久有限。一個主要的問題是如何在基于DRAM和NVM混合內存的系統中平衡二者的使用,以達到最優的性價比和最佳的性能。NVM由于在寫入方面有著過多的局限(寫速度相對慢、寫能耗相對高、寫耐久有限),所以不能作為經常寫入的設備,與此同時DRAM就理所當然地成為了處理數據結構中需要經常讀寫的內存設備,而NVM的容量大的特點使得其更適合作為多讀的內存存儲設備。
為了使排序連接算法適合異構混合內存架構,本文首先提出基于鍵值分離策略的排序連接思路。通過鍵值分離,將一條記錄拆分為鍵(key)和值(value),然后在NVM中維護整條記錄或者只維護值,而在DRAM中維護鍵和指向原記錄的指針。該策略不僅大大減少了DRAM的使用量,也減少了CPU需要處理的數據量,從而提升性能。
鍵值分離的策略最早是在2017年在針對閃存存儲優化的Wiskey[14]系統中提出的,本文受到Wiskey的啟發,首次將鍵值分離策略與排序連接算法相結合,并用于優化異構混合內存架構上的排序連接性能。當2個表R和S在基于DRAM和NVM的異構混合內存架構上執行排序連接時,按照傳統的排序連接算法,需要把輸入的表數據存儲在NVM中,然后將每條記錄〈key,value〉復制到DRAM中進行排序,排序完成后再對表R和S進行連接操作。而在基于鍵值分離的排序連接算法中,仍將原始表數據存儲在NVM中,但是在執行排序和連接操作時采用〈key,rowid〉形式來代表整條記錄,即只將鍵和記錄指針讀入到DRAM中進行處理,記錄的值則仍然保留在NVM中。該方式可以有效減少DRAM的使用量,也可以減少CPU處理的數據量,因此有助于提高排序連接的性能。
3.2 鍵值去重策略
排序連接算法的基本思想很簡單,首先將輸入的2個表排序,排序完成后再進行連接操作。不同于哈希連接算法只能解決等值連接的問題,排序連接算法還可以處理不等關系的連接問題,其根源在于排序連接算法中的連接操作是在已經排好序的數據上執行的,而排序操作也是算法中最重要的部分。一般來說算法會使用通用的快速排序、堆排序、歸并排序等排序算法,這些算法確實可以高效地完成排序操作,但是對于選擇度為M∶N的連接問題來說,還可以進一步優化。
選擇度為M∶N意味著在表R中的1條記錄在S表中可能會有多條(超過1條)記錄與之相匹配,反之亦然。也就是說,在表R和S中有多個key相同而value不同的記錄。如果按照傳統的方式執行算法,這些記錄〈key,value〉都需要被傳輸到DRAM中進行排序操作,因此存在著大量重復的數據拷貝,即key的多次拷貝。本文在鍵值分離策略的基礎上,進一步提出鍵值去重策略,通過去除重復的鍵來進一步降低DRAM的使用代價。
在選擇度為M∶N的連接問題中,輸入的表數據中可能有多個key相同而value不同的記錄,為了能夠減少key的重復拷貝,本文采取對具有相同key的記錄進行合并的方式來組織數據。算法1給出了基于鍵值分離和鍵值去重的C-Join算法流程。首先,為了對表R和S中相同key的記錄合并,分別為它們分配了2個桶數組bucketsR和bucketsS,這2個桶數組的個數是按照連接鍵的上閾值Kmax設定的。接著,遍歷2個表的每條記錄,通過key可以確定它所屬的那個桶,然后將之插入到該桶中,在插入時使用〈key,rowid〉的形式來表征完整的記錄。當2個表的記錄都插入到對應的桶中時,整個排序操作也已經完成。接著,進行連接操作,桶數組bucketsR和bucketsS中連接鍵相同的桶是互相匹配的數據,而那些空的桶則跳過,最終得到連接的結果。
算法1C-Join
Input:R,S;
Output:none。
1 mallocKmaxbucketsbucketsR;
2foreach record inRdo
3 insert 〈key,rowid〉 intobucketsR[key];
4endfor
5 mallocKmaxbucketsbucketsS;
6foreach record inSdo
7 insert 〈key,rowid〉 intobucketsS[key];
8endfor
9foreach bucket inbucketsRdo
10 find the mathing bucket inbucketsS;
11endfor
3.3 C-Join的3種實現方式
在C-Join算法中,桶的數據結構是整個算法中的關鍵部分,桶的設計方案也會直接影響算法在執行過程中的DRAM代價和時間性能。因此,本節針對桶的設計提出3種實現方案,即鏈式結構、線性結構和預分配線性結構。
(1)鏈式結構(C-Join-Chained)。如圖2所示,在鏈式實現中,桶由一個key形成的頭節點以及后面跟著的若干個rowid節點組成,節點之間以指針相連,這樣的數據組織形式的優點在于方便靈活,可以靈活地擴展桶的大小,但是由于指針太多會對空間利用率和性能造成一定的影響。

Figure 2 C-Join-Chained
(2)線性結構(C-Join-Linear)。線性實現方案的思路如圖3所示,與鏈式實現相比,線性實現在rowid的管理上采用了線性數組的形式,這樣的組織形式減少了指針的占用空間,并且在訪問數據時避免了由指針帶來的多次尋址問題,從而縮短了算法的執行時間。但是,其缺點在于該種實現方式必須事先分配一個合理大小的空間以容納所有的記錄,這往往會帶來一部分的空間浪費。

Figure 3 C-Join-Linear
(3)預分配線性結構(C-Join-Premalloc)。線性實現中需要提前分配一個合理大小的空間,帶來了一些內存空間的浪費,因此,希望找到一種方法能夠提前準確地分配一個空間使之剛好能夠容納所有的記錄。要想達到這個效果,那么就必須要知道每個桶所需容納的記錄的數量,而數據庫中一般沒有這項參數。因此,只能先讀取一遍數據,以統計每個桶中記錄的數量,然后再分配每個桶的空間,這樣就避免了一部分的內存浪費。但是,同時也會造成時間性能的下降,因為多讀取了一遍數據。具體數據結構如圖4所示,與線性實現的結構基本相同,只是減少了桶中不必要的空間浪費,使得整個桶空間變得非常緊湊。
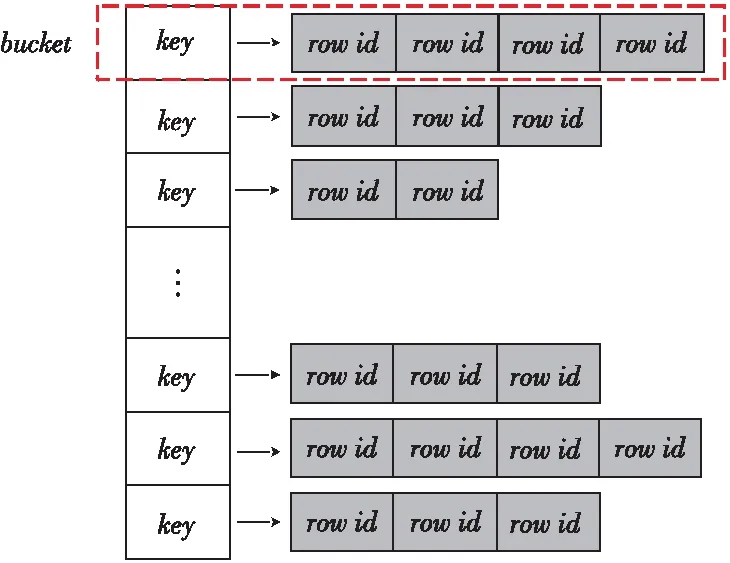
Figure 4 C-Join-Premalloc
從理論上來看,鏈式結構除了在使用上比較靈活外,在內存空間和運行時間方面表現都不會很好。而當表數據每個獨特key出現次數比較接近而且已知出現次數的上限時,采用線性結構比較好,至于更普遍的情況則是采用預分配線性結構比較好。
4 實驗結果
4.1 實驗設置
本文所有的實驗都是在安裝了Ubuntu 18.04系統的筆記本電腦上執行的。該電腦的處理器為Intel? CoreTMi5-4210U CPU @ 1.70 GHz 2.40 GHz,L1、L2、L3緩存大小分別為128 KB、512 KB和3 MB。DRAM內存大小為12 GB。由于排序連接算法的所有實驗均不涉及到NVM的寫操作,所以在實驗中沒有模擬NVM的寫延遲,而NVM讀延遲與DRAM相當,所以可以用DRAM來模擬NVM。在實驗中主要考察算法的時間性能和DRAM的代價。
由于目前還沒有基于異構混合內存系統上的排序連接算法,所以實驗中主要對比C-Join算法與傳統的排序連接算法(SortJoin)。為了更細致地測試鍵值分離與鍵值去重策略的性能,本文單獨實現了基于鍵值分離的排序連接算法,記為SortJoin-V。同時也對比了采用了鍵值分離和鍵值去重的C-Join算法的3種實現方式。所有對比的算法如下所示:
(1)傳統排序連接算法(SortJoin)。這個算法不使用鍵值分離而是使用〈key,value〉整條原始數據執行算法,其中使用的排序算法是快速排序算法。
(2)鍵值分離的排序連接算法(SortJoin-V)。該算法與傳統排序連接算法類似,只不過采用了鍵值分離策略,使用〈key,rowid〉來表征整條數據。
(3)C-Join-Chained(CJoin-C)。C-Join-Chained是C-Join 3種實現方式的一種,它采用了鏈式結構來組織桶,桶中的〈rowid〉以指針相連。
(4)C-Join-Linear(CJoin-L)。C-Join-Linear是C-Join 3種實現方式的一種,它采用了線性數組結構來組織桶,桶中的〈rowid〉存儲在一個地址連續的空間中。
(5)C-Join-Premalloc(CJoin-P)。C-Join-Premalloc是C-Join 3種實現方式的一種,它與C-Join-Linear類似,但是對桶的大小采用預分配的方式進行設置,使得空間更加緊湊。
上述所有算法都使用了相同的NVM和DRAM設置。表R和表S都在NVM上維護,所有中間數據和數據結構都在DRAM上維護。由于在連接過程中不會對NVM上的表數據進行寫操作,因此,排序連接算法的實驗中只關注DRAM的使用量和運行時間。
在工作負載方面,使用與Balkesen等人[8,15]和Albutiu等人[9]類似的工作負載生成方式。文獻中大多采用key加payload的方式,key的大小一般為4 B或8 B。在本文實驗將記錄的key和rowid設為8 B,而value的默認大小設置為1 024 B,在比較鍵值分離的排序連接算法實驗中,將通過改變value的大小來觀察算法在內存用量和運行時間方面的表現。N表示表R和表S中獨特的key的數量,KR和KS分別表示表R和表S中每個獨特key出現的次數,表R和表S的記錄數量分別為N×KR和N×KS,其中N設置為100 000,KR和KS分別設置為10和20。
4.2 SortJoin vs.SortJoin-V
(1)DRAM代價:如圖5和圖6所示,采用了鍵值分離策略的SortJoin-V的DRAM使用量大大減少,而且隨著value的增大,SortJoin-V的DRAM使用量不再增加。當N增大時,SortJoin-V的DRAM使用量雖然略有增加,但是與傳統的SortJoin相比完全可以忽略不計。與SortJoin相比,SortJoin-V大幅減少了DRAM使用量(SortJoin的DRAM使用量約為SortJoin-V的16倍)。從圖5和圖6中可以得到一個結論,SortJoin-V對DRAM內存空間的使用更加高效,而且當輸入數據規模不斷增大時,SortJoin-V會節省更多的DRAM空間。
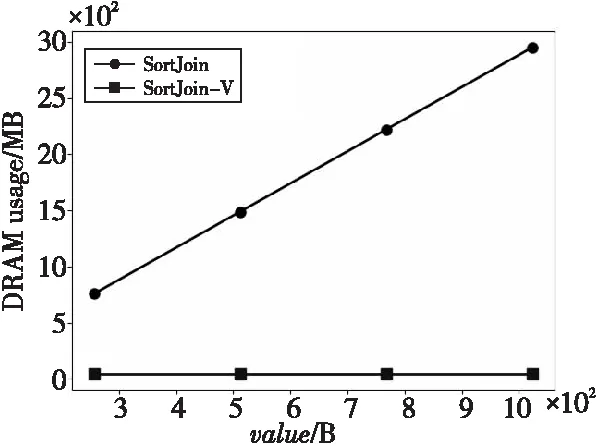
Figure 5 DRAM usage of SortJoin and SortJoin-V with different value
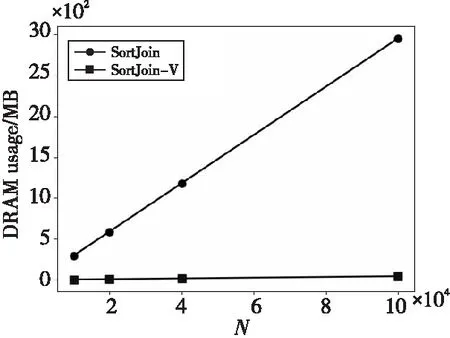
Figure 6 DRAM usage of SortJoin and SortJoin-V with different N
(2)運行時間:排序連接算法的運行時間如圖7和圖8所示,SortJoin的運行時間比SortJoin-V的運行時間高出約2.4倍,而且隨著數據規模的增大,SortJoin-V的運行時間增長速度也比SortJoin的運行時間增長速度更為緩慢,這表明采用了鍵值分離策略的排序連接算法在運行時間方面更有優勢。

Figure 7 Running time of SortJoin and SortJoin-V with different value
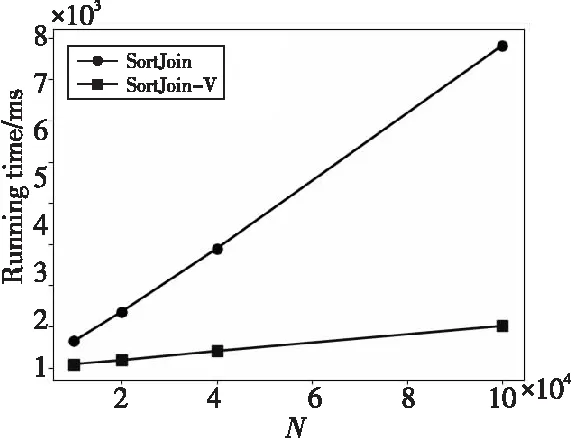
Figure 8 Running time of SortJoin and SortJoin-V with different N
4.3 C-Join vs.SortJoin-V
在這一節中,將SortJoin-V作為基準與C-Join的3種實現方式進行對比,具體結果如圖9和圖10所示。
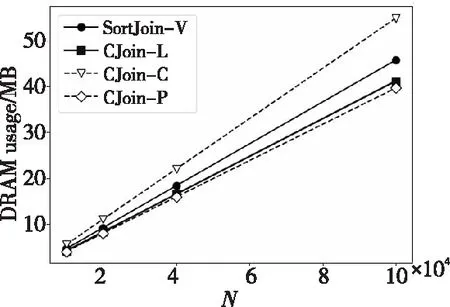
Figure 9 DRAM usage of C-Join and SortJoin-V with different N

Figure 10 Running time of of C-Join and SortJoin-V with different N
從圖9中可以看出,與SortJoin-V相比,CJoin-L和CJoin-P的DRAM使用量更低,而其中CJoin-P的最低,在最好情況下比SortJoin-V節省了13.3%的DRAM空間。這主要歸功于CJoin-P的預分配策略,這也與本文之前的分析相符合。從圖10中可以看到,CJoin-L是4種算法中執行時間最短的,最多比SortJoin-V節約了27.8%的時間,運行時間最高的則是采用了大量指針的CJoin-C,而CJoin-P由于需要提前讀一次表數據,所以性能略有下降,與SortJoin-V的性能相當。總的來說,C-Join實現方式中的CJoin-L和CJoin-P表現比較出色,特別是CJoin-L在DRAM使用量和時間性能方面都要比SortJoin-V更好。
4.4 KR對C-Join算法的影響
由于C-Join算法的核心思想是通過減少數據中重復的key來達到內存空間的節省和時間性能的提升的,所以KR和KS(KR和KS分別表示表R和表S中每個獨特key出現的次數)會對C-Join的2個評估指標產生影響。圖11和圖12展示了不同KR時DRAM使用量和運行時間的變化(這里我們只使KR變化,而KS設置成KR的2倍)。
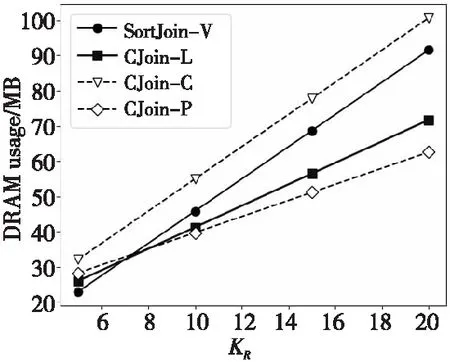
Figure 11 DRAM usage of C-Join and SortJoin-V with different KR
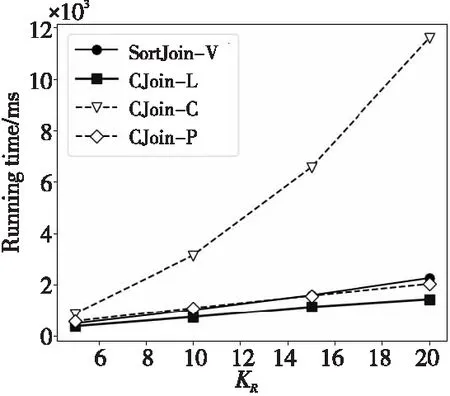
Figure 12 Running time of C-Join and SortJoin-V with different KR
從圖11和圖12可以觀察到,隨著KR的增大,CJoin-L和CJoin-P在DRAM使用量方面增加得較為緩慢,在運行時間方面,CJoin-L的增速也是4種算法中最低的。綜合來看,CJoin-L的實現方式可以很好地應對不同KR的連接問題,在內存使用量和運行時間方面其性能都超過了SortJoin-V,而CJoin-P雖然使用的內存空間更少,但是在運行時間方面卻沒有優勢。
5 結束語
本文針對基于DRAM和NVM的異構混合內存架構提出了一種基于鍵值分離和鍵值去重策略的新型排序連接算法C-Join。鍵值分離的策略可以充分發揮NVM的獨特特性和DRAM的高性能優勢,從而能夠有效減少DRAM使用量,提升連接性能。鍵值去重策略則通過消除連接過程中重復的鍵值拷貝進一步降低了DRAM的代價。本文在算法設計的基礎上,進一步給出了C-Join算法的3種實現方式,通過采用不同的桶數據結構來執行C-Join算法。在模擬數據集上的實驗結果表明,鍵值分離的策略能夠有效地縮短連接時間和降低DRAM代價。C-Join算法的3種實現方式均能夠進一步優化DRAM代價和時間性能。
猜你喜歡
兒童時代·幸福寶寶(2022年12期)2022-12-09 11:24:14
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
名家名作(2021年9期)2021-10-08 01:31:36
名家名作(2021年4期)2021-05-12 09:40:02
名家名作(2021年3期)2021-04-07 06:42:16
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
新世紀智能(語文備考)(2019年12期)2020-01-13 06:04:32
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
名家名作(2017年2期)2017-08-30 01:34:24
